


传统对于监控KPI数据监控通常是基于规则,根据预先设定的阈值来报警, 这种方法虽然简单,但适应性不好,容易出现大量误告漏告,给实际运维工作带来巨大的挑战。为此,本文开发了基于机器学习的KPI异常检测新方法。该方法以逻辑回归模型、小波分析模型、随机森林模型和BiLSTM模型为基础模型,通过加权综合的方式对异常点进行识别。最终在第一届AIOps竞赛中,该方法以F1-Score为0.771397的得分,位列决赛第二。
关键字
异常检测, 序列数据,流数据,实时检测,KPI
1.简介
1.1 背景介绍
随着互联网,特别是移动互联网的发展,WEB服务已经深入到各个领域,WEB服务的稳定性主要靠运维来保障,运维人员通过监控各种各样的运维KPI指标来判断服务是否稳定。然而,实际应用中的运维指标如CPU使用率、内存使用率、磁盘IO等这些指标有成百上千条,单靠人的力量已经无法进行手动监控,因而需要借助于一些自动化的工具或者程式来辅助进行运维监控。本文提出的基于机器学习的KPI异常检测模型的具有模块化,普适及高效的特点,适用于在线实时的KPI异常检测,可有效地降低运维人员的工作量。
1.2 数据探索
对于AIOps官方提供的预赛数据集,本文对数据进行了KPI日均值分析、KPI相似性分析、宏观趋势分析、异常细节分析以及多尺度小波分析。通过对比,可以发现部分KPI具有一些相似的形态和异常点特性,不同KPI之间差异可以非常大。单一的模型不能一劳永逸地适用于所有KPI的异常检测。
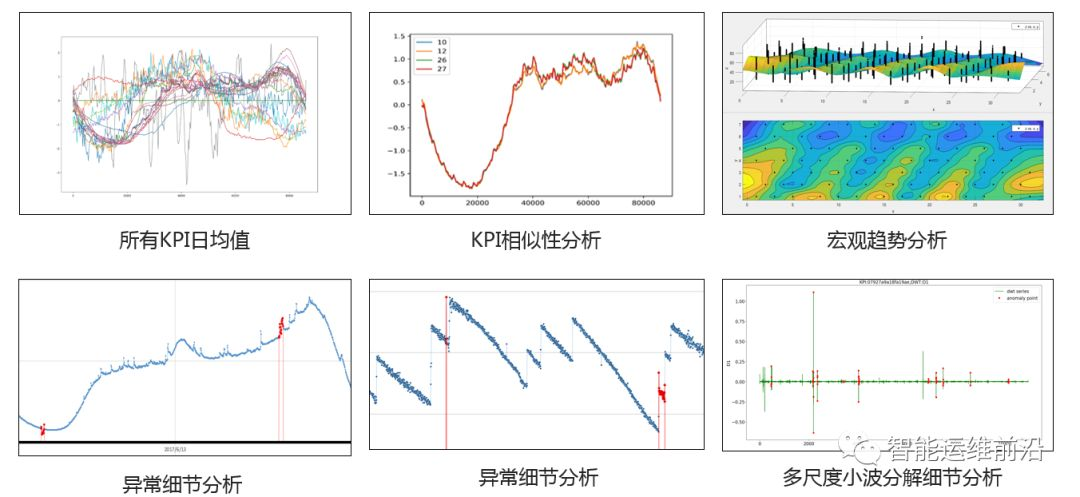
图1.1 数据探索
2.总体设计
图2.1是基于加权综合的异常检测算法的基本框架,主要分为离线模型训练和在线检测两部分。本文尝试了多种异常检测模型,权衡比赛时间和模型的有效性后,最终选取了逻辑回归模型、小波分析模型、随机森林模型和双向LSTM神经网络模型作为加权模型的基本模型,在实时单点检测时,通过加权投票的方式来进行异常点的确定。
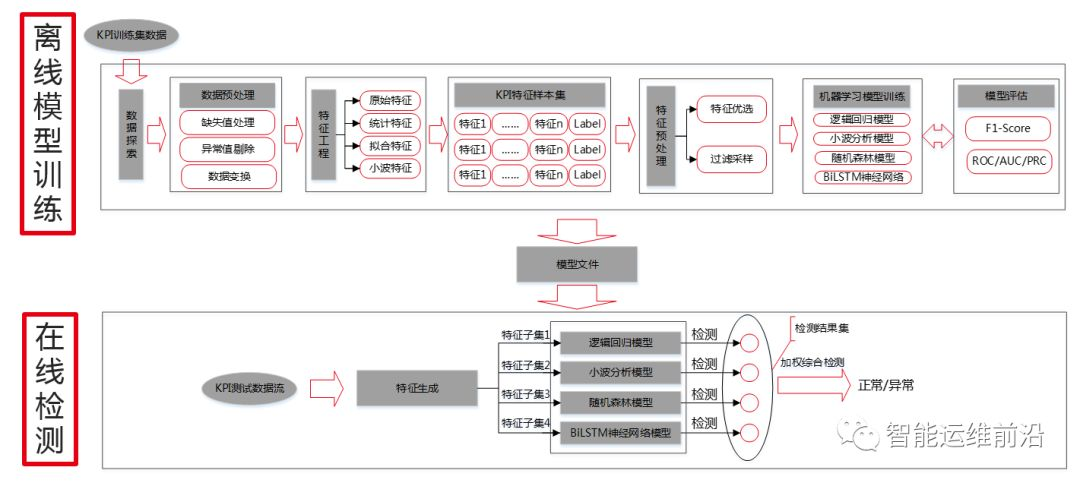
图2.1 算法框架
3.详细设计
3.1 数据预处理
数据预处理主要进行三项内容:
(1)异常数据剔除。使用Grubbs准则,异常点并不一定是官方标记的异常点。
(2)数据标准化处理。为生成不同的特征,本文有选择地使用Z-score和Min-Max方法对数据进行标准化和归一化。
(3)缺失值处理。在尝试了剔除方法、均值方法、插值方法等补全方法后,最终选择均值进行补全。
3.2 特征提取
特征提取是模型训练前最关键的一个内容,特征提取的好坏决定了机器学习的上限。本文参考了裴丹教授在Opprentice框架中提出的特征提取方法,同时借鉴时序特征提取方法,最终选择了原始值特征、统计特征、拟合特征和小波分析特征。通过调整时间窗大小以及提取方法的参数,本模型共提取了61个时序特征。部分特征的提取效果见图3.2。
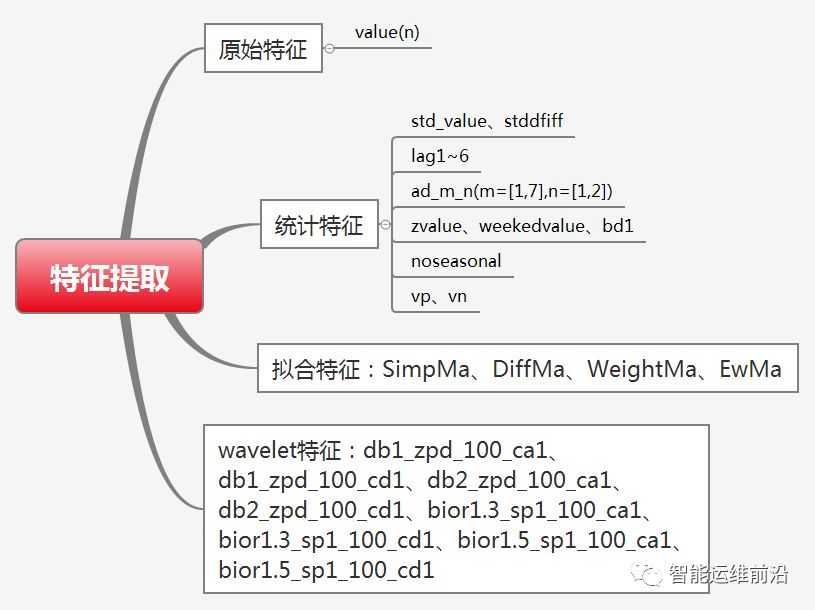
图3.1 特征提取汇总
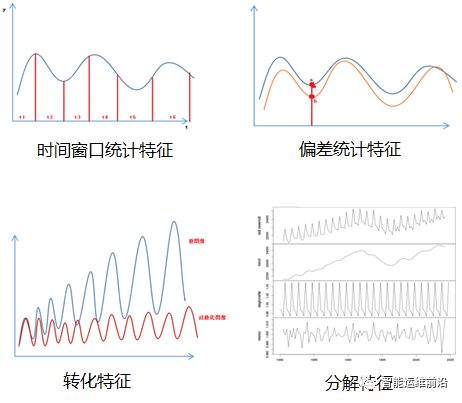
图3.2 特征示例
对于训练集,每个数据点都有61维度的特征可被用于模型训练,在线检测阶段,每获取到一个数据点需要利用历史窗口数据计算当前点的61维度特征。
3.3 数据均衡
本赛题的KPI异常检测的样本数据中,正负样本极度不均衡,对模型的训练效果会产生较大影响,因此在进行神经网络模型等模型的训练前,需要对样本数据进行均衡处理。
本文同时采取了两种数据均衡方案,一是对非异常数据进行欠采样(随机抽样方法),二是对异常点数据进行过采样,主要使用了SMOTE和ADASYN方法。这样确保了输入模型的样本数据的正负样本比例为1:1。
在过采样方案中,本文并不是对所有的异常样本作为过采样的初始样本,而是剔除了特征不明显的异常数据点,比如图3.3中水平段的异常数据点,按照比赛要求,只要异常区段的前7个点中有一个异常点被正常识别,则整个区段将被识别,而如果仅仅识别了第7个点以后的数据点,区段将被标记为未识别,第7个点之后的异常识别对于f-score的提升是不起作用的,反而可能因为加入了新的特征导致错误率的上升。所以本文在训练时,异常区段的第8个点及以后的样本数据点不纳入模型训练。
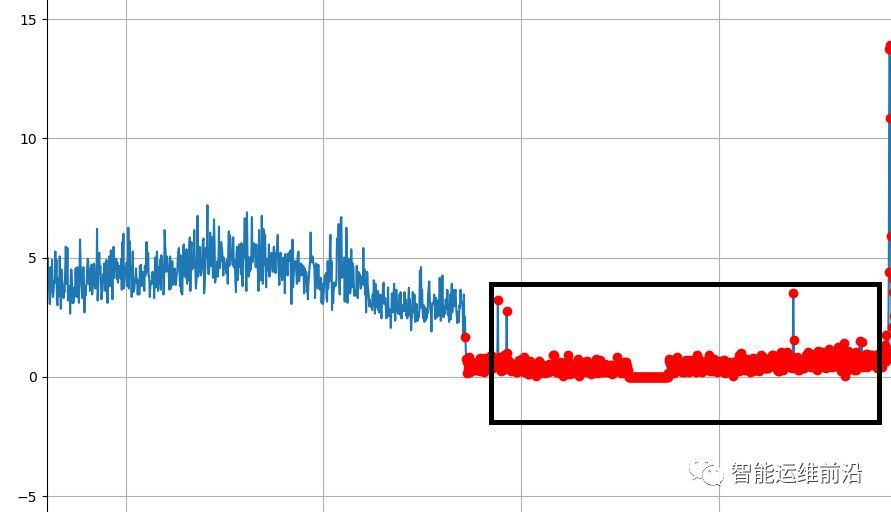
图3.3 异常点数据示例
3.4 基于逻辑回归的异常检测
逻辑回归是在线性回归的基础上,套用了sigmoid函数完成线性到非线性的转变,被广泛的应用于拟合和分类。从判断结果看KPI异常检测也是一个二分类问题,事实表明,只要特征提取准确,使用逻辑回归模型也能达到很好的效果,并且简单高效容易理解。

本文调用了R语言中的广义线性模型GLM进行模型训练和预测。在阈值的选择问题上,常见的是通过ROC(Receiver Operating Characteristic)曲线或者PRC(precision-recall curve)曲线确定阈值。ROC曲线可以在正负样本分布变换的时候保持曲线不变,但是ROC曲线关注的准确率,与本赛题F1-Score最大的目标不相符。PRC曲线关注的是F1-score,准确率和召回率越接近,对应的F1-score最大,但在样本分布极不均衡的情况下,PRC曲线无法很好反映出分类器的性能。最终,本文使用网格搜索方法确定分类阈值。本文利用决赛数据,对逻辑回归模型的表现进行了回溯,模型在训练集和测试集上的表现如图3.4。按照官方标准,其在测试集的总得分是0.693049243。
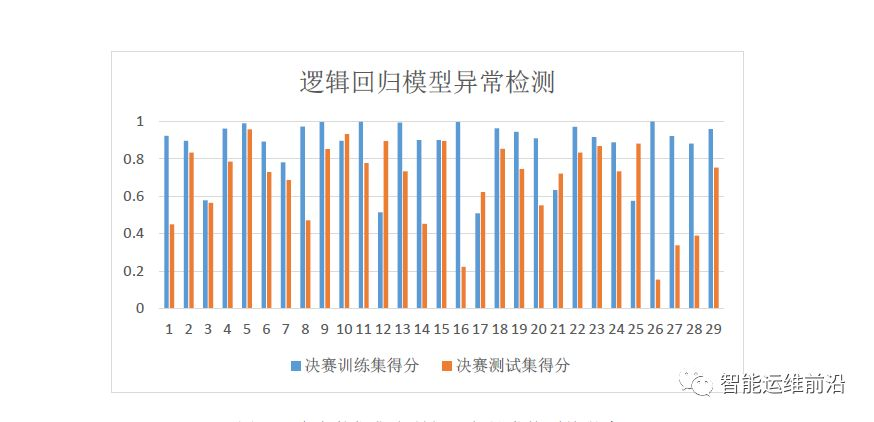
图3.4 决赛数据集上逻辑回归异常检测的得分
3.5 基于小波分析的异常检测
小波分析在信号处理、图像压缩、模式识别等非线性科学领域得到了广泛的应用。在时间序列研究中,主要用于消噪和滤波,并能将序列数据在常规尺度上无法被观测到的特征体现出来。与傅里叶分析不同,小波分析具有时-频多分辨率分析的功能。基于此,本文通过离散小波变换(DWT)将原始KPI序列分解成多个信号序列,并对分解后的序列进行重建。如图3.5a,对原始序列进行5级小波分解,左边为低频信号(近似部分),右边高频信号(细节部分)。
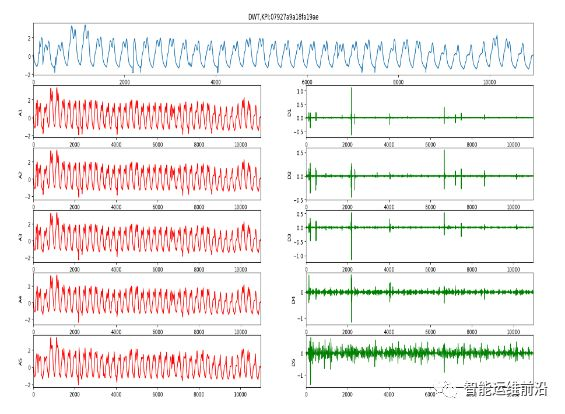
图3.5.a 小波5级分解
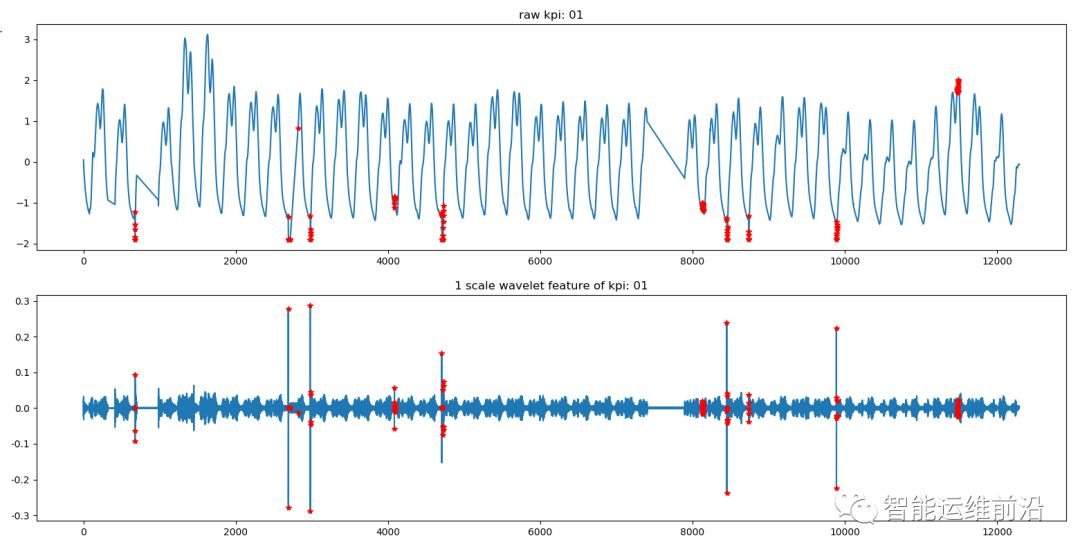
图3.5.b 小波分解异常点分布
从图3.5b中可以看出,异常点的分布在细节序列中分布较明显,异常点以较大概率落在了细节部分的高频成分。从而,可以将KPI时间序列的异常点检测转化为细节序列的异常点检测。
比赛要求实现的是KPI在线异常检测,因此本文通过选取合适时间窗,对时间窗内的数据进行小波分解和重构,提取细节部分序列,并采用Grubbs准则对时间窗内的异常点进行识别,如果当前时刻点在异常点集合中,就认为当前时刻检测异常。
在小波分析过程中,小波基函数、信号扩展模式、小波分解的层数以及时间窗的大小选择将会影响最终的异常检测效果。为此,本文在KPI训练中,以训练集得分最高为目标,通过网格搜索的方法对每条KPI提取最佳的小波分析参数,并用于在线检测。
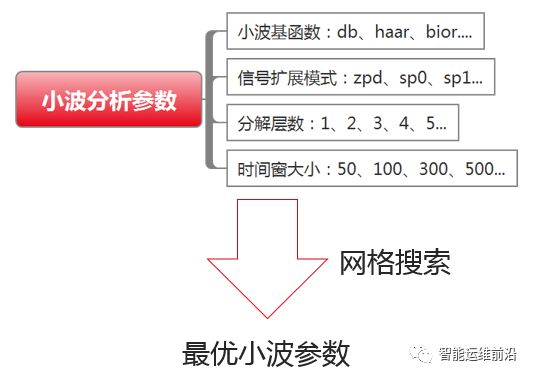
图3.6 小波分析参数优化
小波分析在决赛KPI的得分情况如图3.7,利用官方评分标准,小波分析在测试集上的总得分是0.649976063。从图中可以看出,小波分析在不同KPI上的表现各异。可见,小波分析并非对所有KPI都适用。
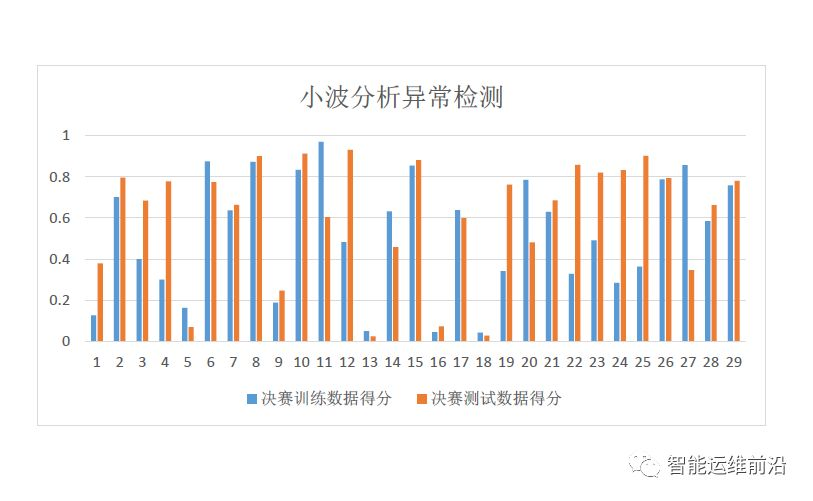
图3.7 决赛数据集上小波分析异常检测的得分
3.6 基于随机森林的异常检测算法
随机森林是一种组合分类器,其基本构成是决策树,不仅可以用于数据清洗,也可以拓展到分类与识别,并且能有效地解决数据不平衡问题。本文使用python提供随机森林分类器RandomForestClassifier进行异常点检测。数据输入源是由特征提取算法提取的部分特征,由于比赛时间限制,我们并没有对随机森林的树数目、最大深度、最大特征数进行过多的优化,随机森林还有很大的提升空间。
随机森林异常检测算法在决赛中的表现如图3.8,其在测试集上的总得分是0.701142416,该得分在四种基础算法中得分最高。
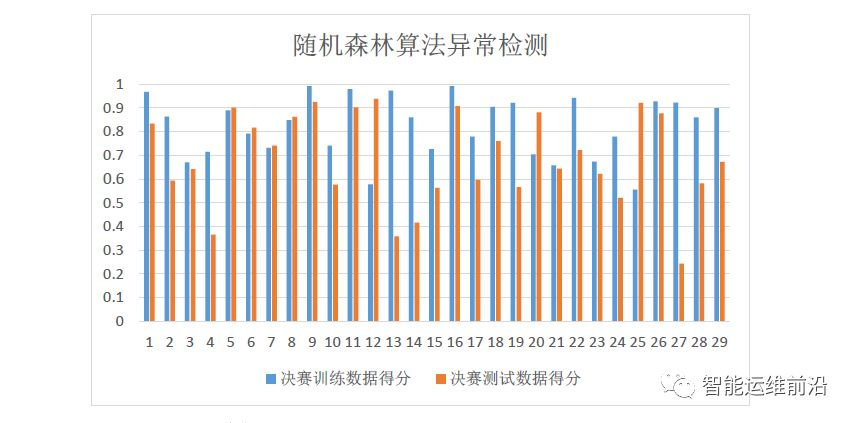
图3.8 决赛数据集上随机森林异常检测的得分
3.7 基于BiLSTM神经网络的异常检测算法
本文使用双向LSTM神经网络进行异常检测, LSTM是循环神经网络的一个优秀的变种,继承了大部分循环模型的特性,同时解决了梯度消失问题。神经网络可以自动学习特征与目标之间的关联关系,LSTM非常适合用于处理与时间序列高度相关的问题;
双向LSTM有更好的性能表现,我们使用其构建异常检测模型,难点在于超参数的有效选择,由于计算资源的问题,我们选择了人工优化方法,在数据覆盖较全的场景下训练和测试有较好的表现。
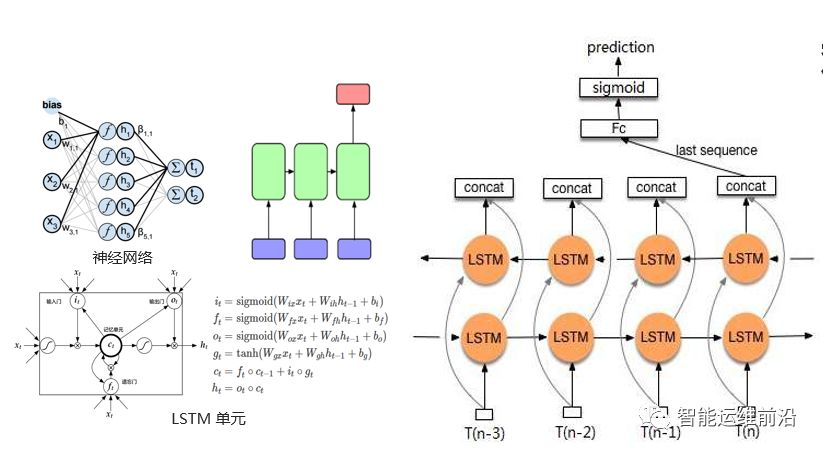
图3.9 BiLSTM神经网络结构
基于BiLSTM的神经网络算法在决赛中的表现如图3.9,其在决赛测试集上的总得分是0.691123881。
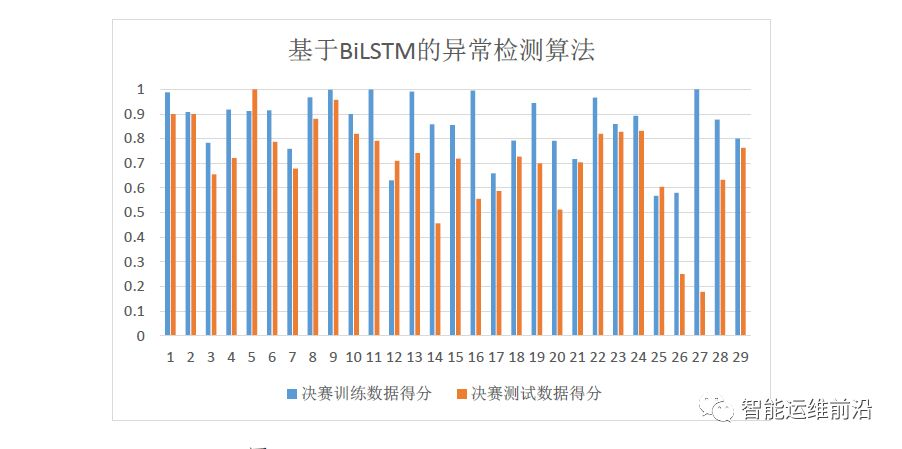
图3.9 决赛数据集上BiLSTM异常检测的得分
4.模型综合
以上四个模型在不同KPI上表现各异,为了获取更加准确的异常检测,本文采用加权投票模型对四个模型进行了综合。
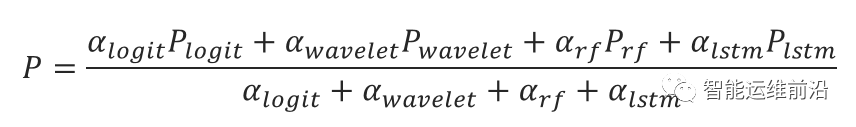
其中:
为各模型权重,取值0~1,为模型训练集得分
各模型异常检测结果,取值0或1
综合预测结果,如果P<0.5,则预测正常,否则异常
对于权重确认,分两种情形考虑:
(1)存在得分大于0.5的模型的条件下,若某个模型的训练集得分小于0.5,则对应的权重置为0
(2)若所有模型的得分小于0.5,则取4个模型中得分最高的作为预测模型,对应的其他模型的权重置为0
回溯决赛结果,四个模型的单模型得分都在00.64~0.66,但是综合得分却达到了0.771397,可见,模型综合取得了一定的成效,能显著减少误判。
表4.1 模型得分对比

本文在进行大量异常检测模型尝试后,最终选择了逻辑回归模型、小波分析模型、随机森林模型和双向LSTM神经网络模型这四种模型进行初步的异常检测,由于KPI的多样性,这四种模型的表现不一,最终我们使用综合加权方法对四个模型进行集成,从结果看,模型的集成取得了显著的效果。KPI异常检测模型多种多样,在实际应用场景中,很难找到或者开发出一种普适的异常检测解决方案,因而,本文综合了当前效果较好的异常检测方法,得到了一种比较通用的异常检测方案。
本检测模型的各子模型也可以单独工作或协作工作,亦可以可插拔方式增加或减少;另外比赛时间有限,很多工作还未完全展开,本检测模型还有不少提升潜力,如通过自动化进行特征优选,通过神经网络优化选择超参数等进而优化模型,通过改进模型集成策略优化集成表现。