

世界那么大,我想去看看。相信每到暑假期间,就会有很多人都想去旅游。但是去哪里玩,没有攻略这又是个问题。这次作者给大家带来的是爬取去哪网自由行数据。先来讲解一下大概思路,我们去一个城市旅行必定有一个出发地,然后有一个目的地,再然后我们就会搜寻当地的名胜然后选择一条路线。这个就是我们旅行开始之前的准备过程。没有这些,我们的旅行就不能开始。所以这次这个案例的目的就是获取去哪儿网上所有自由行的出发城市,然后获取该出发城市能到达的城市,再获得该目的城市所有的旅行产品。好了,是不是很简单。有了大体的思路,再去实现一个源码就不是难事了。作者在这里用的是Python来实现的,用的库为request库,将数据抓取下后再保存到MongoDB数据库。我们先看一下抓取后的结果。
控制台输出结果
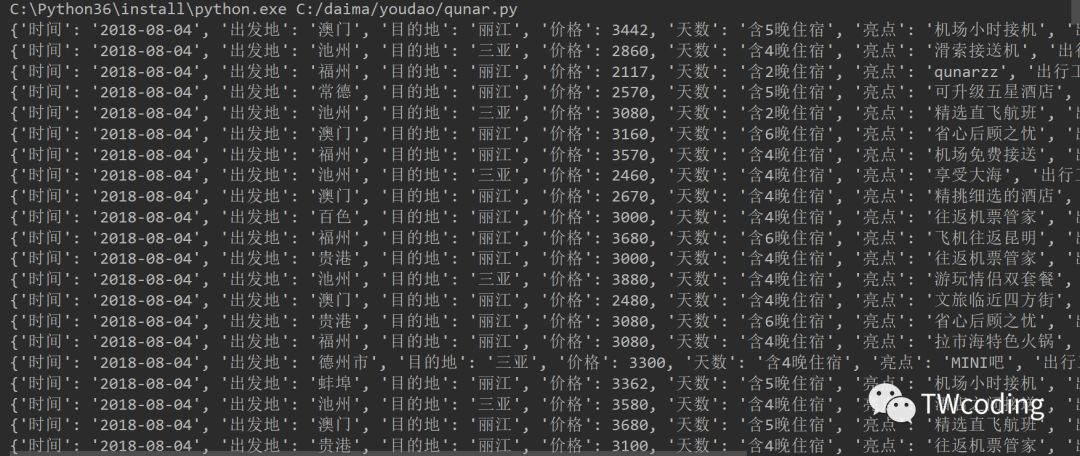

保存到MongoDB数据库,目前数据库有5万多条自由行数据。

1.访问站点解析数据
此次我们访问去哪儿站点的url为“http://touch.qunar.com/”这个网址是去哪儿的移动端,因为它返回的数据是JSON格式,JSON格式数据比较容易处理,所以我们以后数据采集的时候,可以优先选择JSON数据。我们用浏览器访问该URL,然后选择自由行这一栏。如下图所示。

我们单击左侧的出发地站点,如下图所示。
打开开发者工具,选中XHR,我们可以从源码中看到全国各个出发地站点根据字母排序。如下图所示。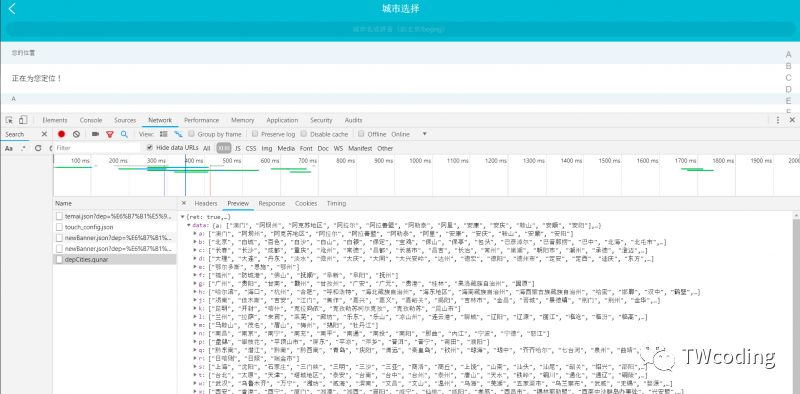
然后切换到Headers页面,观察Request URL和Request Method。如下图所示。
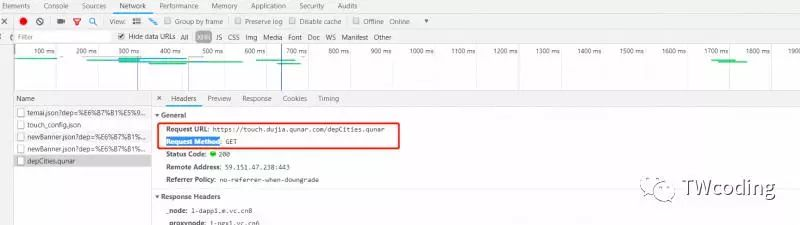
此时的目标URL为"https://touch.dujia.qunar.com/depCities.qunar"。
我们再点击自由行的搜索框,从这里我们可以搜索我们想去的城市。

我们可以从开发者工具中Headers中看到一个请求链接,其中“dep”表示我们出发的城市,由于服务器不能识别中文字符,所以“dep”后面是经某种编码方式编译后才提交给服务器的。这也就是我们看到的一串文字,所以我们可以通过更改dep的值来选择任意一个城市作为我们的出发地。
我们随机选择一个想去的城市,作者在这里选择的是丽江,打开开发者工具。
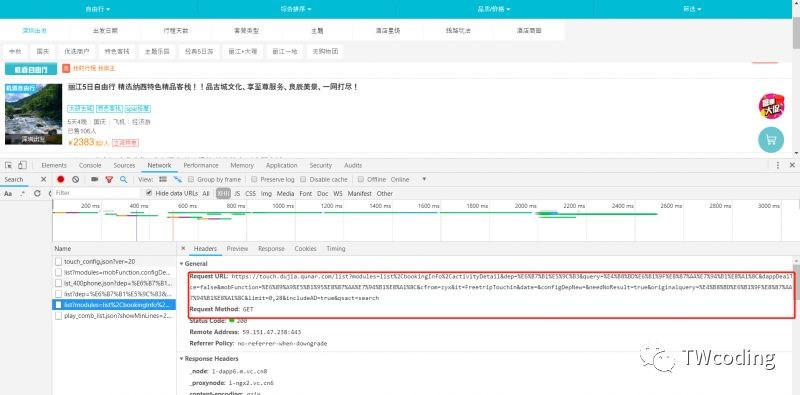
我们可以看到其中的请求链接为"https://touch.dujia.qunar.com/list?modules=list%2CbookingInfo%2CactivityDetail&dep=%E6%B7%B1%E5%9C%B3&query=%E4%B8%BD%E6%B1%9F%E8%87%AA%E7%94%B1%E8%A1%8C&dappDealTrace=false&mobFunction=%E6%89%A9%E5%B1%95%E8%87%AA%E7%94%B1%E8%A1%8C&cfrom=zyx&it=FreetripTouchin&date=&configDepNew=&needNoResult=true&originalquery=%E4%B8%BD%E6%B1%9F%E8%87%AA%E7%94%B1%E8%A1%8C&limit=0,28&includeAD=true&qsact=search"。
其中"dep="后面是出发城市,"query="后面是目的城市,"originalquery="后面是目的城市。从这个链接我们可以获取到该自由行线路的所有产品,并且分析其JSON文件就可以获得自由行产品信息。到此我们我们已经获得了一条线路的所有产品了,那我们获取所有城市之间的自由行产品就很容易了。因为之前我们已经拿到了所有出发城市和目的城市的列表了。到此所有的分析都已经完成,我们可以用代码来实现了。
2.源码实现






3.结语
相信读者看到这里,已经了解了本篇爬虫的思路了,因为去哪儿网服务器后台有较强的识别爬虫的能力。代码中作者也给出了一些反反爬的策略。最简单的方式就是牺牲爬取的速度。如果不想牺牲速度可以加上ip代理池和cookie池,隔一段时间就换下ip和当前cookie的值。有兴趣的读者和想挑战下的读者可以尝试下。
本案例源码:
"https://github.com/NGUWQ/Python3Spider/blob/master/dataanalysis/qunar.py"
如果觉得好的话,可以在GitHub上给个Star。作者会在公众号每天分享一些好玩的爬虫和算法源码。
对爬虫,数据分析,算法感兴趣的朋友们,可以加微信公众号 TWcoding,我们一起玩转Python。
转载请注明出处,谢谢!
自助者,天助之

