

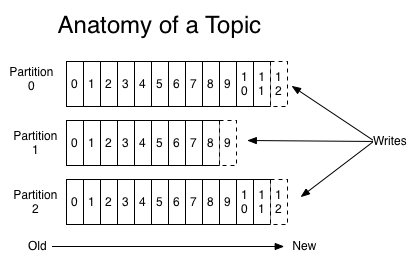
Kafka 与很多其它 MQ 不太一样,Kafka 中的 Topic 具有分区(Partition)的概念,一个 Topic 可以指定一个或多个分区,每个分区内的数据都是有序的,发布的消息最终落到哪个分区是有规则的,默认情况下随机(但其实也不完全随机,内部会有一些机制),实际情况下我们可能会对消息指定一个 Key, 相同 Key 的消息会落到一个分区上,不同的 Key 的消息也可能会落到相同的分区,分区与 Key 的关系的1对多,但 Key 与 分区的关系必须是1对1。
消费者组 (Consumer Group)
消费者并不是独立存在的,每一个消费者实例必定属于一个消费组。
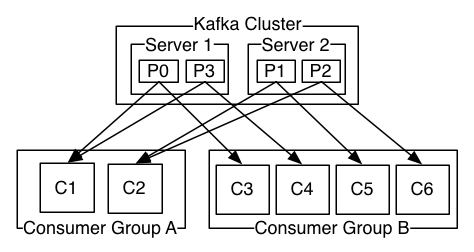
消费组主要说明:
-
Consumer Group 需要设定一个 group.id,Consumer Group 的唯一标识;
-
Consumer Group 下可以有一个或多个 Consumer 实例,Consumer 实例可以是一个进程,也可以是一个线程;
-
Consumer Group 可以订阅多个 Topic,但一个 Topic 下的一个分区只能分配给某个 Consumer 实例消费,不同的 Consumer Group 可以消费 Topic 下同一个分区的数据;
-
Consumer Group 最多的 Consumer 实例个数不应超过订阅的 Topic 的分区数,因为一个分区只能给一个 Consumer 实例消费,多出来的 Consumer 实例完全是浪费;
在实际消费数据时,可以根据消费情况动态对 Topic 的分区数进行调整,从而达到更高的效率。
消费组的偏移重置设定(auto.offset.reset)

largest(默认) ,也可以使用 latest、end
当各分区下有已提交的 offset 时,从提交的 offset 开始消费;无提交的 offset 时,消费新产生的该分区下的数据
注意 : 已提交的 offset 不是指 producer 发送的消息对应的 offset ,而是指消费者消费的消息对应的 offset 。
这到底是什么意思?这里对两种情况进行解释一下:
-
在没有启动 Consumer 实例的情况下,Producer 向某个 Topic 发布了消息。之后当 Consumer 实例启动时是不会消费之前发布的数据的,只有新发布的数据会被消费;
-
在 Consumer 实例启动的情况下,当 Producer 向某个 Topic(n 个分区) 发布消息时,当 Consumer 实例挂掉时并没有对所有分区有过消费记录,在挂掉期间,如果 Producer 发布的消息恰好落到没有消费记录的分区,Consumer 实例重新启动后,这部分消息(落到没有消费记录分区)将不会消费,只有新发布的数据会被消费;
smallest,也可以使用 earliest、beginning
当各分区下有已提交的 offset 时,从提交的 offset 开始消费;无提交的offset时,从头开始消费
error
Topic 各分区都存在已提交的 offset 时,从 offset 后开始消费;只要有一个分区不存在已提交的 offset ,则抛出异常
如果没有使用过 largest 或者 smallest 方式使 Topic 各分区下有已提交的 offset,设置成 error 必然是一直异常。
