

1.动机 2.持久化3.效率 4.生产者4.1负载均衡 4.2异步发送 5.消费者 Push vs. Pull 消费者位置 离线数据加载

1.动机
kafka被设计为能扮演一个大公司可能需要的处理所有实时数据流的统一平台。为了达成这个目的,我们必须考虑相当广泛的用例。
-
它必须有很高的吞吐量,以便能支持高容量的事件流,比如实时日志聚合;
-
它必须能优雅的处理大数据积压,能支持从离线系统定期加载数据;
-
系统必须能低延迟发布消息;
-
我们要它能分区,分布式,实时处理流(这激发了我们的分区和消费者模式);
-
最后,在将流发送到其他数据系统进行服务的情况下,系统必须在机器故障时能保证容错。
支持这些用途,会让我们设计有许多独一无二的元素,而不是一个传统的消息系统。我们将在以下部分概述kafka设计的一些元素。
2.持久化
不要恐惧文件系统!
kafka严重依赖文件系统存储消息和缓存消息。大家普遍认为"磁盘速度很慢",从而让人们怀疑持久化结构能否提供有竞争力的性能。实际上,磁盘可以比人们预期的更慢,也可以比人们预期的更快,这完全取决于如何使用。合理的磁盘结构设计,能够让它和网络一样快。
磁盘性能关键因素就是硬盘的吞吐量在过去十年磁盘寻道延迟。结果表明线性写入一个6块7200rpm的SATA组成的RAID-5阵列的JBOD配置,能够达到600MB/秒。然而 随机写入的话性能只有100K/秒。性能相差6000倍。
线性读写大部分情况可预测,并且操作系统有针对性的优化。现代操作系统提供了 预读(read-ahead)和后写(write-behind)技术,即块倍数预读取数据,并且合并非常小的逻辑写为一个大的物理写。这个问题更深入的讨论可以参考ACM Queue article:https://queue.acm.org/detail.cfm?id=1563874,结论是:顺序写磁盘的速度在某些情况下比随机写内存的速度更快。
为了补偿性能差异,现代操作系统越来越积极的使用主内存进行磁盘缓存。现在操作系统非常乐意将所有可用内存用来磁盘缓存,内存回收时,几乎没有性能损失,所有磁盘的读和写将全部通过统一的内存。如果不使用直接I/O,这个特性不能轻易的关闭。因此,即使一个进程维护了进程内数据缓存,数据还是可能被复制到操作系统的pagecache,所有内存都会存储两次。
此外,kafka运行在JVM上,任何对Java内存有一定了解的用户知道两件事情:
-
对象的内存开销非常高,通常会使存储的数据大小翻倍(或更糟)。
-
随着堆内数据的增加,Java垃圾收集变得越来越频繁和缓慢。
由于这些因素,使用文件系统并依赖pagecache优于维护内存缓存或者其他结构--我们通过自动访问所有可用内存,至少要加倍可用内存。并且可能由于要存储压缩字节结构而不是分离的对象,需要再次加倍可用内存。
这样做以后,将在32G的服务器上产生28~30G的缓存。此外,即使业务进程重启,高速缓存任然是热的。但是进程内缓存将需要在进程内重建(10G的数据大概需要花10分钟),否则它将以完全冷缓存启动(这意味着初始性能非常糟糕)。
这将极大的简化了代码,因为维护高速缓存和文件系统一致性的所有逻辑全部都在操作系统中。如果你对磁盘使用有利于线性读取,那么预读将非常高效的预填充每次磁盘读取的数据到缓存中。
这表明一个非常简单的设计:不要恐慌性的在内存中维护尽可能多数据并将其全部刷到文件系统。我们应该反其道而行之,所有数据应该立即写到文件系统的持久化日志,而不需要刷到磁盘。实际上,这只意味着它被转移到操作系统内核的pagecache中。
这种以pagecache为中心的设计风格在一篇关于Varnish的设计中有描述过。可以戳链接http://varnish-cache.org/wiki/ArchitectNotes了解更多。
Varnish是一款高性能的开源HTTP加速器,淘宝曾经和拼多多现在都有使用这个开源技术来应对庞大的流量。
满足常量时间
消息系统中使用到的持久化数据结构通常是每个消费者队列关联一个BTree或者其他通用的随机访问数据结构,用来维护消息元数据。
BTree是最通用的数据结构,并且能在消息系统中广泛的支持事务性或者非事务性语义。BTree操作复杂度是O(log N),被认为基本上等价于常量时间。
但是对磁盘操作则不然,磁盘每次操作大概要10ms,并且每个磁盘在同一时刻只能做一个寻址,所以并行化非常受到限制。因此,即使非常少量的磁盘搜索也会导致非常高的开销。
由于存储系统混合了非常高速缓存操作与非常低效的磁盘操作,因此高速缓存固定的情况下随着数据的增长,数据结构的性能通常是超线性的。即,数据加倍,会使性能衰退到原来的1/2。
直观地,可以在简单读取上构建持久队列,并将其附加到文件,这与日志记录解决方案的情况一样。这种结构有所有操作时间复杂度是O(1)的优势。读不会阻塞写,写也不会阻塞读。这就有了一个性能完全与数据尺寸分离的优势,即不会随着数据量的增加而导致性能衰减。服务器就能利用很多便宜的,低转速的硬盘。尽管它们的寻址性能很差,但是磁盘在大量的读写时性能是可接受的,只需要花1/3的钱,就能得到3倍的能力。
在没有任何性能损失的前提下,访问几乎无限制的磁盘空间,这意味着我们能提供消息系统通常不具备的功能。例如,在kafka中,我们并不是在消息被消费后就尝试删除消息,而是能保留消息一段很长的时间(例如一周),正如我们将要描述的那样,为消费者带来极大的灵活性。
3.效率
我们尽最大努力在效率上,一个我们主要的用户场景就是处理web活动数据,那是非常海量的数据量。每次页面浏览可能生成十多条消息。此外,我们假设每条投递的消息至少会有一个消息者(通常会有多个),因此我们努力使消费者尽可能的高效。
前一段我们讨论了磁盘效率,糟糕的磁盘访问模式,这类系统效率低下主要有两个原因:很多的小I/O操作,过多的字节拷贝。小I/O问题发生在客户端和服务端,以及服务器本身的持久化操作中。
为了避免这个问题,我们的协议围绕着"消息集合"抽象构建的,很自然的把消息组合到一起。这就允许网络请求把消息组合到一起,分摊网络来回的开销,而不是每次发送一条单独的消息。服务器依次把消息块追加到它的日志中。然后消费者每次抓取大的线性消息块。
这个简单的优化产生了不可思议的数量级速度提升。批量就会导致更大的网络包,更大的顺序磁盘操作等等。所有这些都将允许Kafka将突发的随机消息写入流转换为流向消费者的线性写入。
另一个低效率是字节拷贝。在低消息速率这不是问题,但是在有负载的情况下这影响是显著的。为了避免这个问题,我们制定了一个在生产者,broker和消费者之间共享的标准的二进制消息格式,如此一来数据块在它们中间传输不需要任何修改。
消息日志被broker维护,其本身只是一个文件目录。每个文件都由一系列消息集合填充,且这些消息已经被写入磁盘,并且和生产者和消费者使用的相同的格式。维护这个通用格式可以允许最重要操作的优化:持久化日志块的网络传输。现代的unix操作系统提供了一个高度优化的从pagecache传输数据到socket的代码路径。在Linux系统中,这是通过sendfile系统调用完成的。
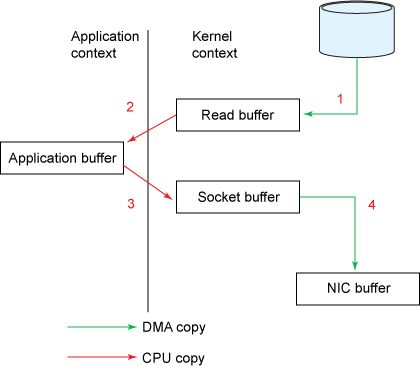
为了理解sendfile的影响,需要先重点了解通用的数据从文件到socket的传输路径:
-
操作系统将磁盘中的数据读入内核空间的pagecache;
-
应用程序将内核空间中的数据读入用户空间缓冲区;
-
应用程序将数据写回内核空间中的套接字缓冲区;
-
操作系统将数据从套接字缓冲区复制到NIC缓冲区,并通过网络发送。
很显然,这样做效率不高。总计有4次拷贝和2次系统调用。然而用sendfile,允许操作系统将数据从pagecache直接发送到网络,从而避免了re-copying。因此在这个优化的路径中,只有最后的拷贝到NIC缓冲区是必须的。
我们期望一种普通的用例,一个topic多个消费者。使用zero-copy优化后,数据只被拷贝到pagecache一次,能够在每次消费时被重用。从而不需要存储在内存中,然后每次读取的时候,拷贝到用户空间。这就允许消息以接近网络连接限制的速率被消费。
zero-copy优化前后效果图:
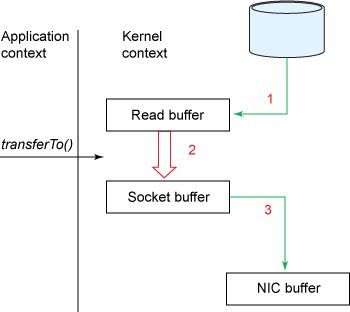
pagecache和sendfile的组合,意味着kafka集群在消费者频繁追赶的时候,看不到磁盘上行任何读取活动,因为它们将完全从缓存提供数据。
更多java中支持的sendfile和zero-copy(零拷贝),请参考文章:https://www.ibm.com/developerworks/linux/library/j-zerocopy/
端到端的批量压缩
在一些场景下,瓶颈实际上不是CPU或者磁盘,而是网络带宽。尤其需要在广域网下的两个数据中心之间发送消息的数据管道。当然,用户能每次压缩他的消息,而不需要kafka的支持。但是这就导致非常差的压缩率,因为大部分冗余是由于相同类型的消息之间的重复(例如,JSON中的字段名称)。
高效的压缩需要压缩多条消息在一起而不是独立的压缩每条消息。
kafka以一个高效的批量格式支持此功能。将一批消息捆绑到一起压缩,然后以这种压缩格式发送到kafka服务器。批量消息就以压缩格式保存在日志中,并且只能被消费者解压。
kafka支持GZIP,Snappy和LZ4这三种压缩协议。
4.生产者
4.1负载均衡
消费者直接发送数据到broker上分区的leader,不需要任何中间路由层。为了让生产者做到这点,所有kafka节点都能回答一个关于哪些broker是存活的,以及topic分区的leader在哪里的元数据请求。
客户端控制发布消息到哪个分区。可以随机(一种随机负载均衡实现),也可以是一些特定分区。kafka暴露了接口允许用户指定消息的key从而指定特定分区(kafka对这个key进行hash然后对分区数取模从而得到目标分区)。例如如果key是一个userId,那么这个用户所有的消息数据都被发送到同一个分区。
这将允许消费者对其消费做出地点假设。 这种分区方式明确设计为允许在消费者中进行对位置敏感的处理。
4.2异步发送
批处理是效率的重要驱动因素之一。kafka生产者试图把数据积累在缓存中,然后每次请求发送更大的批量。批处理能被配置为两种方式:消息不超过一定数量,例如16k。不允许等待超过时间延迟限制,例如100ms。 这种缓冲方式可配置提供了一种机制来权衡少量的额外延迟以获得更好的吞吐量(低延迟和高吞吐量之间的平衡)。
5.消费者
kafka消费者通过向broker发送抓取(fetch)请求导向它要消费的位置。消费者在每个请求中指定了日志的offset,然后接收从这个位置开始的一块日志。消费者可以控制这个位置,如果有需要,它能倒回去重新消费已经消费过的日志。
Push vs. Pull
我们考虑的一个最初问题就是消费者是应该从broker拉取数据,还是broker应该把数据推送给消费者。在这一方面,kafka遵循一个更传统的设计,生产者把数据推送到broker,然后消费者从broker拉取数据。
一些以日志为中心的系统,比如Scribe和Apache Flume,遵循一个完全不同的基于Push模式,数据被推送到下游。两种方式都有利弊。
然而,基于Push的系统,由于broker控制数据传输的速率,所以比较难处理各种不同的消费者。我们的目标一般是消费者能以最大可能的速率消费,不幸的是,在一个Push系统中,这就意味者当消费者消费的速度跟不上生产速度时,消费者会不堪重负。
基于Pull的系统有更好的特性,消费者可以落后,又可能会追上。可以通过某种退避协议来缓解。通过这种协议,消费者能表明它已经超负荷。但是传输速率只会充分使用,而不会过分使用。以前以这种方式构建系统的尝试让我们采用了更传统的Pull模式。
基于Pull的系统另一个优点是系统可以尽可能的批量发送数据到消费者。基于Push的系统必须选择立即发送请求,并且在不能感知下游消费者是否能马上处理的情况下发送。
如果倾向于低延迟的调整,这将导致每次只能发送单条消息,这非常浪费。一个基于Pull的设计就没有这个问题,因为消费者总是拉取日志中当前位置后所有有效的消息(或者可能收到配置的最大拉取大小的限制,比如1k),因此可以在不引入不必要的延迟的情况下得到最佳的批处理。
基于Pull系统的不足就是如果broker没有数据,消费者可能在循环中终止轮询,实际上消费者是在忙着等待数据到来。为了避免这个问题,kafka的poll请求中有参数允许消费者请求时在长轮询中阻塞,等待直到broker中有数据到来(并且可选的支持等待直到给定数量字节可用,确保大的传输数据大小)。
你能想象其他可能的设计,只是拉取,端到端,生产者将在本地写入日志,broker从这里拉取数据,然后消费者又从broker那里拉取数据。类似存储转发(store-and-forward)类型的生产者。这是非常有趣的设计,但是我们决定不适合我们的有上千个生产者的使用场景。
我们大规模运行持久化数据系统的经验使我们感到,在许多应用中涉及系统中成千上万的磁盘不会使事情更可靠,相反可能是维护的噩梦。实际上,我们发现我们可以大规模运行具有很强SLA的pipeline,无需生产者持久性。
消费者位置
令人惊讶的是,保持跟踪已经消费的数据,是一个消息系统的关键性能点之一。许多消息系统在broker上保留了什么消息已经被消费的元数据。当消息传到消费者时,broker要么立即记录,要么等待消费者的确认。实际上对于单台服务器来说,确实不清楚这个状态可能去哪里,由于在消息系统中,用于存储这个信息的数据结构很小,这也是一个务实的选择----broker知道什么数据被消费了,它能立即删除它,从而保持数据量小。
可能并不明显的是,让broker和消费者就所消费的内容达成一致,并不是一个微不足道的问题。如果broker在每次通过网络分发消息时,就记录消息为已消费,那么如果消费者未能成功处理消息(消费者崩溃或者请求超时等原因),那么消息可能会丢失。
为了解决这个问题,需要消息系统增加了确认机制,例如ActiveMQ。这就意味着消息被发送后,只被标记已发送未消费。broker等待消费者把消息标记为已消费的确认。这个机制修复了消息丢失的问题,但是引入了新的问题。首先,消费者处理消息后但在发送确认前出错,那么消息将会被消费两次。第二个问题与性能有关,broker必须保持每条消息的多种状态。所以必须处理棘手的问题,例如如何处理已发送但从未确认的消息。
kafka处理这种问题的方式完全不同。我们的topic被分离成有序分区集合。任何给定时间,每个分区只被订阅这个topic的消费者组里的一个消费者消费。这就意味着,消费者在每个分区的位置只是一个整数,即下一次消费的消息的偏移量。这就使得已经被消费的状态非常小,每个分区只有一个数字,还可以定期检查这个状态。这就使得和消息确认机制等价机制非常低成本。
这个决定有一个另外的好处,消费者能故意回退到一个旧的offset重新消费。这违反了队列的通用性质,但是却成为许多消费者必不可少的特征。例如,如果在消息被消费后,发现消费者的代码有一个BUG,消费者就可以在BUG被消费者马上重新消费这些消息。
离线数据加载
例如批量数据加载,周期性地将数据加载到离线系统(如Hadoop或关系数据仓库)中。
在Hadoop的情况下,我们通过将负载分配到各个映射任务来并行化数据负载,每个节点/主题/分区组合一个,允许加载中的完全并行。 Hadoop提供任务管理,失败的任务可以在没有重复数据危险的情况下重新启动 - 它们只是从原始位置重新启动。
如果读完觉得有收获的话,欢迎点赞、关注、加公众号【匠心零度】,查阅更多精彩历史!!!

