

前言
虽然前端面试中很少会考到算法类的题目,但是你去比如像腾讯一样的大厂面试的时候就知道了,对基本算法的掌握对于从事计算机科学技术的我们来说,还是必不可少的,每天花上 10 分钟,轻松了解基本算法概念以及前端的实现方式。
另外,掌握了一些基本的算法实现,对于我们日常开发来说,也是如虎添翼,能让我们的 js 业务逻辑更趋高效和流畅。
特别说明
我给每篇文章的定位是 10 分钟内应该要掌握下来,由于知识结构需要构建全面些,我就擅作主张地将堆排序算法讲解分割为上、下两篇文章了,希望能让大家阅读起来更清爽愉快。
各位看官都应该手痒痒想写算法了,今天我们就一起来看如何用 js 来实现堆排序。
文章结构
《堆排序(上)》文章结构:
- 简单的二叉树
- 简单的满二叉树
- 简单的完全二叉树
- 简单的堆
- 简单的堆分类
《堆排序(下)》文章结构:
- 算法介绍
- 轻松实现大顶堆调整
- 轻松实现创建大顶堆
- 轻松实现堆排序
- 复杂度分析
算法介绍
堆排序,就是利用堆(假设利用大顶堆)进行排序的方法。
它的基本思想是,将待排序的数组构造成一个大顶堆。此时整个数组的最大值就是堆顶的根节点。将它移走,其实就是将其与堆数组的末尾元素交换,此时末尾元素就是最大值。然后将剩余的 n-1 个元素又重新构造成堆,这样就又能得到次大值。
如此反复操作,直到只剩余一个元素,就能得到一个有序数组了。
根据以上的算法指导,可理出如下关键操作:
- 大顶堆调整(Max-Heapify),将堆的末端子节点做调整,使得子节点永远小于父节点;
- 创建大顶堆(Build-Max-Heap),将堆中所有数据调整位置,使其成为大顶堆;
- 堆排序(Heap-Sort),移除在堆顶的根节点,并做大顶堆调整的迭代运算。
轻松实现大顶堆调整
大顶堆调整(Max-Heapify)的作用是保持大顶堆的性质,是创建大顶堆的核心子程序,一次作用过程如下图所示:
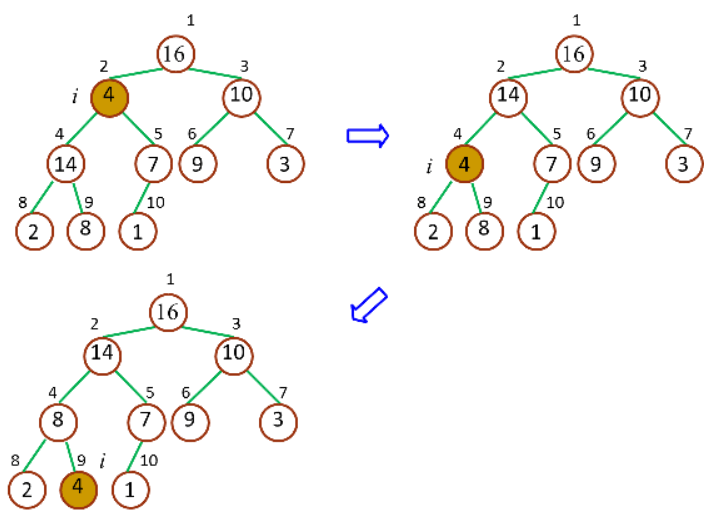
一次大顶堆调整示意图
由于一次调整后,仍有可能出现违反大顶堆的性质,所以需要递归地进行调整,直到整个堆都满足了条件。
/**
* 从 index 开始检查并保持大顶堆性质
* @arr 待排序数组
* @index 检查的起始下标
* @heapSize 堆大小
**/
var maxHeapify = function(arr, index, heapSize) {
// 计算某节点与其左右子节点在位置上的关系
// 上一节讲过
var iMax = index,
iLeft = 2 * index + 1,
iRight = 2 * (index + 1);
// 是否左子节点比当前节点的值更大
if (iLeft < heapSize && arr[index] < arr[iLeft]) {
iMax = iLeft;
}
// 是否右子节点比当前更大节点的值更大
if (iRight < heapSize && arr[iMax] < arr[iRight]) {
iMax = iRight;
}
// 如果三者中,当前节点值不是最大的
if (iMax != index) {
swap(arr, iMax, index);
maxHeapify(arr, iMax, heapSize); // 递归调整
}
};
var swap = function(arr, i, j) {
var temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
};
上面代码将有个隐患,那就是当数组长度很大时,其中的递归函数有可能会引起内存爆栈。那我们不妨来用迭代来实现:
var maxHeapify = function(arr, index, heapSize) {
var iMax, iLeft, iRight;
do {
iMax = index;
iLeft = 2 * index + 1;
iRight = 2 * (index + 1);
// 是否左子节点比当前节点的值更大
if (iLeft < heapSize && arr[index] < arr[iLeft]) {
iMax = iLeft;
}
// 是否右子节点比当前更大节点的值更大
if (iRight < heapSize && arr[iMax] < arr[iRight]) {
iMax = iRight;
}
// 如果三者中,当前节点值不是最大的
if (iMax != index) {
swap(arr, iMax, index);
index = iMax;
}
} while (iMax != index)
}
var swap = function(arr, i, j) {
var temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
轻松实现创建大顶堆
创建大顶堆(Build-Max-Heap)的作用是,将一个数组改造成一个大顶堆,接受数组和堆大小两个参数,其中会自下而上地调用 Max-Heapify 来改造数组。
因为大顶堆调整(Max-Heapify)能够保证下标为 i 的节点之后的节点都满足大顶堆的性质,所以我们要自下而上地调用大顶堆调整(Max-Heapify)。
若最大顶堆的元素总数量为 n,则创建大顶堆(Build-Max-Heap)从下标为 getParentPos(n) 处开始,往上依次调用大顶堆调整(Max-Heapify)。过程如下图所示:
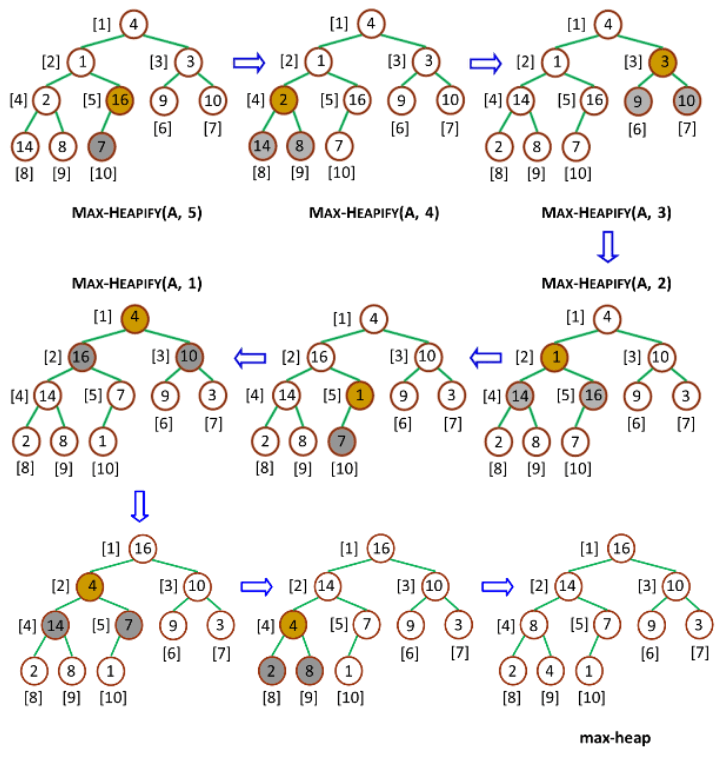
创建大顶堆过程示意图
算法实现如下:
var buildMaxHeap = function(arr, heapSize) {
var i, iParent = Math.floor((heapSize - 1) / 2);
for (i=iParent; i>=0; i--) {
maxHeapify(arr, i, heapSize);
}
}
轻松实现堆排序
堆排序(Heap-Sort)是堆排序的接口算法,其先要调用创建大顶堆(Build-Max-Heap)将数组改造为大顶堆;然后进入迭代,迭代中先将堆顶与堆底元素交换,并将堆长度缩短,继而重新调用大顶堆调整(Max-Heapify)保持大顶堆性质。
因为堆顶元素必然是堆中最大的元素,所以每一次操作之后,堆中存在的最大元素会被分离出堆,重复 n-1 次周,数组排序完成。过程如下图所示:
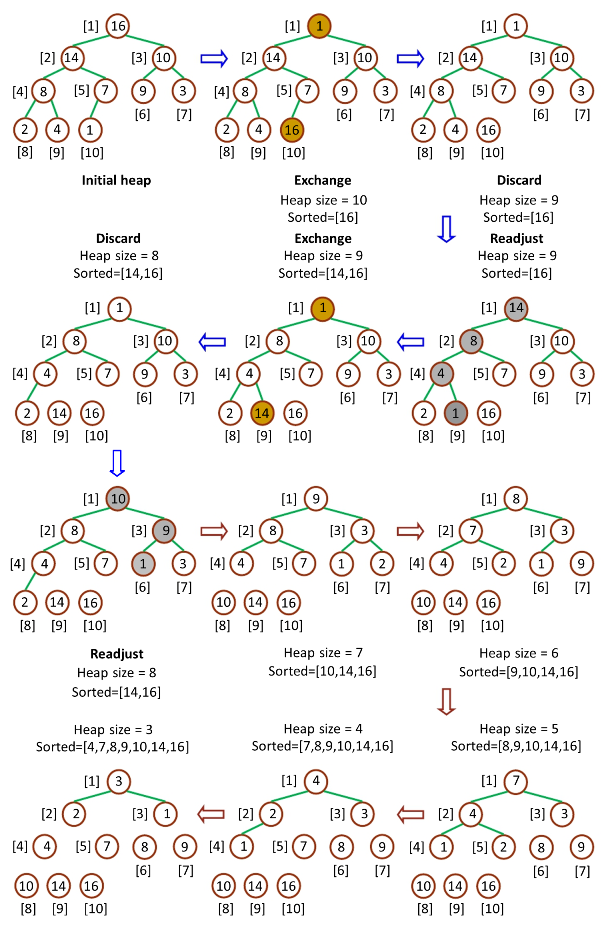
堆排序过程示意图
算法实现如下:
var heapSort = function(arr, heapSize){
var i;
buildMaxHeap(arr, heapSize);
for (i=heapSize-1; i>0; i--) {
swap(arr, 0, i);
maxHeapify(arr, 0, i);
}
};
完整实现
综合以上 3 块代码,完整的 js 代码如下:
/* 大顶堆排序 */
var heapSort = function(arr, heapSize){
var i;
buildMaxHeap(arr, heapSize);
for (i=heapSize-1; i>0; i--) {
swap(arr, 0, i);
maxHeapify(arr, 0, i);
}
};
/* 创建大顶堆 */
var buildMaxHeap = function(arr, heapSize) {
var i, iParent = Math.floor((heapSize - 1) / 2);
for (i=iParent; i>=0; i--) {
maxHeapify(arr, i, heapSize);
}
};
/* 大顶堆调整 */
var maxHeapify = function(arr, index, heapSize) {
var iMax, iLeft, iRight;
do {
iMax = index;
iLeft = 2 * index + 1;
iRight = 2 * (index + 1);
// 是否左子节点比当前节点的值更大
if (iLeft < heapSize && arr[index] < arr[iLeft]) {
iMax = iLeft;
}
// 是否右子节点比当前更大节点的值更大
if (iRight < heapSize && arr[iMax] < arr[iRight]) {
iMax = iRight;
}
// 如果三者中,当前节点值不是最大的
if (iMax != index) {
swap(arr, iMax, index);
index = iMax;
}
} while (iMax != index)
}
var swap = function(arr, i, j) {
var temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
复杂度分析
堆排序的运行时间主要是消耗在初始构建堆和重建堆时的反复筛选上。
我们这里不深入探讨算法的时间复杂度计算,总体来说,堆排序的时间复杂度为 O(n*logn)。由于堆排序对原始数组的排序状态并不敏感,因此它无论最好、最坏还是平均时间复杂都为 O(n*logn)。这在性能上显然要优于冒泡、简单选择、直接插入等复杂度为 O(n^2) 的算法了。
另外,由于初始化构建堆所需的比较次数较多,因此它并不适合元素个数较少的数组。
参考链接

觉得本文不错的话,分享一下给小伙伴吧~
