


故事发展
平静悠闲的日子,依然是钱少事多,此处想象一个表情。忽然有一天,故事就来了,一个做统计的美女老同学说她懒得自己复制粘贴,让我帮她爬虫获取一些文章的内容和制定段落的文字,他们做后续的数据统计和分析,这个忙我当然得帮了,虽然没爬过。。。哈哈,然后下班之后我就花了几个小时用自己比较熟悉的nodejs做了这个简单的小Demo(故事会在文末继续并附上老同学美照!😁)。
目标:
爬取该网站(wwwn.cdc.gov/nchs/nhanes…)的右侧列表中DocFile下所有的文章的url,然后去爬到每个文章内部的第一段和最后的表格信息,如下图:
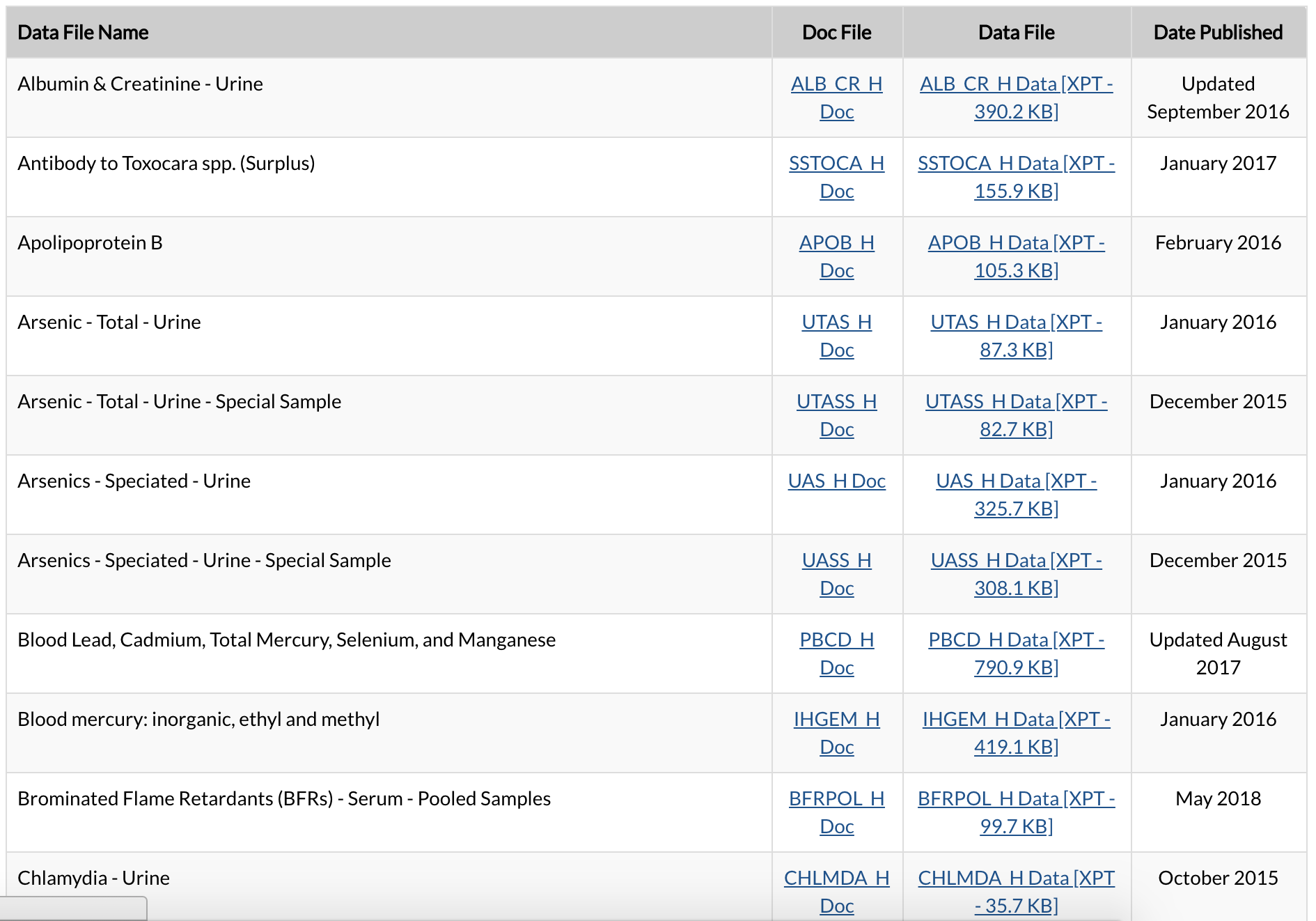

(2018.08.31补充)
爬虫方案分析:
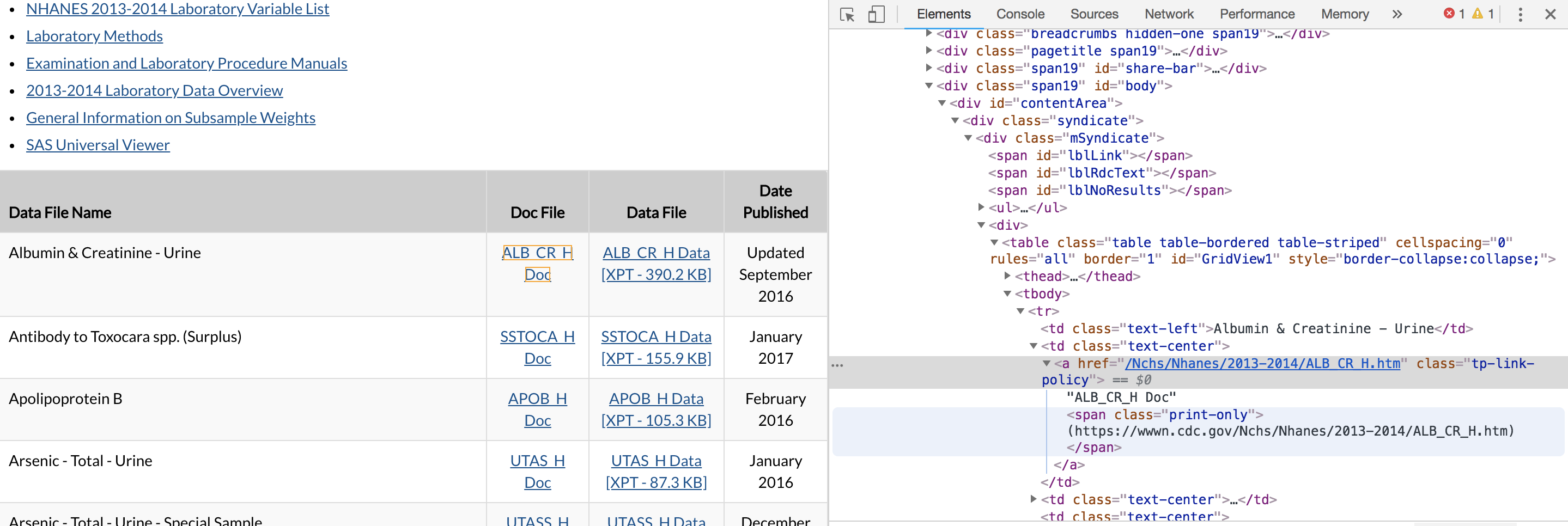
打开要爬去的主页,右键Doc File下面的某一篇文档,选择“检查”可在浏览器开发者工具(windows 按F12可直接打开)中,Element下可看到文档的url地址和整个页面的DOM结构。
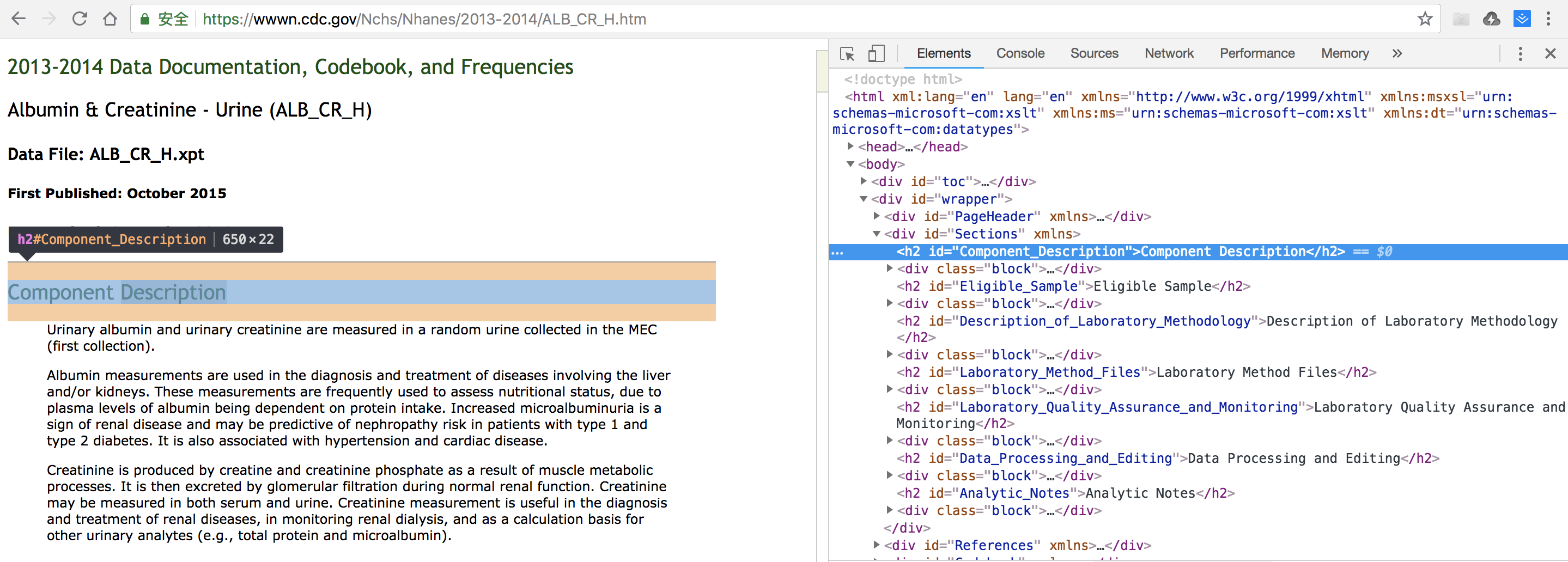
采用相同的方法,可以打开其中一篇文章,在文章要爬去的位置右键,查看到文章的Dom结构,获取到其中内容。
简略思路:
定位到文档所在Table---Table下的Doc File---取出Doc File下的文章url---根据url获取文章内容---选择文章内我们要爬去的内容所在DOM---格式化处理并保存在txt中。
采用的node包如下:
var = require('https')
npm init 初始化搭建项目,然后安装npm install cheerio与request ,建立app.js填写代码。
项目目录:
直接上源代码:
var http = require('http');
var https = require('https')
var fs = require('fs');
var cheerio = require('cheerio');
var urlHeader = 'https://wwwn.cdc.gov'
var urlFather = 'https://wwwn.cdc.gov/nchs/nhanes/search/datapage.aspx?Component=Laboratory&CycleBeginYear=2013'
//初始url
let count = 0;
function findUrlList(x,callback){
https.get(x, function (res) {
var html = ''; //用来存储请求网页的整个html内容
var titles = [];
res.setEncoding('utf-8'); //防止中文乱码
//监听data事件,每次取一块数据
res.on('data', function (chunk) {
html += chunk;
});
//监听end事件,如果整个网页内容的html都获取完毕,就执行回调函数
res.on('end', function () {
var $ = cheerio.load(html); //采用cheerio模块解析html
var urlArr = [];
$('#GridView1 tbody tr').each(function (index, item) {
let url = urlHeader + $(this).children().next().children('a').attr("href")
startRequest(url)
urlArr.push(url)
})
console.log(urlArr.length)
callback()
});
}).on('error', function (err) {
console.log(err);
});
}
function startRequest(x) {
//采用http模块向服务器发起一次get请求
https.get(x, function (res) {
var html = ''; //用来存储请求网页的整个html内容
var titles = [];
res.setEncoding('utf-8'); //防止中文乱码
//监听data事件,每次取一块数据
res.on('data', function (chunk) {
html += chunk;
});
//监听end事件,如果整个网页内容的html都获取完毕,就执行回调函数
res.on('end', function () {
var $ = cheerio.load(html); //采用cheerio模块解析html
var news_item = {
//获取文章的标题
title: $('div #PageHeader h2').text().trim(),
url: '文章地址: '+x,
firstParagraph: '首段:\n'+$('#Component_Description').next().text().trim(),
codeBookAndFrequencies: '表格信息: \n'+$('#Codebook').children().text().trim()
};
savedContent($,news_item); //存储每篇文章的内容及文章标题
});
}).on('error', function (err) {
console.error(err);
});
}
//该函数的作用:在本地存储所爬取的新闻内容资源
function savedContent($, news_item) {
count++;
let x = '['+count+'] ' + '\n';
x += news_item.url;
x = x + '\n';
x += news_item.firstParagraph;
x = x + '\n';
x += news_item.codeBookAndFrequencies;
x = x + '\n';
x += '------------------------------------------------------------ \n';
x = x + '\n';
x = x + '\n';
//将新闻文本内容一段一段添加到/data文件夹下,并用新闻的标题来命名文件
fs.appendFile('./data/' + news_item.title + '.txt', x, 'utf-8', function (err) {
if (err) {
console.log(err);
}
});
}
// startRequest(url); //主程序开始运行
findUrlList(urlFather,() => {
console.log('work done')
})命令行 node app.js 跑起来就可看到结果啦!
爬虫txt结果查看:


API参考:
故事继续
对,我花了两个间断简短的晚上帮她做出来了,然后我发现他想要的不是这样,而是一个更大更多功能的系统,要和他们的R语言系统对接!!!但是又没有经费,哈哈,那故事就这样结束了!但是作为一个很有求知欲的程序君,顺带熟练了一下基本的爬虫,还是很满足的!谢谢阅读,希望能给您一些收获!
美女请收下,你一定不会失望,哈哈哈哈哈😄
