

前言
这是6月前端面试最后一篇文章了,因为我的技术栈是react,下面都是面试官面对面问的一些问题的记录~
react
react的生命周期
MOUNTING:
- mountComponent 负责管理生命周期中的 getInitialState、componentWillMount、render 和 componentDidMount。
由于 getDefaultProps 是通过构造函数进行管理的,所以也是整个生命周期中最先开始执行的。 而 mountComponent 只能望洋兴叹, 无法调用到 getDefaultProps。 这就解释了为何 getDefault-Props只执行一次。
RECEIVE_PROPS:
- updateComponent 负责管理生命周期中的 componentWillReceiveProps、shouldComponent- Update、componentWillUpdate、render 和 componentDidUpdate。
UNMOUNTING:
- unmountComponent 负责管理生命周期中的 componentWillUnmount
组件的生命周期在不同状态下的执行顺序。
- 当首次挂载组件时, 按顺序执行 getDefaultProps、 getInitialState、 componentWillMount、render 和 componentDidMount。
- 当卸载组件时,执行 componentWillUnmount。
- 重新挂载组件时,此时按顺序执行 getInitialState、componentWillMount、render 和componentDidMount,但并不执行 getDefaultProps
- 再次渲染组件时,组件接受到更新状态,此时按顺序执行 componentWillReceiveProps、shouldComponentUpdate、componentWillUpdate、render 和 componentDidUpdate
react的生命周期与setState的关系
- setState React 初学者常会写出 this.state.value = 1 这样的代码,这是完全错误的写法。
绝对不要直接修改 this.state,这不仅是一种低效的做法,而且很有可能会被之后的操作替换
setState 通过一个队列机制实现 state 更新。当执行 setState 时,会将需要更新的 state 合并后放入状态队列,而不会立刻更新 this.state,队列机制可以高效地批量更新 state。如果不通过 setState 而直接修改 this.state 的值,那么该 state 将不会被放入状态队列中,当下次调用 setState 并对状态队列进行合并时,将会忽略之前直接被修改的 state,而造成无法预知的错误。
因此,应该使用 setState 方法来更新 state,同时 React 也正是利用状态队列机制实现了 setState 的异步更新,避免频繁地重复更新 state。
相关源码如下:
// 将新的 state 合并到状态更新队列中
var nextState = this._processPendingState(nextProps, nextContext);
// 根据更新队列和 shouldComponentUpdate 的状态来判断是否需要更新组件
var shouldUpdate = this._pendingForceUpdate ||
!inst.shouldComponentUpdate ||
inst.shouldComponentUpdate(nextProps, nextState, nextContext)
- setState 在生命周期中的调用
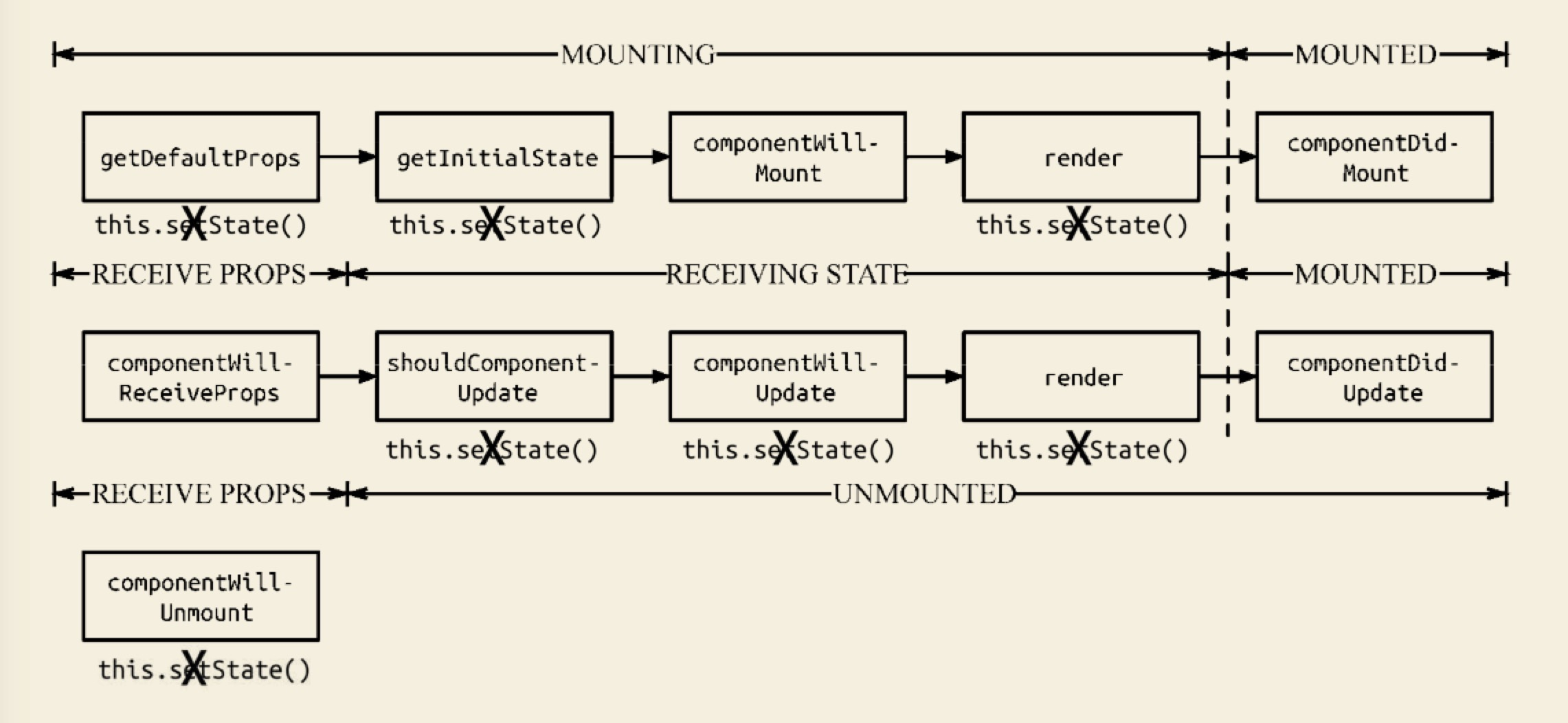
-
如果我们在 componentWillMount 中执行 setState 方法,会发生什么呢? 组件会更新 state,但组件只渲染一次。因此,这是无意义的执行,初始化时的 state 都可以放在 this.state。
-
如果我们在 componentDidMount 中执行 setState 方法,又会发生什么呢? 组件当然会再次更新,不过在初始化过程就渲染了两次组件,这并不是一件好事。但实际情况是,有一些场景不得不需要 setState,比如计算组件的位置或宽高时,就不得不让组件先渲染,更新必要的信息后,再次渲染。
-
如果我们在 componentWillUnmount 中执行 setState 方法,又会发生什么呢? 不会触发 re-render 的,这是因为所有更新队列和更新状态都被重置为null,并清除了公共类,完成了组件卸载操作
-
setState 循环调用风险
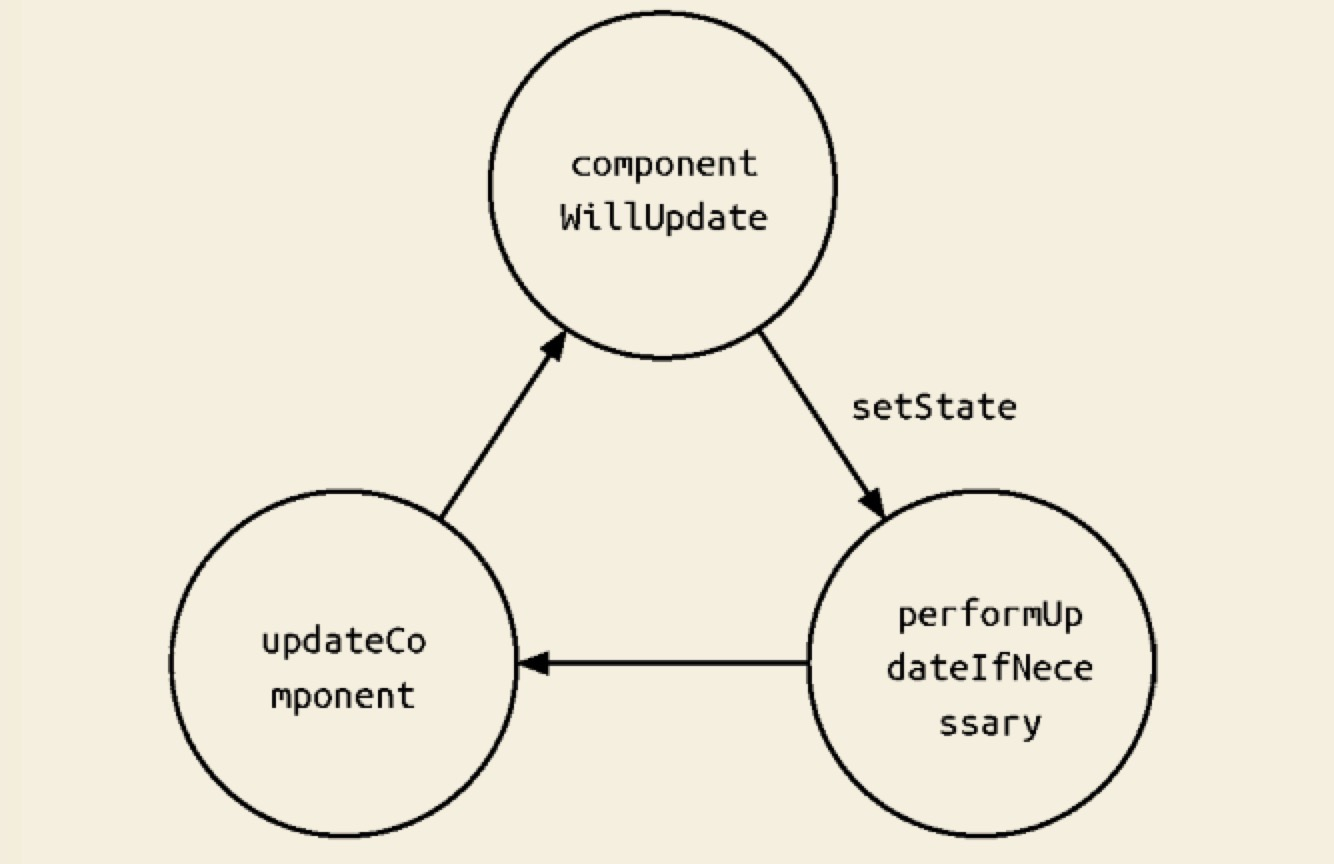
当调用 setState 时, 实际上会执行 enqueueSetState 方法, 并对 partialState 以及_pending- StateQueue 更新队列进行合并操作,最终通过 enqueueUpdate 执行 state 更新。
而 performUpdateIfNecessary 方法会获取 _pendingElement、_pendingStateQueue、_pending- ForceUpdate,并调用 receiveComponent 和 updateComponent 方法进行组件更新。
如果在 shouldComponentUpdate 或 componentWillUpdate 方法中调用 setState,此时 this._pendingStateQueue != null,则 performUpdateIfNecessary 方法就会调用 updateComponent 方法进行组件更新,但 updateComponent 方法又会调用 shouldComponentUpdate 和 componentWill- Update 方法,因此造成循环调用,使得浏览器内存占满后崩溃.如下图
pureComponent和component有什么区别
在一个父组件里有多个子组件的时候,修改一个子组件会导致所有子组件全部重新渲染。 我们一般都会使用shouldComponentUpdate的生命周期去判断,但是这个生命周期是及其消耗性能的,在react里并不推荐使用这个方法。
这个时候我们可以简单的去模拟一个shouldComponentUpdate的方法。pureComponent就是在component的最外层帮我们默认实现了一个浅比较。
React.PureComponent 与 React.Component几乎完全相同,但React.PureComponent通过prop和state的浅对比来实现 shouldComponentUpate()。
如果React组件的 render()函数在给定相同的props和state下渲染为相同的结果,在某些场景下你可以使用 React.PureComponent 来提升性能。
如果对象包含复杂的数据结构,它可能会因深层的数据不一致而产生错误的否定判断(表现为对象深层的数据已改变视图却没有更新)。
考虑使用不可变对象来促进嵌套数据的快速比较。此外,React.PureComponent的shouldComponentUpate() 会忽略整个组件的子级。请确保所有的子级组件也是”Pure”的
如何在在生命周期中发送一个异步的请求
一般在componentDidMount()生命周期里去发送一个异步请求。因为这个时候可能需要的dom已经都挂载在了浏览器上,我们可以去拿到一些我们想要的参数,或者是把返回的数据保存在标签中。
参考一下官方对componentDidMount的解释
componentDidMount() is invoked immediately after a component is mounted. Initialization that requires DOM nodes should go here. If you need to load data from a remote endpoint, this is a good place to instantiate the network request.
react的高阶组件是什么?如何实现一个高阶组件?
React 组件的构建过程中,常常有这样的场景,有一类功能需要被不同的组件公用,此时就涉及抽象的话题。在不同的设计理念下,有许多的抽象方法,而针对 React,我们会用到高阶组件。
higher-order function(高阶函数)在函数式编程中是一个基本的概念,它描述的是这样一种函数:这种函数接受函数作为输入,或是输出一个函数。比如,常用的工具方法 map、reduce 和 sort 等都是高阶函数。 高阶组件(higher-order component) ,类似于高阶函数,它接受 React组件作为输入,输出一个新的 React 组件。 实现高阶组件的方法有如下两种:
- 属性代理(props proxy)。高阶组件通过被包裹的 React 组件来操作 props。
- 反向继承(inheritance inversion)。高阶组件继承于被包裹的 React 组件。
从react推荐组件定义key的原因。
diff 作为 Virtual DOM 的加速器,其算法上的改进优化是 React 整个界面渲染的基础和性能保障, 同时也是 React 源码中最神秘、 最不可思议的部分。 本节依然从源码入手, 深入剖析 diff 的不可思议之处。
下面介绍 React diff 算法的 3 个策略
- 策略一:Web UI 中 DOM 节点跨层级的移动操作特别少,可以忽略不计
- 策略二:拥有相同类的两个组件将会生成相似的树形结构,拥有不同类的两个组件将会生成不同的树形结构。
- 策略三:对于同一层级的一组子节点,它们可以通过唯一 id 进行区分。
其中策略三就是:element diff,当节点处于同一层级时,diff 提供了 3 种节点操作,分别为 INSERT_MARKUP(插入) 、MOVE_ EXISTING(移动)和 REMOVE_NODE(删除) 。
列如:旧集合中包含节点A、B、C 和 D,更新后的新集合中包含节点 B、A、D 和 C,此时新旧集合进行 diff 差异化对比,发现 B != A,则创建并插入 B 至新集合,删除旧集合 A;以此类推,创建并插入 A、D 和 C,删除 B、C 和 D。
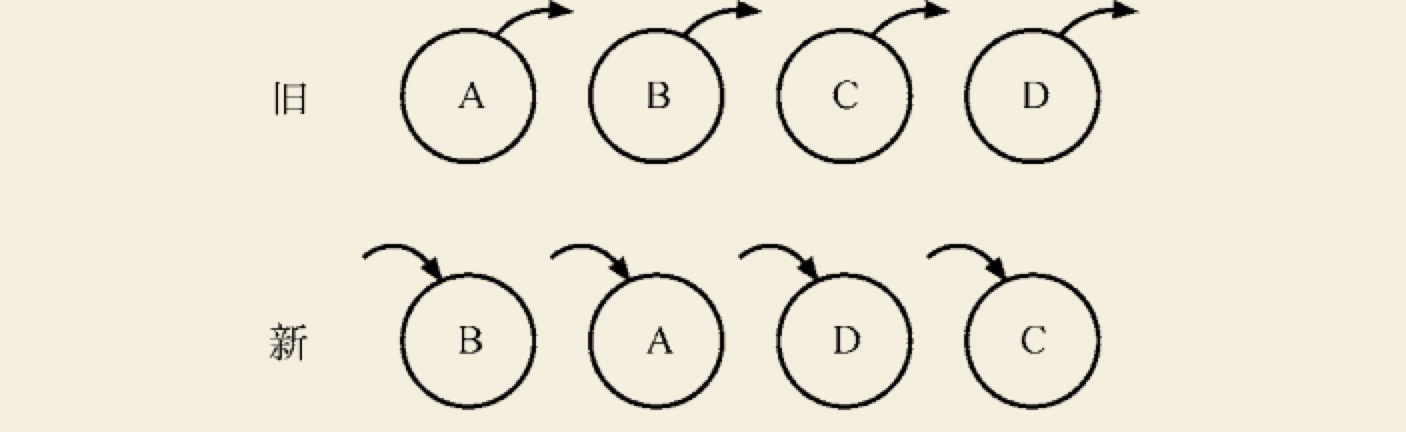
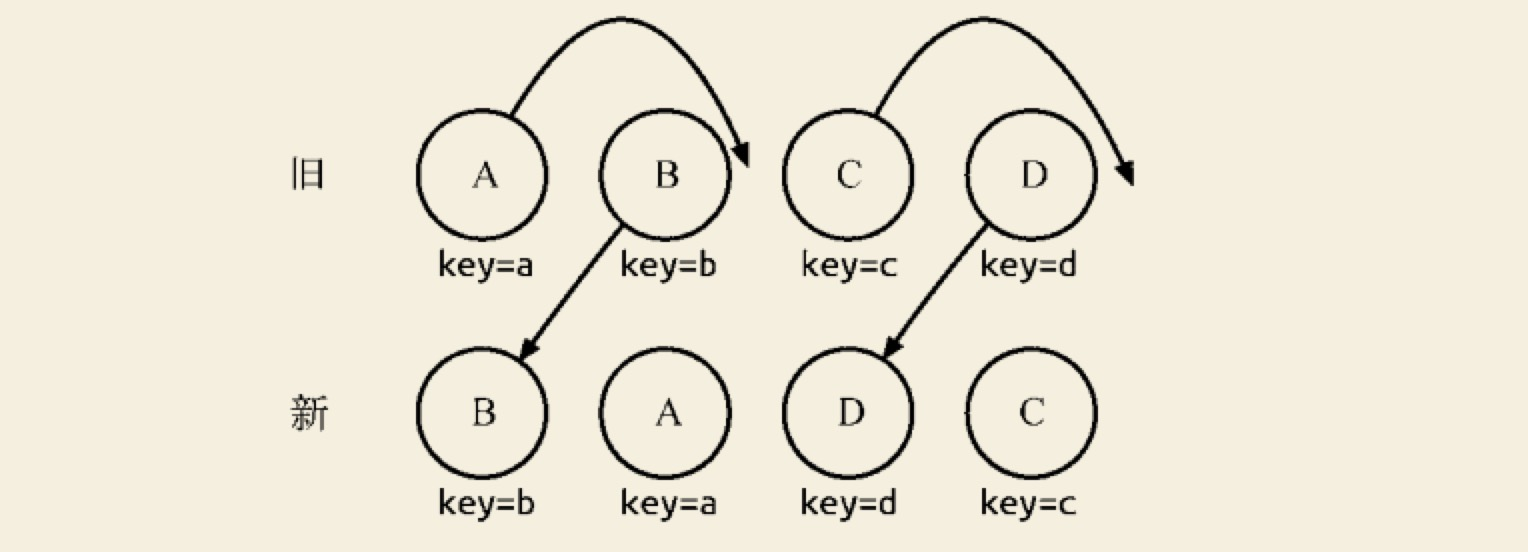
针对一些都是相同的节点,但由于位置发生变化,导致需要进行繁杂低效的删除、创建操作,其实只要对这些节点进行位置移动即可。React 提出优化策略: 允许开发者对同一层级的同组子节点, 添加唯一 key 进行区分,虽然只是小小的改动,性能上却发生了翻天覆地的变化!
新旧集合所包含的节点如图所示,进行diff差异化对比后,通过key发现新旧集合中的节点都是相同的节点, 因此无需进行节点删除和创建, 只需要将旧集合中节点的位置进行移动,更新为新集合中节点的位置,此时 React 给出的 diff 结果为:B、D 不做任何操作,A、C 进行移动操作即可。
redux
redux里combineReducers
combineReducers 辅助函数的作用是,把一个由多个不同 reducer 函数作为 value 的 object,合并成一个最终的 reducer 函数,然后就可以对这个 reducer 调用 createStore。
合并后的 reducer 可以调用各个子 reducer,并把它们的结果合并成一个 state 对象。state 对象的结构由传入的多个 reducer 的 key 决定。
最终,state 对象的结构会是这样的:
{
reducer1: ...
reducer2: ...
}
通过为传入对象的 reducer 命名不同来控制 state key 的命名。例如,你可以调用 combineReducers({ todos: myTodosReducer, counter: myCounterReducer }) 将 state 结构变为 { todos, counter }。
通常的做法是命名 reducer,然后 state 再去分割那些信息,因此你可以使用 ES6 的简写方法:combineReducers({ counter, todos })。这与 combineReducers({ counter: counter, todos: todos }) 一样。
Flux 用户使用须知 本函数可以帮助你组织多个 reducer,使它们分别管理自身相关联的 state。类似于 Flux 中的多个 store 分别管理不同的 state。在 Redux 中,只有一个 store,但是 combineReducers 让你拥有多个 reducer,同时保持各自负责逻辑块的独立性。
-
参数 reducers (Object): 一个对象,它的值(value) 对应不同的 reducer 函数,这些 reducer 函数后面会被合并成一个。下面会介绍传入 reducer 函数需要满足的规则。
-
返回值 (Function):一个调用 reducers 对象里所有 reducer 的 reducer,并且构造一个与 reducers 对象结构相同的 state 对象。
注意 本函数设计的时候有点偏主观,就是为了避免新手犯一些常见错误。也因些我们故意设定一些规则,但如果你自己手动编写根 redcuer 时并不需要遵守这些规则。
每个传入 combineReducers 的 reducer 都需满足以下规则:
所有未匹配到的 action,必须把它接收到的第一个参数也就是那个 state 原封不动返回。
永远不能返回 undefined。当过早 return 时非常容易犯这个错误,为了避免错误扩散,遇到这种情况时 combineReducers 会抛异常。
如果传入的 state 就是 undefined,一定要返回对应 reducer 的初始 state。根据上一条规则,初始 state 禁止使用 undefined。使用 ES6 的默认参数值语法来设置初始 state 很容易,但你也可以手动检查第一个参数是否为 undefined。
虽然 combineReducers 自动帮你检查 reducer 是否符合以上规则,但你也应该牢记,并尽量遵守。
//模拟一个combineReducers
var combineReducers1 = function(obj){
//内部具体代码
var finalState = {};
function reducer(state,action){
//reducer具体逻辑
for (var p in obj) {
//根据key属性值调用function(state.属性名,action)
finalState[p] = obj[p](state[p], action);
}
//返回state
return finalState;
}
//返回最终的reducer
return reducer;
}
redux的middleware的理解
面对多样的业务场景,单纯地修改 dispatch 或 reducer 的代码显然不具有普适性,我们需要的是可以组合的、自由插拔的插件机制,这一点 Redux 借鉴了 Koa (它是用于构建 Web 应用的 Node.js 框架)里 middleware 的思想。
Redux 中 reducer 更关心的是数据的转化逻辑,所以 middleware 就是为了增强 dispatch 而出现的。

这里是middleware实现的源码
export default function applyMiddleware(...middlewares) {
return (next) => (reducer, initialState) => {
let store = next(reducer, initialState);
let dispatch = store.dispatch;
let chain = [];
var middlewareAPI = {
getState: store.getState,
dispatch: (action) => dispatch(action),
};
chain = middlewares.map(middleware => middleware(middlewareAPI));
dispatch = compose(...chain)(store.dispatch);
return {
...store,
dispatch,
};
}
}
源码我就不解析了,这个源码我少说看了5遍,一直理解都不到位,精髓难懂啊

彩蛋
webpack和gulp的区别
webpack的打包原理是:1.一切皆是模块。给定一个主体文件(列如index.js),然后从这个主js中开始去招所有依赖的js,css,img等通过loader把他们都解析成模块输出。
与gulp有什么区别。
因为用过gulp,他的配置是任务,列task,比如js压缩,解析。类似于对less或sass的编译,组合,对图片的压缩,gulp就是提供一个流程化的一个工具。还可以在webpack前先执行gulp做一些流程化的配置,然后用gulp把webpack跑起来~
介绍几款webpack的插件
- copy-webpack-plugin:将单个或整个目录复制到构建目录里
- Extract-text-webpack-plugin:打包的时候分离出文本,打包到单独的文件里
在工作中遇到那些问题?如何解决的。
这个问题基本上是百分之百必问,我觉得,可以在自己的项目里找一个即记忆犹新又能突出难点并且自己掌握的问题去说明~ 太简单又突出不了各位的实力,太难了还没掌握的面试官一深挖就暴露了,哈哈哈哈
非常感谢 《深入React技术栈》作者:陈屹 这本书,让我在react的道路真的学到了很多~推荐~
友情链接:
