

上一篇文章简单介绍了多数据源和动态数据源使用上的一些小心得,本文接着介绍一个实际业务操作中经常遇见的场景——分库分表。随着现在软件系统功能的不断丰富,庞大的用户群体及用户随之带来的各种各样的海量数据给数据库增添了巨大的压力。举个很简单的例子,很多C端产品的用户订单数量随着系统运行时间的推移其数量将呈几何式的增长。这样当我们按照某些条件去搜索订单的时候查询效率势必会很低,或许在高频搜索字段建立索引可以一定程度上缓解这种现象。但是这并不能够在本质解决这个问题而且建立索引所带来的时间成本和存储成本也并不“低廉”。
一种解决的此类问题的技术方案——分库分表便应由而生,其实现在市面上有多种多样的中间件可以进行选择。比较著名的中间件包括:MyCat、Cobar和MySQL Router等,这些中间件大家可以到对应的官方网站或者社区查看详细。今天要特别介绍的是一款轻量级的分表分库工具--Sharding JDBC,与其他几款相比它具有项目入侵性低、部署简单的明显优势。作者是在一个已经成熟运行的系统上进行分库分表的改造,所以项目入侵性低是我选择它的一个很重要因素。毕竟为了使用一个工具而去重构以往大量的代码是一件并不轻松且得不偿失的事情。
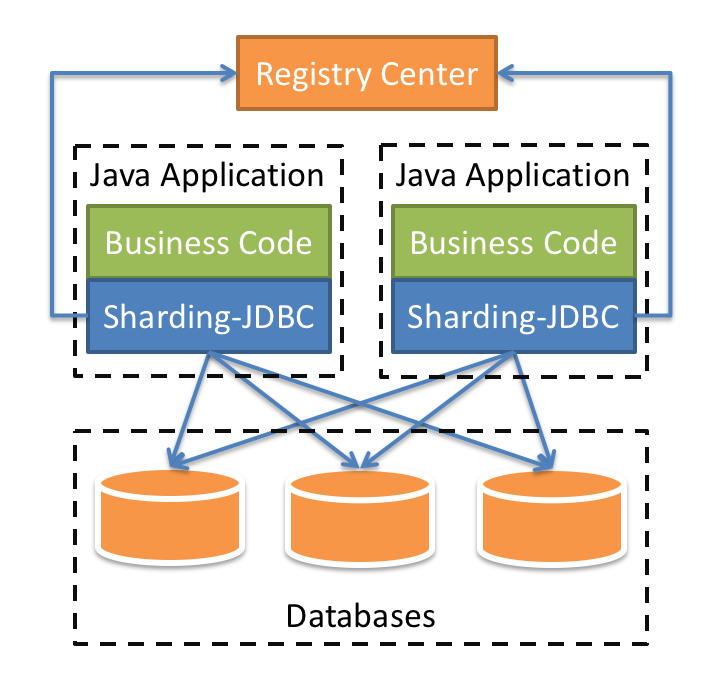
数据源配置
@Bean(name = "crmDataSource")
@Primary
public DataSource datasource() throws SQLException {
//配置数据分片规则
ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration();
shardingRuleConfig.getTableRuleConfigs().add(orderTableRuleConfiguration());
shardingRuleConfig.getTableRuleConfigs().add(orderItemTableRuleConfiguration());
shardingRuleConfig.getBindingTableGroups().add("t_order, t_order_item");
//根据用户编号将不同用户的订单信息路由到两个数据库中
shardingRuleConfig.setDefaultDatabaseShardingStrategyConfig(new InlineShardingStrategyConfiguration("user_id", "ds${user_id % 2}"));
//在根据订单编号将订单信信路由到子表中
shardingRuleConfig.setDefaultTableShardingStrategyConfig(new StandardShardingStrategyConfiguration("order_id", new TableShardingAlgorithm());
return ShardingDataSourceFactory.createDataSource(createDataSourceMap(), shardingRuleConfig);
}
//订单表分表
TableRuleConfiguration orderRuleConfiguration() {
TableRuleConfiguration result = new TableRuleConfiguration();
result.setLogicTable("t_order");
result.setActualDataNodes("ds${0..1}.t_order${0..4}");
result.setKeyGeneratorColumnName("order_id");
return result;
}
//订单详情分表
TableRuleConfiguration orderItemRuleConfiguration() {
TableRuleConfiguration result = new TableRuleConfiguration();
result.setLogicTable("t_order_item");
result.setActualDataNodes("ds${0..1}.t_order_item${0..4}");
return result;
}
//数据源集合配置
Map<String, DataSource> createDataSourceMap() {
//使用atomikos进行分布式事务管理
//第一个数据源
MysqlXADataSource mysqlXADataSource=new MysqlXADataSource();
mysqlXADataSource.setUrl(db0Url);
mysqlXADataSource.setPassword(password);
mysqlXADataSource.setUser(userName);
mysqlXADataSource.setPinGlobalTxToPhysicalConnection(true);
AtomikosDataSourceBean dataSource=new AtomikosDataSourceBean();
dataSource.setXaDataSource(mysqlXADataSource);
dataSource.setUniqueResourceName("ds0");
dataSource.setMaxPoolSize(30);
dataSource.setMinPoolSize(5);
...
//第n个数据源,配置模板同上略
//组合成一个数据源映射集合
Map<String, DataSource> dataSourceMap = new HashMap<>();
dataSourceMap.put("ds0",dataSource1);
dataSourceMap.put("ds1",dataSource2);
...
return datasourceMap;
}
还记得上篇文章介绍的分布式事务么,这里由于对数据表进行了分库操作。所以需要使用XADataSource进行数据源的初始化才能进行有效的事务管理。在分库分表操作中分为数据库的路由和数据表的路由,需要分别进行明确的指定(这里专业性术语叫做数据分片规则的制定)。正如上图所示,JDBC会在打开数据库连接进行操作时确定对哪个数据库的哪张表进行操作。而我们需要做的就是制定这个规则,然后剩下的事情就可以放心的交给Sharding-JDBC去完成了。例如,我们将订单表t_order拆分为10个子表,然后将这十个子表又均匀的散布在ds0和ds1两个数据库中;订单都有所属的用户,如果我们对所属的用户编号进行取模然后根据余数映射到相应的数据库中,再根据订单编号进行取模后将数据映射到相应的数据表中;经过这样两重的筛选,就是一个最为简单而又高效的数据分片规则。上文所示的代码正是按照这一规则进行处理的,本来百万级的订单处理就可以降级为十万级的订单处理,这样在最终数据库操作上都可以大大的提升效率。
分表策略配置
public class TableShardingAlgorithm implements PreciseShardingAlgorithm<Long> {
@Override
public String doSharding(Collection<String> tableNames, PreciseShardingValue<Long> shardingValue) {
//符合分片条件的进行逻辑表名替换
for (String each : tableNames) {
if (each.endsWith(shardingValue.getValue() % 5 + "")) {
return each;
}
}
//否则直接使用表名
return shardingValue.getLogicTableName();
}
}
在数据库中其实并不存在t_order这张逻辑表,我们真正创建的是ds0.t_order0-4,ds1.t_order0-4这10张表,通过
//偶数编号的用户所属的订单进入数据库0,奇数进入数据库1
new InlineShardingStrategyConfiguration("user_id", "ds${user_id % 2}")
//每个数据库中的订单又分别按照订单号存储在对应的子表中
setActualDataNodes("ds${0..1}.t_order${0..4}");
这样在数据库执行操作的时候就告诉了JDBC一个逻辑表替换为实际表的一个可选范围,这样就保证了操作在一个合理的界限内而不会发生错误。在找不到可替换的表时就直接返回表名,这样对于一个数据库中如果既存在需要分表的部分又存在不需要分表的部分就可以实现兼容。
配置起来是不是很简单,这也真正符合标题轻量化的要求,它不需要像Mycat等重量级的数据库中间件还需要一台专门的中间件服务器进行配合。只需要通过Maven将相对应的依赖通过jar包的方式进行引入就可以便捷的开启分库分表的功能,对于SpringBoot项目也有很好的支持。其实Sharding Sphere不仅仅提供了分库分表的功能,它还有诸如:读写分离、数据治理和柔性事务等多样的数据服务(详细可异步官网进行查看:shardingsphere.io)。本文仅入门性质的介绍了其部分功能,其余更加丰富的特性还有待读者自行学习,感谢您的阅读!
