

算法导论(MIT 6.006 第15讲 第16讲 第17讲)
最短路径的定义是什么?
最短路径即拥有最小权重的路径p;
路径定义: p=<,
,...,
>, 其中当
时,有 (
,
)
E;
路径的权重:w(p)= ;
加上权重的数学表示方式
- 边存在权重的图:G(V,E,W) ,W是一个函数,作用于边,生成一个实数,即W(E)->R
- 顶点到自身的路径:(
)表示从(
- 两个顶点之间的最短路径:
E与V的关系 E=O(
)。对于有向图来讲,假设有两个顶点,v1,v2,他们之间只有4种连接情况,依次类推
为什么会有负的权重?
比如社交网络上的喜欢可以看做是正的权重,比喜欢可以看做是负的权重
负权重的边带来什么问题?
如果存在一个带有负权重的边,那么每经过一个循环,会减少原有的权重值,这样造成的现象是可以得到任何可以得到的权重值。比如路径p=<S,A>权重是4,但是路径p=<S,A,C,B,A>权重是3

最短路径算法的一般思路是什么?
d(v) 表示从源点s到当前节点v的路径权重 ,
表示当前最好的路径上,v的前一个节点 ,通过这种方式就能重构整个最短路径
针对没有负权重的环
- 初始化 d[v] =
,
=NIL,d[s]=0
- 通过某种方式选择边(u,v),执行Relax操作,去更新源点到选择的顶点的当前路径值,以及选择顶点的前一个节点
Relax(u,v,w):
select edge(u,v):
if d[v]>d[u]+w(u,v):
d[v]=d[u]+w(u,v)
PI[v]=u
until all edges have d[v] <= d[u]+w(u,v)
relax操作的过程中会不会产生一个一个比  (s,v)还要小的值?
(s,v)还要小的值?
通过归纳法,假设有 d[u]
(s,u)。已知的是
表示s到v的最短路径,那么任意一个到v的顶点u和源点s到u的最短路径必定大于等于
,也就是
通过前面的假设,则必定有 。这说明,中间的过程的任意一个阶段产生的结果d[v]都不会比
(s,v)还要小
最短路径算法的一般思路问题一:错误的选边导致复杂度为指数级别
构造如下结构的图
边的权值按照
方式分配,图中给出的6个点的示例,如果全部显示的边(
,
)的权值为
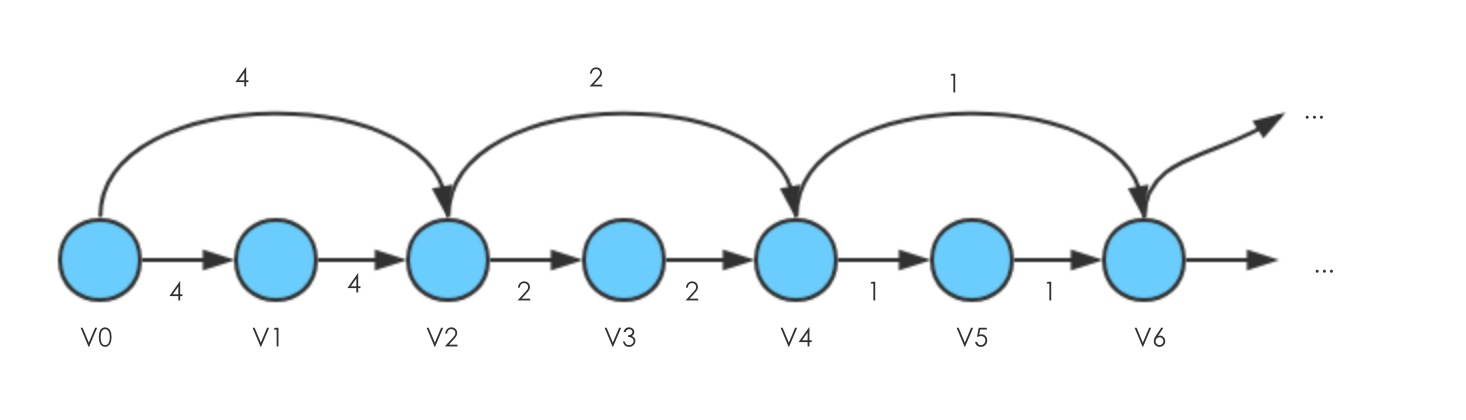
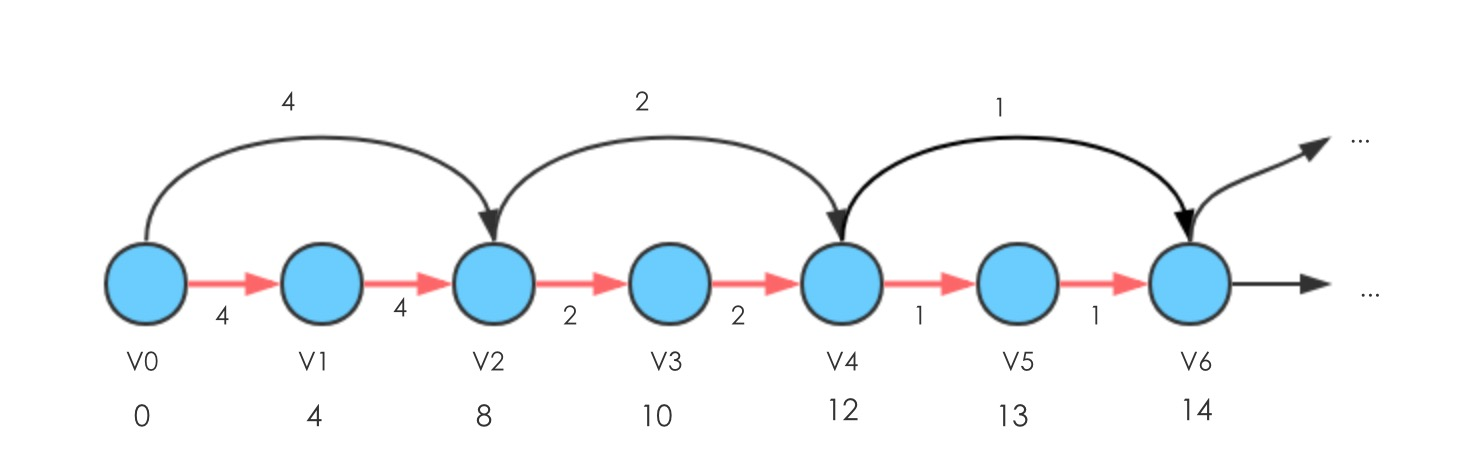
此时,Relax(,
)的边,会更新
到
的路径长度为13
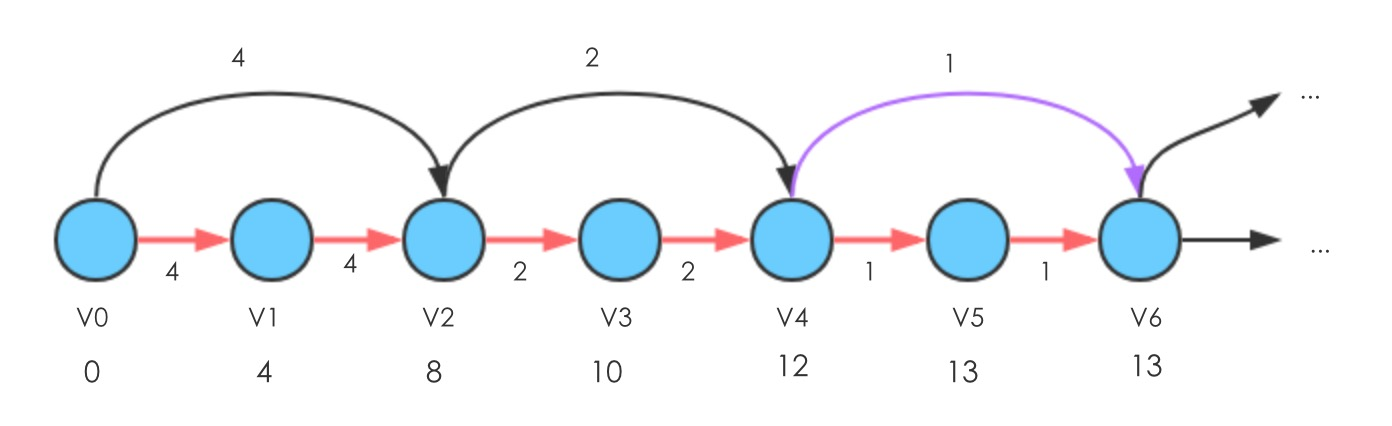
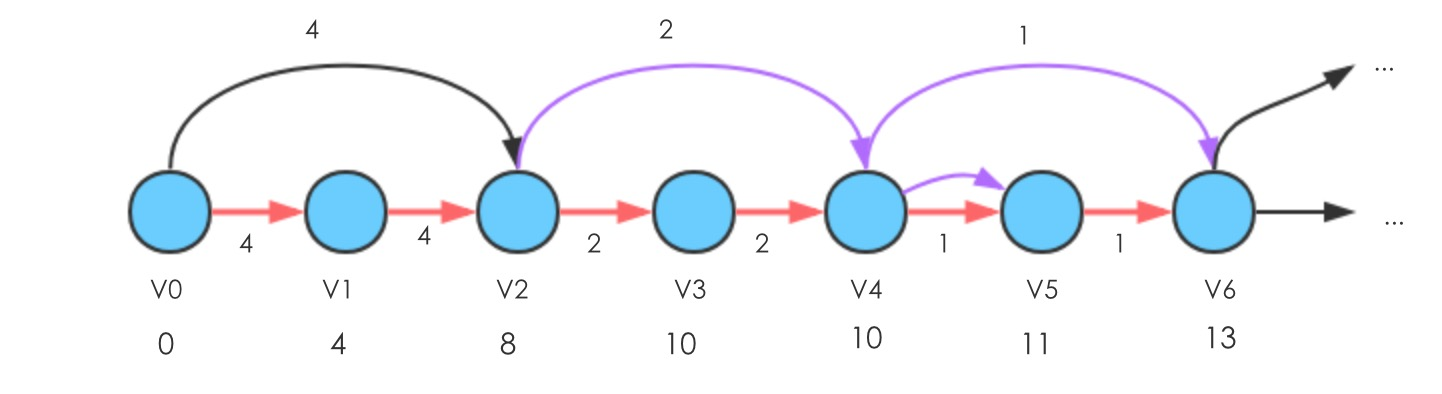
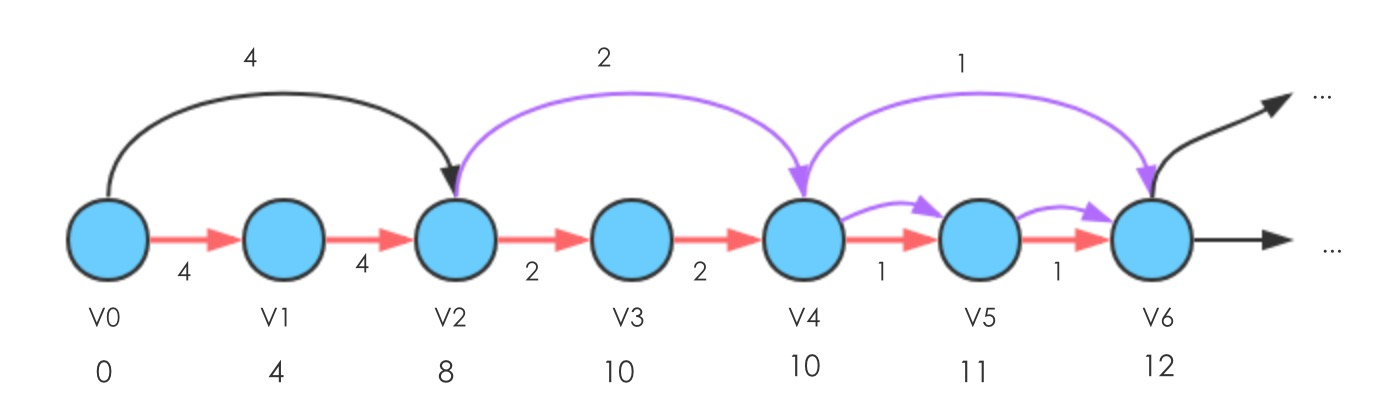
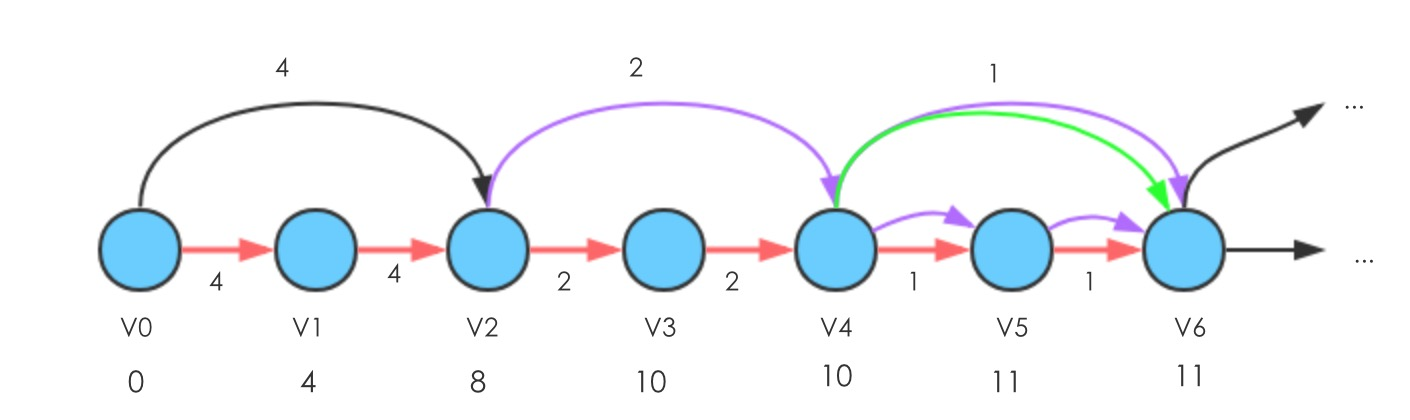
- 首先Relax(
,
),使得d[
]减1
- 再Relax(
,
- 然后Relax(
)和(
- 再执行Relax(
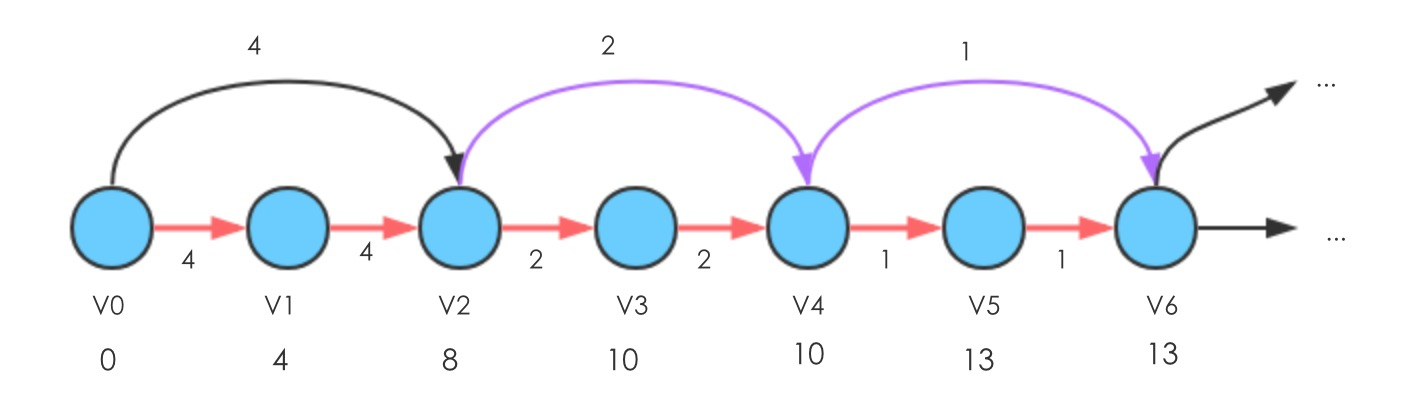
可发现,当Relax的边(,
)权重为1的时候,使得顶点d(
)减1;当Relax边(
,
)权重为2的时候,使得顶点d(
)减2,也就是从权重按照 1,2,4,...,
,
的方式执行的过程中,d(
)需要执行减少的总次数为1+2+4+...+
=
,也就是说,会执行的次数为指数级别
最短路径算法的一般思路问题二:负权重环
如果在源点到目标节点经过的路径上,经过环会导致权重减少,这个算法不会结束
如何获取有向无环图(DAG)中,单个源点到某个点的最短路径?
DAG表示只是没有环,可以存在负边权重
- 对DAG进行拓扑排序,这样保证了u到v的路径一定是u在v之前
- 找到源点,按照从左到右,DAG排列的顺序,对经过的每个顶点进行Relax操作,便得到了源点到所有顶点的最短路径
假设排序好的拓扑图如下,对于初始化时,每个源点到每个节点的距离都认为是
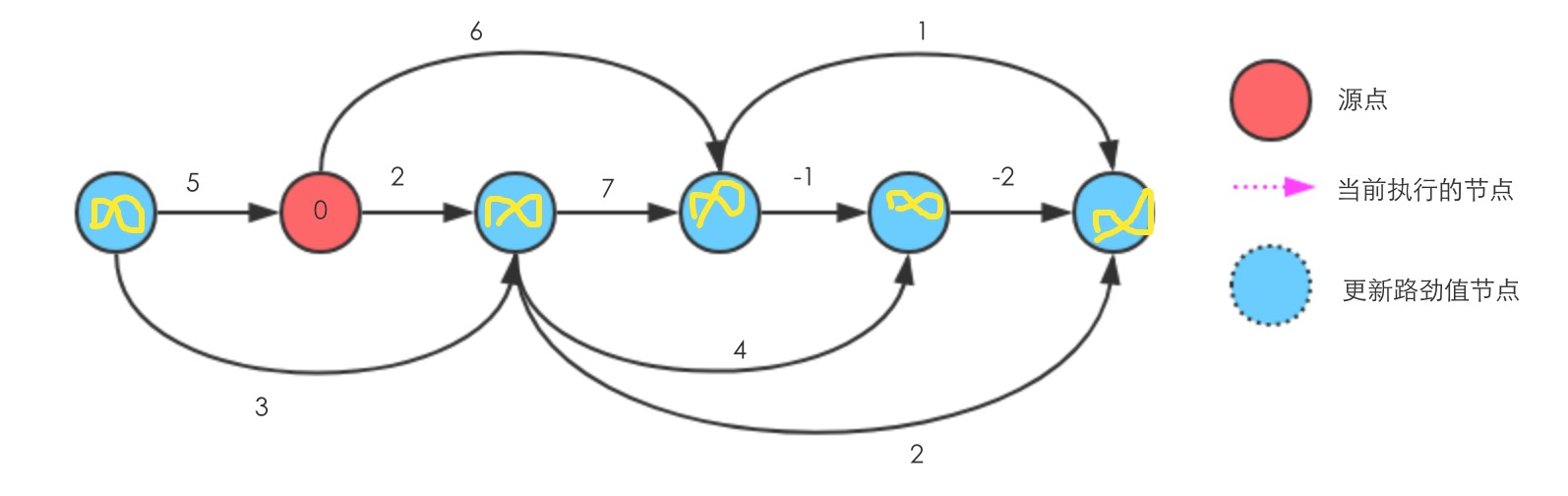
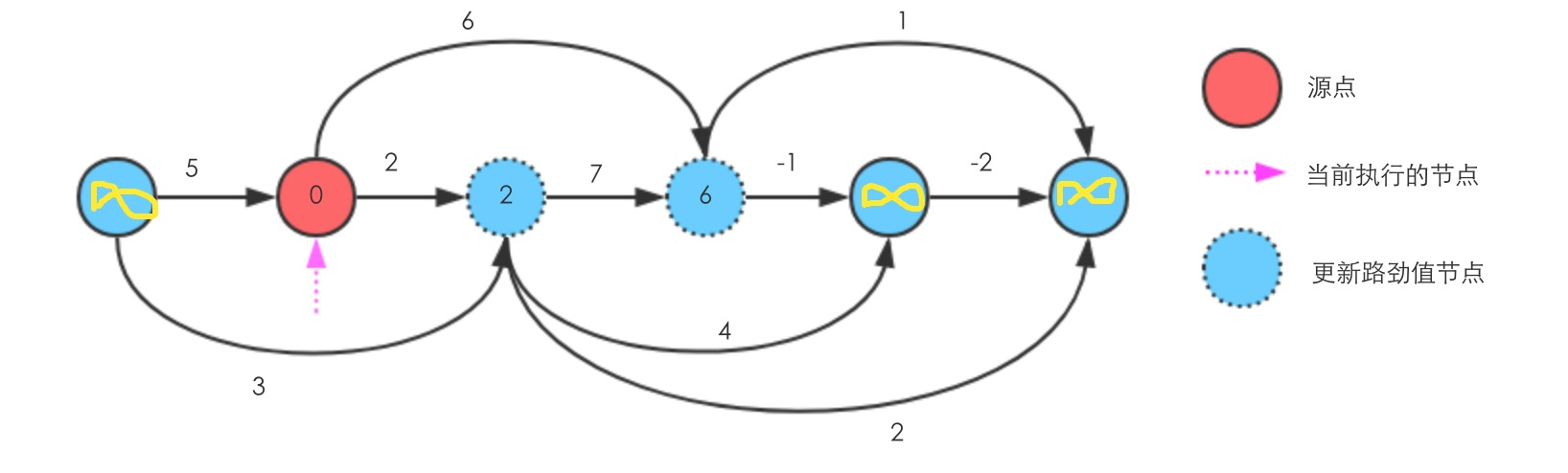
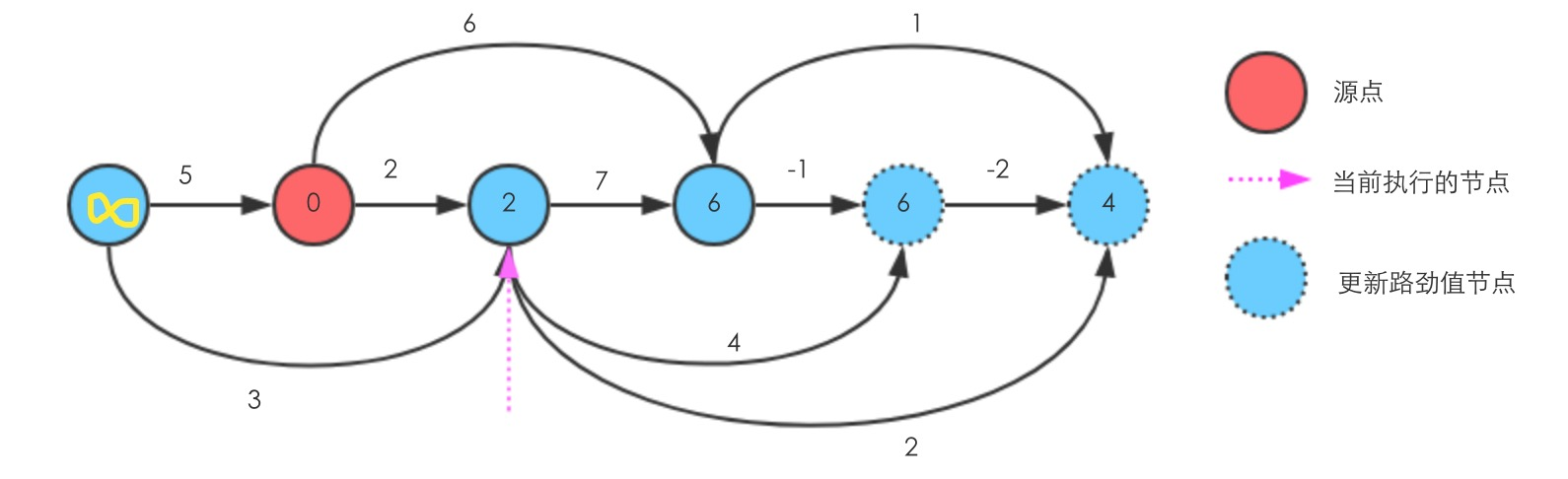
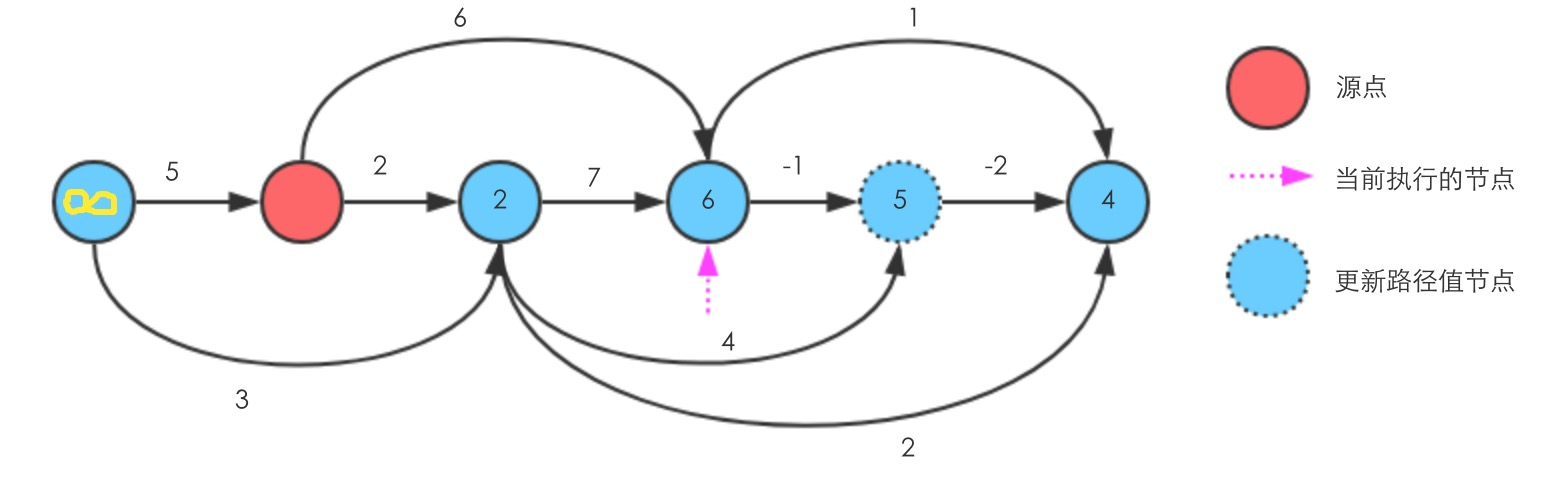
继续往右执行Relax
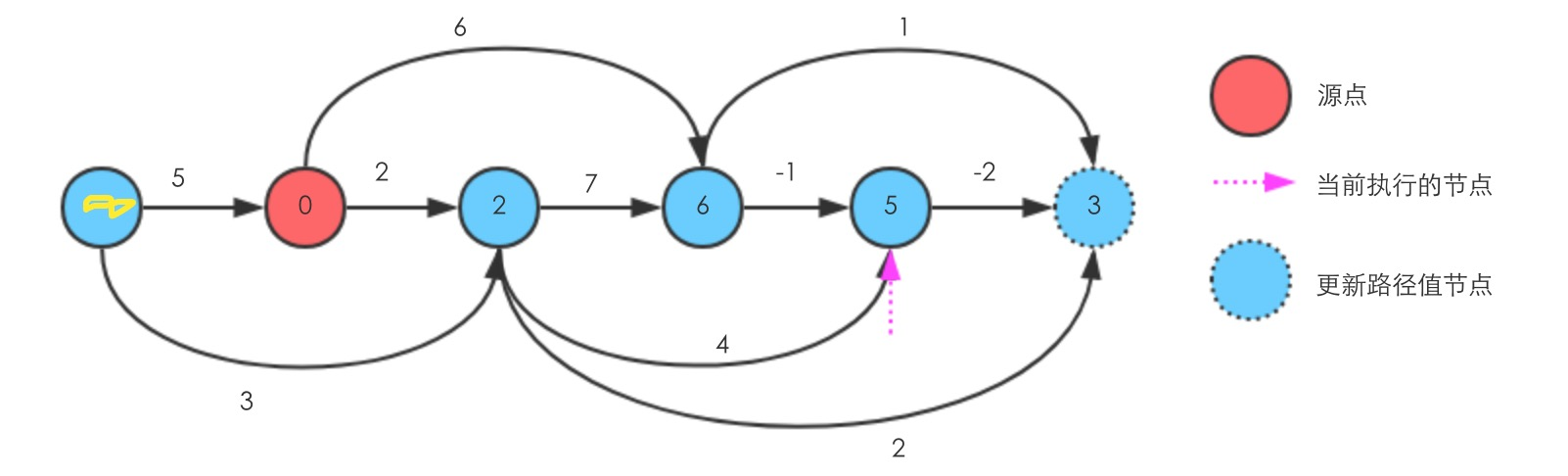
至此执行完毕,可以看到源点到所有节点的最短路径,从左到右分别是 ,0,2,6,5,3
如果图中有环,但是经过这个环不会导致权重减少,如何计算最短路径?
使用Dijkstra算法。伪代码算法如下:
Dijkstra(G,w,s): //G是图,w是权值,s是源点
Initialize(G,s) // 初始化,设置d[s]=0,其它都是无穷,以及PI
S <- {} //已知最短路径的点的集合
Q <- V[G] //需要被处理的顶点,可以看做是一个最小优先级队列,根据d()值进行排序
while Q is not empty: //只要还有没处理的节点
u <- Extract-Min(Q) //从节点中找出一个最小的路径权重的节点,并从Q中移除
S <- S U {u} //将找到的节点并到S中
for each vertex v belong to Adj
Relax(u,v,w) //对边的d()值进行更新
例子如下,选择A为源点
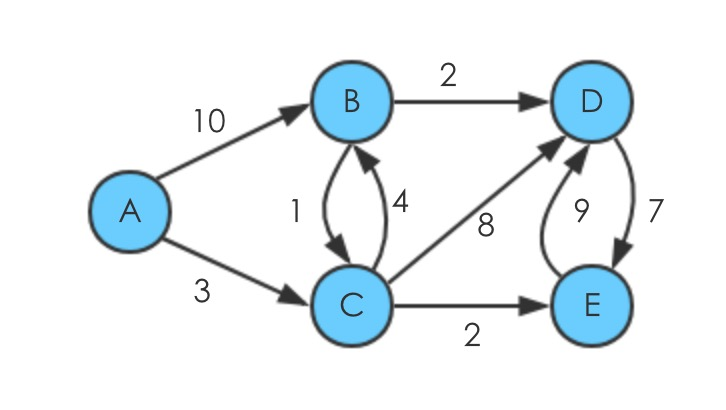
- 进行初始化,从A到其它节点的距离都是
- 获取队列中的最小值,此时是A本身,此时S={A(0)},然后进行一次Relax操作,即发现A能达到的顶点为B,C,更新后队列中的值为 Q={B(10),C(3),D(
- 获取队列中的最小值,此时是C,S={A(0),C(3)},对选择的C做Relax,C能到达的节点为B,D,E,相应队列更新为:Q={B(7),D(11),E(5)};
- 获取队列的最小值,此时是E,S={A(0),C(3),E(5)},对选择的E做Relax,E能到的节点为D,由于比现有的D值要大,所以没有更新,Q={B(7),D(11)};
- 获取队列的最小值,此时是B,此时S={A(0),C(3),E(5),B(7)},B能到达的只剩下D了,B到D得到的值为9,要小,更新Q={D(9)}
- 获取队列最小的值,此时是D,此时S={{A(0),C(3),E(5),B(7),D(9)},至此结束。
括号中的值表示路径距离
Dijkstra算法的时间复杂度
所有的耗时操作包括:
- 将所有的顶点插入优先级队列中,耗时为
;
- 从优先级队列中提取一个最小的值,耗时为
- Relax操作对边进行d值减少,耗时为
; 实现优先级队列方式不同,耗时不同
- 使用Array。 提取最小值花销:
,操作所有的队列中的元素,那么时间就是
=
- 使用最小堆。提取最小值花销:
,减少key的花销
- 使用Fibonacci堆,提取最小值花销:
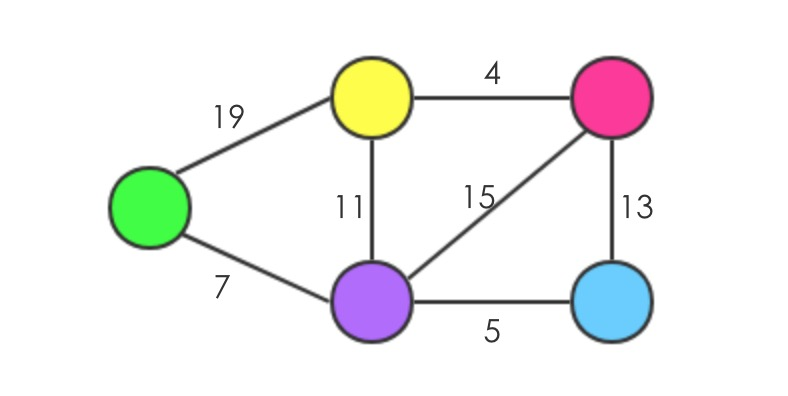
最直观的使用Dijkstra的感受是:以下图为例:
假设绿色的点是源点,如果用这样长度的绳子将各个节点连接起来,那么拎起绿色的球,从上往下悬挂,那些蹦直的线相加就是源点到各个点的最短距离,比如绿色是源点,到其它点的最短距离分别是 7,12,18,22(颜色依次是紫色、蓝色、黄色、红色)
为什么Dijkstra不能处理负权重环的问题?
Dikstra不会去看已经处理好的节点,只会处理没有看到的节点,如果已经处理的节点都是最小的值,再不存在负权重环的情况下,是不会出现使得路径变小的情况。详见:stackoverflow.com/questions/6…
如果在源点到目标节点经过的路径上,有经过环且会导致权重减少,怎么处理最短路径问题?
使用Bellman-Ford算法。
Bellman-Ford(G,w,s):
Initialuze(G,s)
for i=1 to |V|-1:
for each edge(u,v) belong to E:
Relax(u,v,w)
for each edge (u,v) belong to E:
if d[v]>d[u]+w(u,v)
report negative cycle exist
Bellman-Ford最终提供的是,如果没有负权重的环,那么能返回最短路径(d[v]=),否则只是检测出存在负权重的环
耗时分析
两个for循环,分别为V,E,所以时间复杂度就是O(VE)
为什么Bellman-Ford算法在不存在负权重环的情况下能够计算最小路径?
只需要证明,如果不存在负权重的环,那么经过Bellman-Ford有d[v]=。
取一条拥有最少边的最短路径p=<,
,...,
>,其中
为s,
=v。 如果不存在负权重的环,那么说明p是一条简单路径,这表明,k
|V|-1。
这里也不可能是一个正环,即每经过这个环,权重增加,如果是那么它就不是最短路径了
当进行第一次循环的时候,取到的边(,
)进行了Relax,那么有
进行第二次循环,取到的边(
,
)进行了Relax,那么有
那么经过k轮循环之后,有,也就是说经过了|V|-1轮循环之后,每个从源点可达的顶点都计算了最短路径
简单路径(simple path):指除了起点和终点之外,其它顶点不会重复。对于简单路径p=<
,...,
>来讲,如果k>=|V|,那么路径上总的顶点数是|V|+1,但实际只有 |V|个顶点,那么必定存在一条重复的边,使得非起点终点重复了,也就是说他不是简单路径了
为什么Bellman-Ford算法能检测负权重环?
经过|V|-1轮循环之后,如果还有一条边能够Relax,那么当前从s到v的最短路径并不是简单路径,因为所有的节点都已经看过了,这时候肯定存在了重复的节点,也就是说存在一个负权重的环
如果对一个路径上有环,且所有权重值都是负权重,那么使用Bellman-Ford算法能得到最长路径吗?
不能,因为Bellman-Ford对于存在负权重的环的时候只会抛出异常,并没有计算路径,这实际是一个N-P的问题,即花的时间在指数级别或者之上
类似的,如果要求不经过负权重的环的情况下,计算最短路径,也并不是件容易的事情
