

前言
大多数开发者并不对进程有过多细致了解,至少在很多层面上,普通开发者没必要理会这些细节,操作系统存在的意义就是消除开发者在这方面遭遇的恐慌,使得能够快速编写出可以执行的代码。那么理解进程的意义正是希望在操作系统层面有新的认识,在处理多进程和并发时能从根本上判断问题。
本文将从最简单的操作系统模型去分析进程的存在,在操作系统中,任何代码的执行都必须依附于某个进程,可以说,进程就是代码在操作系统执行的基本单元。因此,下面将操作系统各个核心模块做个描绘,然后了解进程在整个系统中存在的形式。
代码的最终形式
无论是何种语言,高级的如php、java、python还是低级的c最终都会转化成统一规范的二进制流,在操作系统的控制下二进制流流通于各个硬件,经由CPU实现计算处理。
这里,我们以c语言为例,讲述代码转化的过程。当你创建如下代码的c文件code.c:
int sum=0;
int sum(int x,inty){
int t=x+y;
sum+=t;
return t;
}操作系统接下来通过编译器转化成如下形式的汇编代码code.s:
pushl %ebp
movl %esp,%ebp
movl 12(%ebp),%eax
addl 8(%ebp),%eax
addl %eax,sum
popl %ebp
ret汇编代码无限接近代码文件在操作系统最终存在的形式,如果不理解上面每一行的意义并不要紧,我们现在只需要知道每一行代表着一个指令,而指令是处理器(CPU)执行的基本单位。尽管汇编代码已经无限接近机器硬件了,但计算机硬件只能识别二进制,所以汇编代码还会经过一次转换,通过汇编器将汇编代码转化成二进制形式(下文左边):
55 pushl %ebp
89 e5 movl %esp,%eb
8b 45 0c movl 12(%ebp),%eax
03 45 08 addl 8(%ebp),%eax
01 05 00 00 00 00 addl %eax,sum
5d popl %ebp
c3 ret为了便于文本编写,上文左边二进制代码我们通过16进制来表示,每行的右边是对应的原汇编代码说明,通过上面的转化,我们编写的c代码最终变成了二进制流!
接下来CPU将加载上面每一行二进制流,按顺序执行每个指令,完成整个过程。
CPU如何运算代码
计算机从上个世纪发展至今,性能实现了巨大的飞跃,但计算机的处理模型一直没有改变,就是我们熟知的"冯诺依曼结构计算机"。这个结构的计算机要求:计算机的数制采用二进制,计算机应该按照程序顺序执行。
时至至今,我们所用的计算机依然是冯诺依曼计算机(额...你或许听说过量子计算机,但你应该没体验过)。CPU保持了高速的运算能力,这里的运算能力体现在对指令的执行频次上,一个完整逻辑的代码最终都将转化成按顺序排放的指令序列,CPU时时刻刻地对待处理指令按序执行。
一个单核的CPU在每个时钟周期内完成一次运算,我们常说的主频就是指CPU内核工作的时钟频率,即每秒钟能产生多少次时钟中断。我们需要了解的是,时钟中断是计算机硬件运作的一种方式,每次时钟的中断相当于一次对硬件的触发(你或许可以想象为对函数的一次调用了)。一个主频为1GHz的CPU意味着每一秒钟CPU可实现1000000000次触发,如果每条指令都可以在一次触发中完成执行,那么CPU的运算能力我们可以简单理解为每秒可执行1000000000条指令。
那么,CPU在运算过程中和指令的关系是怎样的?
通过上文可知,代码编译后的最终形式是二进制流,并且会保存在存储器中供加载。在指令运行过程中,CPU需要知道每次执行的下一条指令地址,并且执行后的相关状态需要实时保存,在CPU执行频率如此快的情况下,要求必须有足够快的速度实现数据存储,而寄存器就是这么一个离CPU最近的存储硬件,它速度足够快,满足CPU的高速存储需求,接下来我们结合上文示例的汇编代码来讲述寄存器和CPU之间的关系。
寄存器代表的是CPU可直接访问的高速存储器,在Y86处理器中,有8个寄存器(在汇编程序中以%符号开头来表示,如%eax,%ecx....代表不同寄存器),每个寄存器可存储四个字节
上一节在讲述代码编译的过程中,我们以一个sum函数做了示例,该函数实现了两个参数x、y的相加,其中我们看到如下一条指令:
movl 12(%ebp),%eax该指令在原c代码中相当于获取参数x的值,具体功能为:将寄存器%ebp保存的值加上12,然后将得到的值作为内存地址去内存中获取对应值,并保存到%eax寄存器中。可以理解为,%ebp保存着内存某个地址,而参数x的值被放置在该内存地址偏移12(这里的单位是字节)的地方,找到该值后放置到%eax寄存器中,存储状态如下图所示:
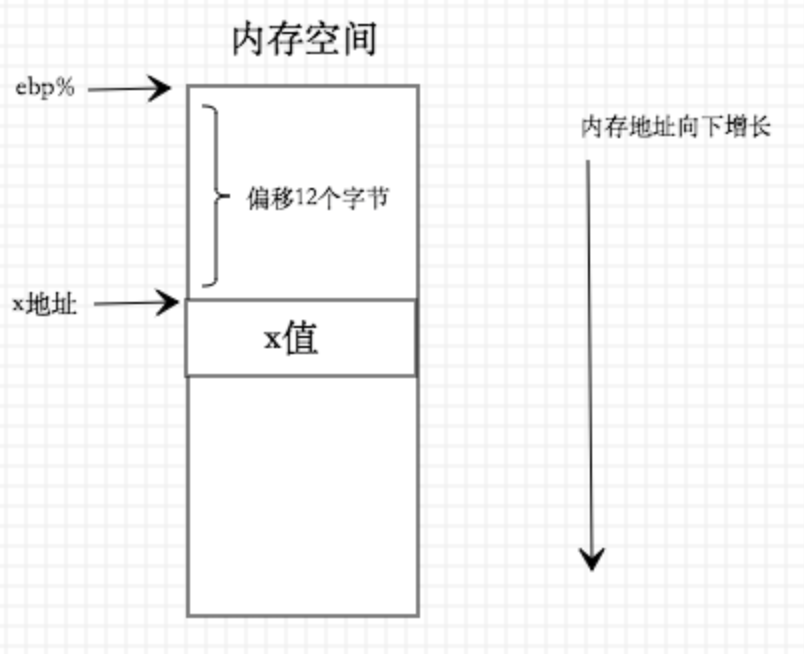
随后开始执行指令:
addl 8(%ebp),%eax其中addl指令会命令CPU执行加的运算操作,具体功能为:将%ebp保存的值加上8,然后得到的结果作为内存地址从内存空间取出对应值,将该值和%eax保存的数据进行相加操作,最后将结果保存到%eax寄存器中。可以理解为,参数y一开始放置在%ebp所保存内存地址偏移量为8的地方,addl命令首先从该地址获取y值,接下来从%eax获取x值,最后执行相加操作,由此实现了sum函数中对参数x和y的计算。存储状态如下图所示:
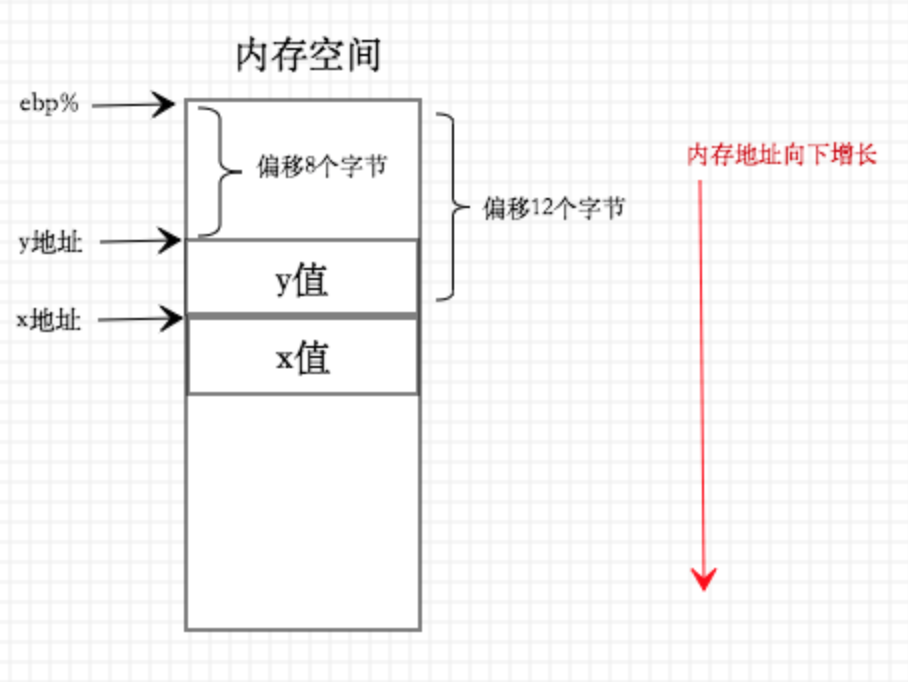
通过上面两条指令,我们大致了解了sum函数的核心计算过程,CPU在这个过程中扮演了主要角色,寄存器则配合CPU完成了一些存储状态的相关操作(放置参数变量的地址,保存相关结果值...)。
值得注意的是,这个过程还有一个专门寄存器用于存放待执行指令的地址,每执行一条指令时都会更新PC寄存器,用于指向下一条指令的地址,操作系统通过维护好PC寄存器保存的内容很好地控制了CPU的运算过程。
操作系统中的调度
从CPU的执行过程来看,在单核的条件下,CPU在每个时钟周期最多只能处理一条指令,如果CPU一直在不间断处理某个代码逻辑,那么其它的应用程序将无法得到执行的机会。因此,必须引入一种机制合理分配计算资源,让不同的代码逻辑能够及时得到处理,调度的概念在这里出现了,操作系统通过调度的机制,在每秒钟处理频次如此高的情况下,每一秒钟的单位时间CPU可以处理很多不同代码逻辑的指令,实现了“并发”的操作。
那么,调度的对象是什么,这个过程如何去理解呢?
上文中的示例代码,完成了两个数值的相加操作,假设现在还有另一个代码逻辑也在运行过程中,完成的是两个数值的相减操作,我们希望这两个过程互不相关互不干扰。
另一个代码逻辑如下:
int sub(int x,inty){
int t=x-y;
return t;
}编译后的形式为:
55 pushl %ebp
89 e5 movl %esp,%ebp
8b 45 0c movl 20(%ebp),%eax
61 45 08 subl 16(%ebp),%eax
01 05 00 00 00 00 addl %eax,sum
5d popl %ebp
c3 ret从汇编代码可以知道,该函数的x、y参数在执行过程中放置在%ebp寄存器所保存地址对应偏移字节的位置处,最终的执行结果也保存在%eax寄存器,只不过%ebp在两个执行过程中会存放不同的值用于区分不同代码空间的内存地址。寄存器是被所有执行过程共享的,按照我们的设想,如果CPU在运算过程中直接来回调用两个逻辑的指令,那么期间寄存器保存的值将会受到另一个程序的干扰,那么将无法得到正确的结果!
我们来模拟CPU运算过程可能遭遇的一种状态,当PC寄存器定位到sum函数如下指令时:
movl 12(%ebp),%eax完成了x值在%eax寄存器的保存操作,此时操作系统通过调度将PC指定到sub函数的如下指令:
movl 20(%ebp),%eax如果在此过程不对%ebp进行更新操作,那么sub函数的x值将会按照sum函数执行的存储状态来继续处理,这显然是不对的,会造成取值的错误。
同样的情况,当CPU执行完sum函数的下一条指令时:
addl 8(%ebp),%eax此时,%eax保存着x、y相加的结果,接下来操作系统通过调度将PC指定到sub函数的如下指令:
movl 20(%ebp),%eax可以预见的是,%eax值被覆盖了,那么当CPU重新调度到sum函数的后续指令时,将发生各种可能的错误。
所以,在调度过程中,必须设计一套模型,使得各个代码逻辑在执行过程中,关于存储空间的利用不会互相干扰,并且CPU能完整地执行完各个逻辑。
上下文的概念和进程的存在
在前面示例的案例中,如果要让两个函数同时运行,通过CPU高频的调度可以“无感知”地分配计算资源进行处理,但在两个不同代码逻辑中来回计算,需要考虑一些存储空间的冲突问题,避免数据受到彼此干扰,这里需要提及一个重要概念:上下文环境
个人刚开始接触编程时,偶尔会在书本或相关文档中见到“上下文”的字眼,当时并没有太在意这个概念,也没真正理解过。何谓上下文?百科是这样概括的:
上下文,即语境、语意,是语言学科(语言学、社会语言学、篇章分析、语用学、符号学等)的概念。
但在刚刚分析的问题中,我个人可以用蹩脚的话语来说明上下文环境:某个执行中代码逻辑的前后关系和存储状态,前后关系说明了在这个环境下需保证逻辑的正确性,存储状态说明了相关数据内容在前后执行过程中需保持一致的状态,不可异常变动。
假设CPU在执行sum函数过程中,还未执行指令movl 12(%ebp),%eax的情况下直接执行addl 8(%ebp),%eax,那么这个前后关系就被破坏了。如果在执行sum函数的指令addl 8(%ebp),%eax后开始调度sub函数的movl 20(%ebp),%eax指令,那么%eax数值被干扰,当CPU重新调度执行sum函数后续指令时,存储状态的一致性被破坏了。
因此,维护好上下文环境就是将每个独立的代码逻辑当做一个完整而封闭的执行单元来区别处理,进程的概念就是在这样的需求下被设计了出来,可以说,进程作为不同程序执行的基本单元,维护了相应的上下文环境,在CPU高速调度过程中保证了不同程序的正确运行!
关于进程的概念,linux操作系统中是这样理解的:
程序是一个可执行文件,而进程是一个执行中的程序实例。利用分时技术,在Linux操作系统上可以同时运行多个进程。分时技术的基本原理是把CPU的运行时间划分成一个个规定长度的时间片,让每个进程在一个时间内运行。当进程的时间片用完时系统就利用调度程序切换到另一个进程去运行。因此实际上对于具有单个CPU的机器来说某一时刻只能运行一个进程。但由于每个进程运行的时间片很短,所以表面看起来好像所有进程都在同时运行着。
当前包括Linux等操作系统经过数十年发展,进程在操作系统内部的表示已经变得非常复杂,包括线程、协程等概念也被创造出来,但所有的程序最终都依附于进程。本文意在对进程完成初步印象,因此我们将用最简单的方式来结合前面案例构建一个进程结构。
在上面的调度案例中,我们遭遇了上下文环境不一致的问题,一个是代码逻辑方面、一个是存储状态方面,我们分别从这两个方面进行分析。
代码逻辑
CPU在调度过程中,从sum函数切换到sub函数执行时,首先需要知道接下来该执行sub函数哪个位置的指令,从而切换到sub函数执行前可以更新PC寄存器的值,让CPU沿着上一次执行的位置按序处理后续指令。这里,需要有一个存储空间用于保存各个代码逻辑待需执行的指令位置,每当CPU调度到该程序时,从该空间提取出指令位置信息,恢复到PC寄存器,整个过程可以实现完整的处理。
存储状态
当执行完sum函数的 movl 12(%ebp),%eax 指令后,%eax保存着sum函数的x变量值,用于后续指令的调用,但当CPU接下来调度到sub函数的 movl 20(%ebp),%eax 指令执行后,%eax的值将受到干扰,因此每次调度都必须对当前上下文环境的寄存器值进行保存,即在准备调度到sub函数前将%eax的值保存到sum函数专有的内存空间,在后续重新执行sum函数时,再从该内存空间恢复%eax值,这样保证了sum函数后续的指令 addl 8(%ebp),%eax 正常处理!这些过程由操作系统的进程机制自动处理,对程序员而言都是透明的。
所以,每个进程必须要求有一个独立的内存空间,这个内存空间的第一作用就是维护当前代码逻辑的上下文环境信息!
linux操作系统是怎么实现进程管理的?我们来窥探下linux本人在30年前开发linux内核初版时的思路:linux内核在内存空间为每个进程开辟一个独立而固定的内存空间来存放进程结构,进程结构保存了不同进程当前的上下文环境信息。结合前文的分析,我们了解到至少在该空间保存了进程待执行指令的地址(用于恢复PC寄存器),当调度发生准备切换到另一进程时,操作系统会将各个寄存器值保存到进程空间对应位置中,当调度重新切换到该进程时再从进程空间恢复到各个寄存器,进程切换就是在这么一个过程中反反复复。
如果你理解了这个基本过程,那么应该明白进程的调度其实是有成本的,操作系统每次对进程的调度,都需要对很多存储状态进行处理,目前操作系统很多进程状态都存储在内存中,这就要求每次调度都会对内存进行了一定的IO操作,这对于每秒钟亿万次运算的CPU来说不得不等待IO的过程,可能会造成一定的延迟。
相关问题
有个技术编写一个从远端服务器拉取数据的脚本,在四核CPU的服务器上操作。当时一下子开启了几十个进程同时往远端拉取,发现进程开的越多,整个服务器从远端拉取数据的速度反而越慢,最终还没有开4个进程的块,这是为什么呢?
为什么说线程比较轻量?这个轻量的轻如何从底层去理解?
golang语言作为21世纪的C语言,以高性能、高并发著称,其中golang有一个叫“协程”的概念,通过协程一个应用程序可以在消耗极少内存和其它计算资源的条件下实现大量并发处理,这种技术到底是怎么实现的?
后语
在本人的理解中,进程存在的意义就是为了管理不同的程序,维护着不同程序的上下文环境,这些都是在调度的场景中被设计出来的。无论操作系统如何庞大复杂,进程调度的核心概念都离不开此。本文在很多关键细节上并没有做非常细致而严谨的说明,突出的是进程在调度中扮演的角色,这个角色如果深究还有非常多的特性和细节,可以自行查找相关资料了解。
参考:《深入理解计算机系统》、《linux内核完全注释》、《linux内核架构》
