

首先放上波波老师的《算法与数据结构》这门课程地址:coding.imooc.com/class/71.ht… 诚心推荐。
当我们在解决一个问题的时候,通常分两步:第一步是解决这个问题,第二步是如何更好的解决这个问题。第二步就是在第一步的基础上看看原先使用的方法,有没有改进或者优化的地方,或者有没有更好的方法解决问题。对于解决排序问题,上一章主要介绍了时间复杂度为O(n^2)级别的基础排序算法,选择排序,插入排序,以及冒泡排序,这是解决问题的第一步。这三种排序算法都能解决排序的问题,但也存在不足,效率太低了,我们前面的数据量只有8个元素,在计算机上很快就会有结果,或许只有几纳秒,但是当数据量是百万或者千万级别的时候,因为时间复杂度为O(n^2),要经历两次遍历,那么百万或者千万级别的数据倍乘起来的时间的消耗将是巨大的。那么在大的数据量上,使用这三种排序算法的时间是多少呢?准备一个测试用例分别计算这三种排序算法在1百万数据量上的性能。
算法性能测试
下面这个函数的作用是创建一个随机的待排序的数组,数组内的元素类型为int,元素的取值范围为[rangeL,rangeR],元素个数为n。
int *generateRandomArray(int n, int rangeL, int rangeR){
int *arr = new int[n];
srand(time(NULL));
for (int i = 0; i < n; i++) {
arr[i] = rand() % (rangeR - rangeL + 1) + rangeL;
}
return arr;
}
下面这个函数是判断数组内的元素是否是有序,测试时设定的有序是从小到大的排列。基本逻辑循环遍历这个数组,如果遍历到当前元素比后一个元素大的话,说明这个数组不是有序的,返回false。
template <typename S>
bool isSorted(S arr[],int n){
for (int i = 0; i < n - 1; i++) {
if (arr[i] < arr[i+1]) {
return false;
}
}
return true;
}
下面这个函数为主要的测试函数,传入的第一个参数为一个字符串,使用时传入排序算法的名字,方便打印输出时查看。第二个参数是一个函数指针,这个函数的参数有两个,第一个是待排序的数组,第二个是数组元素的个数。后面两个参数为待排序数组和数组的个数,用于函数调用时传参。
template <typename T>
void testSort(string sortName,void(*sort)(T arr[], int i),S arr[],int i){
clock_t startTime = clock();
sort(arr,i);
clock_t endTime = clock();
assert(isSorted(arr, i));
cout<<sortName<<":"<< (double)(endTime - startTime) / CLOCKS_PER_SEC<<"s"<<endl;
}
整体逻辑在startTime 与 endTime中间调用排序函数,排序完成后调用isSorted()函数来测试数组的有序性,如果返回的false,则抛出异常。没问题就打印endTime与startTime两者时间的差值,单位是秒(s)。
接下来我们就来测试下这三个函数将100万个数排序所需要花费的时间,将上一章中写好的排序函数传入到测试函数中。
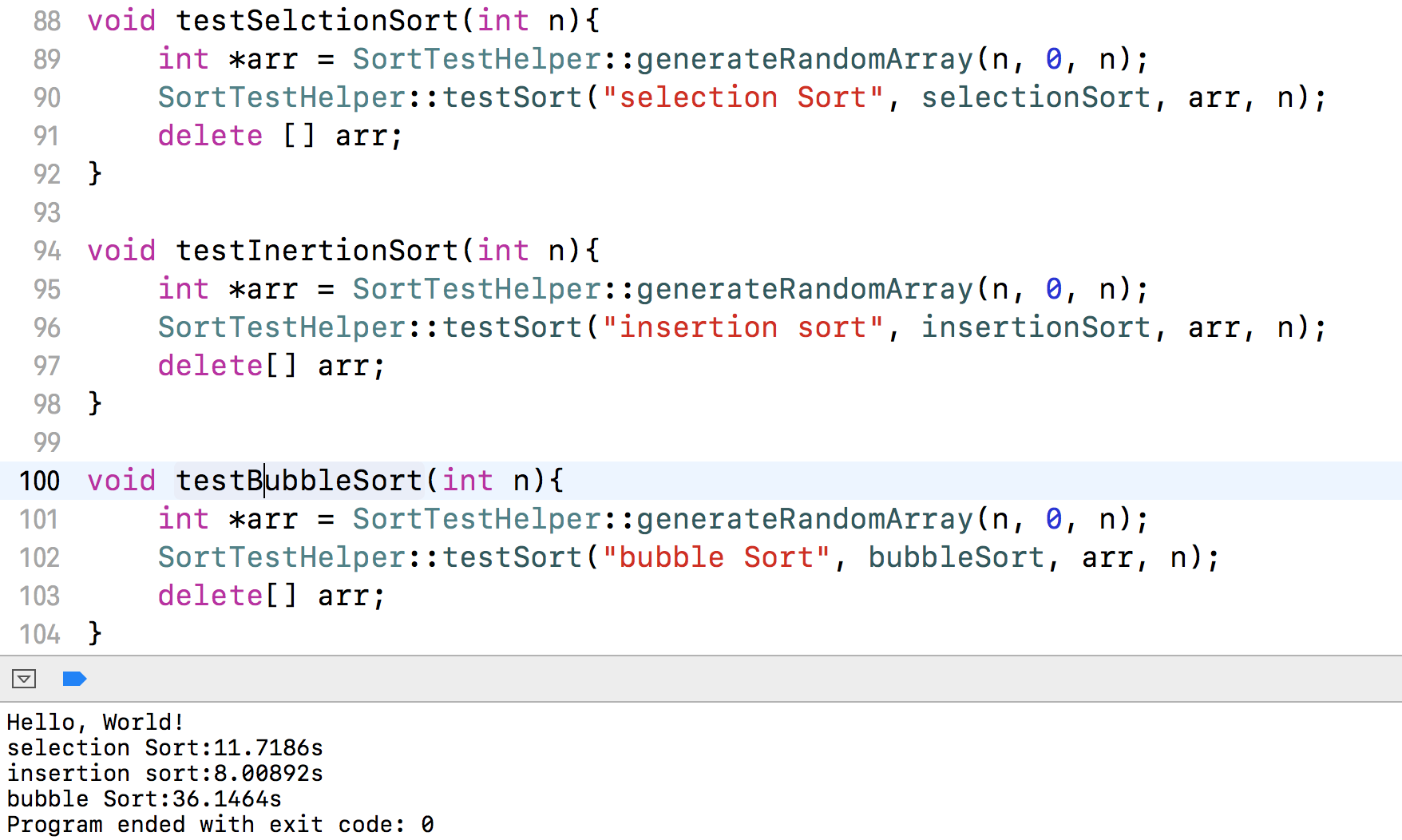
这里的传入的数组的个数n起初是传入1百万,但是运行后我等了好久好久还没出结果,我不知道要等到什么时候去。所以改为了10万。可以看到冒泡排序花费了36秒,比选择排序11.7秒和插入排序8秒要多的多。原因是因为排序时相邻元素进行了大量的两两交换操作,交换是需要时间的,所以比前面两种排序耗时。冒泡排序也有很多优化的地方,不过在这里不是重点,这里就不再赘述了。可以看到插入排序的时间最少,在实现插入排序时我们开辟了一个临时空间来保存将要排序的元素,避免了一些交换的操作。对这里不太理解的可以看我的上一篇文章:juejin.cn/post/684490… 在这篇文章中的关于插入排序的优化部分。当开辟更多的临时空间来辅助排序,以空间来换取时间,就成为了另一种考虑排序的方法了,在这种思考方向上就出现了归并排序和快速排序这两种时间复杂度为0(nlogn)的高级排序方法,本章主要介绍归并排序,在介绍之前先简单比较一下设计时间复杂度为O(nlogn)的算法比0(n^2)在时间上的优势。
O(nlogn)与0(n^2)在时间上的比较
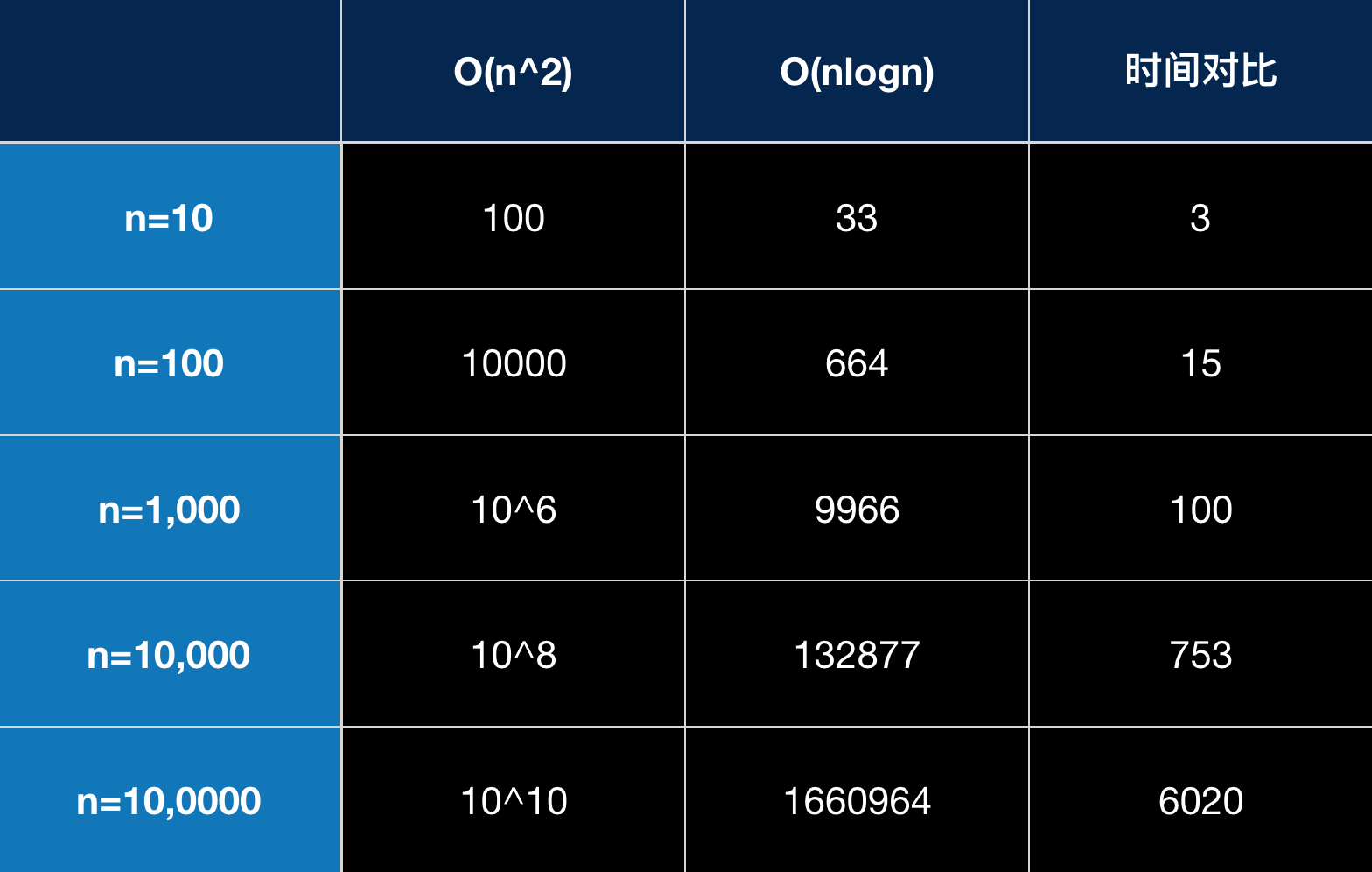
可以看出来,当n的取值不断增大,也就是数量级不断增大的时候,nlogn比n^2的运行速度的倍数,也就是图中的时间对比下的数字,变得越来越大,当n = 100000时,nlogn比n^2快了6020倍。打个比方,nlogn运行需要一天时间的话,那么n^2级别的算法就需要6020天,一年365天,17年后才能知道结果。如果数量级更大,时间上的差异会更明显。所以设计效率更高的排序算法就很有必要了。下面开始介绍效率更高的归并排序。
归并排序的实现思想
同样给定一组待排序的数组,8个元素。

归并排序的思想是先将这个数组分成2个部分,让这两个部分先单独排序。然后再将这两个部分归并起来。整个数组被分成了2部分,一部分为3,6,4,1,另一部分为 8,5,7,2。
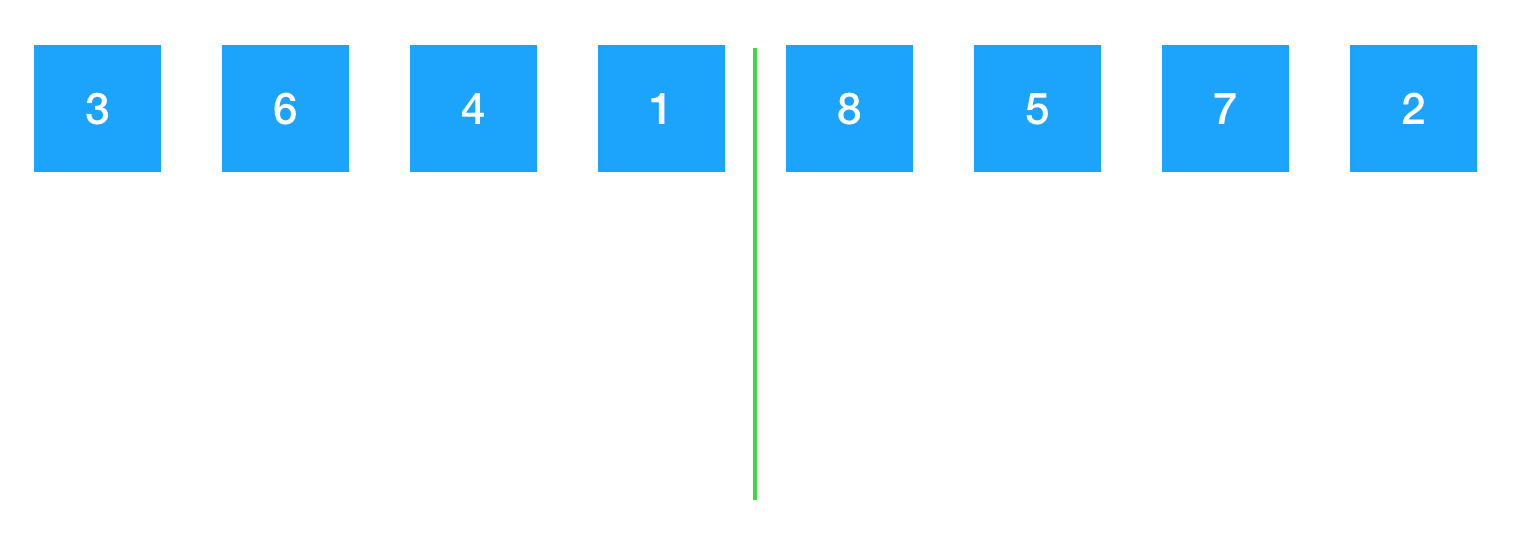
为了对这两个部分进行排序,又分别对这两个部分进行切割。
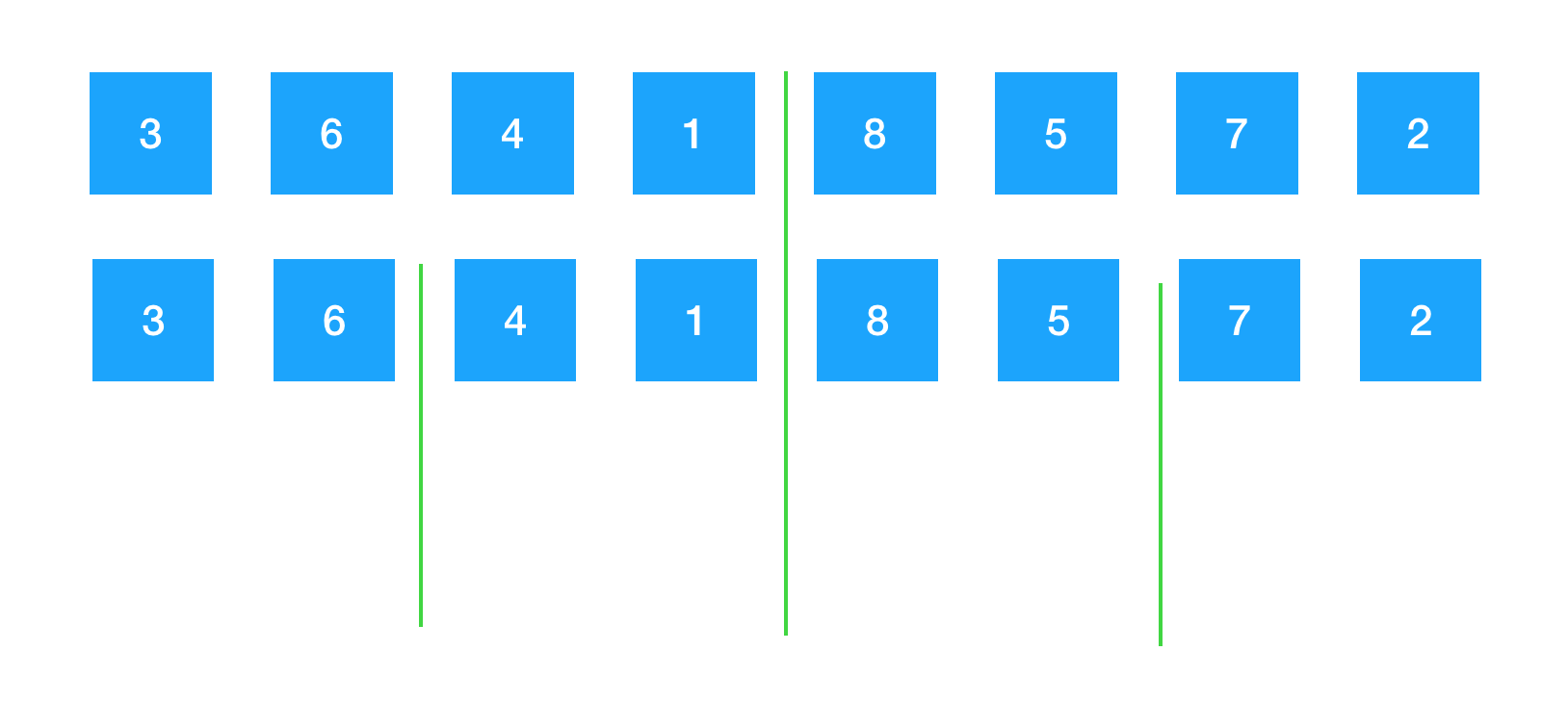
然后继续先切分,再进行归并。我们看到这个数组就被切分成一个一个单独的元素。每一个元素不用进行排序就是有序的了。切割好后,下一步就是从下往上进行归并。
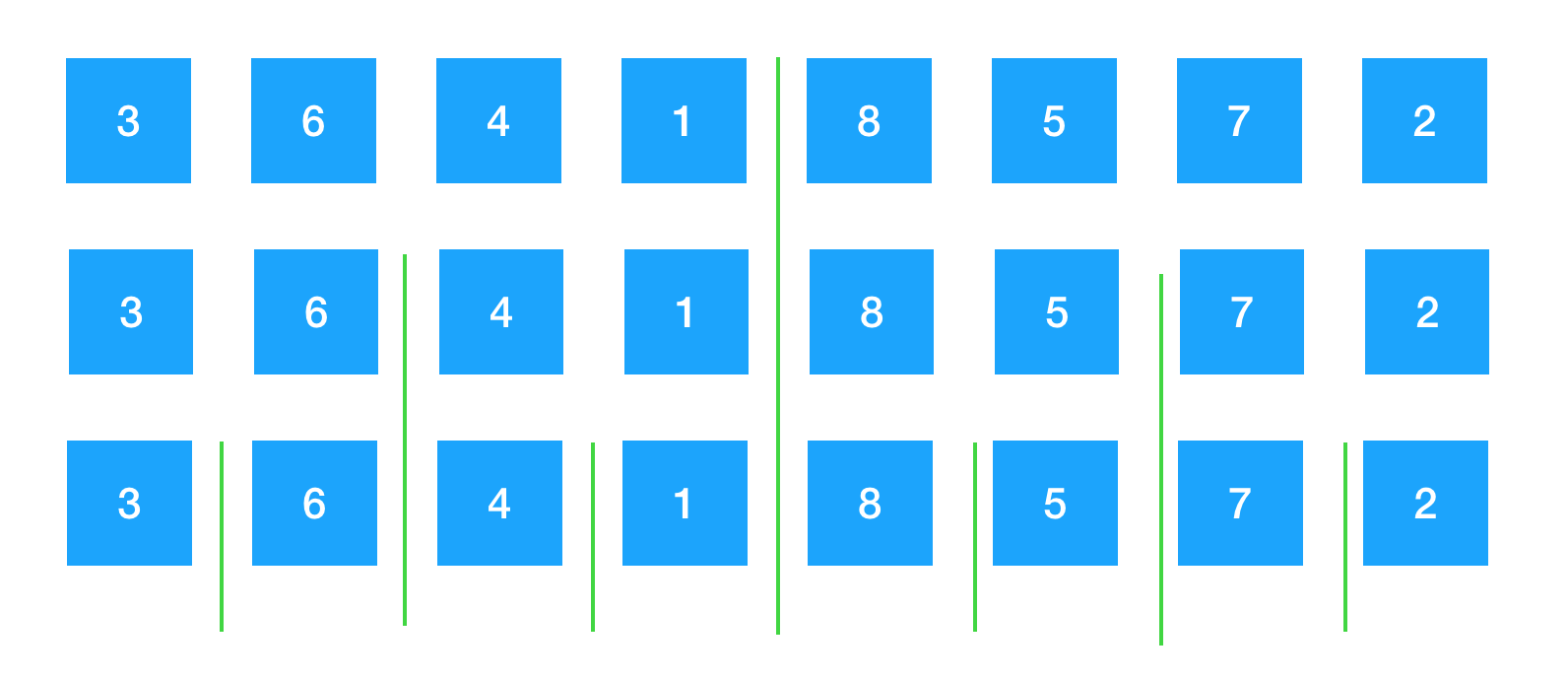
归并开始。 3 和 6 这两组数据归并成一组有序的数据,4 和 1 这两组数据归并成一组有序的数据,8 和 5 这两组数据归并成一组有序的数据,7 和 2 归并成一组有序的数据,图片红色部分代表每一个小部分归并完成。可以看到红色部分为下面蓝色中两组数据归并后变得有序了。
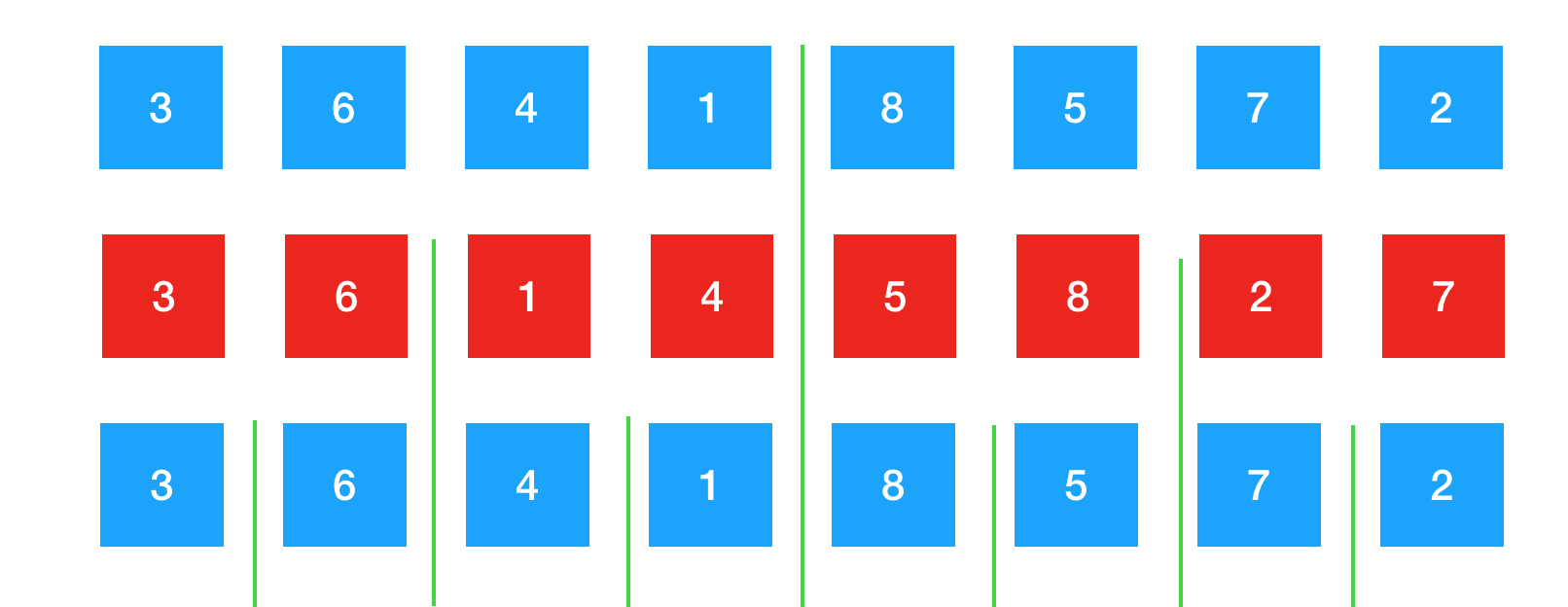
然后继续 3,6 与 1,4进行归并,5,8 与2,7进行归并,那么此时1,3,4,6归并完成,2,5,7,8归并完成
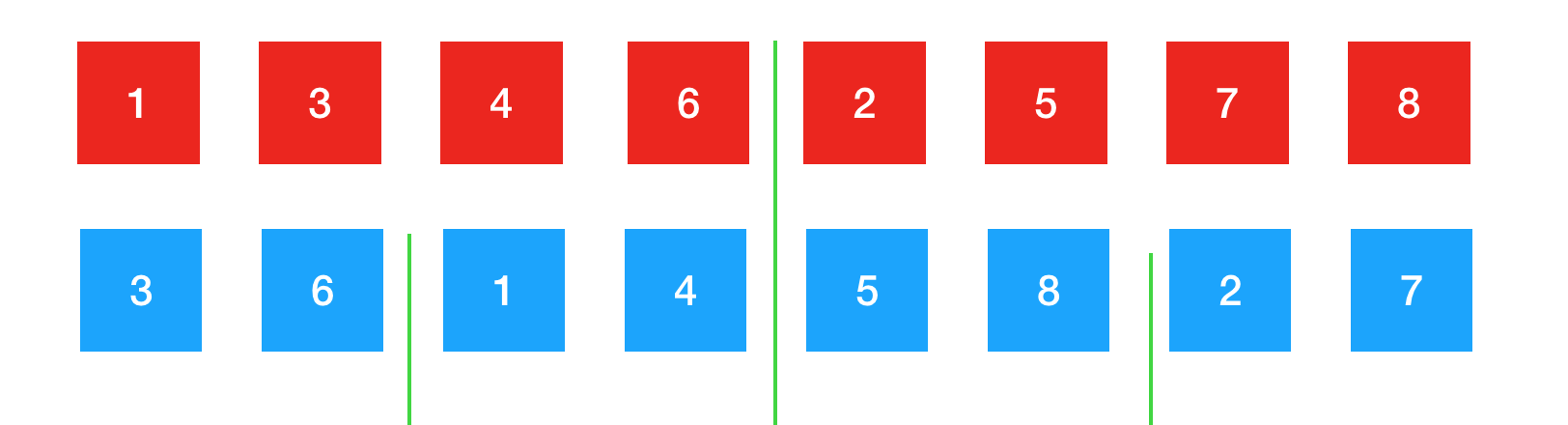
继续将这两个部分归并成一个整体。
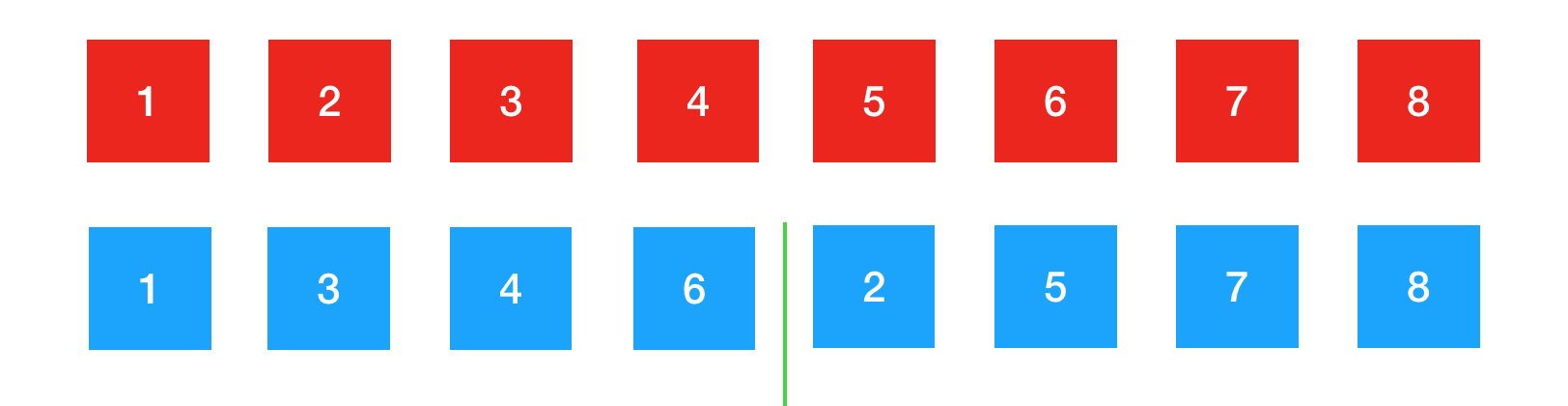
那么红色区域整个数组就排好序了。以上就是归并排序的思想,先平均切分成两个部分,对每一个部分分别排好序后,再归并成一个有序的整体。 重点来了,这个归并过程是怎样的?如果可以的话,那么我们就可以使用递归的过程先切割在逐层归并来完成整个排序。
选取最后一步的归并过程进行讲解。
归并过程
看下图,左右两部分都已排好了序,归并的过程就是将这两部分合并成一个有序的整体。咱们一步步讲解如何进行归并。

首先开辟一块与这个数组同样大小的临时的空间来辅助我们完成这个操作。
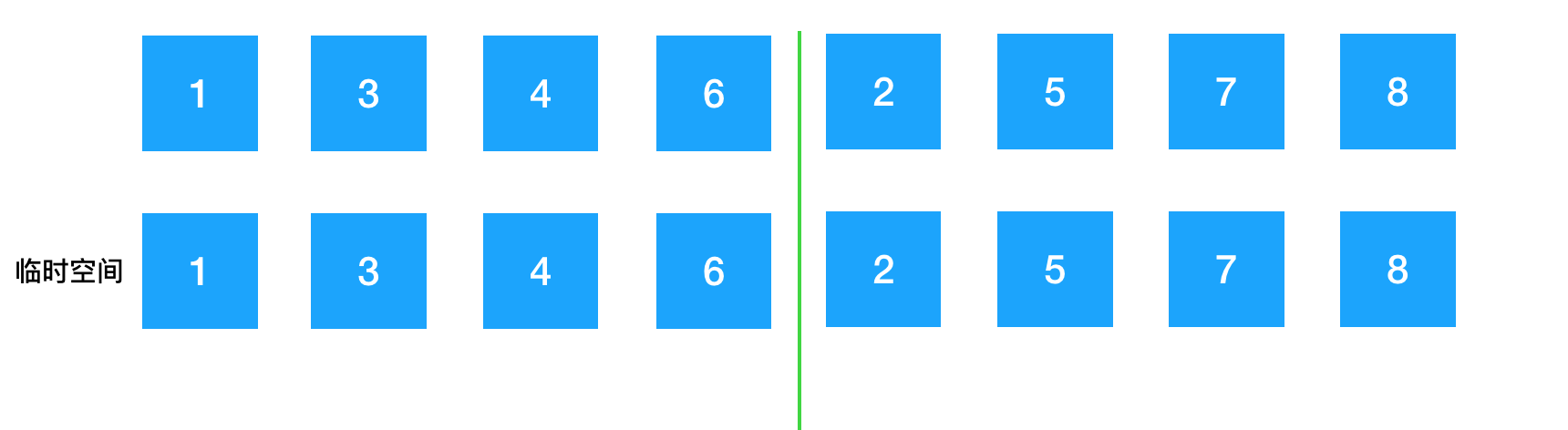
那么现在要使用三个索引对数组内的元素进行追踪。将开辟的临时空间中的两部分的黄色箭头所指向的首元素进行比较。
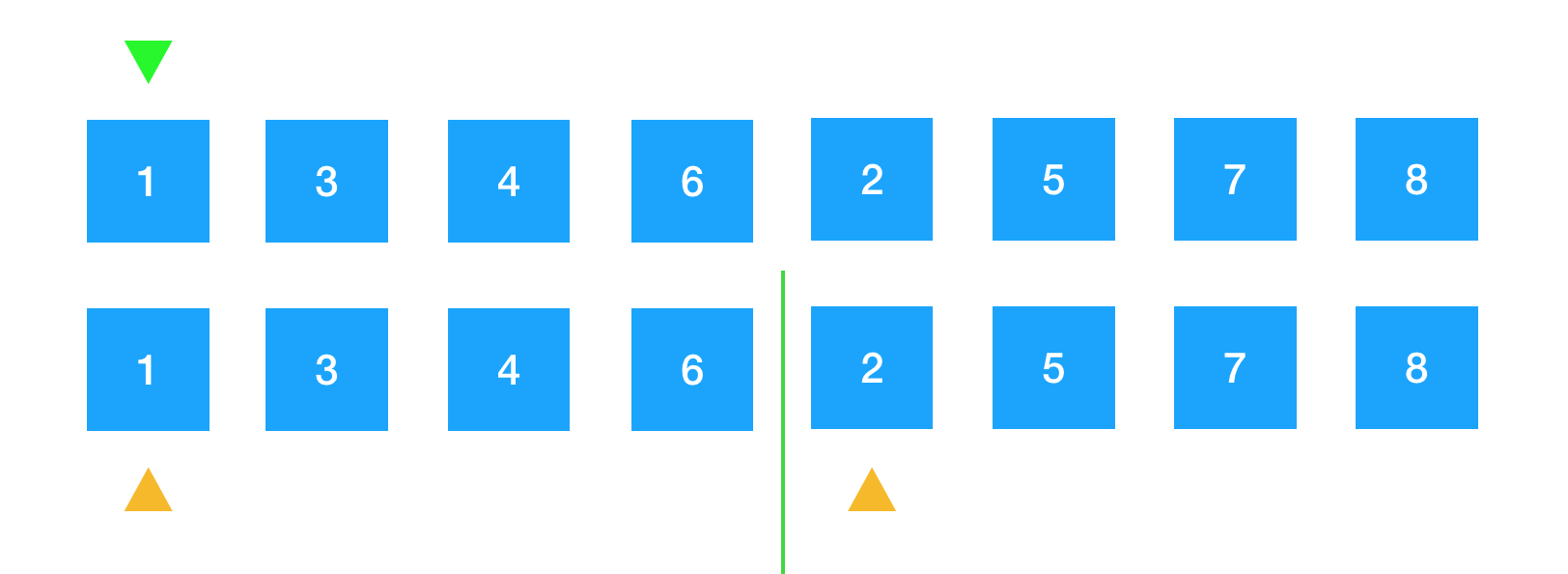
左边部分的1与右边部分的2我称之为待排序的元素,然后将这两个元素进行比较,1比2小,所以将1放到原数组绿色箭头的首元素上,此时1变成红色,表示已排好序。
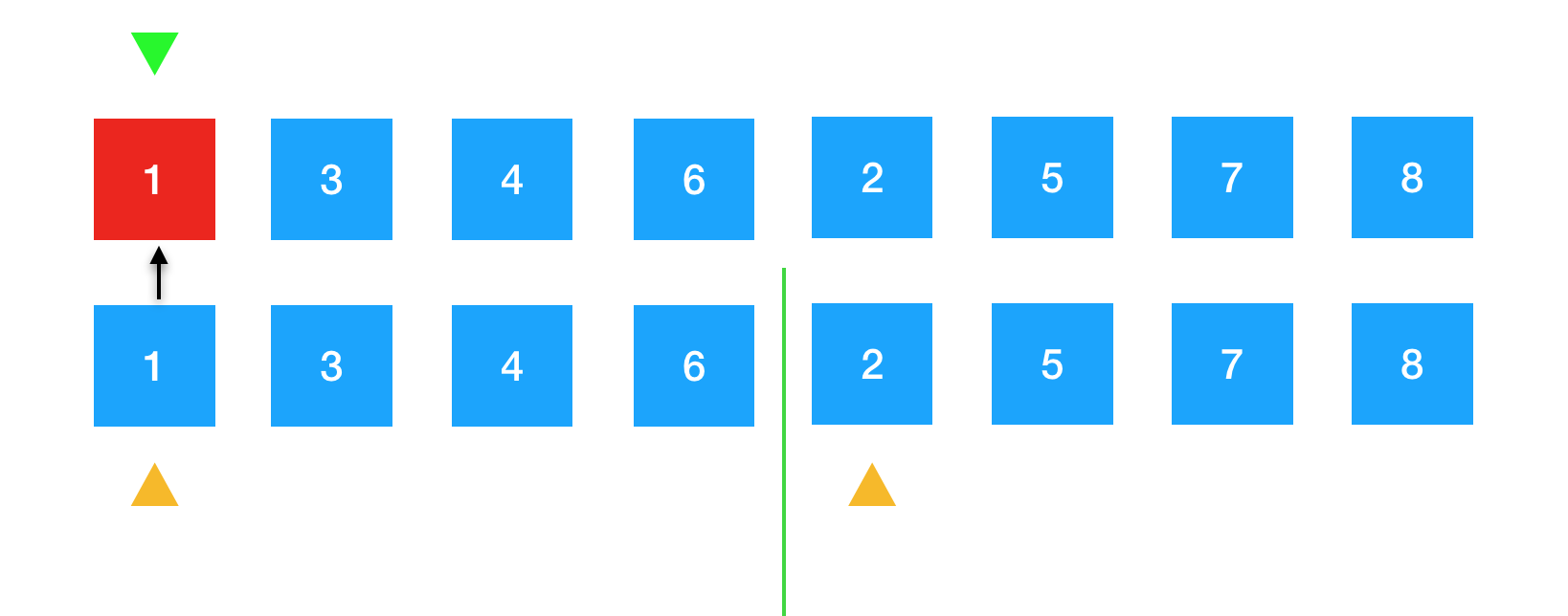
1已经排好序了,那么就要将黄色箭头向后挪一位,此时指着3,同时上面数组中的第一个元素1,也就是红色部分已经排好序了,所以将绿色箭头后移。如图示。
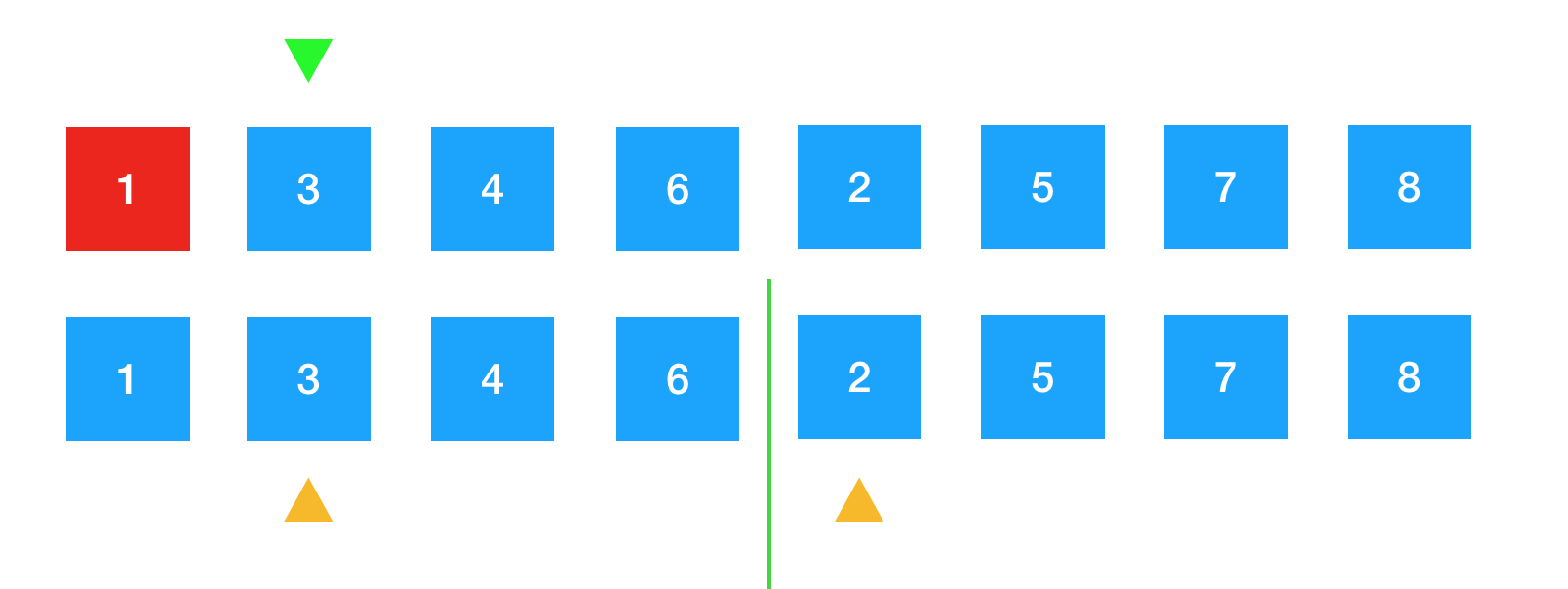
同样将临时空间中左右两部分的黄色箭头所指向的3与2进行比较,2比3小,所以将2放到上面数组所指向的位置上,此时红色区域的1与2就排序完成了。如图示。
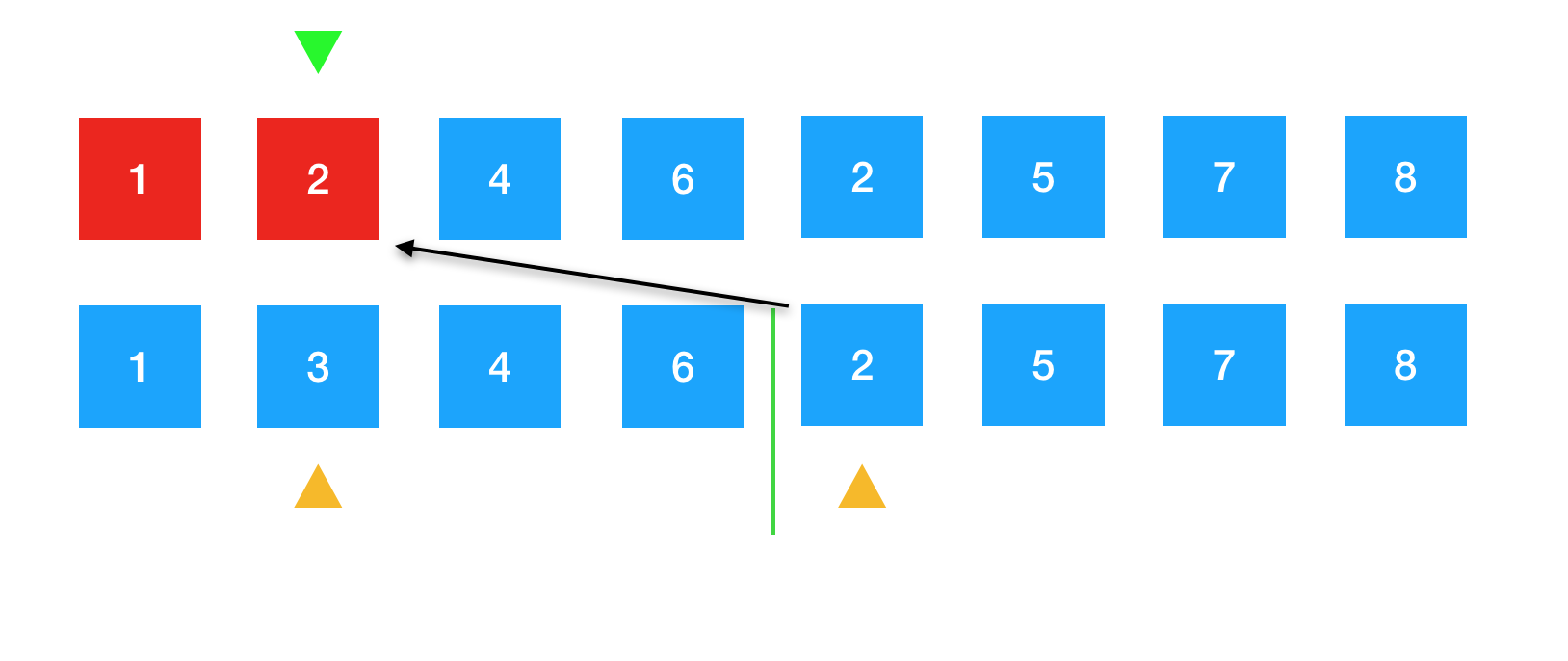
继续,2排好序后,将临时空间右边的黄色箭头往后移一位,指向待排序的元素5。因为2已排序完成,将原数组的绿色箭头指向下一个位置。
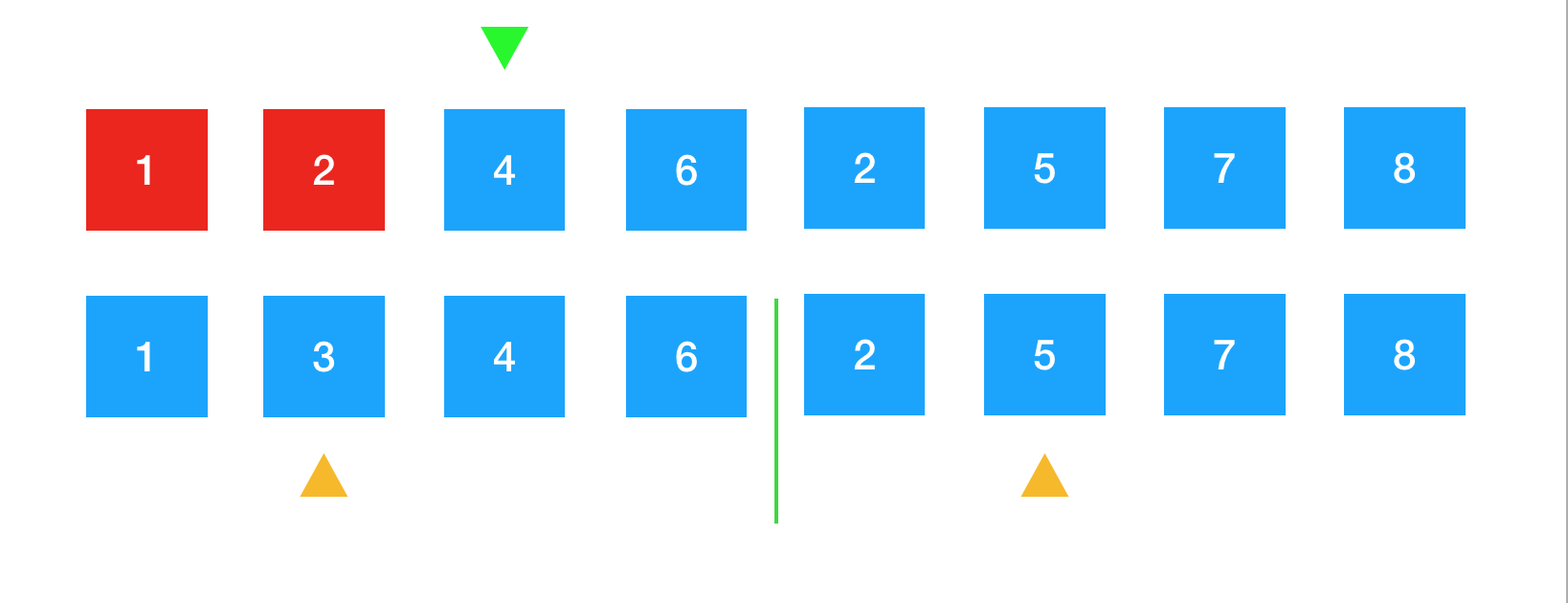
将两个黄色箭头所指向的3与5进行比较,3比5小,所以将3放到绿色箭头所指向的位置上。
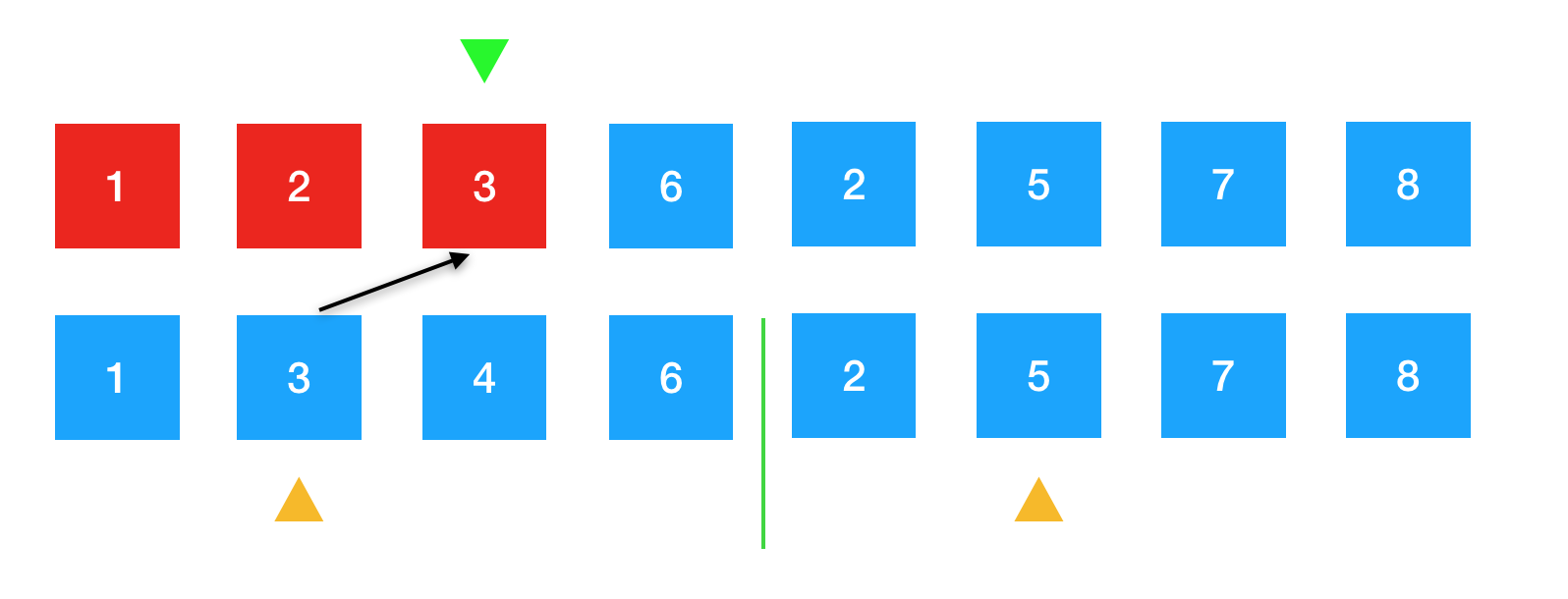
继续,绿色箭头像后移一位,左边黄色箭头也需要往后移一位,指向下一个待排序的元素4。
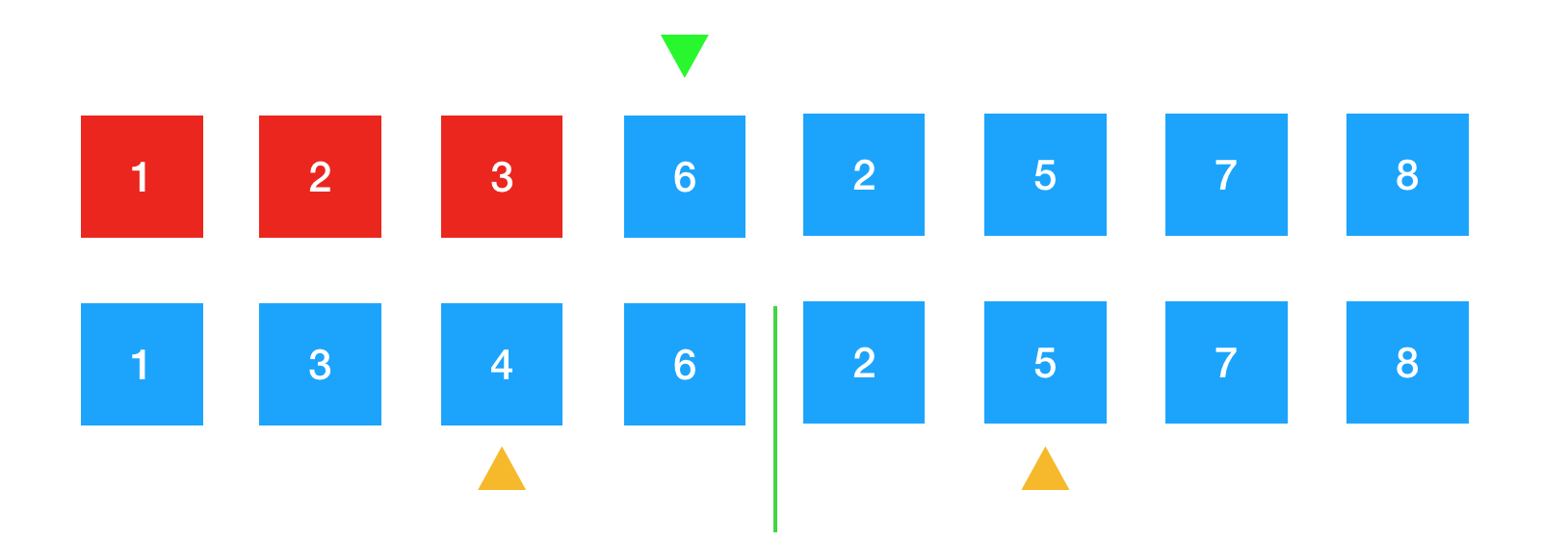
继续进行比较。4比5要小,将4放到绿色箭头下的位置。
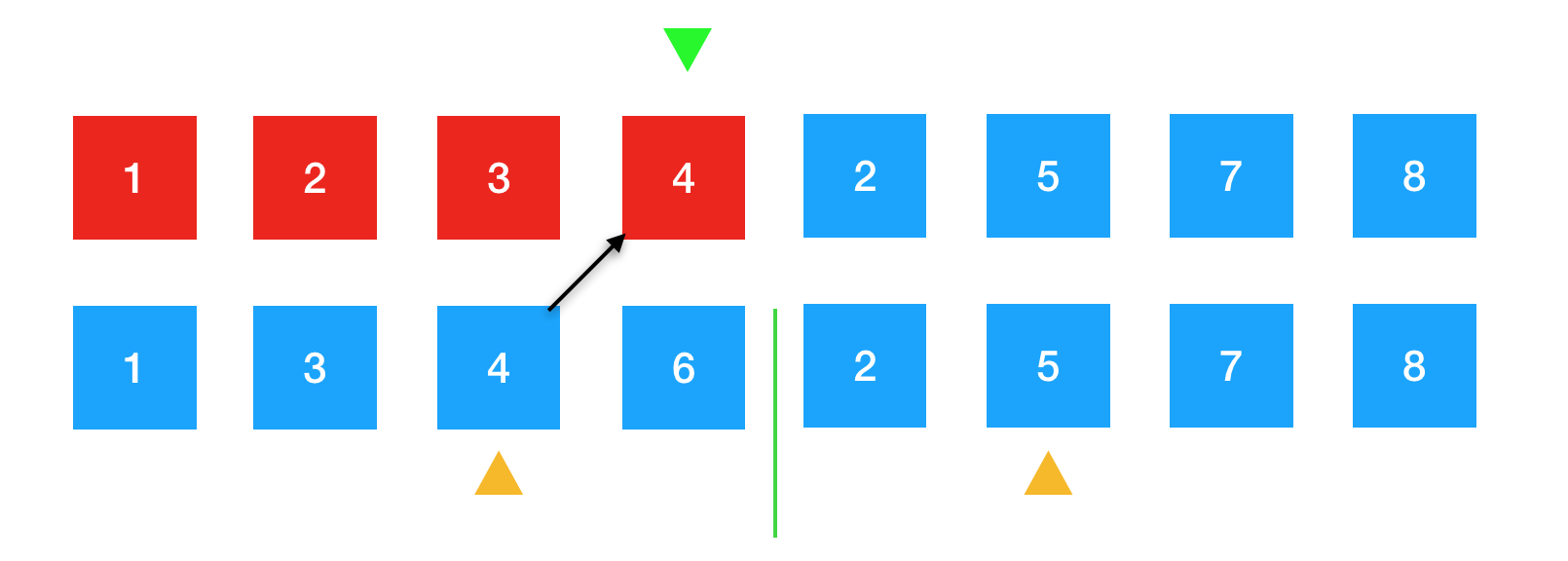
4排好序后,对应的黄色箭头指向下一个待排序的元素6。绿色箭头往后挪,准备承接下一个将要放置的元素。
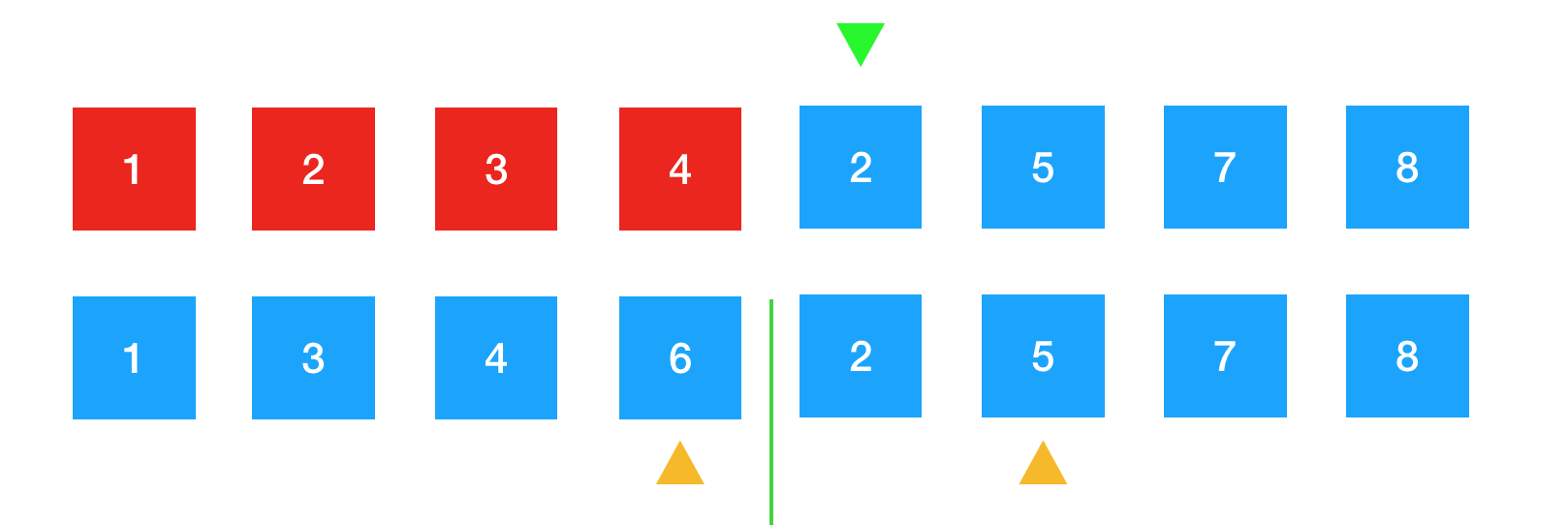
继续进行比较。5比6小,将5放到绿色箭头下的位置。
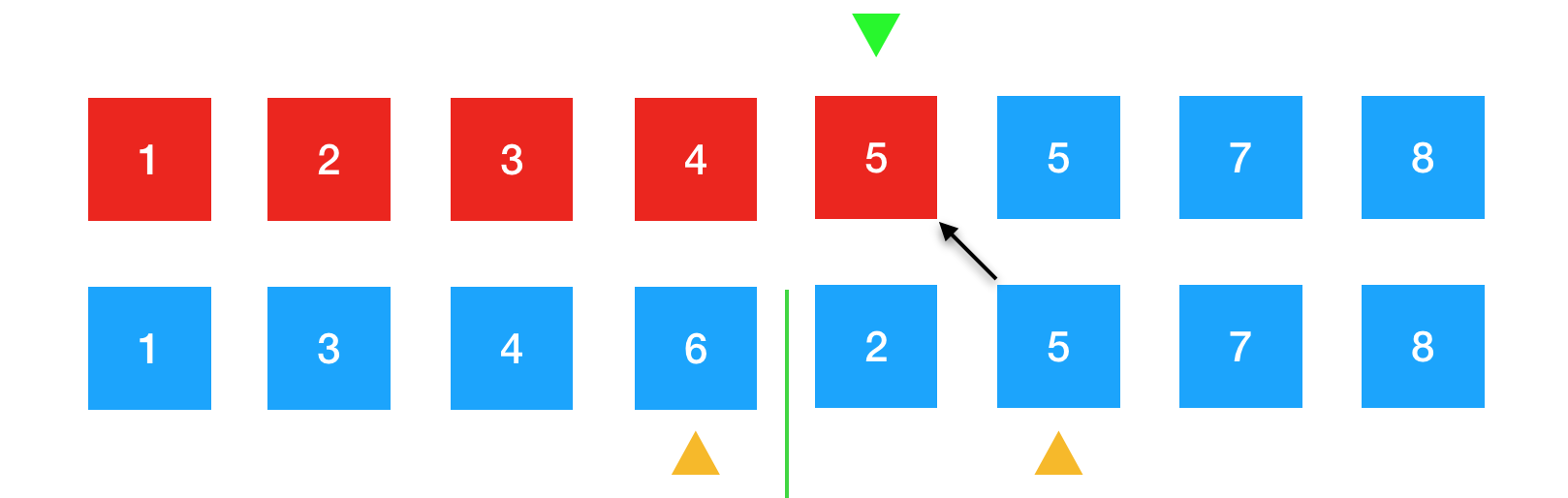
5排好序后,黄色箭头后移,指向下一个待排序的元素7,绿色箭头后移,准备承接下一个将要放置的元素。
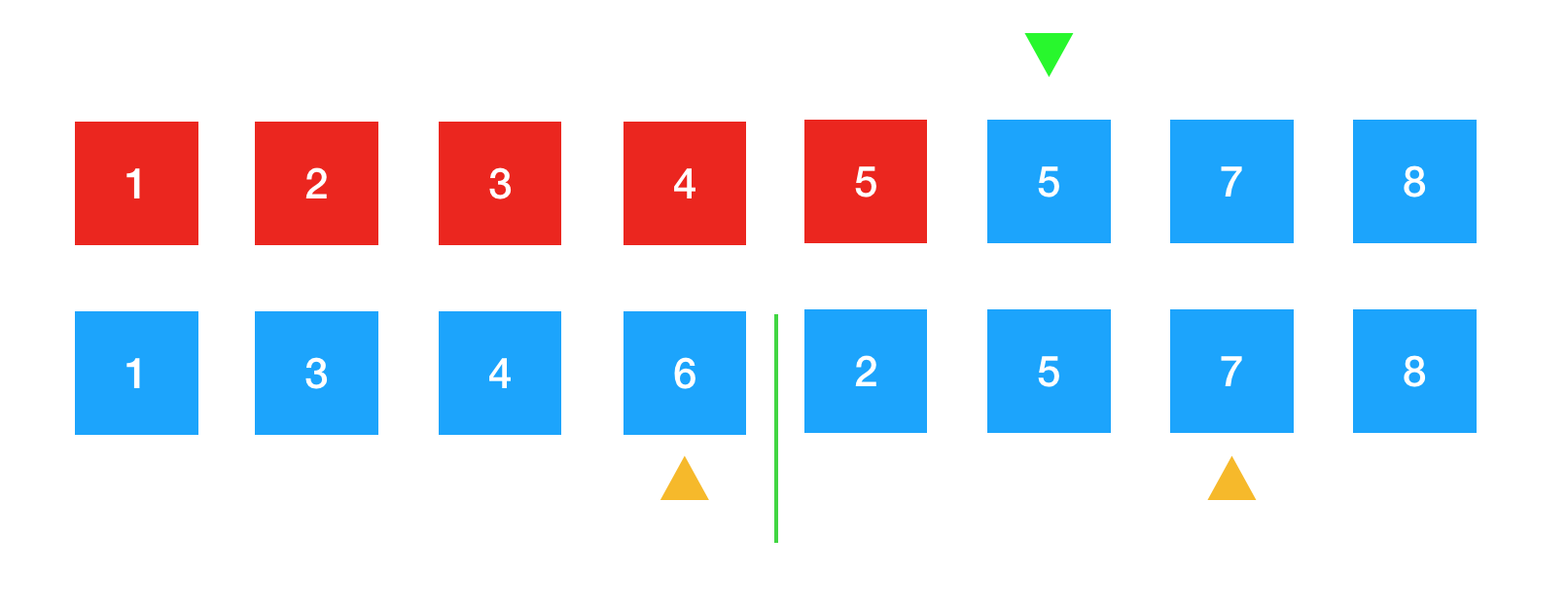
继续进行比较。6比7要小,所以将6放到绿色箭头下的位置。
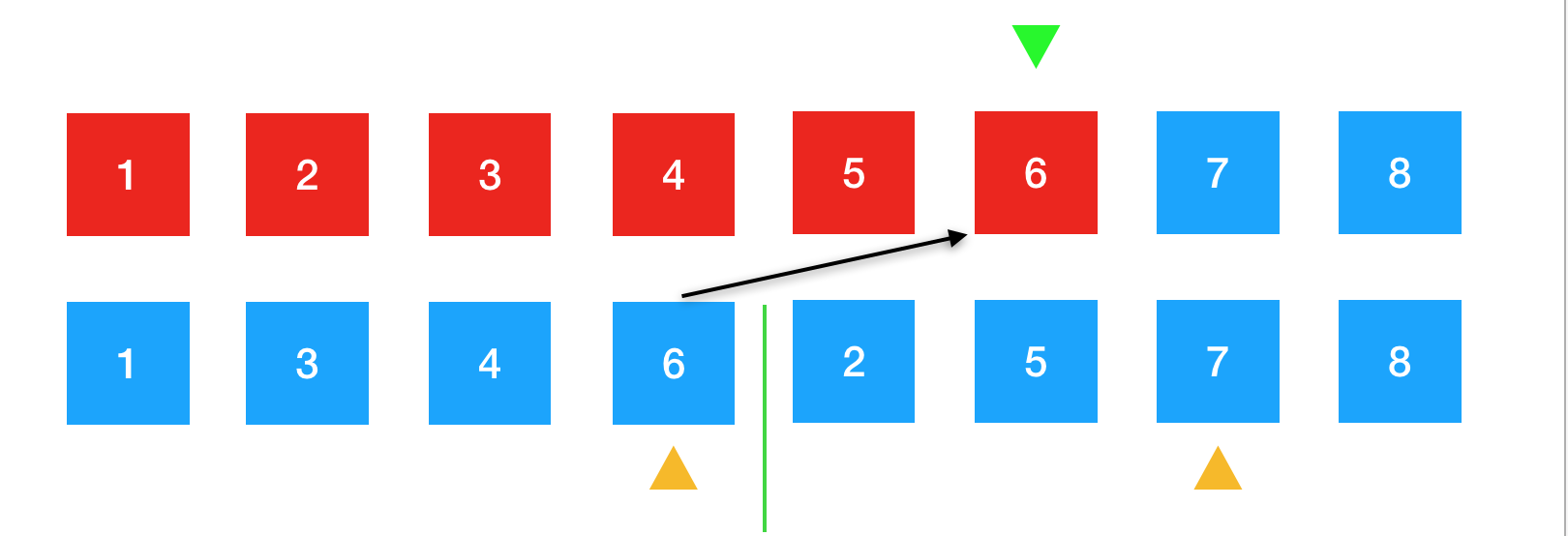
此时,左边的元素1,3,4,6已全部排序完成了。所以右边的7与8两个元素直接放置到元素的剩下位置上就好了。排序完成。
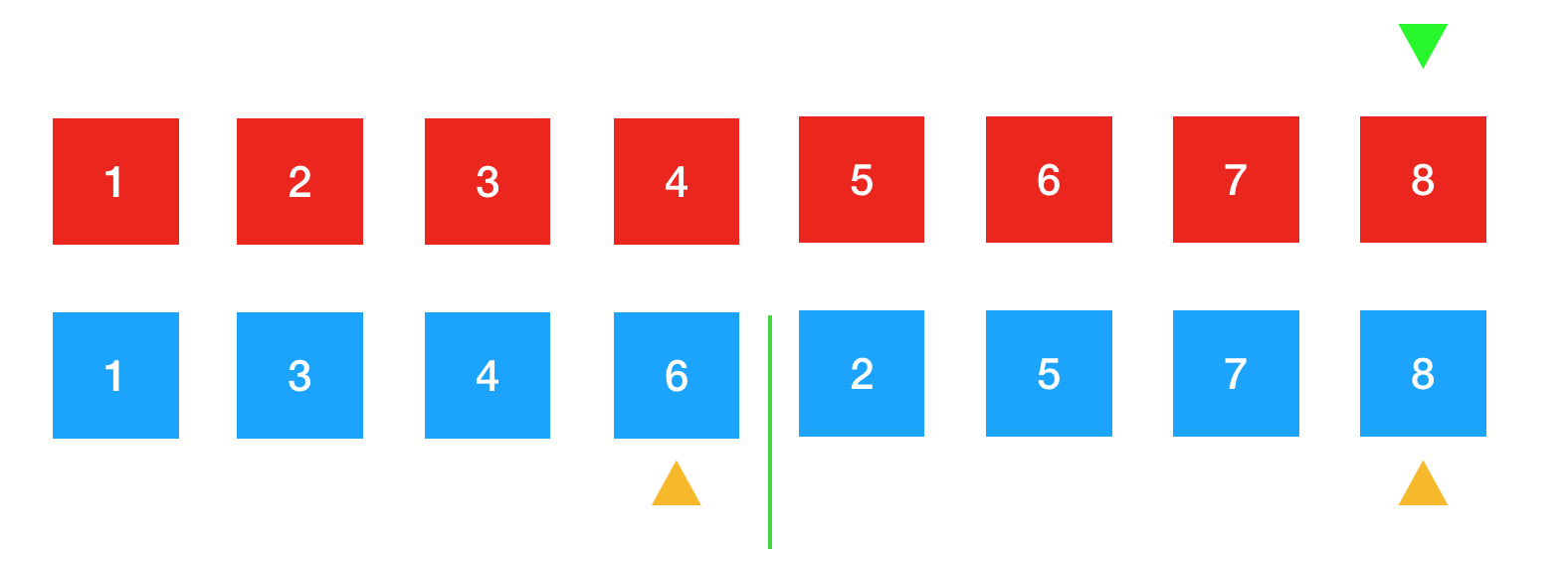
排序过程总结:先开辟一块与待排序数组同样大小的临时空间,将这块空间中的两个已排好序的数组内的元素一一比较,将比较较小的元素放置到原数组对应的位置上。
代码实现
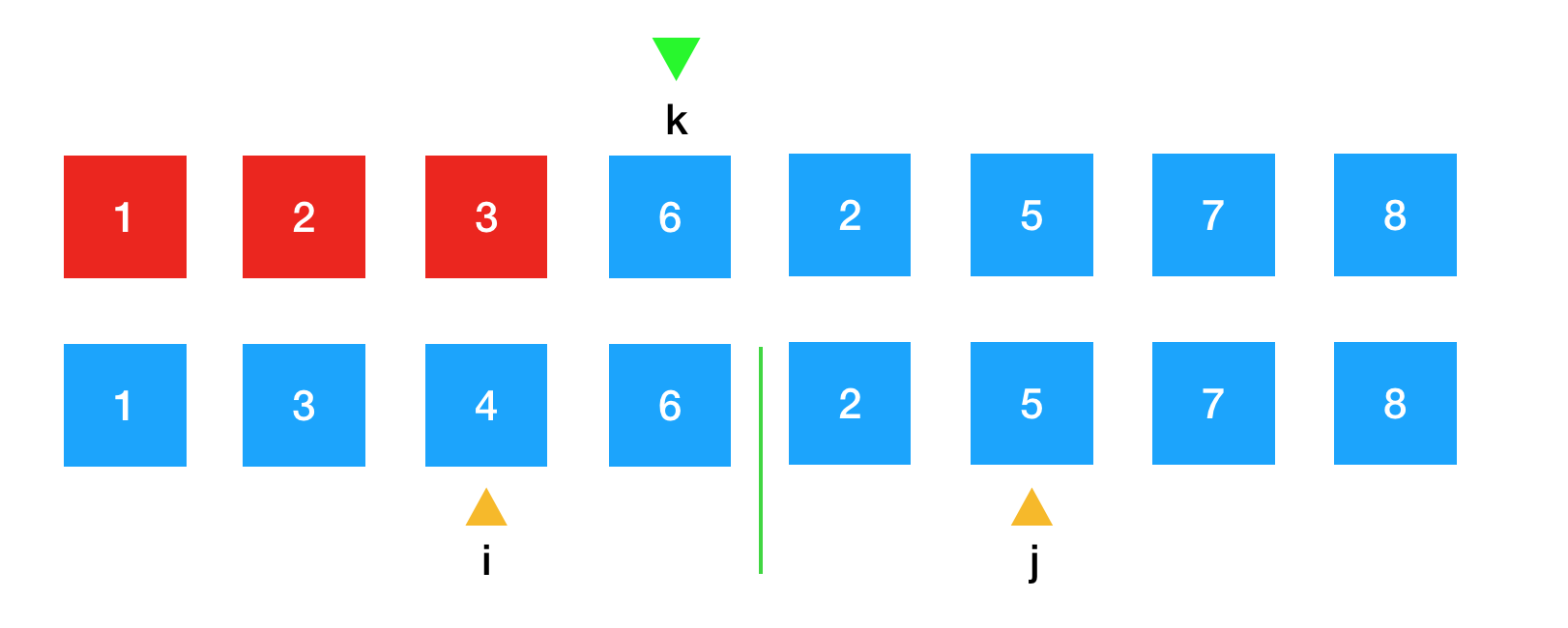
从前面的图片演示中,我们设立了三个索引的位置,在代码实现中,我们必须把他们定义清楚,尤其要注意,对于边界条件的处理。这样在编码过程中才不会出问题。
如图所示,将这三个索引的位置分别定义为i,j,k。 i,j表示当前正在进行比较的两个元素,k表示这两个元素比较后得到的结果最终将要放置的位置。这里需要注意的是,k不表示归并结束后放置的元素的位置,而是表示下一个需要放置的位置。我们在写算法过程中,就需要时刻维护这些变量,使他们在算法运行过程中,始终满足他们所代表的定义。
接下来我们要对一些边界情况进行处理,我们设定这个数组是在一个前闭后闭的区间中,在数组最左边的位置为l(left),最右边的元素为r(right)。所以这个数组的区间为[l,r];
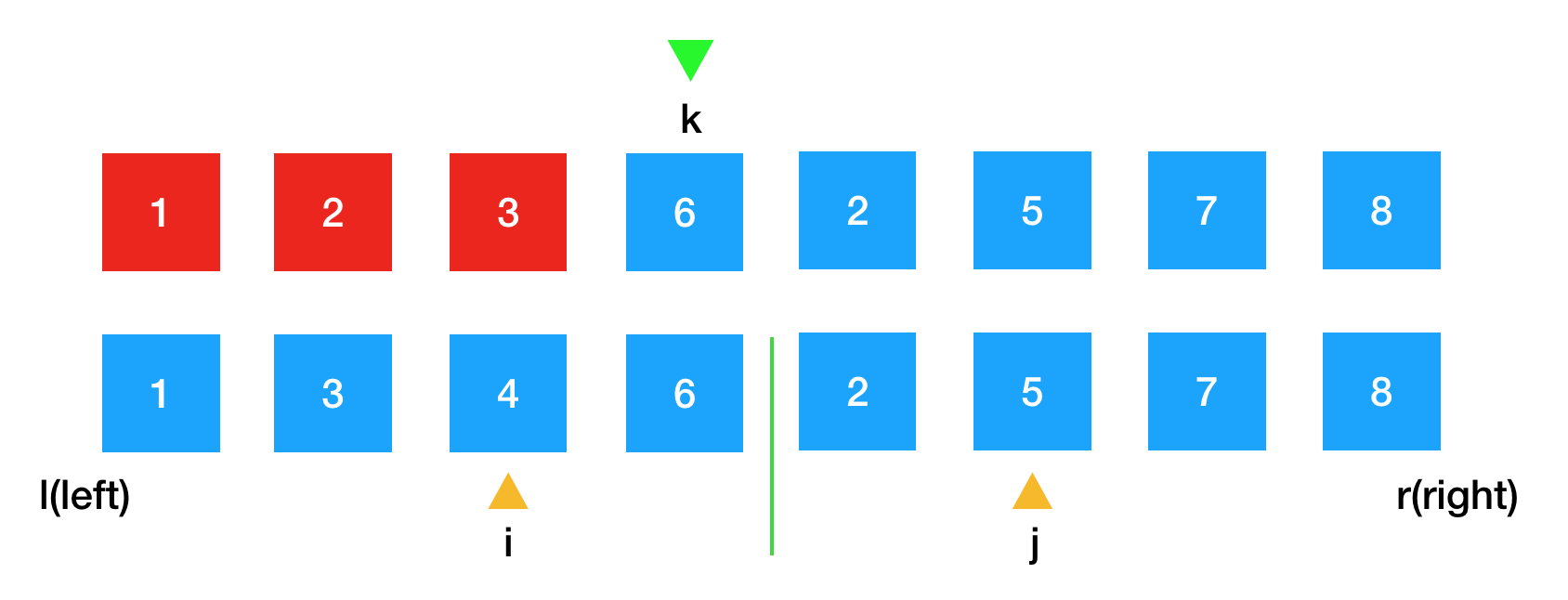
接下来再定义一个变量m(middle),用来区分左边已排好序的部分和右边排好序的部分,给他的定义是:左边排好序的最后一个元素的位置,如图所示。
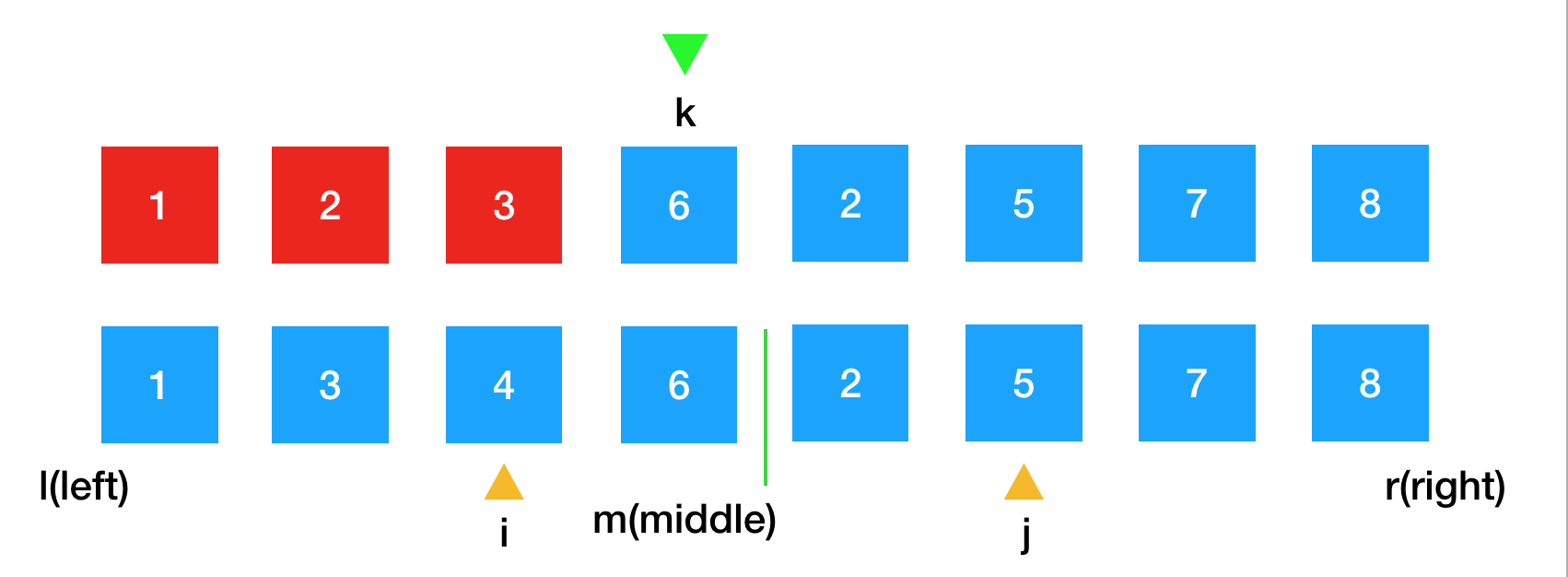
所以左边已排好序的区间为[l,m],右边已排好序的区间为[m + 1,r], 所以i的取值范围是 0 <= i <= m; m + 1 <= j <= r;
定义好这些变量后,下面开始写实现代码:
依旧写成一个函数,传入的参数为待排序的数组和数组的元素个数。在上面的实现中也可以看到,归并排序的本质其实是一次逐层进行递归的过程。归并排序的实现中,调用的 __mergeSort就为递归函数
template <typename T>
void mergeSort(T arr[], int n){
__mergeSort(arr,0,n - 1);
}
下面继续看递归函数的实现。传入的参数为待排序的数组,l ,r 分别为数组最左边与最右边元素的索引,所以是对数组的范围arr[l,r]内的元素进行排序。
首先先处理递归到底的情况,也就是当l >= r,时,l > r不可能发生,也就是当l = r时,此时由于区间是前闭后闭,区间[l,r]中就只有一个元素,此时我们的递归函数就直接返回return回去就好了,否则的话,定义一个中间变量m,根据前面谈过的m表示左边的已排好序的最后一个元素,将这个区间平分成左右两个部分,那么两部分的区间范围分别为[l,m],与[m+1,r],然后再调用该函数,进行递归,对着两部分的范围内的元素进行排序,然后这两个部分依次进行递归,当这两部分排好序之后,再调用__merge(),对这两个部分进行归并。
// 递归使用归并排序,对arr[l,r]范围内的元素进行排序
template <typename T>
void __mergeSort(T arr[], int l,int r){
if (l >= r) {
return;,
}
int m = (l + r) / 2;
__mergeSort(arr, l, m);
__mergeSort(arr, m + 1, r);
__merge(arr,l,mid,r);
}
下面,我们来看 __merge这个函数的具体实现, __merge这个函数的功能是将arr[l...m],以及 arr[m+1...r],这两个数组内的元素进行归并。我们一步步看这个函数的实现。
- 先创建一个临时的辅助数组temArr,因为定义数组边界是前闭后闭的,所以数组的大小为 r-l后需要再加上1;
- 然后进行for循环,对这个临时数组内的元素进行赋值,注意新创建的元素索引是从0开始的,而传入的数组是从l开始的,所以赋值时有l的偏移量,。
- 定义两个变量i,j。表示当前左右两部分正在进行比较的两个元素。
- 在for循环中进行比较排序,k表示这i,j两个元素比较后得到的结果最终将要放置的位置,k的范围也就是要要归并的两个数组 的整体范围,也就是arr[l,r]。
- 首先先维护i,与j的范围,i最多小于等于m,当i大于m时,就说明左边部分已排序完成,那么右边剩余的为排序的部分直接赋值给arr剩下未排序的部分就好了。同理,j最多小于等于r,当j大于r时,就说明右边部分已排序完成,那么左边剩余的为排序的部分直接赋值给arr剩下未排序的部分就好了。
- 然后比较两边元素的大小,小的赋值给arr[k],再进行i,j在定义上的维护。至此归并过程完成。
//arr[l...m],以及 arr[m+1...r],这两个数组内的元素进行归并。
template <typename T>
void __merge(T arr[],int l,int mid,int r){
// 创建一个临时空间
T temArr[r-l+1];
for (int i = l; i<=r; i++) {
temArr[i-l] = arr[i];
}
int i = l,j = mid + 1;
for (int k = l; k <= r; k++) {
if (i>mid) {
arr[k] = temArr[j-l];
j++;
}else if (j>r) {
arr[k] = temArr[i-l];
i++;
} else if (temArr[i-l] < temArr[j-l]) {
arr[k] = temArr[i-l];
i++;
} else {
arr[k] = temArr[j-l];
j++;
}
}
}
归并算法性能测试
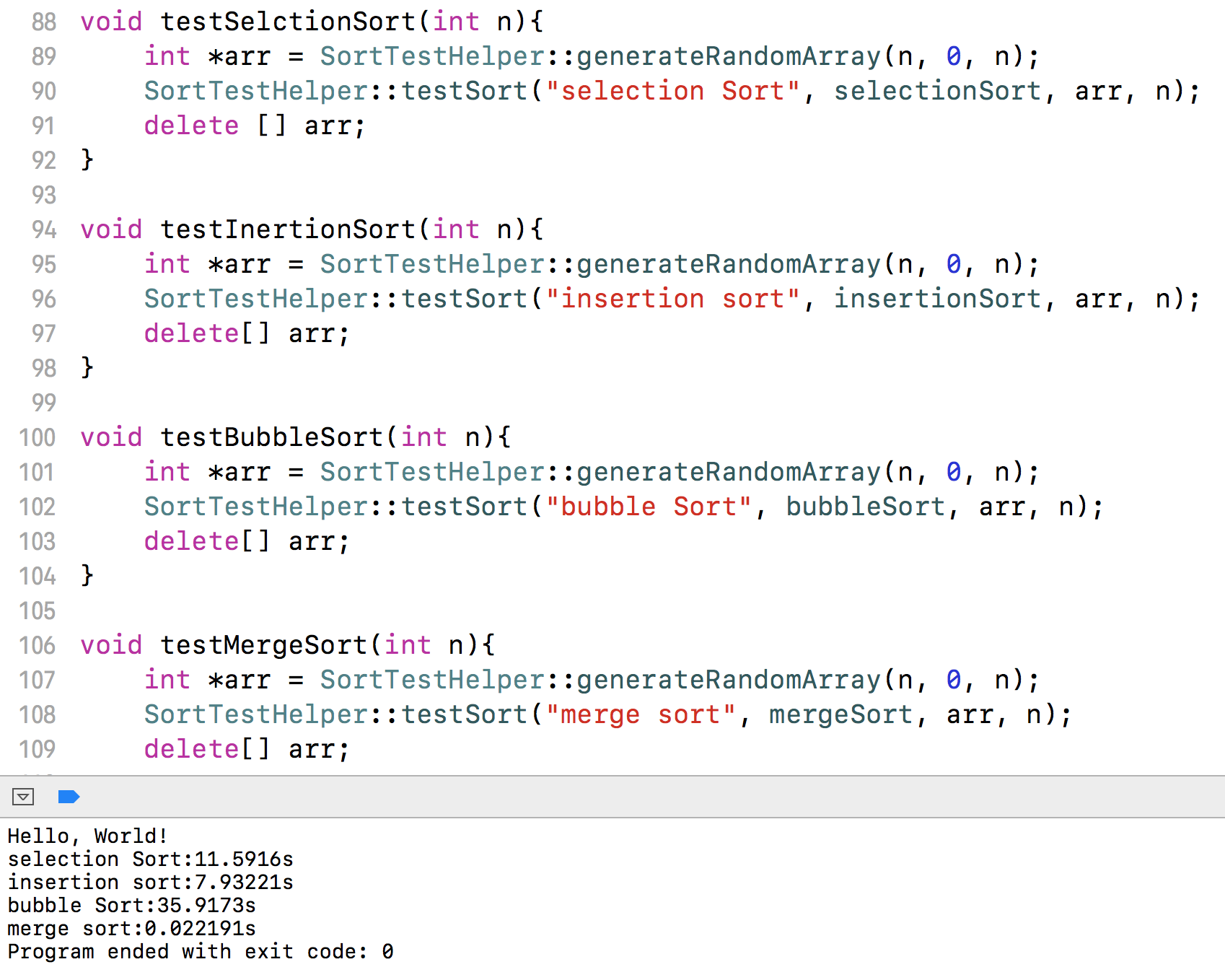
利用前面写好的测试用例,对写好的归并排序的算法进行性能测试,测试数据量和前面的10万保持一致,来比较与基础算法的差异。
可以看到,归并排序只用了0.02秒。性能比选择排序快了580倍,比插入排序快了396倍,比冒泡排序快了1796倍。差异明显。
好了,归并排序就介绍到这里,暂时还没讲归并排序的优化,以后再做补充吧。
感谢您能看到最后,篇幅略长,我不清楚我讲述的您是否理解,如果有不理解的内容,烦请提出,我一定做详细的解释。如果文章内容有错误,烦请指正。如果您喜欢我的文章,请关注我。
