

原文链接:Graph Data Structures for Beginners
众成翻译地址:初学者应该了解的数据结构: Graph
系列文章,建议不了解图的同学慢慢阅读一下这篇文章,希望对你有所帮助~如果想深入理解图,那不建议阅读这篇基础文章,这里有更多深入的知识可以探索~以下是译文正文:
在这篇文章中,我们将要探索非线性的数据结构:图,将涵盖它的基本概念及其典型的应用。
你很可能在不同的应用中接触到图(或树)。比如你想知道从家出发怎么去公司最近,就可以利用图的(寻路)算法来得到答案!我们将探讨上述场景与其他有趣的情况。
在上一篇文章中,我们探讨了线性的数据结构,如数组、链表、集合、栈等。本文将以此(译者注:即线性数据结构,没看过前文也没关系,其实也很好懂)为基础。
本篇是以下教程的一部分(译者注:如果大家觉得还不错,我会翻译整个系列的文章):
初学者应该了解的数据结构与算法(DSA)
- 算法的时间复杂性与大 O 符号
- 每个程序员应该知道的八种时间复杂度
- 初学者应该了解的数据结构:Array、HashMap 与 List (译文)
- 初学者应该了解的数据结构: Graph 👈 即本文
- 初学者应该了解的数据结构:Tree (敬请期待)
- 附录 I:递归算法分析
以下是本文对图操作的小结:
| 邻接表 | 邻接矩阵 | |
|---|---|---|
| 空间复杂度 | O(|V|+ |E|) | O(|V|²) |
| 添加顶点 | O(1) | O(|V|²) |
| 移除顶点 | O(|V| + |E|) | O(|V|)² |
| 添加边 | O(1) | O(1) |
| 移除边 (基于 Array 实现) | O(|E|) | O(1) |
| 移除边 (基于 HashSet 实现) | O(1) | O(1 |
| 获取相邻的顶点 | O(|E|) | O(|V|) |
| 判断是否相邻 (基于 Array 实现) | O(|E|) | O(1) |
| 判断是否相邻 (基于 HashSet 实现) | O(1) | O(1) |
图的基础
图是一种(包含若干个节点),每个节点可以连接 0 个或多个元素
两个节点相连的部分称为边(edge)。节点也被称作顶点(vertice)。
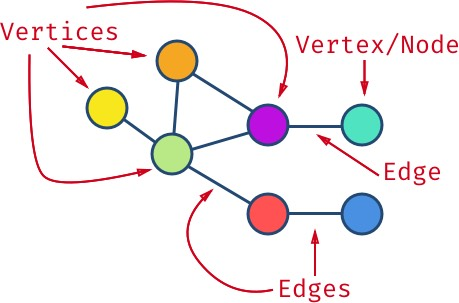
一个顶点的**度(degree)**是指与该顶点相连的边的条数。比如上图中,紫色顶点的度是 3,蓝色顶点的度是 1。
如果所有的边都是双向(译者注:或者理解为没有方向)的,那我们就有了一个无向图(undirected graph)。反之如果边是有向的,我们得到的就是有向图(directed graph)。你可以将有向图和无向图想象为单行道或双行道组成的交通网。
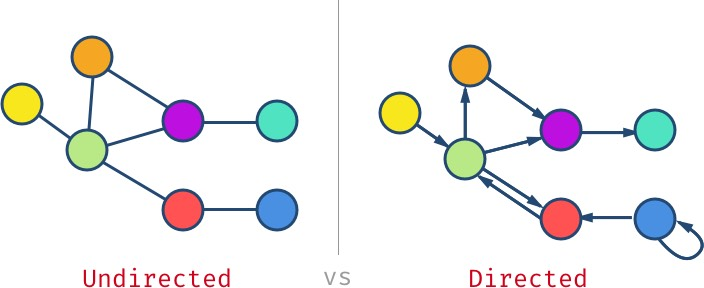
顶点的边可以是从自己出发再连接回自己(如蓝色的顶点),拥有这样的边的图被称为自环。
图可以有环(cycle),即如果遍历图的顶点,某个顶点可以被访问超过一次。而没有环的图被称为无环图(acyclic graph)。
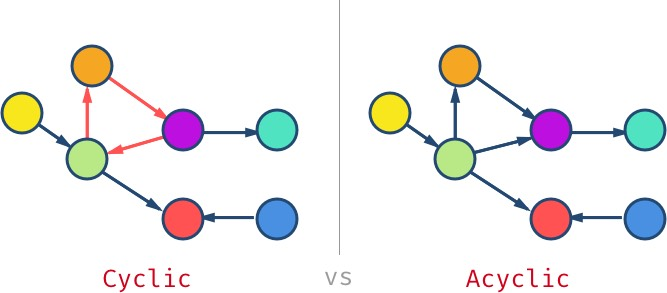
此外,无环无向图也被称为树(tree)。在下篇文章中,我们将深入套路这种数据结构。
在图中,从一个顶点出发,并非所有顶点都是可到达的。可能会存在孤立的顶点或者是相分离的子图。如果一个图所有顶点都至少有一条边(译者注:原文表述有点奇怪,个人认为不应该是至少有一条边,而是从任一节点出发,沿着各条边可以访问图中任意节点),这样的图被称为连通图(connected graph)。而当一个图中两两不同的顶点之间都恰有一条边相连,这样的图就是完全图(complete graph)。
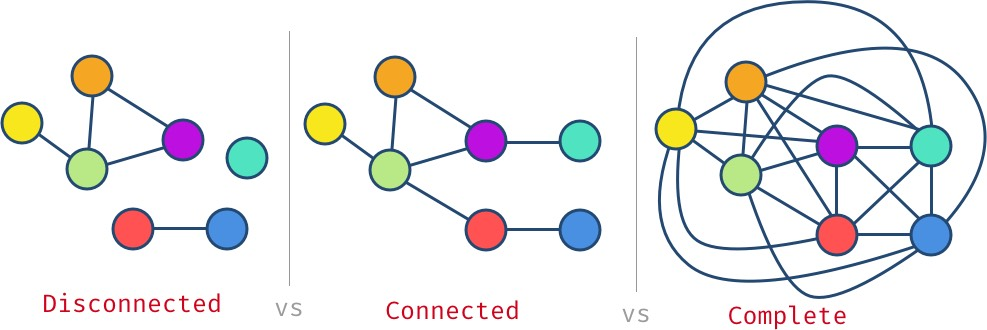
对于完全图而言,每个顶点都有 图的顶点数 - 1 条边。在上面完全图的例子中,一共有7个顶点,因此每个顶点有6条边。
图的应用
当图的每条边都被分配了权重时,我们就有了一个加权图(weighted graph)。如果边的权重被忽略,那么可以将(每条边的)权重都视为 1(译者注:权重都是一样,也就是无权重)。
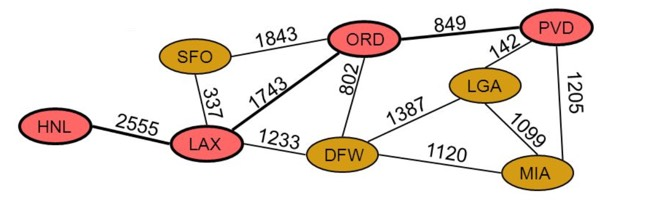
加权图应用的场景很多,根据待解决问题主体的不同,有不同的展现。一起来看一些具体的场景吧:
-
航空线路图 (如上图所示)
- 顶点 = 机场
- 边 = 两个机场间的飞行线路
- 权重 = 两个机场间的距离
-
GPS 导航
- 顶点 = 交叉路口
- 边 = 道路
- 权重 = 从一个路口到另一个路口所花的时间
-
网络
- 顶点 = 服务器
- 边 = 数据链路
- 权重 = 连接速度
一般而言, 图在现实世界中的应用有:
- 电子电路
- 航空控制
- 行车导航
- 电信设施: 基站建设规划
- 社交网络: Facebook 利用图来推荐(你可能认识的)朋友
- 推荐系统: Amazon/Netflix 利用图来推荐产品与电影
- 利用图来规划物流线路
我们学习了图的基础以及它的一些应用场景。接下来一起学习怎么使用代码来表示图。
图的表示
图的表示有两种主要方式:
- 邻接表
- 邻接矩阵
让我们以有向图为例子,阐述这两种表示方式:
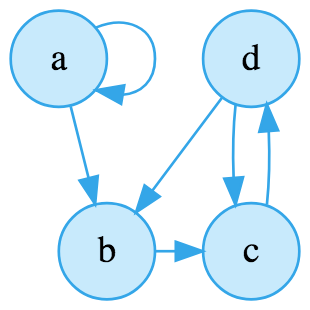
这是一个拥有四个顶点的图。当一个顶点有一条边指向它自身时(译者注:即闭合的路径),称之为自环(self-loop)。
邻接矩阵
邻接矩阵使用二维数组(N x N)来表示图。如若不同顶点存在连接的边,就赋值两顶点交汇处为1(也可以是这条边的权重),反之赋值为 0 或者 -。
我们可以通过建立以下的邻接矩阵,来表示上面的图:
a b c d e
a 1 1 - - -
b - - 1 - -
c - - - 1 -
d - 1 1 - -
如你所见,矩阵水平与垂直两个方向都列出了所有的顶点。如果图中只有很少顶点互相连接,那么这个图就是稀疏图(sparse graph)。如果图相连的顶点很多(接近两两顶点都相连)的话,我们称这种图为稠密图(dense graph)。而如果图的每个顶点都直接连接到除此之外的所有顶点,那就是一个完全图(complete graph)。
注意,你必须意识到对于无向图而言,邻接矩阵始终是对角线对称的。然而,对于有向图而言,并非总是如此(反例如上面的有向图)。
那查询两个顶点是否相邻的时间复杂度是什么呢?
在邻接矩阵中,查询两个顶点是否相邻的时间复杂度是 O(1)。
那空间复杂度呢?
利用邻接矩阵存储一个图,空间复杂度是 O(n²),n 为顶点的数量,因此也可以表示为 O(|V|²)。
添加一个顶点的时间复杂度呢?
邻接矩阵根据顶点的数量存储为 V x V 的矩阵。因此每增加一个顶点,矩阵需要重建为 V+1 x V+1 的新矩阵。
(因此,)在邻接矩阵中添加一个顶点的时间复杂度是 O(|V|²)。
如何获取相邻的顶点?
由于邻接矩阵是一个 V x V 的矩阵,为了获取所有相邻的顶点,我们必须去到该顶点所在的行中,查询它与其他顶点是否有边。
以上面的邻接矩阵为例,假设我们想知道与顶点 b 相邻的顶点有哪些,就需要到达记录 b 与其他节点关系的那一行中进行查询。
a b c d e
b - - 1 - -
访问它与其他所有顶点的关系,因此:
在邻接矩阵中,查询相邻顶点的时间复杂度是 O(|V|)。
想象一下,如果你需要将 FaceBook 中人们的关系网表示为一个图。你必须建立一个 20亿 x 20亿 的邻接矩阵,而该矩阵中很多位置都是空的。没有任何人可能认识其他所有人,最多也就认识几千个人。
通常,我们使用邻接矩阵处理稀疏图时,会浪费很多空间。这就是大多时候使用邻接表而不是邻接矩阵去表示一个图的原因(译者注:邻接矩阵也有优势的,尤其是表示有向稠密图时,比邻接表要方便得多)。
邻接表
表示一个图,最常用的方式是邻接表。每个顶点都有一个记录着与它所相邻顶点的表。
可以使用一个数组或者 HashMap 来建立一个邻接表,它存储这所有的顶点。每个顶点都有一个列表(可以是数组、链表、集合等数据结构),存放着与其相邻的顶点。
例如上面的图,对于顶点 a,与之相邻的有顶点 b,同时也是自环;而顶点 b 则有指向顶点 c 的边,如此类推:
a -> { a b }
b -> { c }
c -> { d }
d -> { b c }
和想象中的一样,如果想知道一个顶点是否连接着其他顶点,就必须遍历(顶点的)整个列表。
在邻接表中查询两个顶点是否相连的时间复杂度是 O(n),n 为顶点的数量,因此也可以表示为 O(|V|)。
那空间复杂度呢?
利用邻接表存储一个图的空间复杂度是 O(n),n 为顶点数量与边数量之和,因此也可以表示为 O(|V| + |E|)。
基于 HashMap 实现的邻接表
要表示一个图,最常见的方式是使用邻接表。有几种实现邻接表的方式:
最简单的实现方式之一是使用 HashMap。HashMap 的键是顶点的值,HashMap 的值是一个邻接数组(即也该顶点相邻顶点的集合)。
const graph = {
a:[ 'a','b' ],
b:[ 'c' ],
c:[ 'd' ],
d:[ 'b','c' ]
};
图通常需要实现以下两种操作:
- 添加或删除顶点。
- 添加或删除边。
添加或删除一个顶点需要更新邻接表。
假设需要删除顶点 b。我们不但需要 delete graph['b'],还需要删除顶点 a 与顶点 d 的邻接数组中的引用。
每当移除一个顶点,都需要遍历整个邻接表,因此时间复杂度是 O(|V| + |E|)。有更好的实现方式吗?稍后再回答这问题。首先让我们以更面向对象的方式实现邻接表,之后切换(邻接表的底层)实现将更容易。
基于邻接表,以面向对象风格实现图
先从顶点的类开始,在该类中,除了保存顶点自身以及它的相邻顶点集合之外,还会编写一些方法,用于在邻接表中增加或删除相邻的顶点。
class Node {
constructor(value) {
this.value = value;
this.adjacents = []; // adjacency list
}
addAdjacent(node) {
this.adjacents.push(node);
}
removeAdjacent(node) {
const index = this.adjacents.indexOf(node);
if (index > -1) {
this.adjacents.splice(index, 1);
return node;
}
}
getAdjacents() {
return this.adjacents;
}
isAdjacent(node) {
return this.adjacents.indexOf(node) > -1;
}
}
注意,addAdjacent 方法的时间复杂度是 O(1),但删除相邻顶点的函数时间复杂度是 O(|E|)。如果不使用数组而是用 HashSet 会怎样呢?(删除相邻顶点的)时间复杂度会下降到 O(1)。但现在先让代码能跑起来,之后再做优化。
Make it work. Make it right. Make it faster.
现在有了 Node 类,是时候编写 Graph 类,它可以执行添加或删除顶点和边。
Graph.constructor
class Graph {
constructor(edgeDirection = Graph.DIRECTED) {
this.nodes = new Map();
this.edgeDirection = edgeDirection;
}
// ...
}
Graph.UNDIRECTED = Symbol('directed graph'); // one-way edges
Graph.DIRECTED = Symbol('undirected graph'); // two-ways edges
首先,我们需要确认图是有向还是无向的,当添加边时,这会有所不同。
Graph.addEdge
添加一条新的边,需要知道两个顶点:边的起点与边的终点。
addEdge(source, destination) {
const sourceNode = this.addVertex(source);
const destinationNode = this.addVertex(destination);
sourceNode.addAdjacent(destinationNode);
if(this.edgeDirection === Graph.UNDIRECTED) {
destinationNode.addAdjacent(sourceNode);
}
return [sourceNode, destinationNode];
}
我们往边的起点添加了一个相邻顶点(即边的终点)。如果该图是无向图,也需要往边的终点添加一个相邻顶点(即边的起点),因为(无向图中)边是双向的。
在邻接表中新增一条边的时间复杂度是:O(1)。
如果新添加的边两端的顶点并不存在,就必需先创建(不存在的顶底),下面让我们来实现它!
Graph.addVertex
创建顶点的方式是往 this.nodes 中新增一个顶点。this.nodes 中存储着的是一组组键值对,键是顶点的值,值是 Node 类的实例。注意看下面代码的 5-6 行(即 const vertex = new Node(value); this.nodes.set(value, vertex);):
addVertex(value) {
if(this.nodes.has(value)) {
return this.nodes.get(value);
} else {
const vertex = new Node(value);
this.nodes.set(value, vertex);
return vertex;
}
}
没必要覆写已存在的顶点。因此先检查一下顶点是否存在,如果不存在才创造一个新节点。
在邻接表中新增一个顶点的时间复杂度是: O(1)。
Graph.removeVertex
从一个图中删除一个顶点会相对麻烦一点。我们必须检查待删除的顶点是否为其他顶点的相邻顶点。
removeVertex(value) {
const current = this.nodes.get(value);
if(current) {
for (const node of this.nodes.values()) {
node.removeAdjacent(current);
}
}
return this.nodes.delete(value);
}
必须访问每个顶点及其它们的相邻顶点集合。
在邻接表中删除一个顶点的时间复杂度是: O(|V| + |E|)。
最后,一起来实现删除一条边吧!
Graph.removeEdge
删除一条边是十分简单的,与新增一条边类似。
removeEdge(source, destination) {
const sourceNode = this.nodes.get(source);
const destinationNode = this.nodes.get(destination);
if(sourceNode && destinationNode) {
sourceNode.removeAdjacent(destinationNode);
if(this.edgeDirection === Graph.UNDIRECTED) {
destinationNode.removeAdjacent(sourceNode);
}
}
return [sourceNode, destinationNode];
}
删除与新增一条边主要的不同是:
- 如果边两端的顶点不存在,不再需要创建它。
- 使用
Node.removeAdjacent而不是Node.addAdjacent。
由于 removeAdjacent 需要遍历相邻节点的集合,因此它的运行时是:
在邻接表中删除一条边的时间复杂度是: O(|E|)。
接下来,我们将讨论如何从图中搜索。
广度优先搜索(BFS) - 图的搜索
广度优先搜索是一种从最初的顶点开始,优先访问所有相邻顶点的搜索方法。
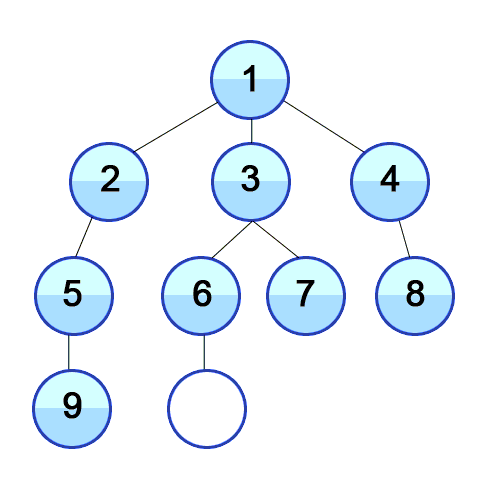
接下来一起看看如何用代码来实现它:
*bfs(first) {
const visited = new Map();
const visitList = new Queue();
visitList.add(first);
while(!visitList.isEmpty()) {
const node = visitList.remove();
if(node && !visited.has(node)) {
yield node;
visited.set(node);
node.getAdjacents().forEach(adj => visitList.add(adj));
}
}
}
正如你所见的一样,我们使用了一个队列来暂存待访问的顶点,队列遵循先进先出(FIFO)的原则。
同时也是用了 JavaScript generators,要注意函数名前面 *(,那是生成器的标志)。通过生成器,可以一次迭代一个值(即顶点)。对于巨型(包含数以百万计的顶点)的图而言是很有用的,很多情况下不用访问图的每一个顶点。
以下是如何使用上述 BFS 代码的示例:
const graph = new Graph(Graph.UNDIRECTED);
const [first] = graph.addEdge(1, 2);
graph.addEdge(1, 3);
graph.addEdge(1, 4);
graph.addEdge(5, 2);
graph.addEdge(6, 3);
graph.addEdge(7, 3);
graph.addEdge(8, 4);
graph.addEdge(9, 5);
graph.addEdge(10, 6);
bfsFromFirst = graph.bfs(first);
bfsFromFirst.next().value.value; // 1
bfsFromFirst.next().value.value; // 2
bfsFromFirst.next().value.value; // 3
bfsFromFirst.next().value.value; // 4
// ...
你可以在这找到更多的测试代码。
接下来该讲述深度优先搜索了!
深度优先搜索 (DFS) -图的搜索
深度优先搜索是图的另一种搜索方法,通过递归搜索顶点的首个相邻顶点,再搜索其他相邻顶点,从而访问所有的顶点。
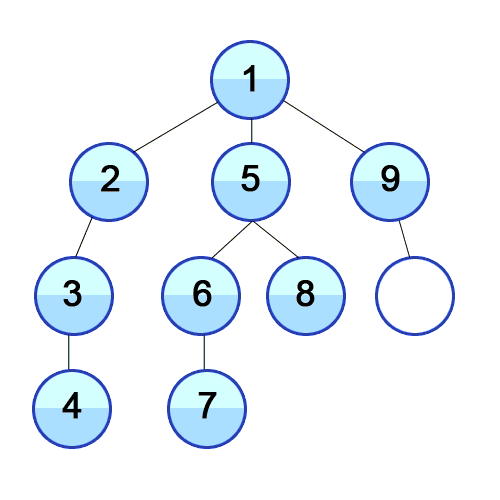
DFS 的实现近似于 BFS,但使用的是栈而不是队列:
*dfs(first) {
const visited = new Map();
const visitList = new Stack();
visitList.add(first);
while(!visitList.isEmpty()) {
const node = visitList.remove();
if(node && !visited.has(node)) {
yield node;
visited.set(node);
node.getAdjacents().forEach(adj => visitList.add(adj));
}
}
}
测试例子如下:
const graph = new Graph(Graph.UNDIRECTED);
const [first] = graph.addEdge(1, 2);
graph.addEdge(1, 3);
graph.addEdge(1, 4);
graph.addEdge(5, 2);
graph.addEdge(6, 3);
graph.addEdge(7, 3);
graph.addEdge(8, 4);
graph.addEdge(9, 5);
graph.addEdge(10, 6);
dfsFromFirst = graph.dfs(first);
visitedOrder = Array.from(dfsFromFirst);
const values = visitedOrder.map(node => node.value);
console.log(values); // [1, 4, 8, 3, 7, 6, 10, 2, 5, 9]
正如你所看到的,BFS 与 DFS 所用的图(的数据)是一样的,然而访问顶点的顺序却非常不一样。BFS 是从 1 到 10 按顺序输出,DFS 则是先进入最深处访问顶点(译者注:其实这个例子是先序遍历,看起来可能不太像先深入最深处)。
图的时间与空间复杂度
我们接触了图的一些基础操作,如何添加和删除一个顶点或一条边,以下是前文涵盖内容的小结:
| 邻接表 | 邻接矩阵 | |
|---|---|---|
| 空间复杂度 | O(|V|+ |E|) | O(|V|²) |
| 添加顶点 | O(1) | O(|V|²) |
| 移除顶点 | O(|V| + |E|) | O(|V|)² |
| 添加边 | O(1) | O(1) |
| 移除边 (基于 Array 实现) | O(|E|) | O(1) |
| 移除边 (基于 HashSet 实现) | O(1) | O(1 |
| 获取相邻的顶点 | O(|E|) | O(|V|) |
| 判断是否相邻 (基于 Array 实现) | O(|E|) | O(1) |
| 判断是否相邻 (基于 HashSet 实现) | O(1) | O(1) |
正如上表所示,邻接表中几乎所有的操作方法都是更快的。邻接矩阵比邻接表性能更高的方法只有一处:检查顶点是否与其他顶点相邻,然而使用 HashSet 而不是 Array 实现邻接表的话,也能在恒定时间内获取结果 :)
总结
图可以是很多现实场景的抽象,如机场,社交网络,互联网等。我们介绍了一些图的基础算法,如广度优先搜索(BFS)与深度优先搜索(DFS)等。同时权衡了图的不同实现方式:邻接矩阵和邻接表。我们将在另外一篇文章(更深入地)介绍图的其他应用,如查找图的两个顶点间的最短距离及其他有趣的算法(译者注:这篇文章介绍的比较基础,图的各种算法才是最有趣的,有兴趣的同学可以看这个)。
