

Redux解决的问题
JavaScript 需要管理比任何时候都要多的 state (状态)
state 在什么时候,由于什么原因,如何变化已然不受控制。
通过限制更新发生的时间和方式,Redux 试图让 state 的变化变得可预测。
Redux设计分析
三个原则
- 单一数据源
- state是只读的 不可写(想要修改就必须按照redux的单向数据流逻辑来操作),是实现单向数据流的根本保障
- 使用纯函数来执行修改 纯函数意味着依赖单一,我们只需要派发一个用于描述state变化的action即可。 这让时间旅行、记录和热更新成为可能 尽可能的简化单向数据流,不需要魔法
流程图
action => middleware => reducer(s) => Store
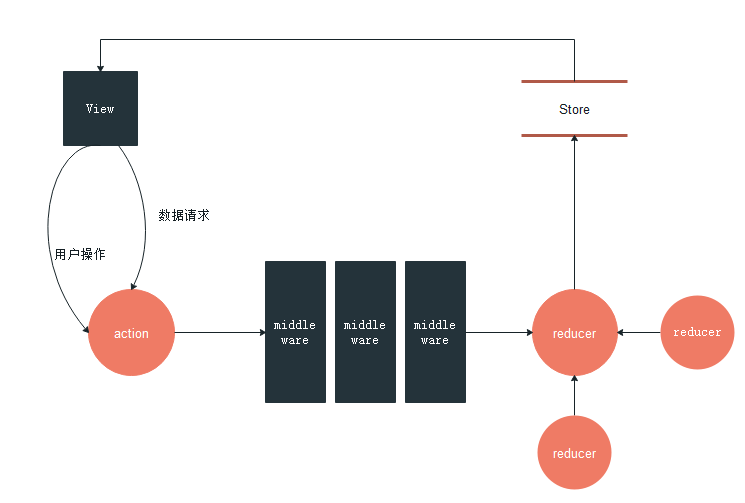
功能设计
- createStore(rootReducer, initStore, middleware). 创建store
- applyMiddleware(...middlewares). 使用中间件 链式使用
- compose(...fn). 嵌套函数
- combineReducers(...reducer). 组合reducer
- bindActionCreator(actionCreators, dispatch). 封装多个action
这是redux提供的几个关键文件和它们的作用,其实简单他们提供的功能不难发现他们函数式编程的影子。redux里面设计比较巧妙的点个人感觉是在中间件里。middleware在redux中被设计为在action发起后,到达reducer之前的拓展点。我们可以利用middleware实现类似日志记录,错误定位或者路由,还有异步处理action这些操作。
关键点分析
redux的源码是比较典型的FP风格,掌握一些基本FP概念,再去阅读redux源码会轻松很多
- 高阶函数
Higher order functions can take functions as parameters and return functions as return values.
接受函数作为参数传入,并能返回封装后函数。
- 科里化
Currying > Currying is the technique of translating the evaluation of a function that takes multiple arguments into evaluating a sequence of functions, each with a single argument
是把接受多个参数的函数变换成接受一个单一参数(最初函数的第一个参数)的函数,并且返回接受余下的参数而且返回结果的新函数的技术。 add(1,2,3) => add(1)(2)(3)
-
Compose > Composes functions from right to left. 组合函数,将从右向左执行。
compose(subtract,multiple,add)(200) 等同于 subtract(multiple(add(200)));
内部使用reduce,而不是直接嵌套。
单向数据流
store.dispatch(action) => middleware =>reducer => store
贴上实现单向数据流的关键源码(部分删减)
dispatch函数的实现 (/createStore.js)
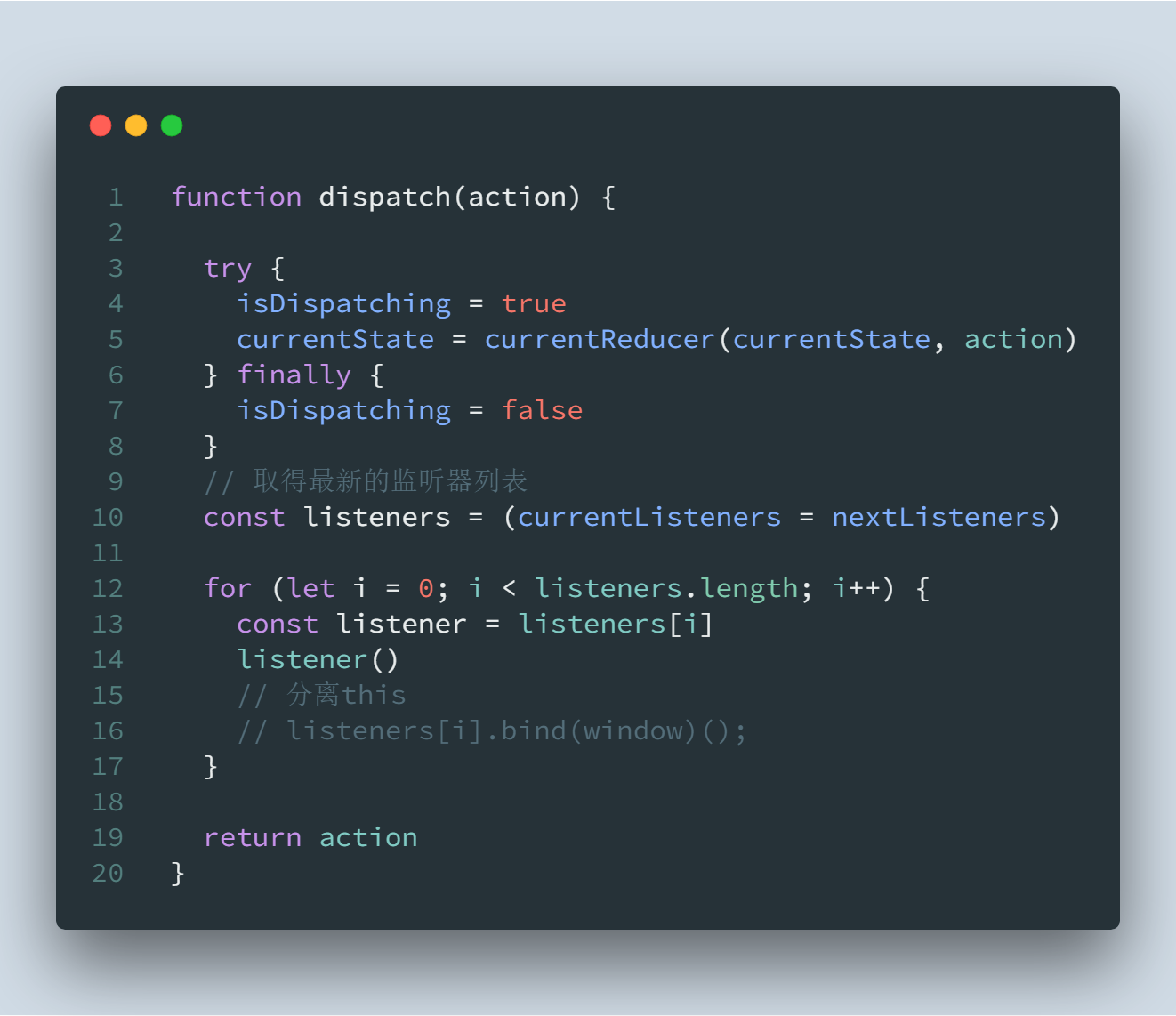
isDispatching变量用来控制在reducer函数执行过程中不允许再次dispatch,这个过程用try/finally提供可靠性;第十行取得当前监听器函数列表的快照,在for循环中依次执行,这里执行也是有讲究,并没有直接listener[i]()调用,而是采用了分割this的行为逐个调用监听器函数。总结这个dispatch函数关键点如下
- 状态位控制流程,在reducer过程中不允许dispatch
- 用快照的形式存储监听器列表,避免在监听器函数中调用subscribe函数引发的不可预期行为
- 隔离监听器this,营造私有变量。
combineReducer函数的实现(/combineReducers.js)
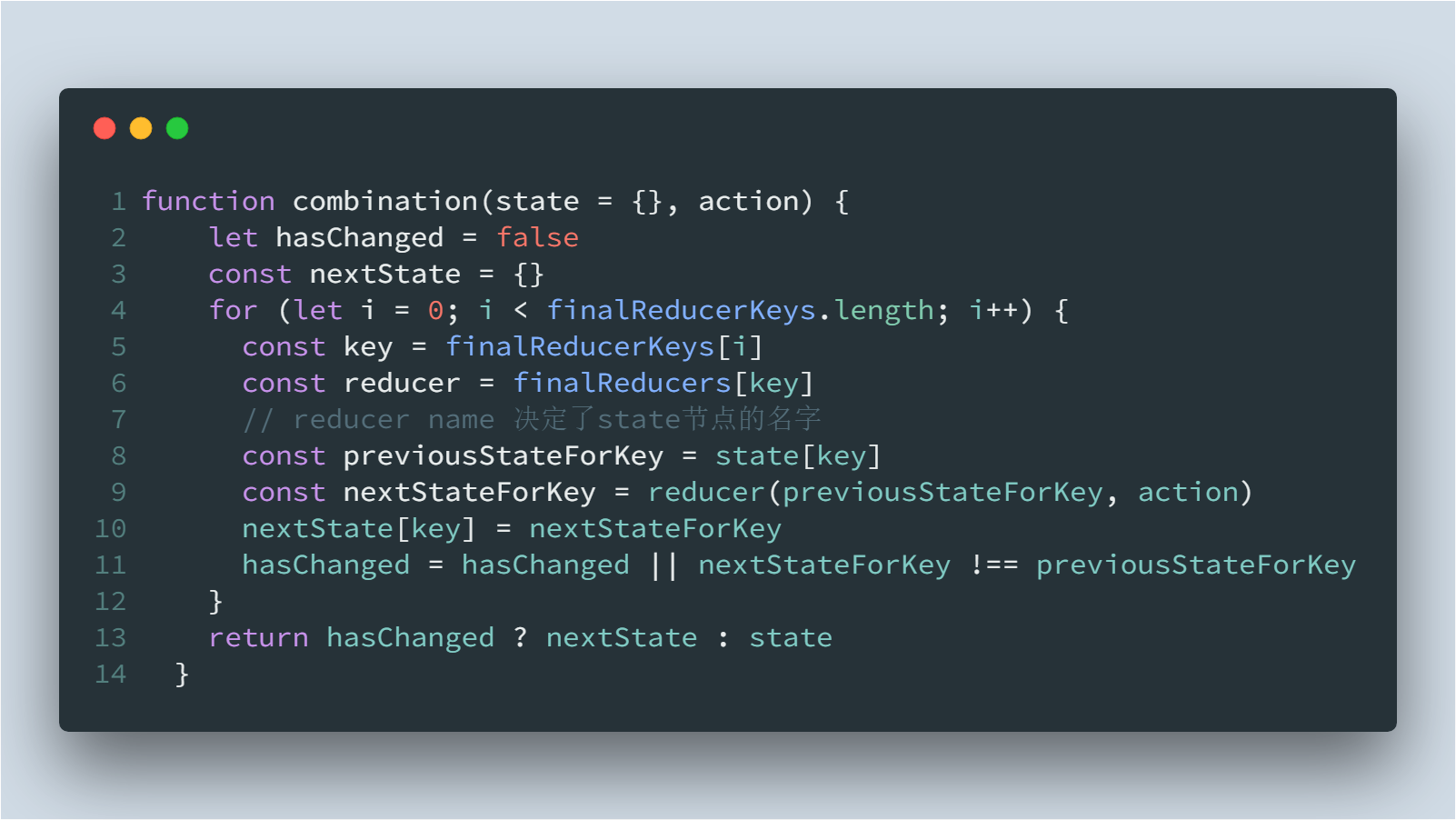
- reducer name 决定了state节点的key 调用由store提供的dispatch函数,即可触发reducer,将返回的state更新,并触发state监听器列表中的方法。
中间件到底做了什么
中间件发挥作用的时间点在派发action后,达到reducer前,可以理解为在调用原生dispatch(action)前,使用了中间件。 与其按照时间节点来理解,倒不如说中间件是为了增强dispatch函数而做的设计 applyMiddleware的源码非常精炼
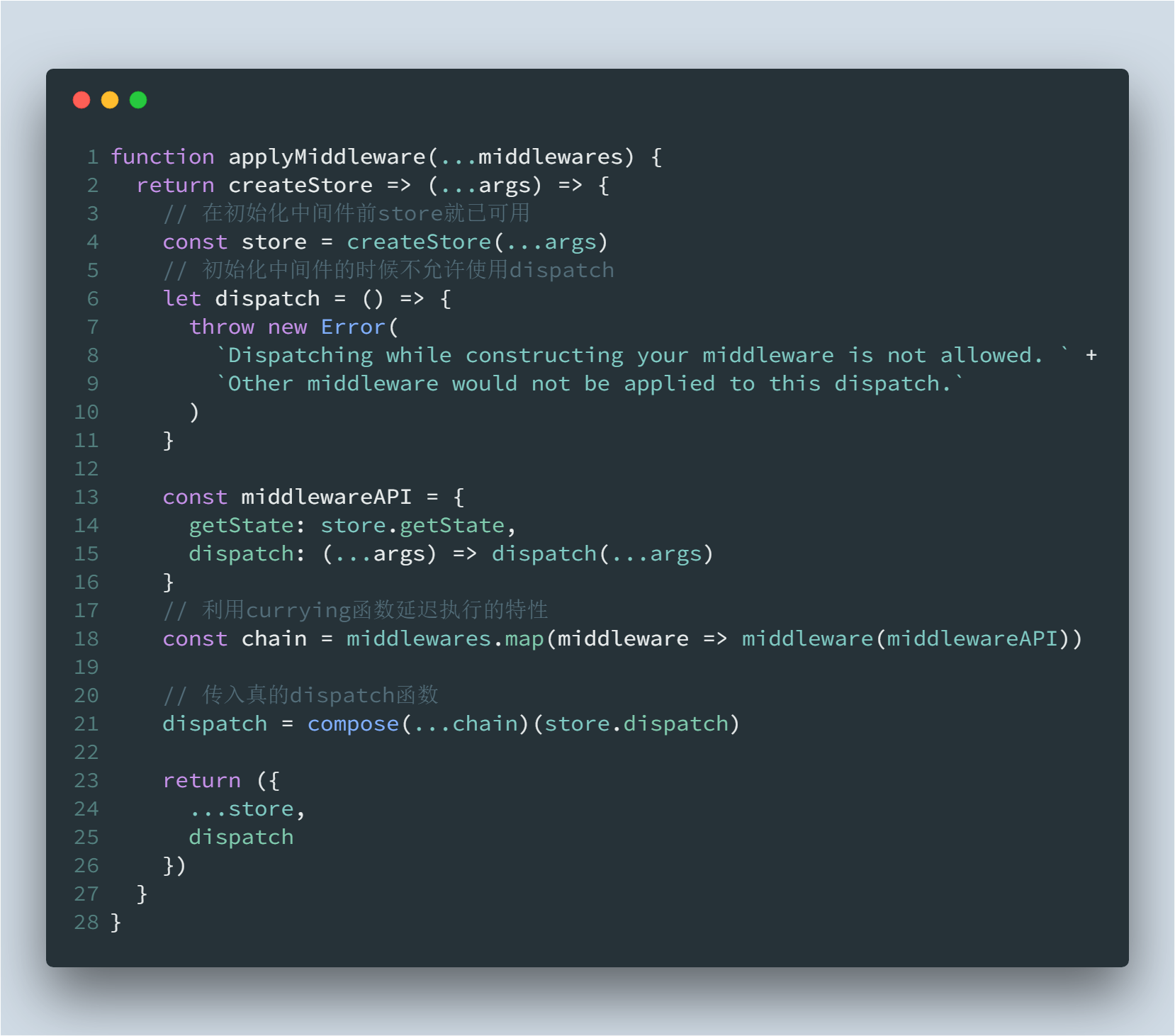
- 如何让中间件都可以获取到state
- 如何让中间件可链式使用
- 中间件的函数签名为什么是middleware = store => next => action => { next(action) }
如何让中间件都可以获取到state
这里声明了一个middlewareAPI,通过里面的getState方法就可以拿到store里的数据,另外一个dispatch并没有什么实际的作用,就算调用了,它也会告诉你不能使用,这里利用map将middlewareAPI传入到每个中间件里,构造了一个闭包,让中间件可以访问到state数据,这里也利用了currying函数延迟执行的特性,它接受了参数执行但是返回的是另外一个待执行的函数。 如此就保证了每个中间件可以获取到state,关键点在于中间件科里化的设计,让其可以延迟执行和参数复用。
const middlewareAPI = { getState: store.getState, dispatch: (...args) => dispatch(...args) }
// 利用currying函数延迟执行的特性
如何让中间件可链式使用
如何将中间件串联起来,并保存最后一个函数传入的参数为store.dispatch 想实现这个特性就要用到compose组合函数, 将中间件串联起来,并且最后一个函数入参为store.dispatch, 传入的next就是下一个中间件,当然最后一个函数接受的next就是原生的store.dispatch,那个时候中间件就处理完毕,将action派发到reducer了。
const a = next => action => next(action)
const b = next => action => next(action)
const c = dispatch => action => dispatch(action)
compose(c, b, a)(store.dispatch)
// 源码实现 dispatch = compose(...chain)(store.dispatch)
中间件的函数签名
函数签名middleware = store => next => action => { next(action) }
其实看到这里应该也大致明白了为什么要这么设计中间件,返回的第一个函数是为了保证中间件可以取到全局状态,返回的第二个函数是为了保证中间件可以依次调用。redux里的中间件是一个科里化的函数,其主要目的是为了利用其延迟计算和参数复用的能力,来实现中间件的众多特性。
一些遗憾
redux虽然为我们解决了state的管理问题,但依然不是百分之百的完美。逻辑上redux提供了一套简单可行且非常清晰规范的state管理方案,数据的单数据流和其三个原则,与之带来的是会写一些模板代码,如果使用了中间件,特别是redux-saga那种独立规范特别多的中间件,会耗费我们很多的时间在写模板上,虽然我们可以对数据流动掌控的特别精细,但是时间成本依然减缓了我们开发的效率。
改进方案
redux的改进应该在保留优势设计,解决痛点的基础上进行。其实在多数开发者使用redux时一般会对其做简单的封装再使用,对redux增加一些设计模式或是使用企业内部的diapatch增强方法,这里抛砖引玉,提出几个redux理想改进的几个需要注意的地方
- 尽可能保留redux的核心概念,降低学习成本
- 减少redux模板代码,可以从提高复用性和提供内置模板的角度来减少开发者的重复工作
- 能无缝接入redux的生态,支持中间件,enhancer
- 保留redux的特性,保留其三个原则
- 如何简单抽象action和reducer之间的关系是一个非常重要的思考点
- 提供对复杂场景的功能支持,比如动态增加reducer,提供多个store实例
