pattern discovery
模式识别中的一些基本概念
- 模式:对于一个集合项,某些特定的子序列或者结构通常一起出现在数据集中
- absolute support :某一项出现的频率[数量]
- relative support: 某一项出现的频率
- frequent item:该项的support值大于最小support阈值
- association rules: X->Y(s,c) 在有X的前提下,有Y的概率是多少 s(support):support( x U y )[x和y都出现的数量];
- confidence:既包含x又包含y的概率,简记为c = sup(x U y) / sup(x)
- close pattern:子集x是频繁的。并且不存在一个x的父集y,是的y和x有一样的support值。它不会丢失频繁子集信息
- max pattern: 子集x是频繁的。并且不存在一个x的父频繁子集。会丢失频繁子集的support值
Apriori算法基本思想
如果一个集合是频繁的,那么在同一个最小sup值下,它的子集也是频繁的。算法的核心思想是:首先找到所有的1项代表集C1,根据sup过滤得到频繁集合F1,从F1中得到代表集C2,C2的自己如果有不在F1中的,就删掉【这个过程称为剪枝】,然后遍历数据集,当C2中的数据在原始数据集中是频繁的时候,得到频繁集F2,依次往复。
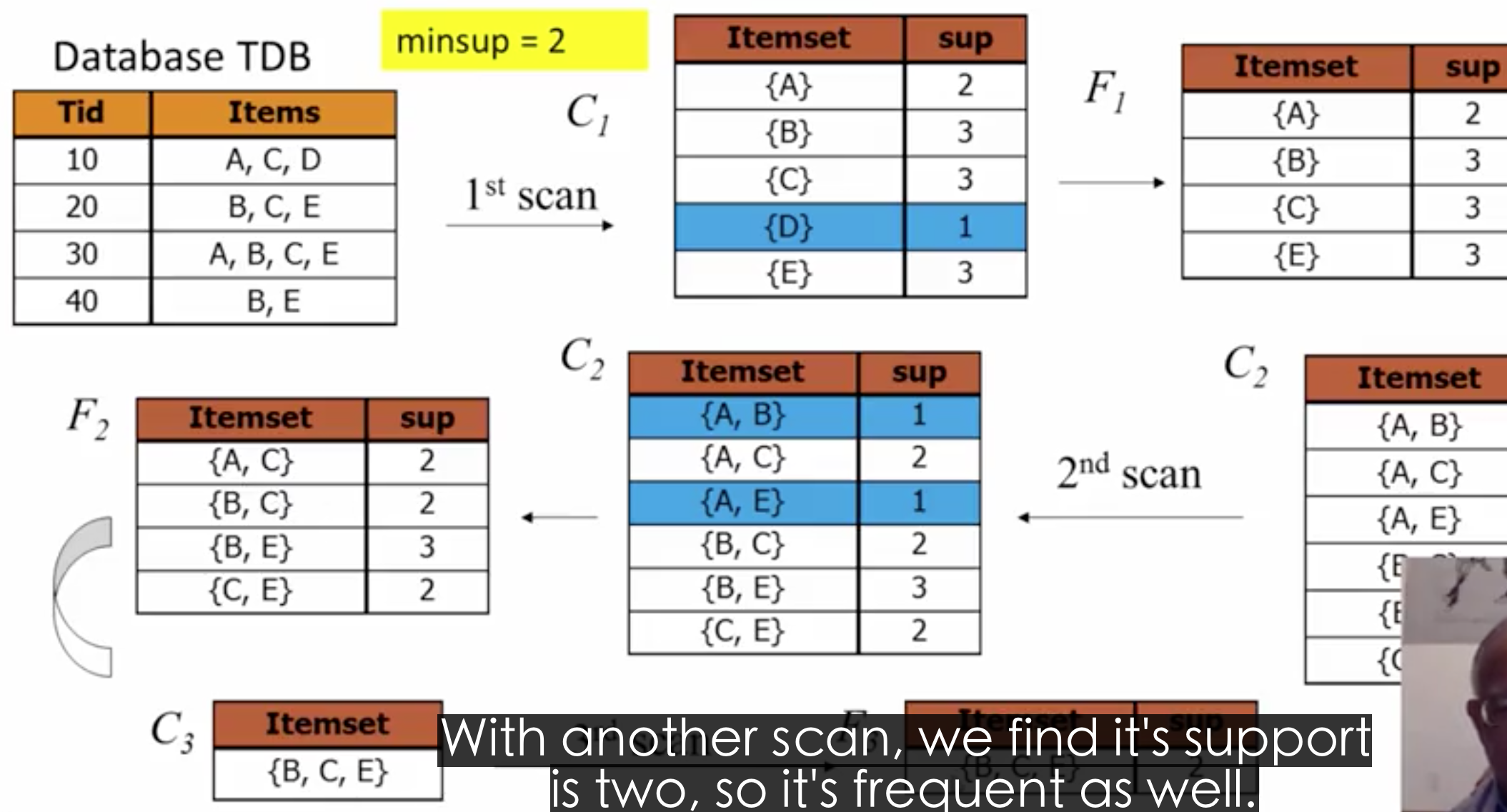
Aprior算法面临的问题
- 看起来没产生一个频繁集需要访问一遍数据库,改进的策略是:分区。
- 从k项的频繁集,到k+!项的代表集会包含很多元素,所以最好能减少代表集的数量,有效策略是 hash(等)。
分区策略
对于一个很大的数据库来说,分区之后,如果某一项是频繁的,意味着至少存在一个分区,它也是频繁的,所以,第一次扫描数据库,先把当前分区的数据全部收入内存,然后计算出当前分区的所有频繁集,然后把所有的频繁集统一收作全局代表。再过滤出全局频繁的,整个过程只有两次扫描数据库【有点小把戏,把数据缩小到内存中能放下,在内存中算】
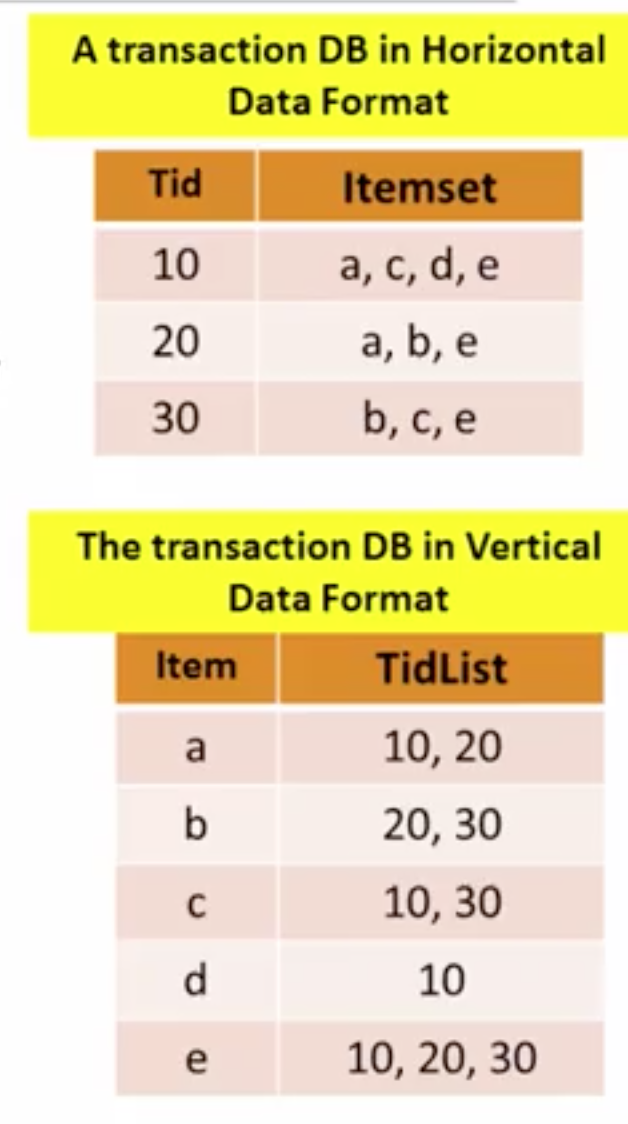
- ECLAT(Equivalence Class Transformation):一般的数据库是根据项ID和项值来存储的,这里的主要思想是把唯一的项值提出来,对应列放在数据库中的项ID列表。
此时,当前项的频率就是ID列表的大小,如果要看两个项的频率就是求IDlist的交集。
这种存储具备如下的特征:如果idlist一模一样,代表这两项肯定是一起出现;如果x的ID列表是Y的ID列表的子集,那么拥有X项的记录必定拥有Y
hash较少代表集数量
对所有k集频繁项做hash计算,hash表中存储计算结果为同一个hash值的个数【可以在具体的分区做】,如果这个数值小于support值,那么当前hash桶中的所有项都不是频繁的,就不会当做代表集频繁模式挖掘-DHP算法详解 | I am Busy
大致思路是:同一个hash值的肯定会进同一个地方,如果一项出现多个,那么他们必定是进同一个hash桶,也就是说这个的hash桶的个数会很多,如果个数少,说明这个hash桶中的数据都不是频繁的
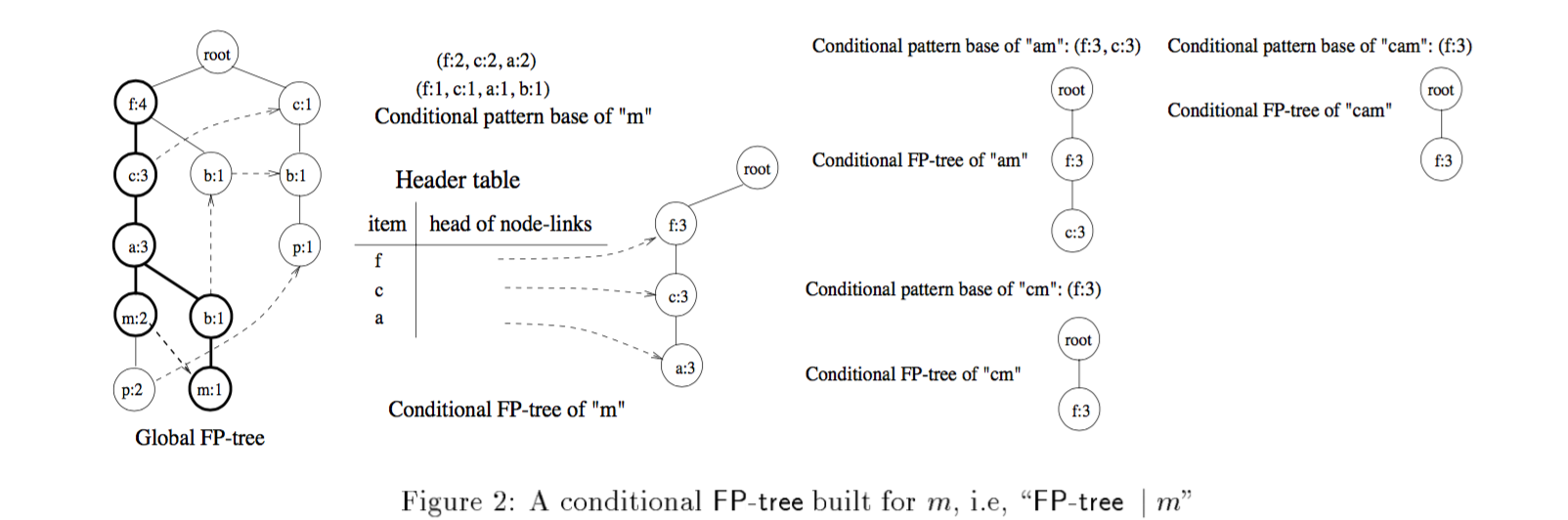
FPGrowth算法
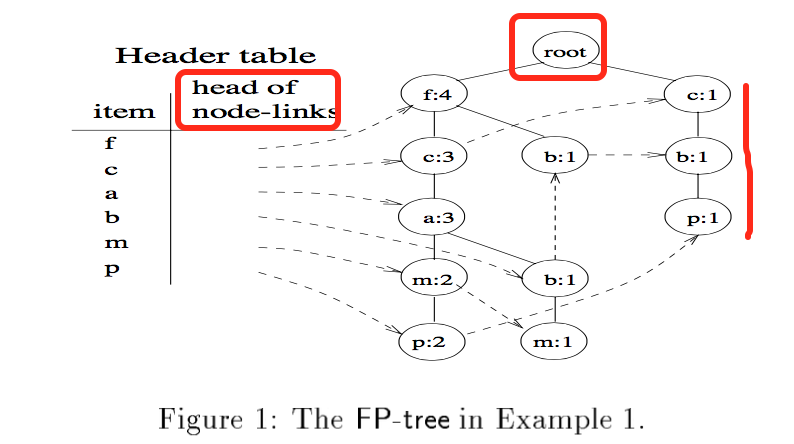
FP-tree(frequent pattern tree)定义:
- 它包含了一个root,被标记成null,root有每一项作为前缀的子项,同时有一张表记录了频繁项的头;
- 项前缀的子树包含3个部分:该项的名字,数量和节点链接。
- 每个频繁项的头表有两个字段,项的名字以及节点链接的头
经过FP定义构建好FP-tree之后,这时它的跟节点是root,可以称作全局树,然后根据header table给定的顺序,从末尾的项,选择一个元素P,以它为条件,构建FP-tree,称作P条件先的FP-tree,构建策略是从P开始往上寻找父节点,count值则是以P为基础,构建结果后,一直到最终只剩下一个元素,挖掘结束