

我们知道一个大型的公司往往都具有复杂的组织结构,成百上千号员工,要做到大而不乱,就必须依靠合理的组织结构来优化内部的交流成本。Redis 内部也有组织结构,不同的是这个组织结构要维系上亿的对象,而不是几百几千。今天我来向大家呈现 Redis 如何来管理这上亿的对象而不会混乱的。

Redis 的对象很多,但是对象的种类却是有限的,目前一共只有7种对象。
#define OBJ_STRING 0 /* String object. */
#define OBJ_LIST 1 /* List object. */
#define OBJ_SET 2 /* Set object. */
#define OBJ_ZSET 3 /* Sorted set object. */
#define OBJ_HASH 4 /* Hash object. */
#define OBJ_MODULE 5 /* Module object. */
#define OBJ_STREAM 6 /* Stream object. */
看到这里,肯定会要很多人要举手表示抗议!老钱啊,你这不对啊,HyperLogLog 哪里去了?Geo 哪里去了?
这个问题提的非常棒!其实这个问题是我在写这篇文章的时候自己向自己提出的,我在问这个问题的时候,我也不知道为什么,我只是隐约觉得上面这三种高级数据结构在Redis内部应该是混合使用了上面的基础数据结构,也就是说他们是复合数据结构。但是我需要求证,于是我阅读了一下源码证实了我的猜测。
HyperLogLog 和 Bitmap 一样,使用的是一个普通的动态字符串,而 Geo 使用的是 zset。还有一个奇妙的地方就是当你使用 pfadd 构造出来的计数器对象可以直接使用字符串命令将它的内部全部显示出来。
127.0.0.1:6379> pfadd codehole python java golang
(integer) 1
127.0.0.1:6379> get codehole
"HYLL\x01\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x80C\x03\x84MK\x80P\xb8\x80^\xf3"
同样你也可以使用 zset 相关的指令将 geo 的内容显示出来
127.0.0.1:6379> GEOADD city 13.361389 38.115556 "Palermo" 15.087269 37.502669 "Catania"
(integer) 2
127.0.0.1:6379> zrange city 0 -1 withscores
1) "Palermo"
2) "3479099956230698"
3) "Catania"
4) "3479447370796909"
这个问题算是回答完了,接下来我再提出一个问题,平时我们听的「跳跃列表 skiplist」,「压缩列表 ziplist」、「快速列表 quicklist」跟对象类型什么关系?
为了回答这个问题,接下来要引入 Redis 的对象结构。Redis 所有的对象都有一个相同的「头结构」,头部结构中有一个指针指向各自不同的「体结构」。
typedef struct redisObject {
unsigned type:4; // 对象类型
unsigned encoding:4; // 对象编码
unsigned lru:24; // LRU时间戳
int refcount; // 引用计数
void *ptr; // 指向体结构的指针
} robj;
我们注意到 type 字段只有 4bit,最多只能表示 16 个对象类型,这大概是为什么对象类型要省着用的原因,太浪费了以后就不好扩展了。
我们还注意到有一个 encoding 字段,它也是 4 个位,它代表的是对象的内部结构类型。Redis 为了节约内存,在集合对象比较小时,采用特殊结构进行存储。比如hash对象在内部 key 很少 (size<512) 并且 value 值较短 (len<64) 的时候采用 ziplist 进行存储,超过了这个数量就使用标准的 hashtable 存储。
Type是对外统一接口是形象,Encoding是对内具体实现是骨肉。
我们翻翻源码来看看 encoding 都有哪些
#define OBJ_ENCODING_RAW 0 // 可修改的长字符串
#define OBJ_ENCODING_INT 1 // 整型字符串
#define OBJ_ENCODING_HT 2 // hashtable
#define OBJ_ENCODING_ZIPMAP 3 // 压缩map,已经废弃不用,改用ziplist
#define OBJ_ENCODING_LINKEDLIST 4 // 双向链表,已废弃不用,改用quicklist
#define OBJ_ENCODING_ZIPLIST 5 // 压缩列表
#define OBJ_ENCODING_INTSET 6 // 整数集合,个数少全是整数的set
#define OBJ_ENCODING_SKIPLIST 7 // 跳跃列表,zset的标准内部结构
#define OBJ_ENCODING_EMBSTR 8 // 只读短字符串
#define OBJ_ENCODING_QUICKLIST 9 // 快速列表,存储list
#define OBJ_ENCODING_STREAM 10 // 流
看到这里我开始有点当心,encoding 只有 4bit,但是已经用掉了 11 个值,以后要是扩展改怎么办?这个问题这里就不好回答了,大家可以自己讨论。
Type和Encoding的对应关系如下
1. string ==> raw|embstr|int
2. list ==> quicklist
3. hash ==> ziplist|hashtable
4. set ==> intset|hashtable
5. zset ==> ziplist|skiplist
6. stream => stream
接下来我们要开始深入内部结构了,将每一个结构都过一遍,限于篇幅,不能讲的太详细。
第一个我们要讲的是字典,因为它太重要了,Redis 对象树的主干就是字典结构,key 是对象的名称,value 是各种不同的对象,所有的对象都挂在一棵字典上。除了容纳所有对象的主干字典外,还有容纳所有带过期时间的对象的过期主干字典,它的 key 是对象的名称,value 是对象的过期时间戳。
typedef struct redisDb {
dict *dict;
dict *expires;
...
} redisDb;
字典的 value 呈现出了多态性,它可以是一个单纯的整数或者浮点数,也可以是一个对象,会有一个统一的对象头,也就是前面的 redisObject 结构体,会根据 type 字段和 encoding 字段来决定 ptr 字段指向的具体数据结构。我们来看一下字典的结构体代码定义
// dict
typedef struct dict {
dictType *type; // 字典的接口实现,为字典带来多态性
void *privdata; // 存储字典的附加信息
dictht ht[2]; // 注意这里不是指向指针的数组,为什么?
long rehashidx; // 渐进式rehash时记录当前rehash的位置
unsigned long iterators;
} dict;
// dict hashtable
typedef struct dictht {
dictEntry **table; // 指向第一维数组
unsigned long size; // 数组的长度
unsigned long sizemask; // 用于快速hash定位 sizemask = size - 1
unsigned long used; // 数组中的元素个数
} dictht;
// 定义了字典功能的接口
typedef struct dictType {
uint64_t (*hashFunction)(const void *key);
void *(*keyDup)(void *privdata, const void *key);
void *(*valDup)(void *privdata, const void *obj);
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
void (*keyDestructor)(void *privdata, void *key);
void (*valDestructor)(void *privdata, void *obj);
} dictType;
// key-value wrapper
typedef struct dictEntry {
void *key;
union {
void *val; // sds|set|dict|zset|quicklist
uint64_t u64; // 用于过期字典,val存储过期时间戳
int64_t s64; // Don't watch me!
double d; // 用于zset,存储score值
} v;
struct dictEntry *next;
} dictEntry;
字典结构的内部实现是两个 hashtable,为什么是两个 hashtable 呢,这个涉及到字典的渐进式扩容和所容,我们后再讲。通常情况下,我们只会使用到ht[0],一个单纯的 hashtable
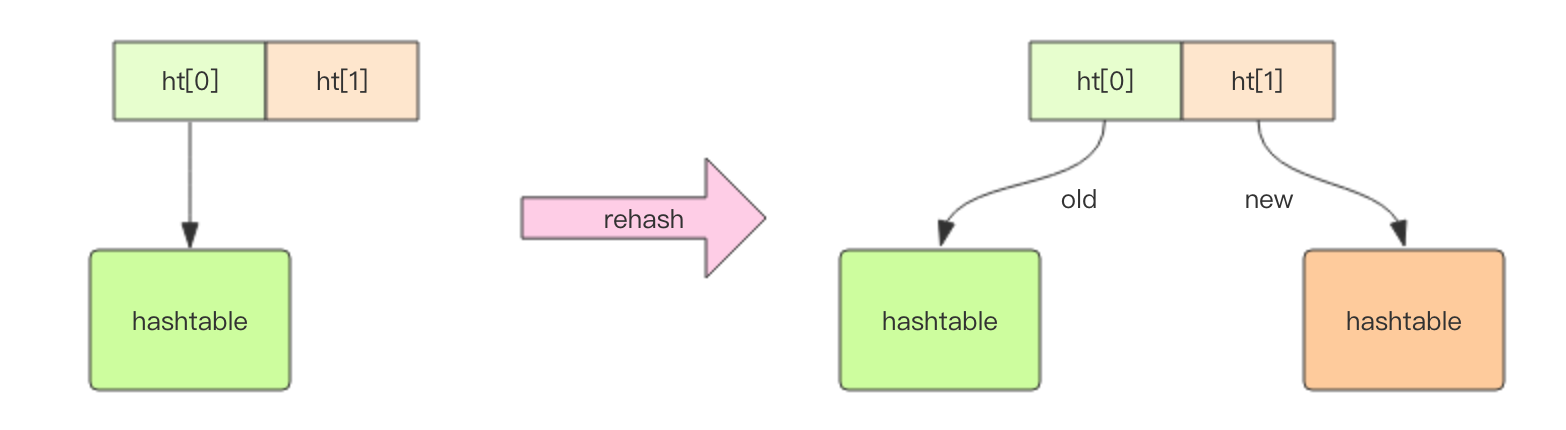
我们看看 hashtable 的内部结构。hashtable 的结构和 Java 语言的 HashMap 初级版是一样的,为什么说初级版本呢,因为 Java8 对 HashMap 做了改造,在 hash 不均匀的时候做了复杂的优化处理,至于具体的优化方法,这里我就不做详细解释了,感兴趣可以搜索相关资料。
我们看下字典的内部结构,它是一个二维的
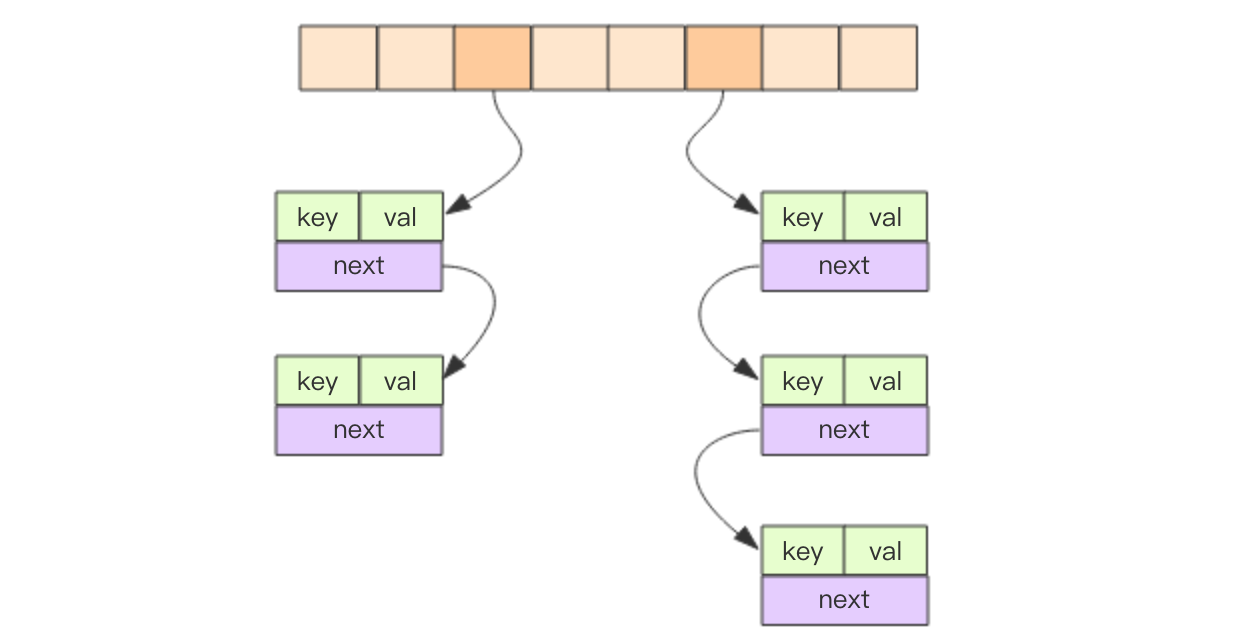
查找过程如下,为了方便阅读,我仔细去掉了额外的需要考虑「渐进式迁移」的部分代码
dictEntry *dictFind(dict *d, const void *key)
{
dictEntry *he;
uint64_t h, idx, table;
if (d->ht[0].used == 0) return NULL; /* dict is empty */
h = dictHashKey(d, key); // 计算hash值
idx = h & d->ht[0].sizemask; // 定位数组位置
he = d->ht[0].table[idx]; // 获取链表表头
while(he) {
if (key==he->key || dictCompareKeys(d, key, he->key))
return he; // 找到了就返回
he = he->next; // 找不到继续遍历
}
return NULL;
}
其中 dictHashKey 和 dictCompareKeys 会分别调用相应字典的多态函数
#define dictHashKey(d, key) (d)->type->hashFunction(key)
#define dictCompareKeys(d, key1, key2) \
(((d)->type->keyCompare) ? \
(d)->type->keyCompare((d)->privdata, key1, key2) : \
(key1) == (key2))
需要注意到定位数组用的是按位操作,这是因为字典的第一维数组的长度都会 2^n 。对于 2^n 长度的数组来说,对数组长度的取模操作等价于按位操作
sizemask = size - 1;
idx = h & d->ht[0].sizemask ==> idx = h % d->ht[0].size
我们在使用 Java 的 HashMap 时会当心如果对象的 hashcode 不均匀,会导致链表长度差别较大,个别链表会特别长,对性能就会产生较大影响。所以 Java8 对 HashMap 的链表进行了适当的改造,如果链表的长度超过 8,就会转变成一颗红黑树,用于提升查找效率。
那为什么 Redis 不需要考虑这点呢?
这是因为 Java 的 HashMap 容纳的 key 对象是不可控的,它可以是任意对象,如果对象的 hashCode 方法返回的数值不均匀就会带来性能问题。
但是 Redis 的字典容纳的 key 都是 sds 动态字符串,它的 hashCode 是均匀的可控的,Redis的内置 hash(siphash) 算法可以保证字符串的 hash 值非常均匀。
接下来我们谈谈字典的扩容。
在 Java 的 HashMap 里面,扩容是申请一个新的数组,这个数组是旧数组的两倍大小,然后一次性将旧数组下面挂接的所有元素一次性全部迁移到新数组中。如果字典中元素特别多,扩容会比较消耗计算资源,也就是通常所说的「卡顿」。
Redis 内存里可以容纳的对象会上亿,这些对象是使用字典组织起来的。如果 Redis 字典的扩容策略和 Java 的 HashMap 一样,这样庞大的字典肯定也会遭遇「卡顿问题」。
Redis 为了解决这个问题,它使用了渐进式迁移策略。当字典需要扩容时,它会申请一个新的 hashtable 放在字典的 ht[1] 中,在迁移完成之前新旧两个 hashtable 将会共存,也就是 ht[1] 和 ht[0] 两个字段值同时存在。
int dictExpand(dict *d, unsigned long size)
{
if (dictIsRehashing(d) || d->ht[0].used > size)
return DICT_ERR;
dictht n;
unsigned long realsize = _dictNextPower(size);
if (realsize == d->ht[0].size) return DICT_ERR;
// 分配一个新的hashtable
n.size = realsize;
n.sizemask = realsize - 1;
n.table = zcalloc(realsize*sizeof(dictEntry*));
n.used = 0;
// 如果是空字典的第一次扩容,那就挂到ht[0]上
if (d->ht[0].table == NULL) {
d->ht[0] = n;
return DICT_OK;
}
// 挂在ht[1]上,准备进行渐进式迁移
d->ht[1] = n;
d->rehashidx = 0;
return DICT_OK;
}
在后续该字典的每个指令中,Redis都会将旧 hashtable 的一部分键值对迁移到新的 hashtable 中。目前渐进式迁移每次迁移 10 个槽位,也就是最多 10 个链表,平均一个链表的长度大约是 1。看到这里我不禁要当心一个大型的字典需要渐进式迁移多少次才能完成。如果没有了后续的读写操作,是不是就永远无法迁移完成了呢?这个读者可以继续思考。
当 Redis 中积累了上亿个对象时,这颗对象树的主干是一个字典,这个字典是非常大的,它也需要扩容。如果这个渐进式扩容的时间比较漫长,Redis 的每个指令都需要进行渐进式迁移,势必会持续影响整体的性能,而且内存会长期处于一个比较高的冗余状态。
所以 Redis 对于这个主干字典采取了定期主动迁移法,每隔 1ms 都会执行渐进式迁移,每次迁移不超过 1ms,以免导致正常的指令卡顿。
// 渐进式rehash,最多持续时间ms
int dictRehashMilliseconds(dict *d, int ms) {
long long start = timeInMilliseconds();
int rehashes = 0;
// 每次执行100步(每步10个槽位),停下来看看时间,如果超出时间就中断
while(dictRehash(d,100)) {
rehashes += 100;
if (timeInMilliseconds()-start > ms) break;
}
return rehashes;
}
// 对指定db进行渐进式rehash
// 优先迁移所有对象的主干字典,再考虑过期对象字典
int incrementallyRehash(int dbid) {
if (dictIsRehashing(server.db[dbid].dict)) {
dictRehashMilliseconds(server.db[dbid].dict,1);
return 1;
}
if (dictIsRehashing(server.db[dbid].expires)) {
dictRehashMilliseconds(server.db[dbid].expires,1);
return 1;
}
return 0;
}
同时如果 Redis 正在进行 bgsave 或者 bgaofrewrite 开启子进程来执行持久化操作时,需要遍历整颗对象树。为了避免父子进程过多的页面分离出来拉高整体内存占用,在这两条指令执行时,尽量不执行字典的扩容 dict_can_resize = false,除非字典已经特别拥挤,这个拥挤程度的阈值默认是 dict_force_resize_ratio = 5,也就是字典元素的个数相对第一维数组的长度的比例。
static int _dictExpandIfNeeded(dict *d)
{
// 如果正在执行渐进式rehash,那就暂时不要扩容
if (dictIsRehashing(d)) return DICT_OK;
// 如果是空字典,那就进行第一次扩容
if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE);
// 综合考虑字典的拥挤程度以及实例是否处于bgsave/bgaofrewrite
// 来决定是否进行扩容
if(dict_can_resize ||
d->ht[0].used/d->ht[0].size > dict_force_resize_ratio))
{
return dictExpand(d, d->ht[0].used*2);
}
return DICT_OK;
}
有关字典的内容就讲到这里,下一篇我们继续看看字典里面容纳的 key 。字典的 key 放的都是字符串,所以下一篇我们要讲的内容是字符串的内部结构,敬请期待。
本文节选之掘金在线技术小册《Redis 深度历险》,对 Redis 感兴趣请点击连接深入阅读《Redis 深度历险》


阅读更多深度技术文章,扫一扫上面的二维码关注微信公众号「码洞」
