


MySQL的索引有很多种类型,可以为不同的场景提供更好的性能。而B-Tree索引是最为常见的MySQL索引类型,一般谈论MySQL索引时,如果没有特别说明,就是指B-Tree索引。本文就详细讲解一下B-Tree索引的的底层结构,使用原则和特性。 为了节约你的时间,本文的主要内容如下:
- B-Tree索引的底层结构
- B-Tree索引的使用规则
- 聚簇索引
- InnoDB和MyISAM引擎索引的差异
- 松散索引
- 覆盖索引
B-Tree索引
B-Tree索引使用B-Tree来存储数据,当然不同存储引擎的实现方式不同。B-Tree通常意味着所有的值都是按顺序存储的,并且每一个叶子页到根的距离相同,图1展示了B-Tree索引的抽象表示,由此可以看出MySQL的B-Tree索引的大致工作机制。
B-Tree索引的底层数据结构一般是B+树,其具体数据结构和优势这里就不作详细描述,下图展示了B-树索引的抽象表示,大致反应了MyISAM索引是如何工作的,而InnoDB使用的结构有所不同。
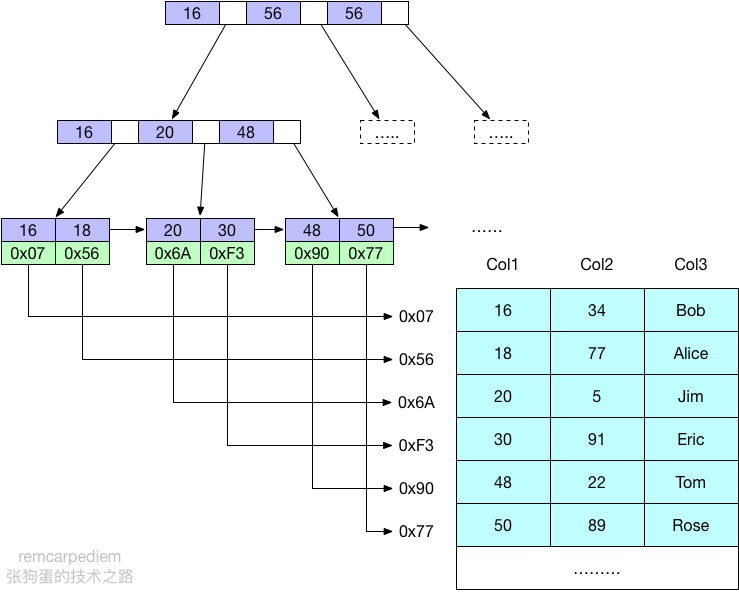
MySQL可以在单独一列上添加B-Tree索引,也可以在多列数据上添加B-Tree索引,多列的数据按照添加索引声明的顺序组合起来,存储在B-Tree的页中。假设有如下数据表:
CREATE TABLE People (
last_name varchar(50) not null,
first_name varchar(50) not null,
birthday date not null,
gender enum('m','f') not null
key(last_name, first_name, birthday)
);
对于表中的每一行数据,索引中包含了last_name,first_name和birthday列的值,下图展示了该索引是如何组织数据的存储的。
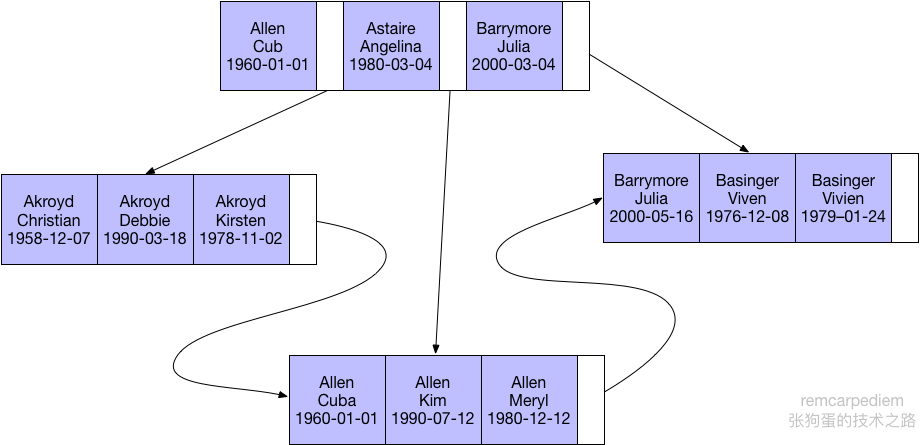
B-Tree索引使用B-Tree作为其存储数据的数据结构,其使用的查询规则也由此决定。一般来说,B-Tree索引适用于全键值、键值范围和键前缀查找,其中键前缀查找只适用于根据最左前缀查找。B-Tree索引支持的查询原则如下所示:
-
全值匹配:全值匹配指的是和索引中的所有列进行匹配,
-
匹配最左前缀:前边提到的索引可以用于查找所有姓Allen的人,即只使用索引中的第一列。
-
匹配列前缀:也可以只匹配某一列的值的开头部分。例如前面提到的索引可用于查找所有以J开头的姓的人。这里也只用到了索引的第一列。
-
匹配范围值:例如前边提到的索引可用于查找姓在Allen和Barrymore之间的人。这里也只使用了索引的第一列。
-
精确匹配某一列并范围匹配另外一列:前边提到的索引也可用于查找所有姓为Allen,并且名字是字母K开头(比如Kim,Karl等)的人。即第一列last_name全匹配,第二列first_name范围匹配。
因为索引树的节点是有序的,所以除了按值查找之外,索引还可以用于查询中的ORDER BY操作(按顺序查找),如果ORDER BY子句满足前面列出的几种查询类型,则这个索引也可以满足对应的排序需求。
下面是一些关于B-Tree索引的限制:
- 如果不是按照索引的最左列开始查找,则无法使用索引。例如上面例子中的索引无法查找名字为Bill的人,也无法查找某个特定生日的日,因为这两列都不是最左数据列。
- 如果查询中有某个列的范围查询,则其右侧所有列都无法使用索引优化查找。
聚簇索引
聚簇索引并不是一种单独的索引类型,而是一种数据存储方式。具体的细节依赖于其实现方式,但是InnoDB的聚簇索引实际上在同一个结构中保存了B-Tree索引和数据行。
当表有聚簇索引时,它的数据行实际上存放在索引的叶子页中,这也就是说数据行和相邻的键值紧凑地存储在一起。
下图展示了聚簇索引中的记录是如何存放的。注意到,叶子页包含了行的全部数据行,但是节点页只包含了索引列。
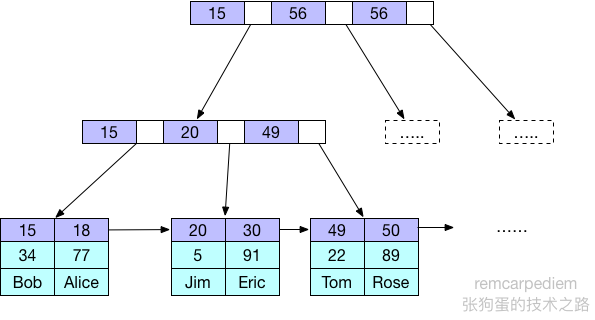
聚簇索引可能对性能有帮助,但也可能导致严重的性能问题。聚簇的数据是有一些重要的优点:
- 数据访问更快,聚簇索引将索引和数据保存在同一个B-Tree中,因此从聚簇索引中获取数据通常比在非聚簇索引中查找要快。
- 使用覆盖索引扫描的查询可以直接使用页节点中的主键值。
如果在设计表和查询时能充分利用上面的优点,那么就能极大地提升性能。同时,聚簇索引也有一些缺点:
- 插入顺序严重依赖插入顺序。按照主键的顺序插入是向InnoDB表中插入数据速度最快的方式,需要避免主键键值随机的(不连续且值得分布范围非常大)聚簇索引,比如使用UUID作为主键,而应该使用类似AUTO_INCREMENT的自增列。
- 更新聚簇索引列的代价很高,因为会强制InnoDB将每个被更新的行移动位置到新的位置。
- 基于聚簇索引的表在插入新行,或者主键被更新导致需要移动行时,可能面临“页分裂”的问题。当行的主键值要求必须将这行插入到某个已满的页中时,存储引擎会将该页分裂成两个页面来容纳该行,这就是一次页分裂操作。页分裂会导致表占用更多的磁盘空间
- 二级索引可能比想象的更大,因为在二级索引中的叶节点包含了引用行的主键列
- 二级索引访问需要两次索引查找,而不是一次。
InnoDB和MyISAM的索引区别
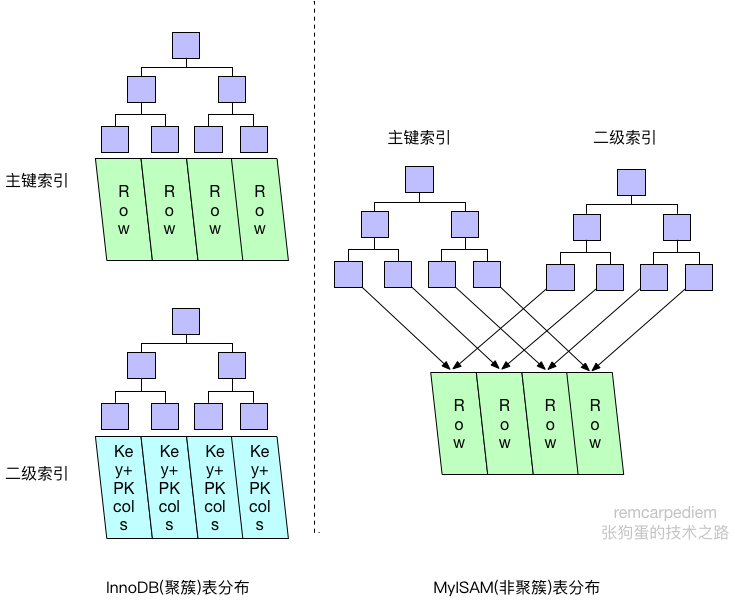
聚簇索引和非聚簇索引的数据分布有区别,以及对应的主键索引和二级索引的数据分布也有区别,通常会让人感到困惑和意外。下图展示了MyISAM和InnoDB的不同索引和数据存储方式。
MyISAM的数据分布非常简单,按照数据插入的顺序存储在磁盘上,主键索引和二级索引的叶节点存储着指针,指向对应的数据行。
InnoDB中,聚簇索引“就是”表,所以不会像MyISAM那样需要独立的行存储。聚簇索引的每个叶节点都包含了主键值和所有的剩余列(在此例中是col2)。
InnoDB的二级索引和聚簇索引很不同。InnoDB二级索引的叶节点中存储的不是“行指针”,而是主键值,并以此作为指向行的“指针”。
松散索引扫描
MySQL并不支持松散索引扫描,也就是无法按照不连续的方式扫描一个索引。通常,MySQL的索引扫描需要先定义一个起点和终点,即使需要的数据只是这段索引中很少数的几个,MySQL仍然需要扫描这段索引中的每个条目。
下面,我们通过一个示例说明这点,假设我们有如下索引(a,b),有下面的查询:
mysql>SELECT * FROM tb1 WHERE b BETWEEN 2 AND 3;
因为索引的前导字段是列a,但是在查询中只指定了字段b,MySQL无法使用这个索引,从而只能通过全表扫描找到匹配的行,如下图所示。
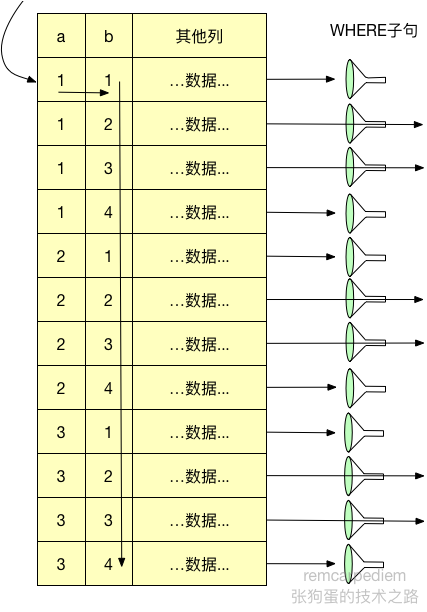
了解索引的物理结构的话,不难发现还可以有一个更快的办法执行上面的查询。索引的物理结构(不是存储引擎的API)是的可以先扫描a列第一个值对应的b列的范围,然后再跳到a列第二个不不同值扫描对应的b列的范围。下图展示了如果由MySQL来实现这个过程会怎样。
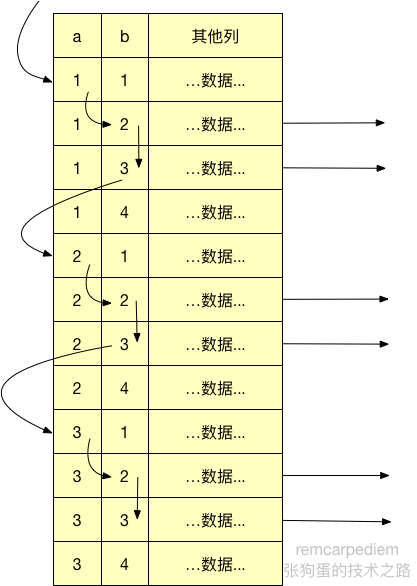
注意到,这时就无须再使用WHERE子句过滤,因为松散索引扫描已经跳过了所有不需要的记录。
MySQL 5.0之后的版本,在某些特殊的场景下是可以使用松散索引扫描的,例如,在一个分组查询中需要找到分组的最大值和最小值:
mysql> EXPLAIN SELECT actor_id, MAX(film_id)
-> FROM sakila.film.film_actor
-> GROUP BY actor_id;
********************************************* 1. row ***********************************
id: 1
select_type: SIMPLE
table: film_actor
type: range
possible_keys: NULL
key: PRIMARY
key_len: 2
ref: NULL
rows: 396
Extra: Using index for group-by
在EXPLAIN中的Extra字段显示"Using index for group-by",表示这里将使用松散索引扫描。
覆盖索引
索引除了是一种查找数据的高效方式之外,也是一种列数据的直接获取方式。MySQL可以使用索引来直接获取列的数据,这样就不需要读取数据行。如果一个索引包含所有需要查询的字段的值,我们就称之为“覆盖索引”。 覆盖索引是非常有用的工具,能够极大地提高性能。SQL查询只需要扫描索引而无需回表,会带来很多好处:
- 索引条目数量和大小通常远小于数据行的条目和大小,所以如果只需要读取索引,那么MySQL就会极大地减少数据访问量。
- 因为索引是按照列顺序存储的,所以对于I/O密集型的范围查找会比随机从磁盘读取每一行数据的I/O要少的多。
- 由于InnoDB的聚簇索引,覆盖索引对InnoDB表特别有用。InnoDB的二级索引在叶子节点中保存了行的主键,索引如果二级主键能够覆盖查询,则避免对主键索引的第二次查询。
当发起一个被覆盖索引的查询(也叫索引覆盖查询)时,在EXPLAIN的Extra列可以看到"Using Index"的信息。例如,表sakila.inventory有一个多列索引(store_id, film_id)。MySQL如果只需要访问这两列,就可以使用这个索引做覆盖索引,如下所示:
mysql> EXPLAIN SELECT store_id, film_id FROM sakila.inventory
*********************************1.row***************************************
id:1
select_type:SIMPLE
table:inventory
type:index
possible_keys:NULL
key:idx_store_id_film_id
key_len:3
ref:NULL
rows:4673
Extra:Using Index
订阅最新文章,欢迎关注我的微信公众号

参考:
- MySQL索引背后的数据结构及算法原理
- 《高性能MySQL》
