

前言
大多数项目的查询操作占据了数据处理很大的比例,关于查询的优化成为了很多数据库一直研究的重点。当前的数据库产品一旦涉及到超大库数据的查询都会采用索引技术,如MySql、Oracle、SqlServer、Hive...在满足不同的产品特性和应用场景里有着不同的实现方案。
通常来说,索引的目的主要是提高查询速度,不同数据库对索引的技术细节做了很好的封装,在实际应用中对于开发或维护人员来说是完全透明的。然而,笔者认为,深入理解查询技术对于开发者来说是面向大型数据处理的必要过程;对于架构人员来说,索引技术的充分理解往往可以在数据处理方案的选择上进行全面的分析,做出良好判断。
本文从操作系统层面结合硬件I/O过程理解查询所带来的关键问题,从而引申出索引查询技术的设计思路,整个过程将对索引关于I/O层面的技术细节做出分析。
I/O的认识
计算机经过几十年发展各方面性能都得到了显著提高,然而却一直有个因素限制着计算机的高速运转,这就是I/O的问题。
很多开发者似乎并不对I/O有刻意的认识,但在数据处理领域这是一个绕不开的话题,关于I/O维基百科是这样解释的:
I/O(英语:Input/Output),即输入/输出,通常指数据在内部存储器和外部存储器或其他周边设备之间的输入和输出。I/O是信息处理系统(例如计算机)与外部世界(可能是人类或另一信息处理系统)之间的通信。输入是系统接收的信号或数据,输出则是从其发送的信号或数据。
在了解I/O前,我们需要认识的是,现代计算机,磁盘和内存一直占据着主要角色,大部分持久化的数据都会选择容量较大、成本较低的磁盘中,而内存则作为高速缓存的角色为计算机提供存储支持。在数据查询中,一次I/O可以理解为从磁盘亦或是从内存读取一次数据的过程,在涉及到查询性能的分析中,就必须对I/O的成本具备一定的敏感性。
什么是I/O的成本?
计算机性能的大幅提升离不开存储器和CPU在处理速度上的不断提高,但关于性能提升的速度在CPU和存储器间却造成了一定的差距,CPU自1980年来在普通计算机中的处理速度已经实现了10000倍的提升,而磁盘只提升了30倍左右。这造成了一种现象,就是大多数时候CPU需要等待磁盘的运转,一个完整的数据处理过程,磁盘往往占据了主要的操作时间,在这里我们可以把I/O的成本理解为每一次从磁盘、内存读取的时间消耗。
之前一篇文章【理解进程的存在】笔者分析了CPU处理运算的基本过程,从CPU每秒亿万次的时钟周期中我们具备了一定的感知,就是CPU对指令的处理速度大大超越了常规理解,底有多快?当前4核CPU的时钟周期已经达到了0.4ns左右,也就是说每0.4ns就能完成一次指令操作,而内存一次访问时间大概是9ns(建议理解下ns、ms这些维度的时间差距),尽管差了20来倍,但似乎还维持在同一量级的水平上。磁盘就离谱了,机械磁盘当前还维持在29ms的访问时间,和内存、CPU分别是百万和千万量级的巨大差异!磁盘相较于内存为何在I/O中有如此糟糕的表现?参考之前文章【磁盘和内存的基本认识】的相关描述,我们这可以从存储器的存储原理和存储介质两方面做好了解。
因此,数据处理的瓶颈往往在于I/O,而I/O的瓶颈往往在于驱动硬盘的过程,只有尽可能减少对磁盘的I/O依赖,我们才能从性能上完成突破。
需要清楚的是,磁盘较差的I/O表现不代表不能被市场接收。因为磁盘的制造成本相较于其它高速存储器有着巨大优势,所以接下来很长一段时间磁盘的I/O依旧是一个需要面对的课题。
从OS层面看磁盘I/O过程
在硬件角度上我们认识到存储器本身带来的局限性,那么大部分场景下关于查询的优化将主要从软件层面做好处理,不同操作系统在底层上都对I/O做了良好支持,量化I/O成本必须从OS层面进行细致了解。
早期计算机系统的存储层次只有三层:CPU寄存器、DRAM主存储器(内存)和磁盘存储,OS围绕这三种存储介质进行相应优化,由于CPU和存储器在发展过程中性能差距不断变大,目前计算机在寄存器和内存之间又置入了多层高速缓存存储器,部分情况下内存和磁盘中间还会置入SSD(固态硬盘)。当前OS利用一定的算法在缓存命中方面做好工作,尽可能提高整体I/O的性能,但这并不妨碍我们核心问题的分析,大多数情况下,OS需要解决的问题依旧是数据从磁盘到内存的过程,为了简化分析模型,我们将问题从内存、磁盘两者进行思考。
在磁盘中,数据是以块为单位进行管理的,每块一般设定为4Kb,我们可以抽象出磁盘就是很多块按序号排列的存储结构:
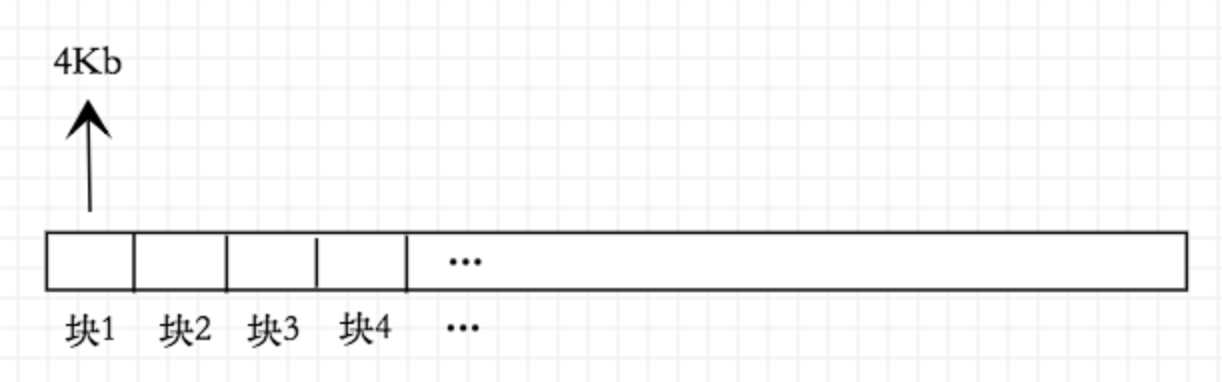
当OS需要获取磁盘某个数据时,将产生一个I/O中断,本次I/O中断将带上具体的块号去驱动磁盘进行块数据查找和读取操作,这些操作都是以某块作为起点,每次读取数据的最小单位也是4Kb,这意味着如果你获取的数据小于4Kb或者数据放置在某块特定偏移处,那么磁盘依然会从该块开始将整个块内容传递到内存中:
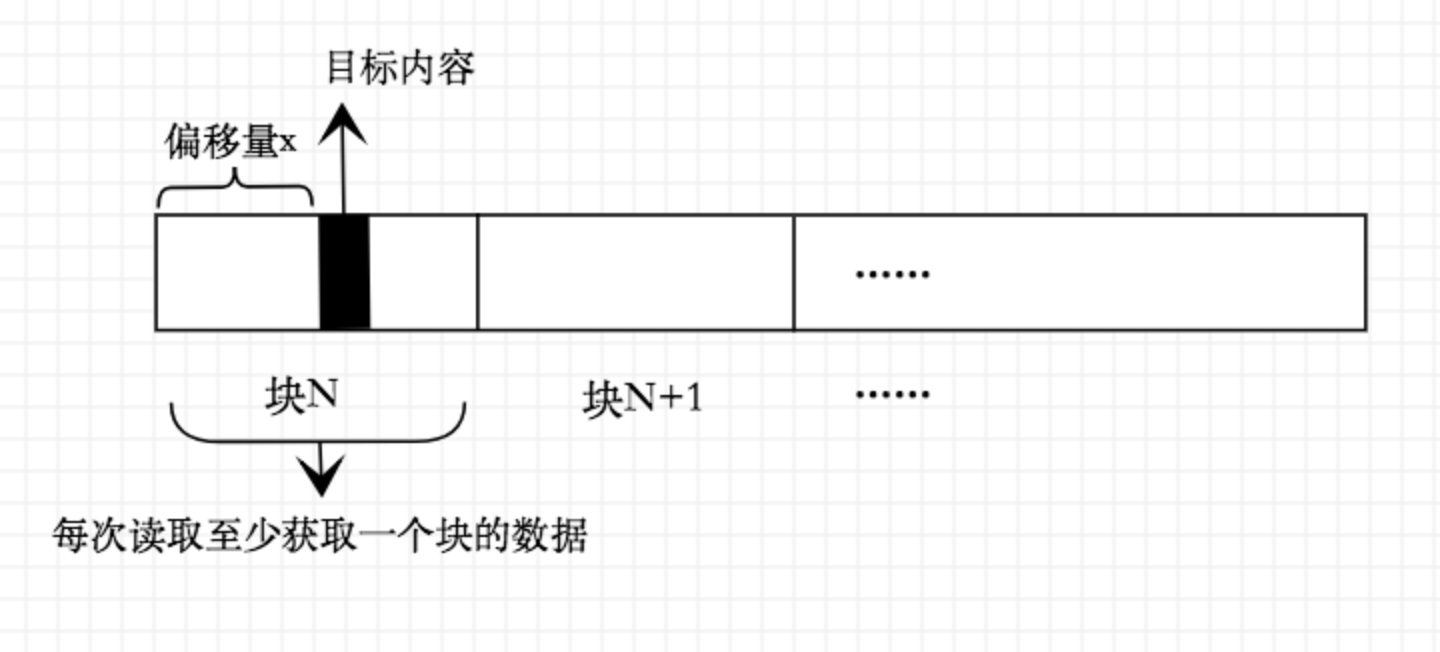
对于小于4Kb的数据,如果刚好放置在某块中,那么往往只需对磁盘进行一次驱动,也就是一次I/O过程,但如果这数据刚好横跨两个块,那么就需要驱动磁盘读取两个块数据了(下图查询目标内容需要读取块N、块N+1):
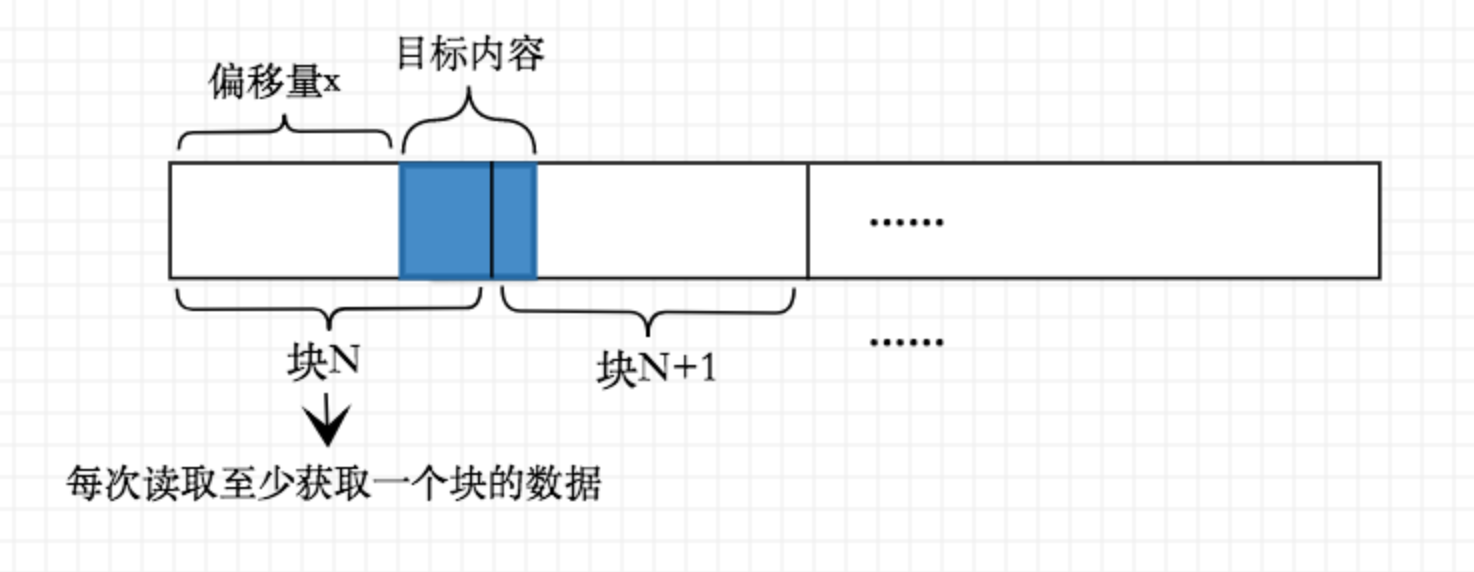
因此,我们应该尽量避免上述情况,将目标数据以块为单位进行对齐,这样能减少磁盘I/O过程中块的读取次数。
但如果目标数据本身就很大,必须占用多个块呢?显然,假设目标数据连续占用N个块,那么磁盘将进行N次读取操作:
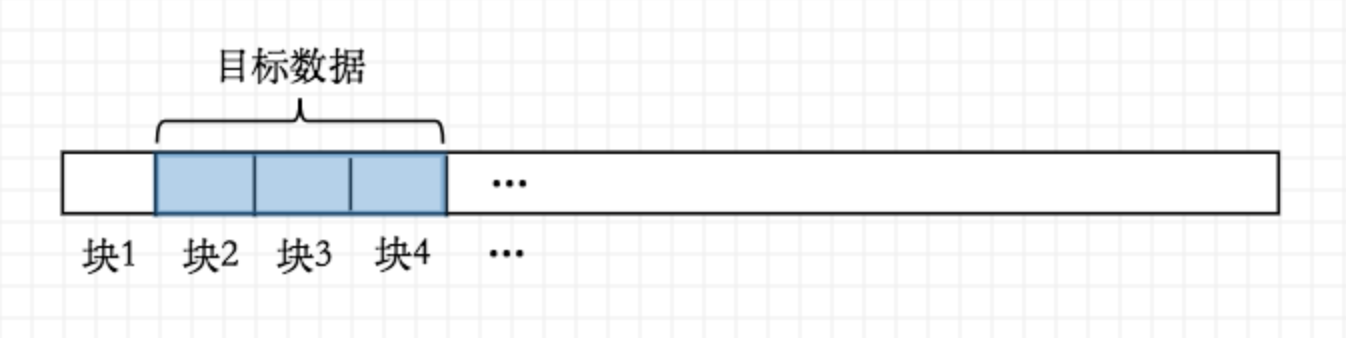
但如果目标数据并不顺序存放,而是分散在各个块区域:
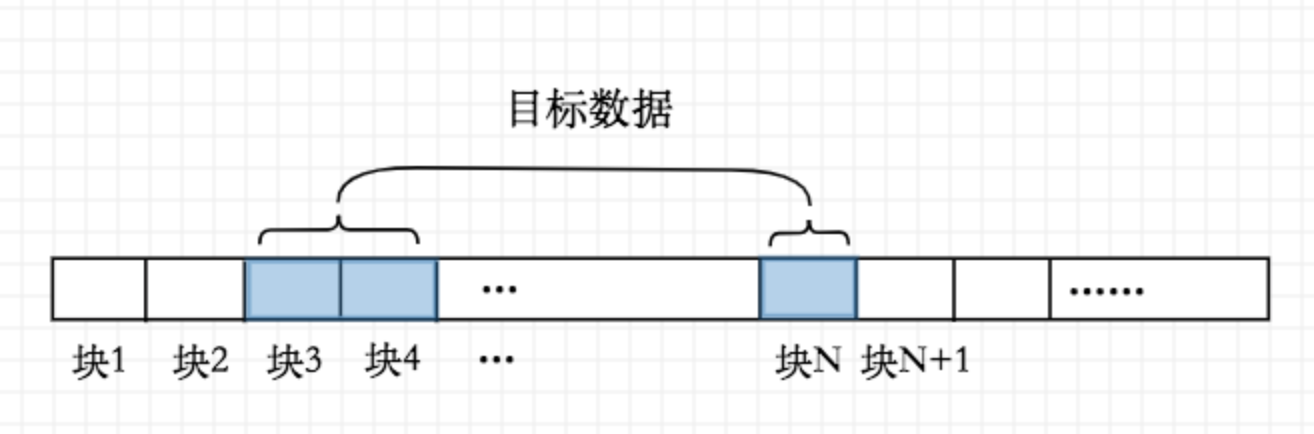
同样是进行三个块读取操作,但从磁盘的物理构造来讲,磁盘必须进程两次块定位操作,也就是I/O中的磁头定位过程。磁盘在读取目标数据前必须将磁头定位到指定的块起始处,如果中间目标数据分散在块的不同区域,那么磁头必须进行一定距离的物理旋转工作,这显然会占用读取时间,也就是顺序读和随机读的关键区别!因此,最理想的情况是,目标数据在磁盘中的存放位置不仅块对齐而且是连续存放,至少要控制数据在磁盘的离散程度在较低水平。
CPU在执行任何指令时,但凡涉及到磁盘I/O,OS都会将数据先预读到内存缓存空间,通过上文的介绍,内存的存取周期和CPU的处理周期在量级上并无太大区别,因此数据库在管理数据方法上,更多的精力花在减少磁盘的I/O。
数据的管理和检索
数据库对不同表会有专门的文件管理,一个文件可以理解为记录的一个序列,不同表在磁盘中的文件组织方式可能有一定区别。常规来讲,诸如mysql的关系型数据库是一种行式数据库,表中每条记录可以理解为一行,每行不同字段的内容在磁盘中是顺序存放的,而不同行在磁盘的的位置则不一定是按序的,有可能分散在不同区域的块中。
我们考虑在数据库中创建一个用户表user:
CREATE TABLE `user` (
`id` varchar(20),
`name` varchar(20),
`age` numeric(3,0)
)假设数据库给每个字段分配了最大容量,即id(20个字节)、name(20字节)、age(2字节),我们创建了如下3条记录:
| 记录1 | 1 | cary | 25 |
| 记录2 | 2 | harry | 26 |
| 记录3 | 3 | marry | 23 |
我们可知每行记录都占用了固定大小42Byte,一开始3条记录还是顺序存放的:
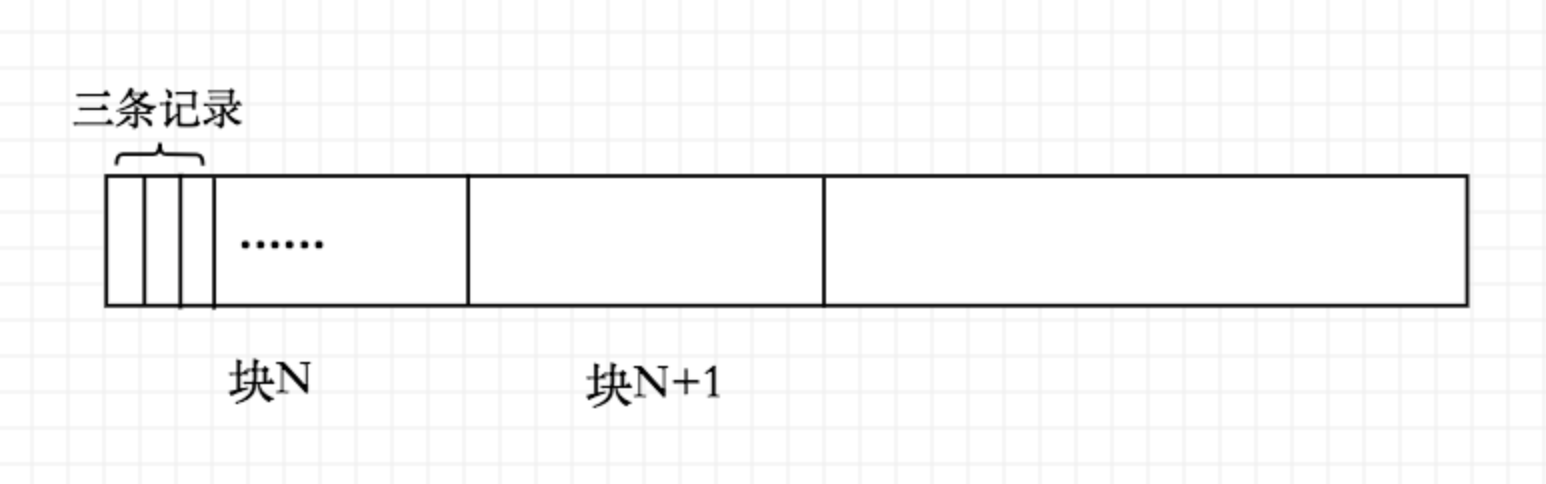
当我们执行查询操作:
select * from user where id=2;显然, 本次查询将对应块内容加载到内存后开始按行处理,筛选出所有id=2的数据,CPU执行模型如下 :
do begin
for each row in user {
if row.id=2 {
select row;
}
}
end整个过程的I/O复杂度为O(1)、CPU计算复杂度为O(3)。现在我们假设每行数据依然按序存放,但行数扩增为100万行:
| 记录1 | 1 | cary | 25 |
| 记录2 | 2 | harry | 26 |
| 记录3 | 3 | marry | 23 |
| ....... ....... ....... |
|||
| 记录999999 | 999999 | joke | 28 |
| 记录1000000 | 1000000 | zerui | 26 |
在不考虑块对齐的情况下,100万行数据将占用max(1000000*42Byte/4Kb)=42000个块,同样执行上述sql查询的情况下,I/O的复杂度为O(42000),CPU计算复杂度为O(1000000)。在如此量级条件下机器处理压力将大幅上升,并且随着表数据的不断增加,复杂度呈线性增加状态,这绝对是不可接受的!
因此,必须要有一种技术来解决大量数据的检索问题,我们关注两个核心需求,一个是减少磁盘的I/O、一个是降低CPU的处理复杂度,索引应运而生。
索引的介绍
我们现在已经对数据查询有了基本的成本概念,这个成本体现在I/O和CPU处理上,索引如何解决这两个问题呢?
上文示例的user表数据结构中,我们假设了行数据在磁盘中按id顺序存放,当我们按id条件进行数据检索时,最简单的方式其实可以新增一个数据结构来做目标区间的定位:
| id值 | 目标记录块号 |
| 1 | N |
| 10000 | N+K |
| 20000 | N+2K |
| …… | |
| 1000000 | N+100K |
该结构描述了一个映射条件,左边是表id属性值,右边是对应记录在磁盘中的块号,当我们要查询id=100000的记录时,通过映射表我们可以预判目标记录放置在磁盘块区间[N+10K,N+11K],因此接下来OS只需驱动磁盘进行最多1K个块的读取操作,整个过程I/O复杂度最大为O(1K),CPU处理复杂度最大为O(10000),处理性能实现了10000倍的提高!
这样简单设计的数据结构我们称为顺序索引,索引信息同样放置在磁盘空间管理,但凡对id字段的检索,数据库会优先考虑从该索引表进行目标块定位,然后从目标块中检索目标信息。按照上诉设计的索引结构,区间划分的粒度为10000,可知总共有100行,假设每行记录我们设定10Byte空间存储,那么整个索引结构将占用1000Byte,不到1Kb,因此有些时候我们可以直接将索引结构预加载到内存,这样关于索引的查询过程将不涉及到磁盘的I/O消耗,这为我们优化查询速度提供了新的思路!
但是,顺序索引结构的简单是基于行记录在磁盘存储上的苛刻要求下所支持的,行记录必须按照id值在磁盘中按序存放。现实业务环境下,数据有较高的复杂度和变动频率,一些行数据会被删除,腾出的空间会被其它后续插入的行给占用,后续插入的记录在磁盘中也可能呈现随机状态。而一旦目标行数据不按顺序存放,那么顺序索引关于块区间的划分将毫无意义!
| 记录1 | 1 | cary | 25 | |
| 记录2 | 2 | harry | 26 | |
| 记录3 | 897 | karry | 24 | 原来id=3的记录被删除,后续插入了id为897的记录 |
这里,我们介绍新的一种数据结构:二叉树,当目标数据在磁盘的存放呈现离散随机状态时,我们依然希望能很好地实现快速检索。
在二叉树的基础上我们增加如下条件:左子节点小于根节点,右子节点大于或等于根节点,假设user表有id为2、3、5、6、7、8的记录,那么将有如下形态:
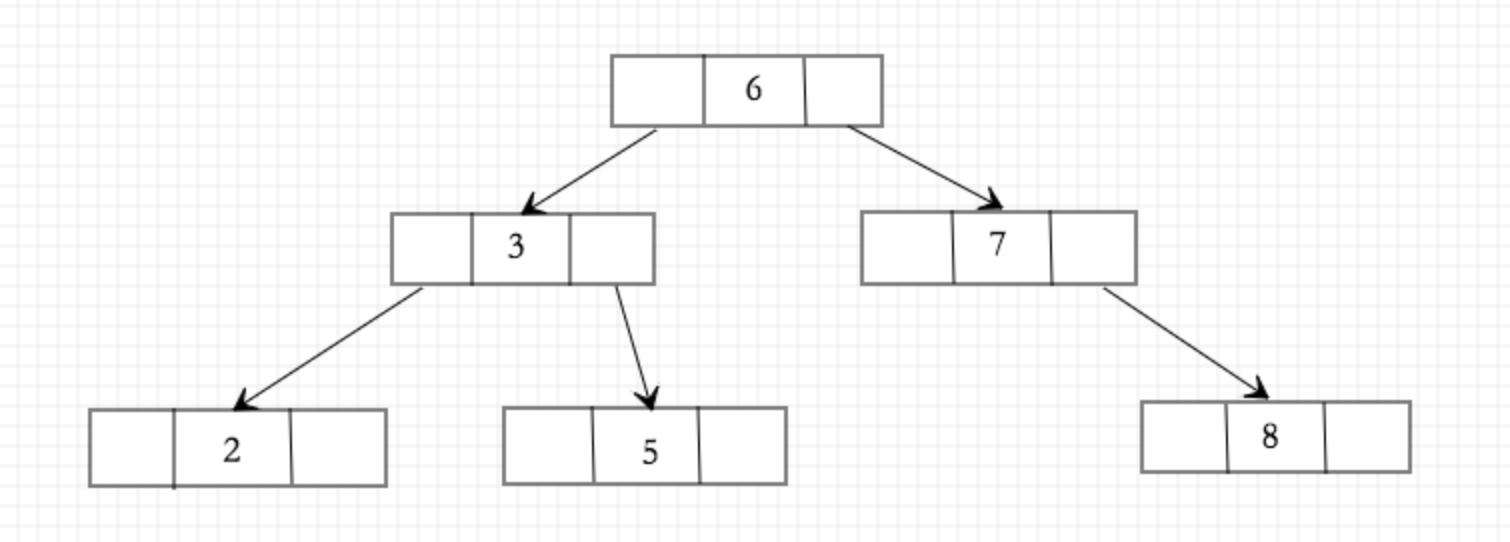
由此构建的索引结构包含了id属性所有值的情况,对100万行的数据来说,该索引结构就有100万个节点,每个节点还包含了该id对应记录在磁盘中的具体位置,当查询id=3的记录时,我们发现经过根节点的判断后,左指针刚好指向节点为3的内容,由此可获取记录最终的磁盘位置。
那么如何分析二叉树索引结构带来的成本问题?通过该结构规则,其实相当于对记录进行了二分法操作,从数学的角度讲,每次判断都是一次半数的数量级检索。上述示例总共6条记录我们最多只需进行log2N=6即N=3的判断次数,对于100万个节点的索引结构,我们查询id最多需要log2N=1000000即N=20的节点获取,也就是磁盘I/O复杂度最大为O(20),假设目标记录增长为1000万行,I/O复杂度也不过是O(23),I/O复杂度和目标记录行数呈现出的指数关系极大缓解了I/O成本上升的趋势!
I/O复杂度和二叉树的高度是存在直接关系的,100万个节点需要构造最多20层高度的二叉树,假设每个节点内容包含:左指针(4Byte)、id值(8Byte)、右指针(4Byte)、目标记录指针(4Byte),总共占据20Byte,那么索引将至少占据20Byte*1000000=20Mb的存储空间,最理想的情况是将索引结构直接加载到内存,这样只需在内存消耗O(20),但区别于不同的机器性能,20Mb对于珍贵的内存资源还是稍显奢侈,能否在磁盘上减少索引层面的I/O次数呢?
我们在二叉树索引构造中,每次I/O的成本带来的是一半数据的过滤功效,在此基础上我们希望能更大限度地提升下过滤的量级。我们把思路扩展到n叉树中,对于n叉树我们能得到lognN的指数模型,其中n代表每个节点的下级指针个数,假设n=10那么log10N=1000000就有N=5即O(5)的复杂度,这相对于O(20)又是4倍的I/O性能提升,关于n叉数我们设计了如下形态:
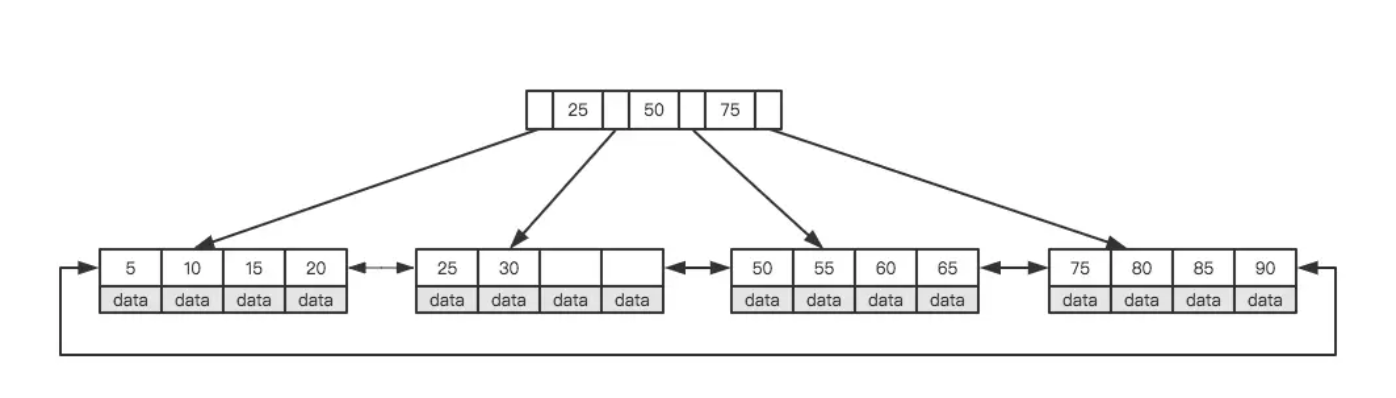
每个节点将有四个指针,每个指针同样遵循上诉二叉树的设定规则:id值左边指针指向小于该id的下级范围,id值右边指针指向大于该id值的下级范围。整个n叉树我们直观上明显更“胖”了,意味着一次节点I/O后我们对目标数据能做出更大量级的细分!通过上文关于磁盘I/O的介绍,我们了解到磁盘以每个块作为最小操作单位,因此当前很多数据库产品在设计n叉树时有意地将一个块大小作为一个叶节点的大小,假设上诉叶节点不同元素占用情况为:左右指针各占4Byte,id值8Byte,目标记录指针4Byte,那么一个4Kb的磁盘块将大致可以容纳250个下级指针,100万行目标记录只需log250N=1000000即N=3的I/O次数,充分提升了每次节点I/O带来的检索效用!
因此,了解当前数据库表采用的索引构造,通过数学问题我们就可以很好的对实际项目中的一些查询做好成本分析,特别是大数据环境下,在预估查询时间时能很好地得出相应的性能表现。
当前不同数据库产品在设计索引时考虑了实际的应用场景,数据库表文件在磁盘的存放方式决定了需要采用怎样的索引结构。对于磁盘中按序存放的目标数据往往通过顺序索引就能实现快速检索,像一些大数据产品本身专注于查询性能,表数据往往只能进行数据追加而不支持删改操作,每次表数据的删改变动必须进行全局的格式化,这就是为了要保证数据在磁盘中的按序存放。而诸如mysql事务性数据库,针对的更多是常规业务操作,数据的增删改查是必须充分支持的,数据在磁盘的分布较为复杂,索引的设计上往往采用的是树形结构。
后语
关于索引的设计是一个较为复杂的过程,本文更多是希望在大脑中构造出数据查询中I/O成本分析的思考模型。索引极大的提升了数据库数据的查询速度,但我们也应该清楚的认识到,关于索引本身结构的维护也是一个不小的工程,不同索引结构本身的复杂性直接关系到索引结构本身维护过程中需要承担的I/O复杂度和CPU计算复杂度,关于索引的构建和维护可以另行查阅相关资料进行了解。
