

本文来自阿里云前端监控团队,转载请注明出处
本文为2018年6月21日,在北京举办的GMTC(全球大前端技术大会),下午性能与监控专场,由阿里云前端监控团队前端技术专家彭伟春带来的演讲稿,现场反馈效果非常好,地上都坐了三圈,很多人反馈根本无法挤进去。先上现场照。

正文从这里开始~

大家下午好,今天我给大家带来的主题是《大前端时代前端监控的最佳实践》

先做一个自我介绍,我叫彭伟春,英文名是Holden, 阿里花名是六猴, 大家都叫我猴哥。是阿里开源同构框架beidou的作者,目前是阿里云前端系统技术负责人

今天我分享的内容分成三个部分
* 第一部分是“大前端时代前端监控新的变化”, 讲述这些年来,前端监控一些新的视角以及最前沿的一些思考。
* 第二部分"前端监控的最佳实践", 从使用的角度出发,介绍前端监控系统的各种使用姿势
* 最后是“阿里云ARMS前端监控系统架构”, 简单地剖析下,阿里云前端监控系统是怎么实现的。

先进入我们第一个环节 大前端时代前端监控新的变化
要了解前端监控新的变化,还得先看看前端这些年发生了哪些变化
* 首先是Gmail的横空出世,开启了SPA的时代
* Backbone/Angular等框架带来了MVVM模式的同时,也把JS从脚本语言提升到了工程语言
* React Native/Weex把移动端开发从Hybrid模式进化到了跨端开发模式
* Node.js问世为前端带来了更多的可能性

前端这些年发生了翻天覆地的变化,又会给监控带来什么呢?让我们思考下以下几个问题
* 传统监控模式能否适用于新的技术?比如PV统计
* SPA模式下首屏如何计算?
* 跨端开发给监控带来什么什么挑战?
* 前端监控的上报模式在Node.js端是否合理?
* 接下来我和大家一起探讨其中的一两项
早些年,SPA如此盛行,我们也在业务中做了尝试,体验是大幅提升了,可业务方却吐槽PV下降了

那到底是什么导致了PV下降了呢?在后端直出时代,我们每一次的交互,都是向后端请求一个新的页面,PV自然就高,改成SPA模式之后,大量的页面请求变成了页内路由,或者说是页内转场。那如何解呢?这难不倒我们,大部分框架路由都是基于哈希实现的,我们只要侦听hash改变,每次改变上报一次PV就好了。也有少量的路由并不是基于哈希实现的,比如angular, 这时候就需要轻量级地hack pushState和replaceState

这样就完美了吗?

我们再思考下以下几个案例
* 某新闻类的网站,每次看完之后,都会下拉刷新,加载新的内容,这个时候是算一次PV还是多次?
* 天猫商品列表页,看完一屏之后,向上滚动会再加载新的一屏,PV该算一次还是多次?
* 阿里云邮后台一直开着,每周上百次查看,是算一个PV还是每次查看都计算一次?
* 未关闭的浏览器tab几小时之后再次浏览,该不该再计一次PV?
* 查找信息时,浏览器Tab之间快速切换,切换过程中要不要计一次PV?
其实还有很多其它层出不穷的场景,具体该如何去统计PV留给大家去思考, 不再展开
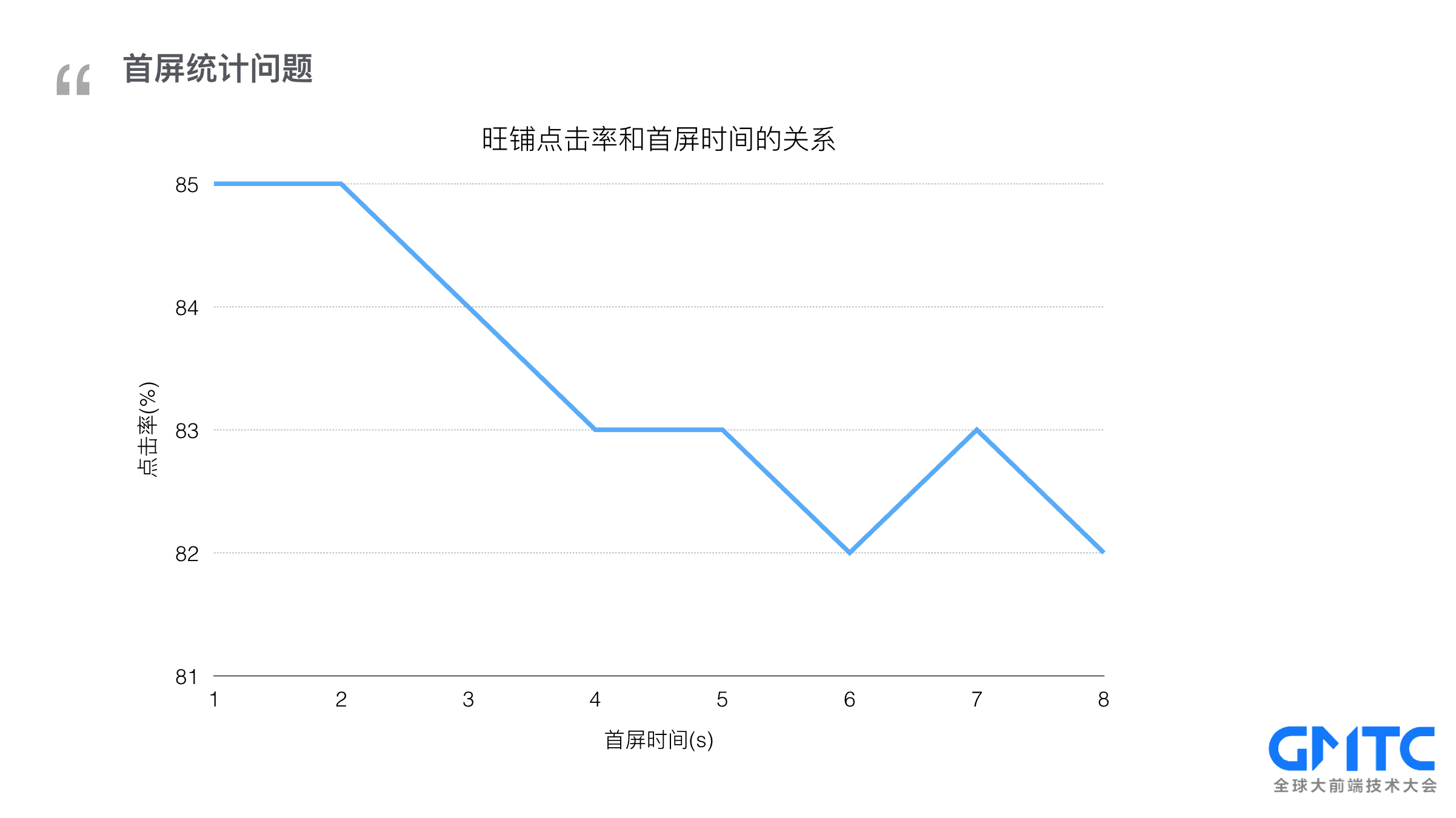
接下来我们探讨一个大家最感兴趣的话题: 性能。先看一组我们的统计数据,淘宝旺铺页面点击率随加载时间变长从85%的点击率逐步降低到了82%,别小看这3%,在阿里这么大的体量下,3%意味着巨大的商业价值,那站在前端监控的角度,首屏是如何统计出来的呢?

回到那个刀耕火种的年代,那时候要什么没什么,都是自己动手丰衣足食。这就是手动打点阶段: 手动打点,分别在页头和首屏dom节点处new Date()打点,计算差值,作为首屏时间,再加上setTimeout(new Date(), 0)标记首屏可交互时间
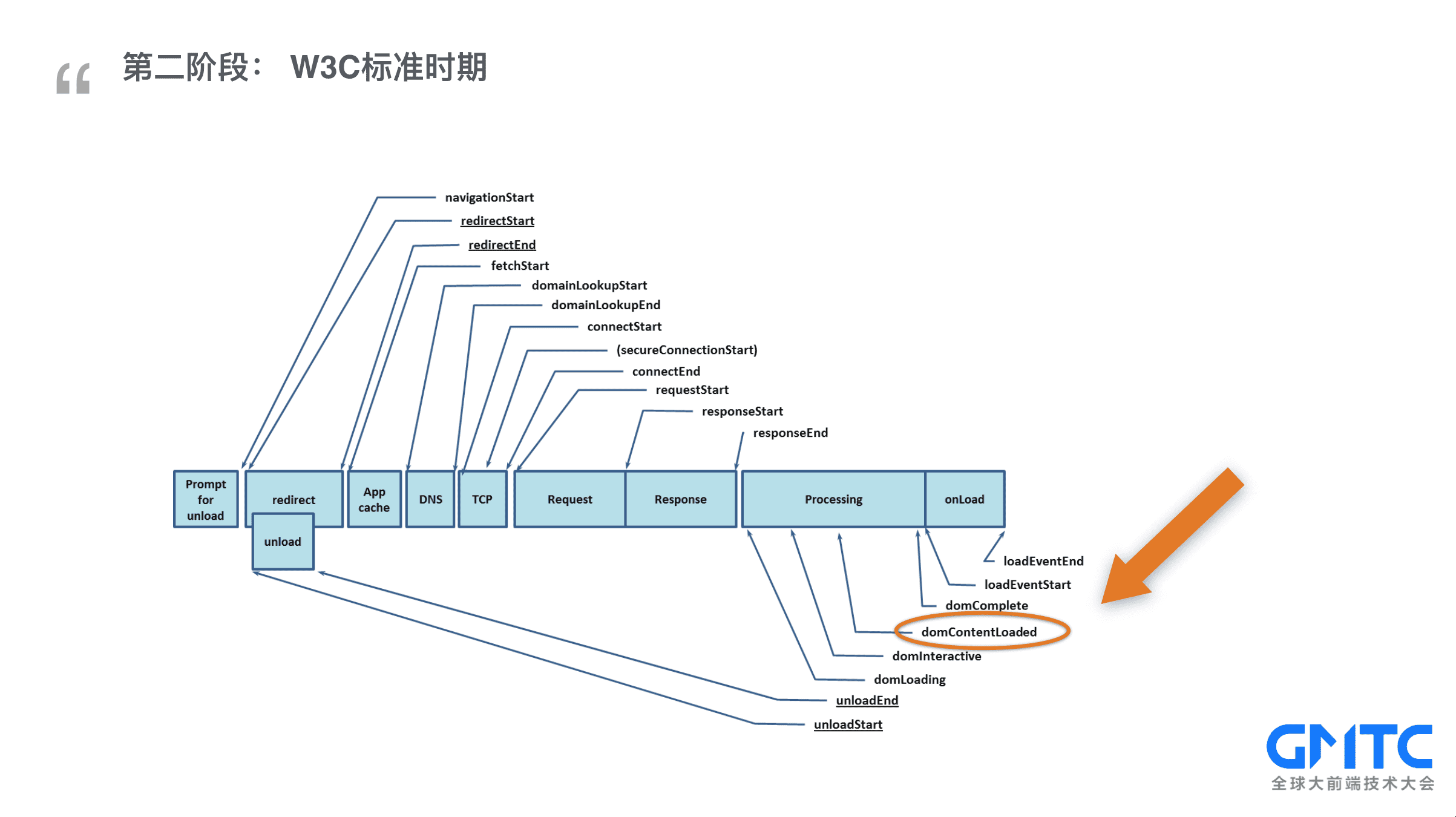
随着前端的飞速发展,手工打点的模式早已满足不了需求了。为了帮助开发人员更好地衡量和改进web性能,W3C性能小组引入了 Navigation Timing API 帮我们自动,精准的实现了性能测试的打点问题,大致地过一下,性能API里面包含了【卸载上一个页面】【重定向】【应用缓存】【DNS域名解析】【TCP连接】【请求页面】【响应】【页面处理】最后触发load事件,通常我们把domContentLoaded作为首屏时间。Chrome最早支持,IE跟进
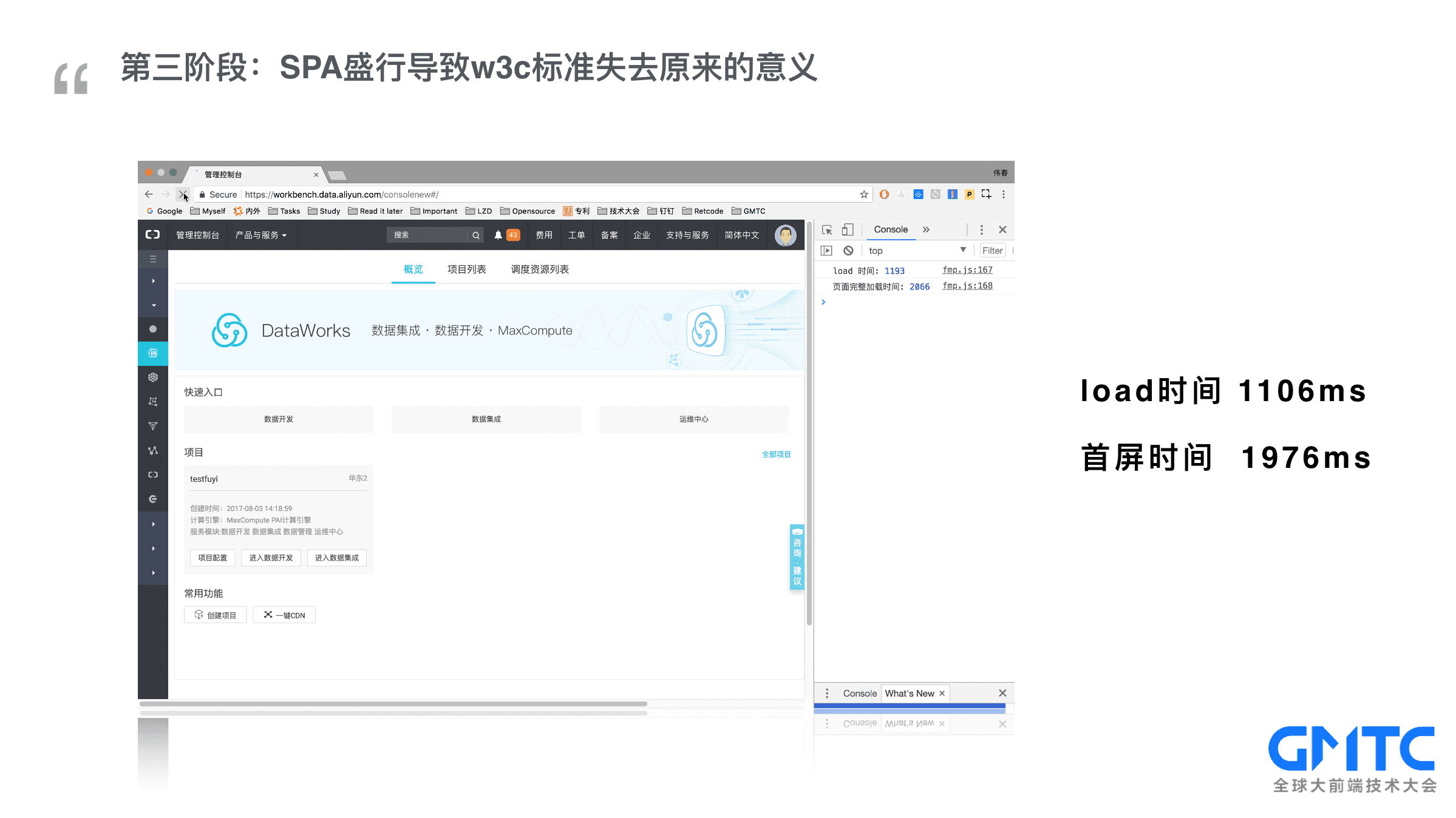
在很长一段时间里,我们都享受着performance API带来的便利, 但随着SPA模式的盛行,我们再回过头来看看W3C标准是否足够了。先来看一个案例,这是阿里云某产品的管理后台。整个加载过程分成三个部分,1. 加载初始的空壳页面 2.加载JS资源并异步请求数据 3. 前端渲染中间的主体部分。按照W3C标准取值首屏时间应该是1106ms, 而实际的首屏在1976ms,也就是完成异步取数据后渲染完页面的时间点。为什么会相差如此大呢?实际上SPA的盛行让W3C标准失去了原来的意义
针对这种情况Google lighthouse提出了FMP的概念,first meaning paint, 也就是主要内容可见时间,那什么是主要内容? 每个人得出的结论可能会不一样
先做一个猜想:主要内容 = 页面渲染过中元素增量最大的点
先通过飞猪案例做一次验证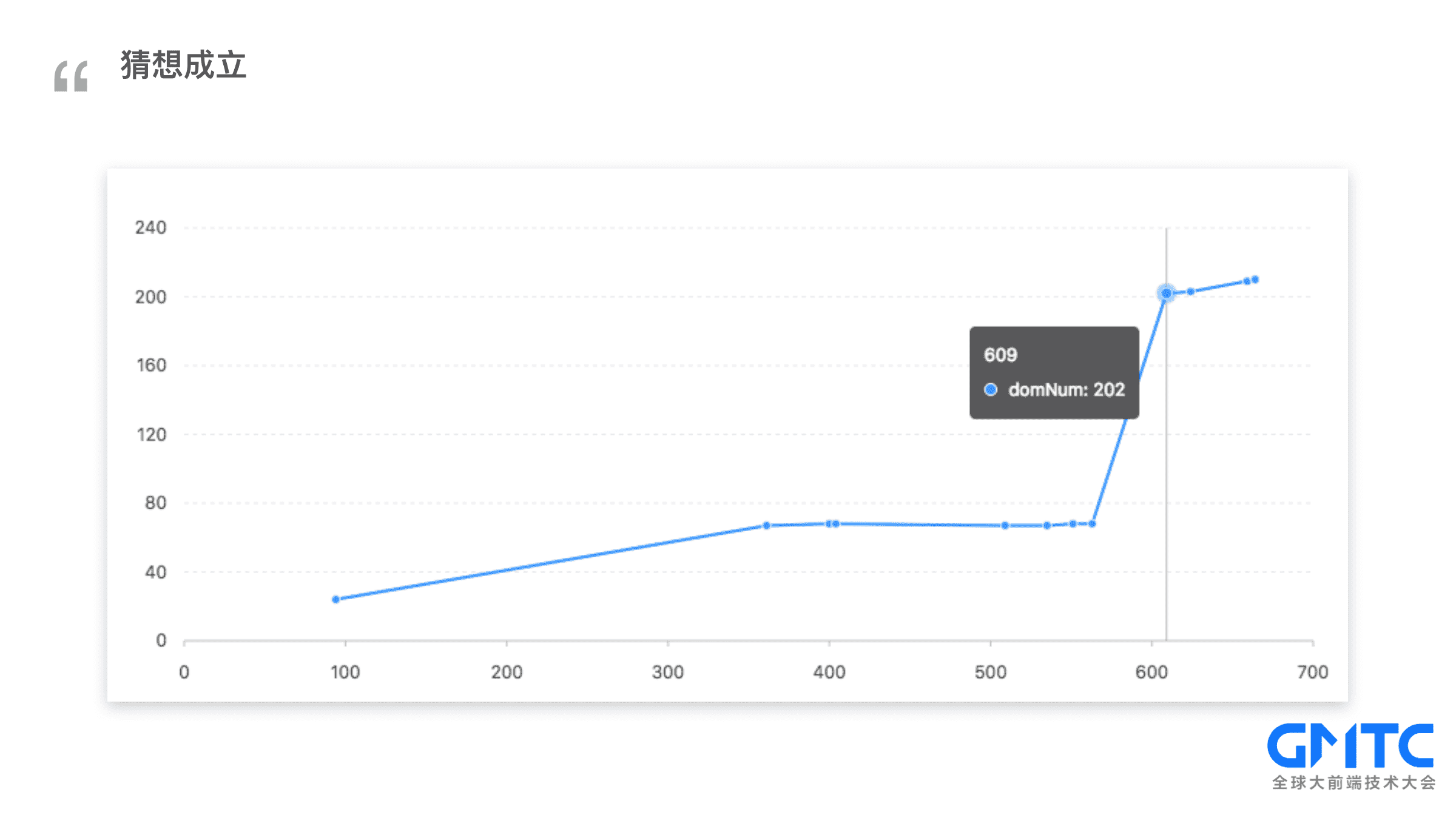
猜想成立
再通过手淘案例做一次验证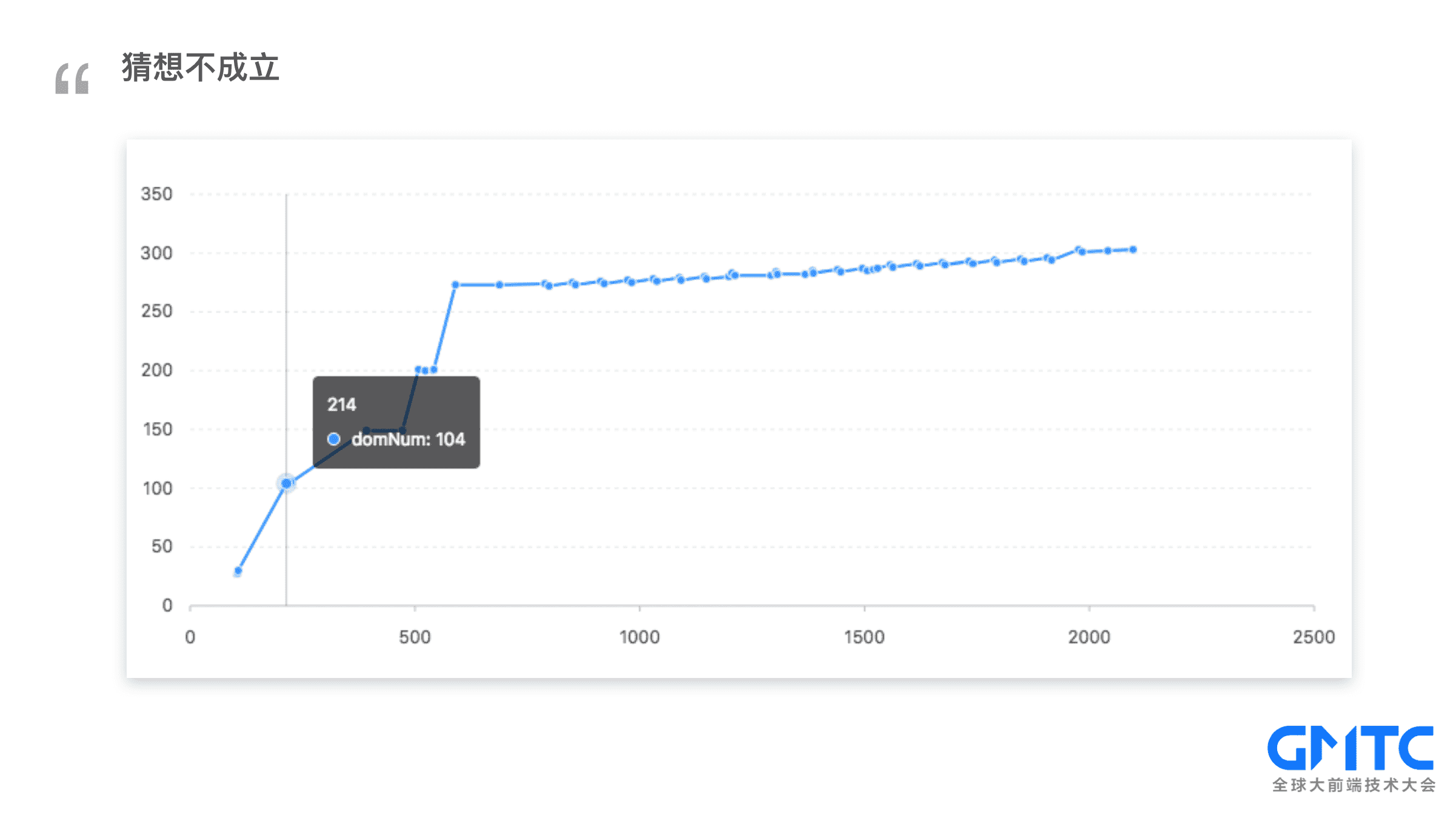
猜想不成立
那到底是什么原因导致我们的猜想不成立?
* 首先是元素是否可见, 不可见的元素对用户的影响基本为0
* 其次是每个元素对页面的影响是否等效?由此引出权重,不同的元素采用不同的权重计算影响。阿里云前端监控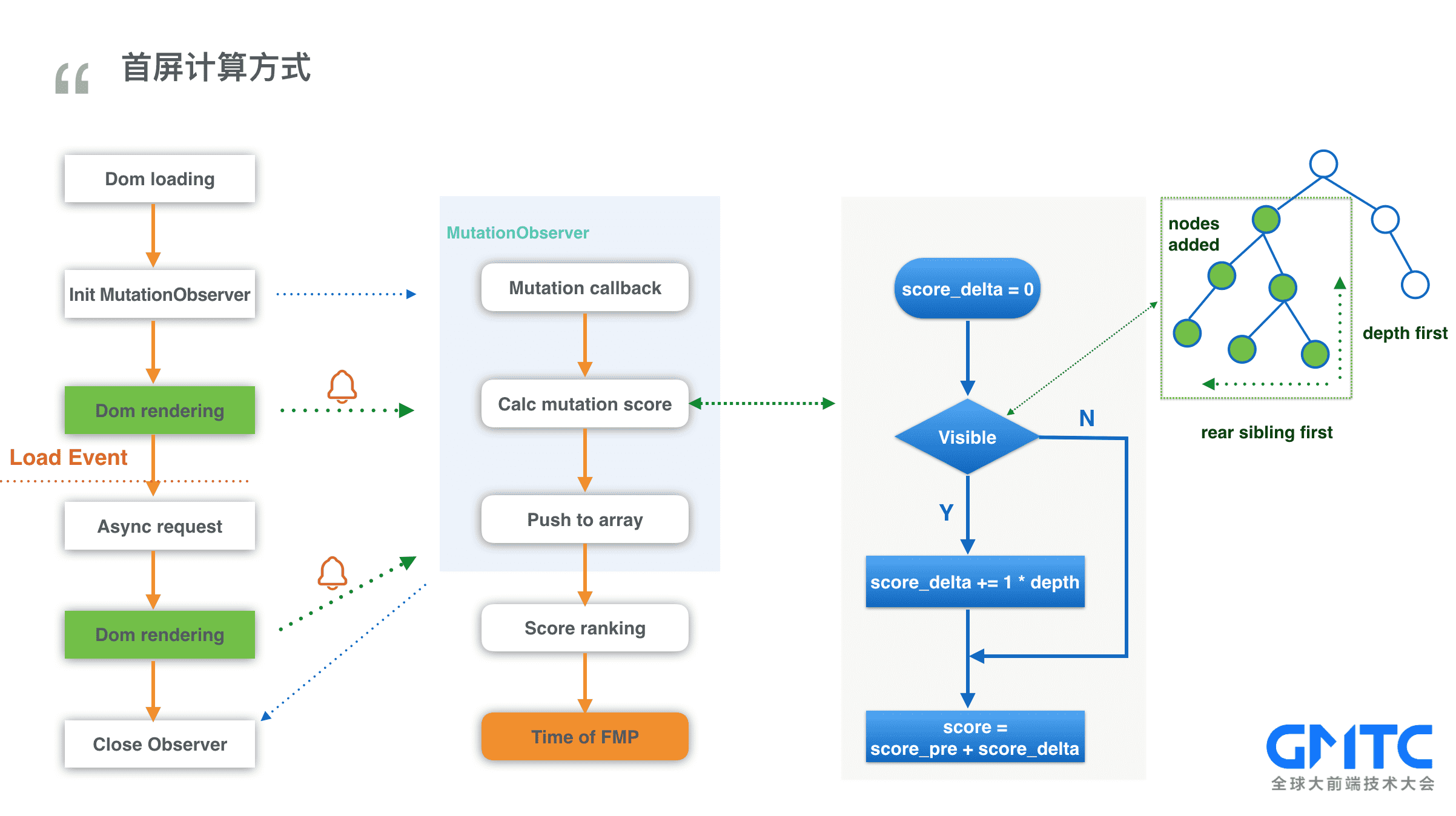
根据上面的修正因子。我们重新设计了一遍算法, 计算每次变化的得分,一起来看看,算法是如何实现的?
如图所示分为三个步骤
1. 侦听页面元素的变化
2. 遍历每次新增的元素,并计算这些元素的得分总和
3. 如果元素可见,得分为 1 * weight(权重), 如果元素不可见,得分为0
如果每次都去遍历新增元素并计算是否可见是非常消耗性能的。实际上采用的是深度优先算法,如果子元素可见,那父元素可见,不再计算。 同样的,如果最后一个元素可见,那前面的兄弟元素也可见。通过深度优先算法,性能有了大幅的提升。
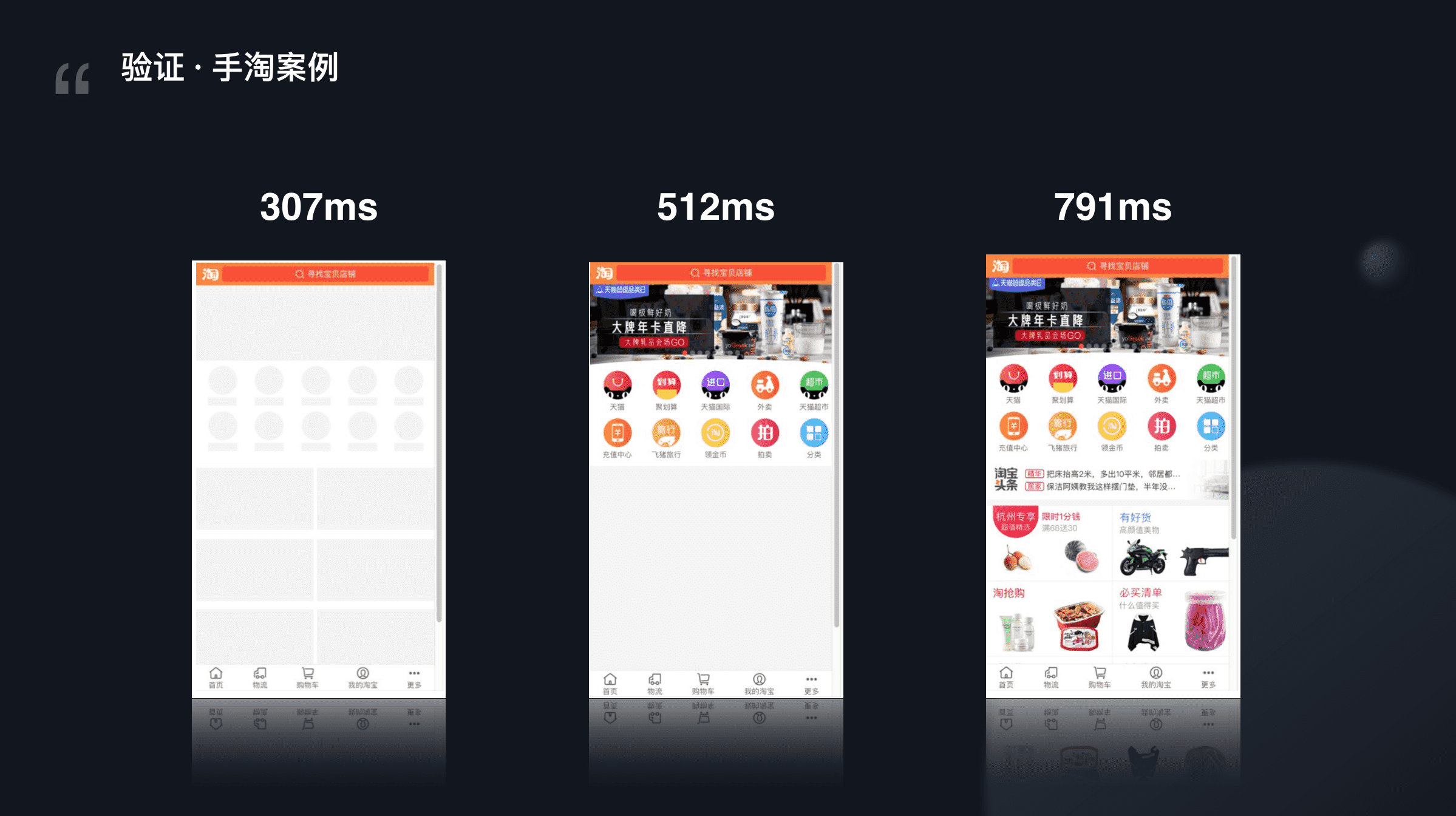
再拿之前的手淘案例来验证一遍。
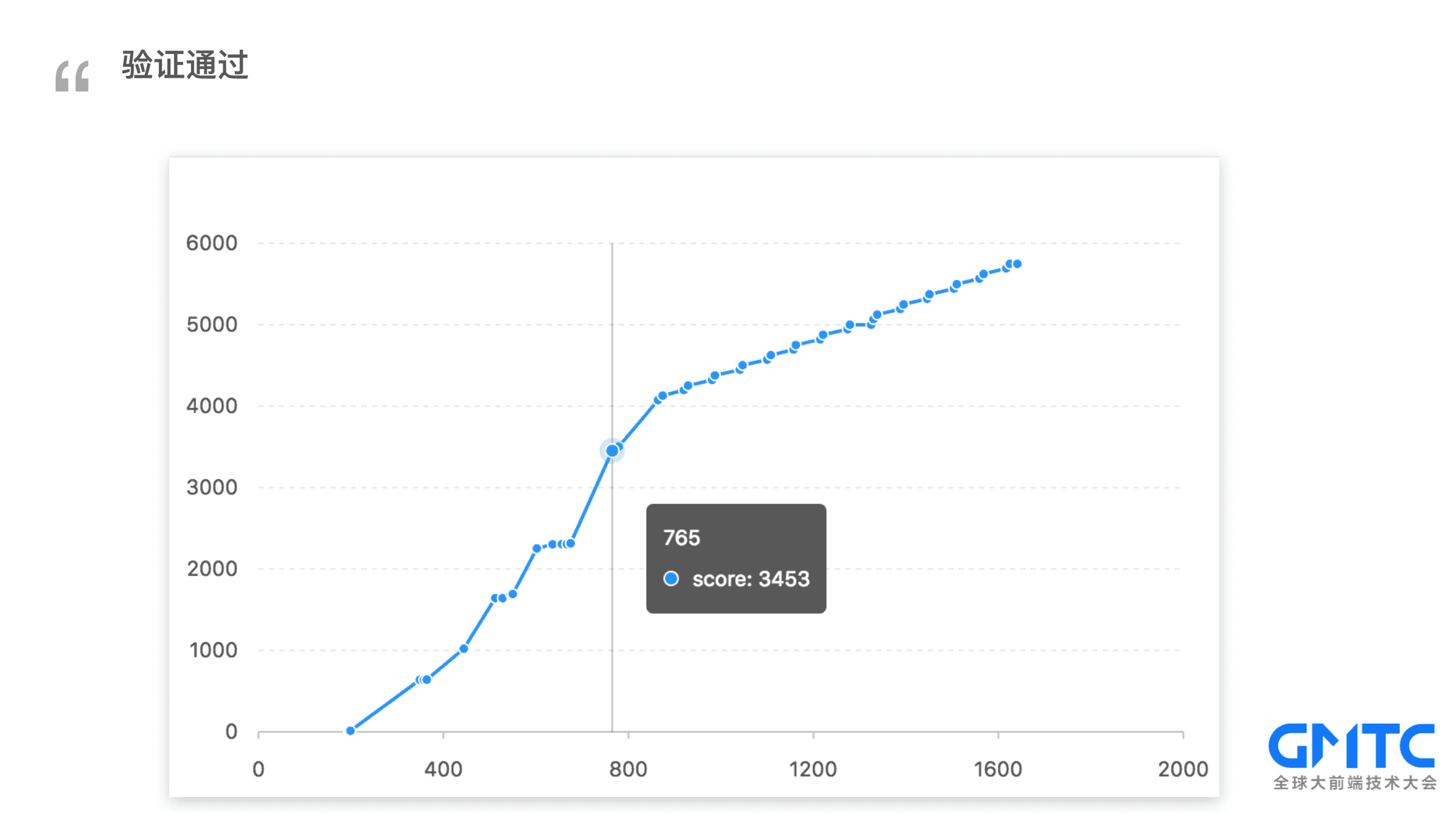
经过改良之后,第三屏主要内容的得分是最高的,符合预期。
那么接下来首屏统计又会发生什么样的变化呢?其实统计首屏时间本身就是浏览器的职责,交由浏览器来处理是最好的。目前W3C关于首屏统计已经进入了提议阶段,坐等W3C再次标准化。大家可以在github上看到最新进
限于篇幅,前端监控其它新的变化不再展开。讲了这么多前端监控的新变化,那什么才是打开前端监控最最正确地姿势呢?

由此进入我们的第二个环节,“前端监控的最佳实践”
我用一个表达式“要是什么什么就好了”来总结。我经常会想【要是天上能掉钱就好了】,【要是有个机器人帮我写代码就好了】。同样的,每次发版之后都是提心吊胆的,不知道用户到底能不能正常使用。(这时候你就会想)要是能有双眼睛帮我盯着系统就好了;每次出错,都是用户投诉反馈问题,实际等到用户主动反馈问题,影响面已经非常大了: (这时候你就会想)要是能在第一时间发现错误就好了;
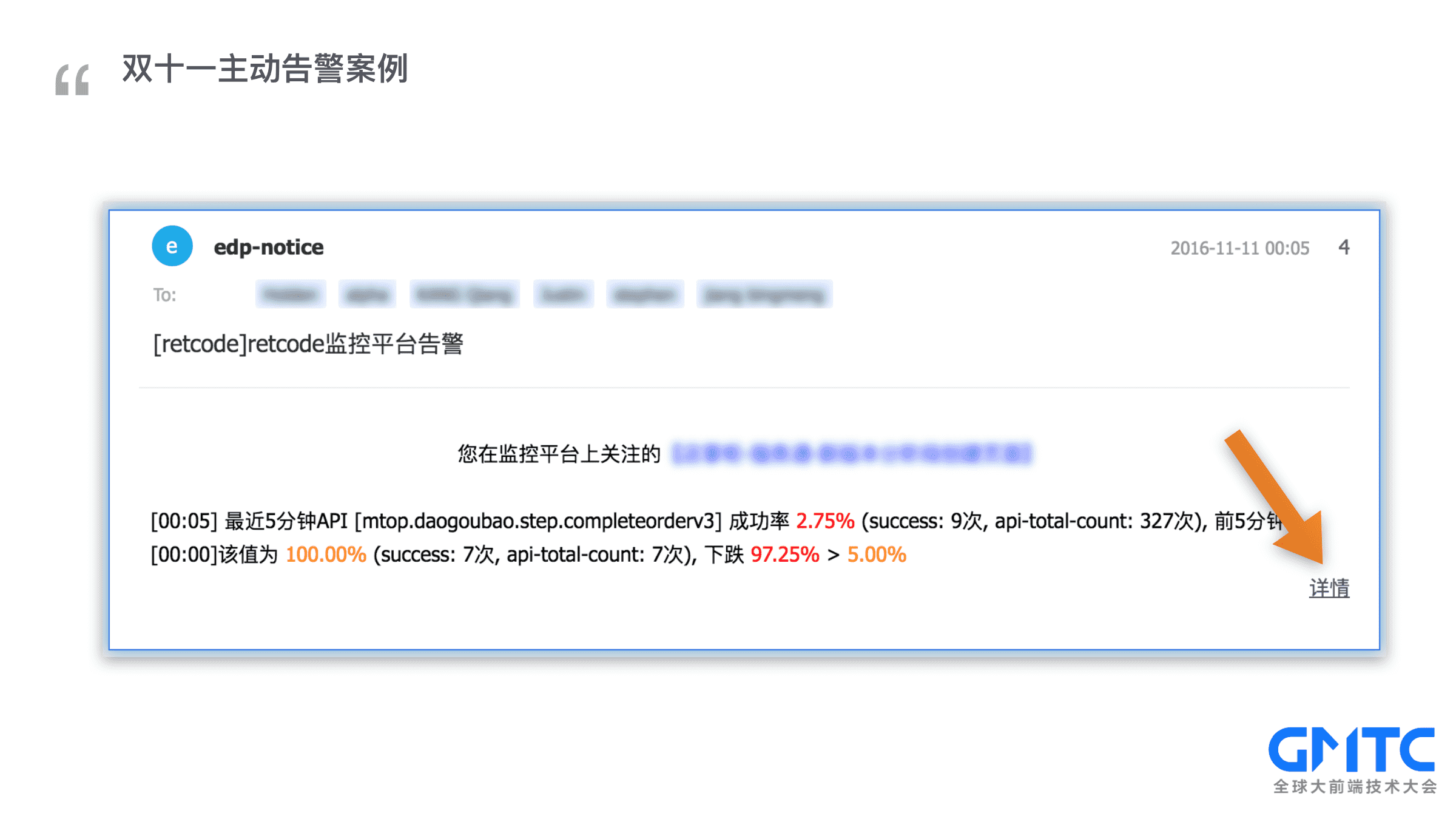
还真有这样的案例,前年双十一凌晨值班,突然收到邮件和短信告警,于是点开了详情
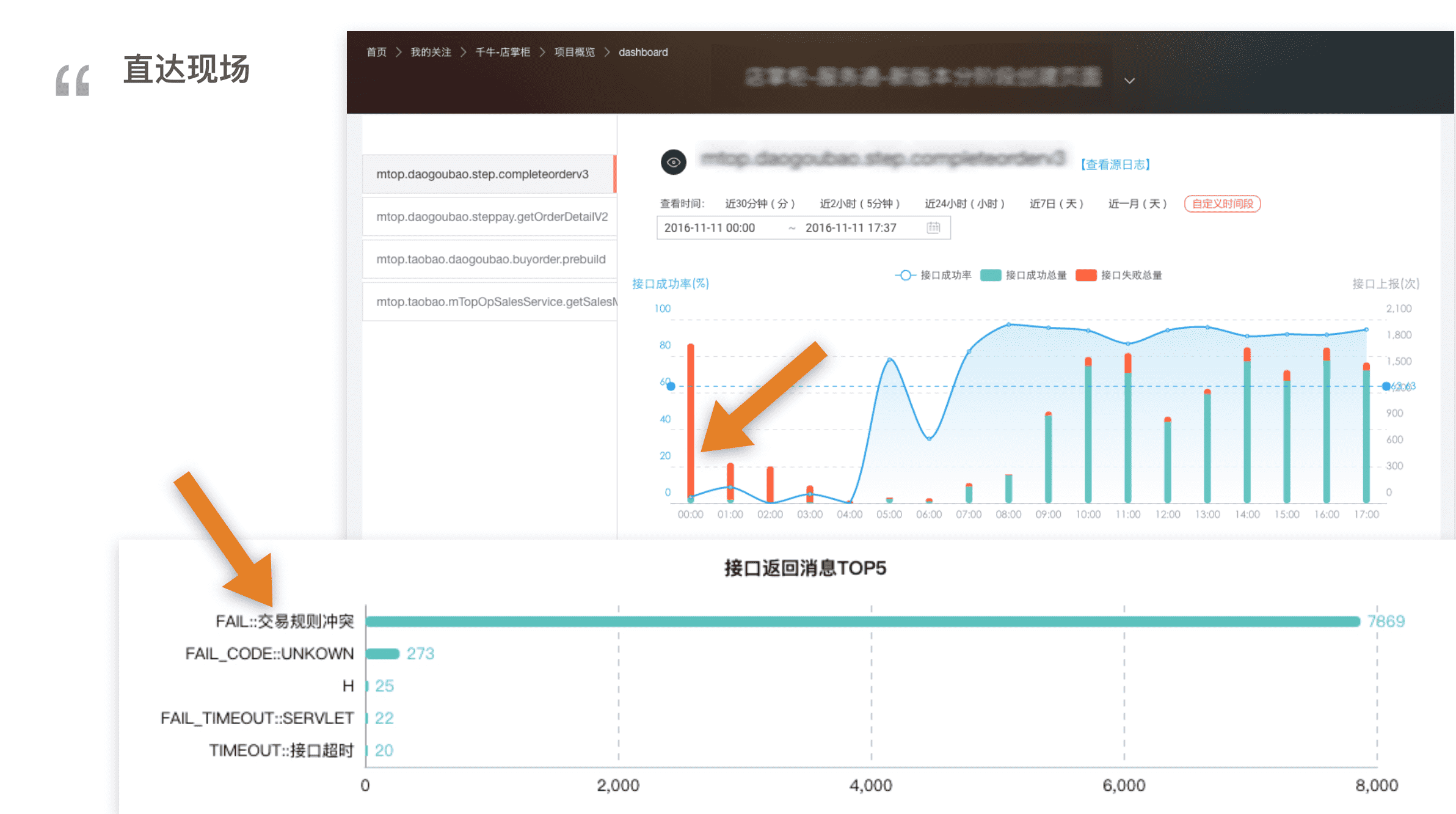
发现在接口成功率趋势图中,接口请求量大幅上升,伴随着成功率急剧下降,再查看错误信息聚合模块,发现频率最高的错误信息是【交易规则冲突】,深度排查之后,最终找出了原因,是运营配置的双十一优惠规则和平时优惠规则产生了冲突,导致下单失败。最后凌晨4点申请了紧急发布修复了冲突,解除告警。
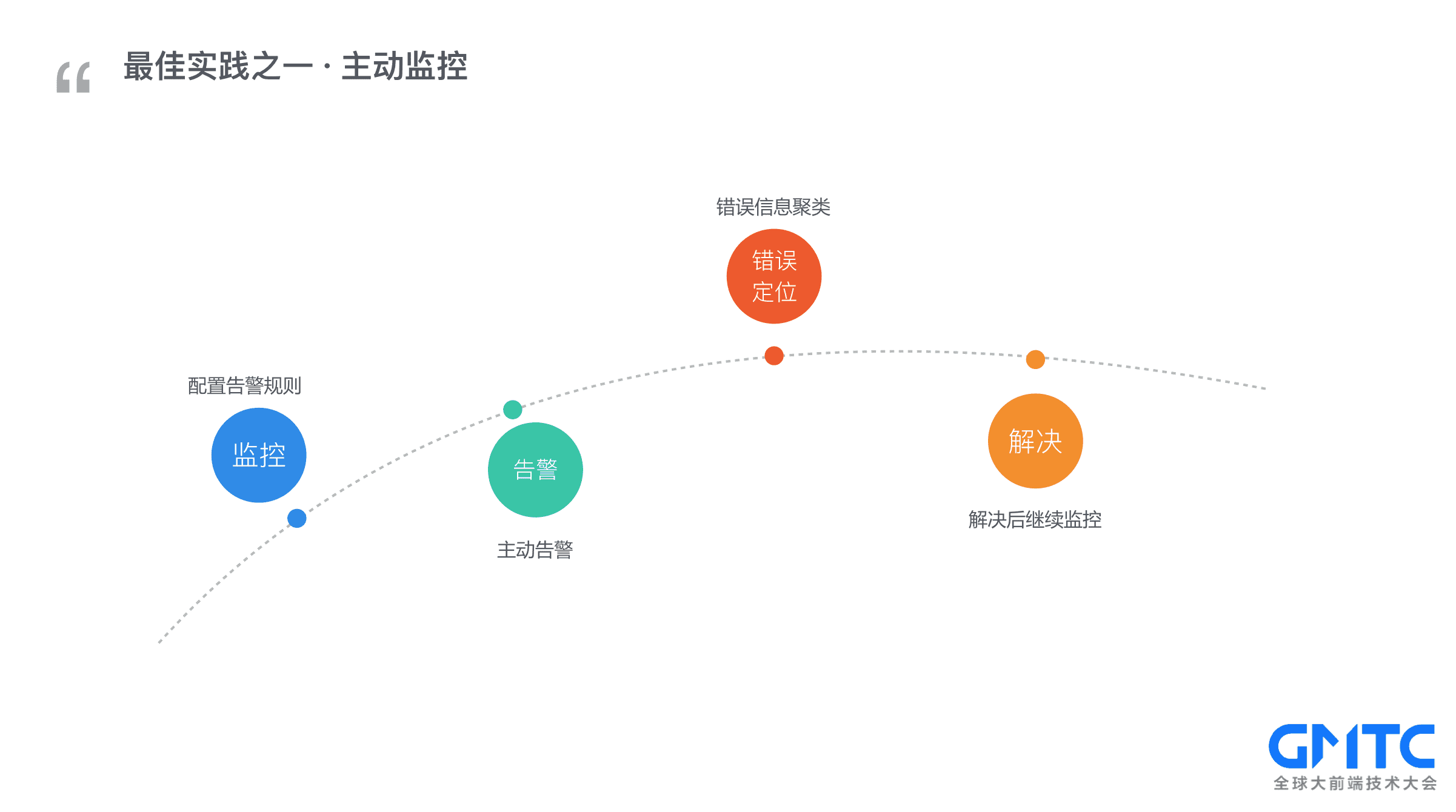
由此可以得出最佳实践之一:主动监控。当然主动监控的内容不仅局限于API成功率,也包括JS错误率等。稍微总结下流程:先是配置告警规则; 然后就可以放心大胆地睡觉了,如有任何风吹草动,系统马上会通知到我们,再通过错误聚类模块,精准地定位问题。再手起刀落,bug修复完成。

再回到我们的【要是什么什么就好了】,在做性能优化的时候,有时候明明整体性能已经不错了,可偏偏有少量用户觉得很慢:(这时候你就会想)要是能知道慢速用户发生了什么就好了

这时候我们就需要用到【性能样本分布】,打开页面性能页面,查看0 -60秒之间每个区间的性能样本分布情况,从分布图中可以看出来大部分用户加载时间都在2秒以内,极少数部分用户的页面时间在10秒左右的
拖动下面的滑块,缩小时间范围到10S左右,这时候系统就会筛选出10秒左右的慢会话
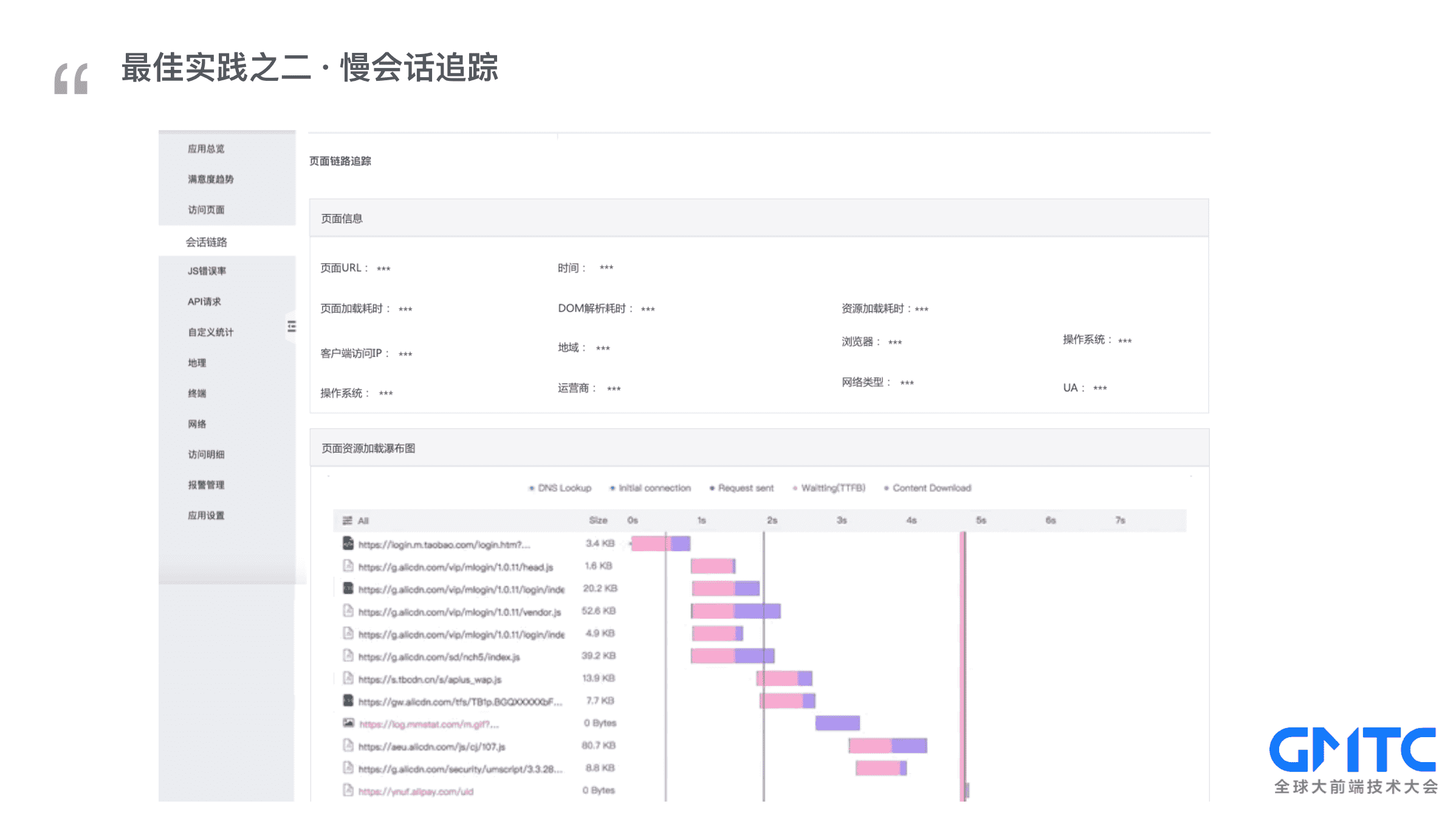
点击展开某次慢会话,不仅可以看到这次慢会话的基本信息,比如网络类型等,还可以看到完整的资源加载瀑布图,可以清晰地看出来,具体是什么资源导致整个会话变慢。由此我们又可以得出最佳实践之二:慢会话追踪

再回到我们的【要是什么什么就好了】,有时候用户提交了一条反馈,某某功能出错用不了,这时候你又不知道用户端到底报了什么错,是不是又得打电话给用户,还得手把手教用户如何通过浏览器开发者工具把错误截图下来发你。我哩个去,用户这个时候很可能因为系统太烂了,已经不堪其辱,早就把页面关了并且发誓再也不用这破系统。(这时候你就会想)要是能知道用户报了什么错就好了
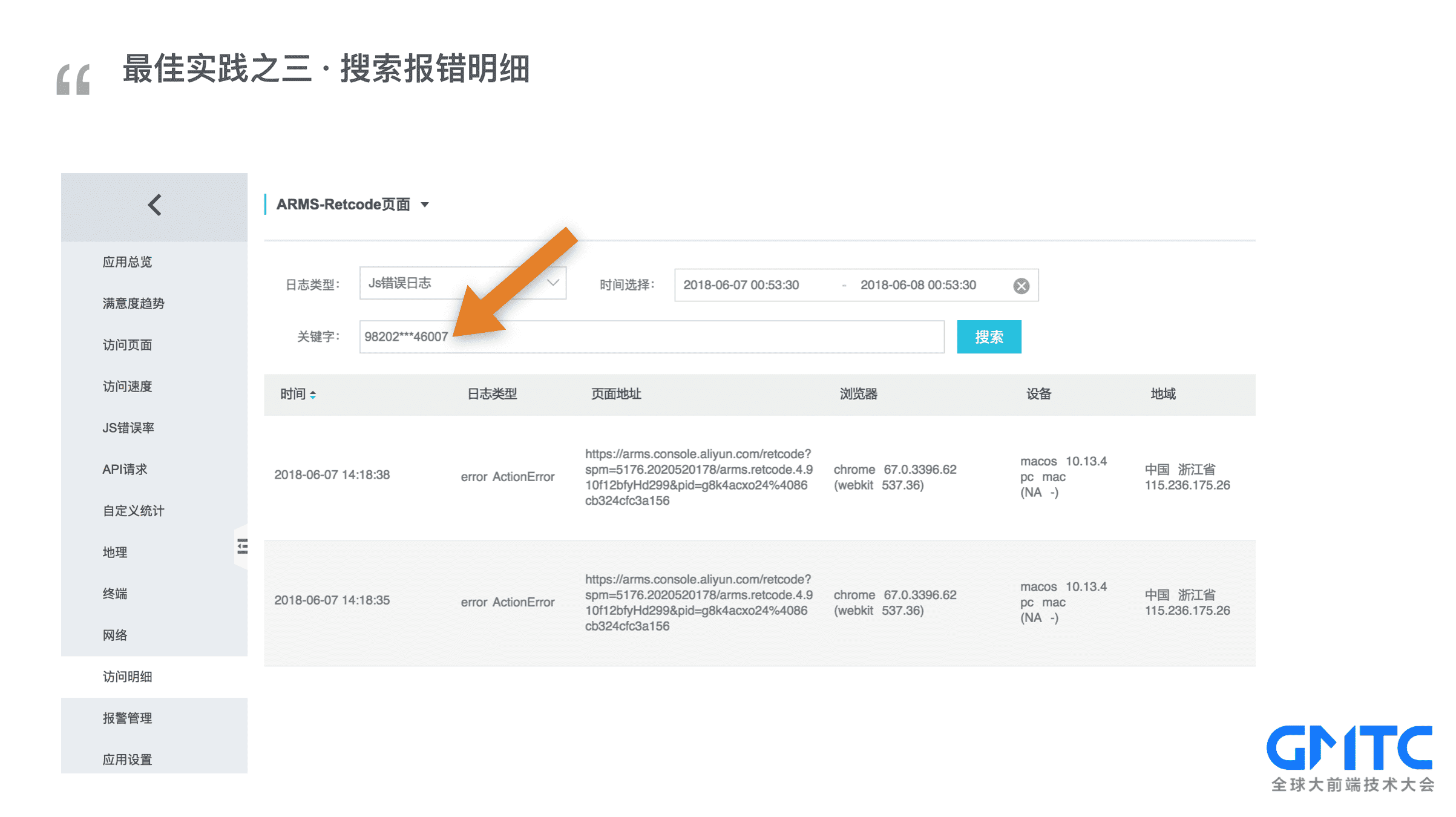
别怕,打开阿里云前端监控的【访问明细】搜索用户ID,直接可以看到该用户在访问过程中,到底报了什么错。

有时候拿到了用户报错时的基本信息,也知道用户报了什么错,但是在自己电脑上调试的时候,无论如何也复现不了,这个时候是不是又得去和用户沟通,让用户描述重现路径,实际上用户可能自己都忘了具体怎么做才能重现错误。(这时候我们就会想)要是能重现用户行为就好了。
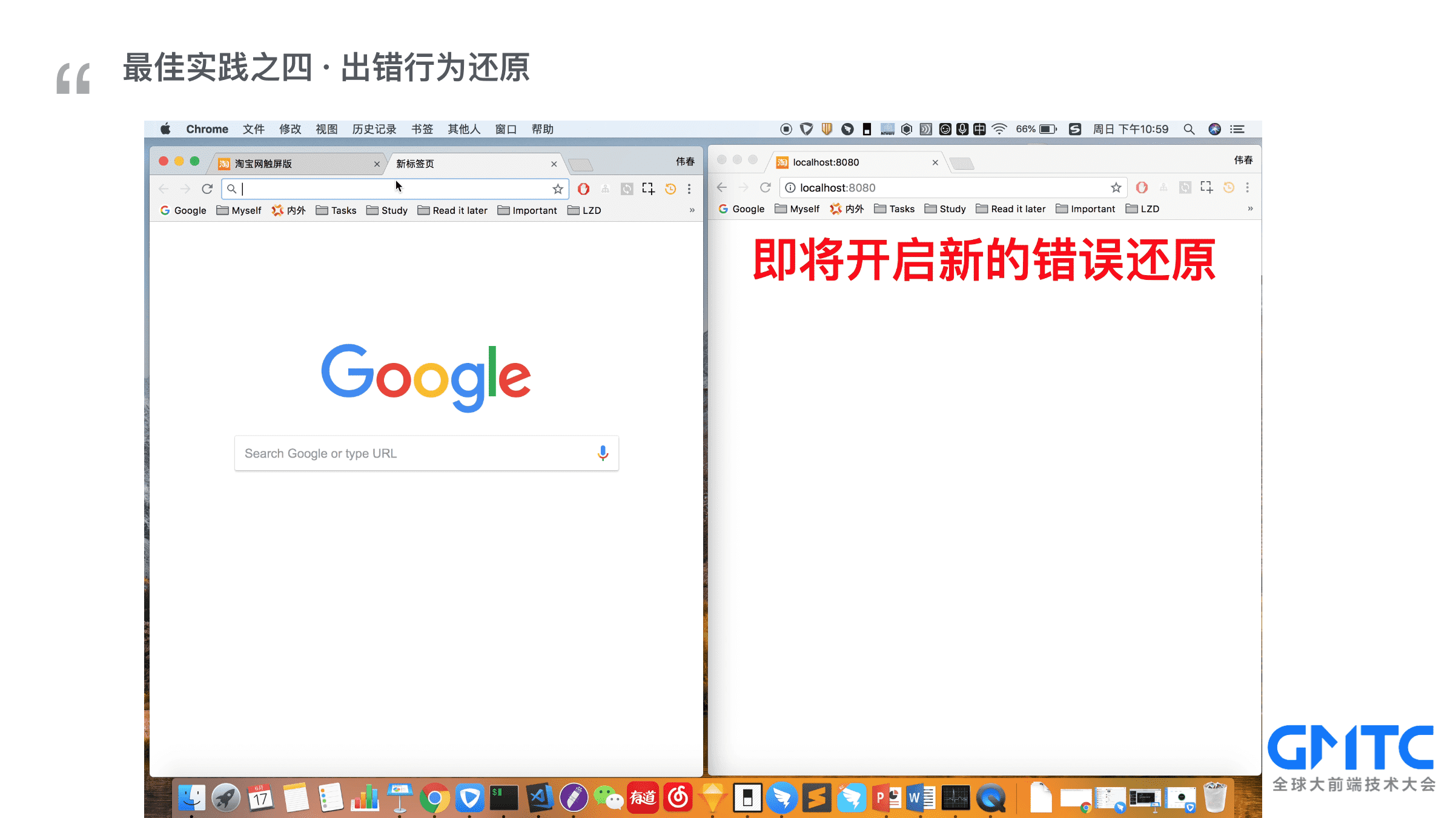
【视频演示】我们现场来模拟一次用户出错还原,左边是用户实际操作的屏幕,为了更好地展示效果,我把用户行为实时地展示在右边的屏幕上
* 第一步: 模拟用户在淘宝页面上做出了一系列的操作, 鼠标移动、滚动页面,搜索等
* 第二步:假设突然出现了某某错误,这时系统会把记录的用户行为存储到服务端
* 第三步: 开发人员通过会话ID查询到出错行为,最终进行还原。大家可以看到左边屏幕不再操作,右边屏幕还原出了之前出错的所有行为。

大家一定在想这么炫酷的能力是如何实现的呢?接下来就为大家揭秘阿里云前端监控系统背后的技术架构。
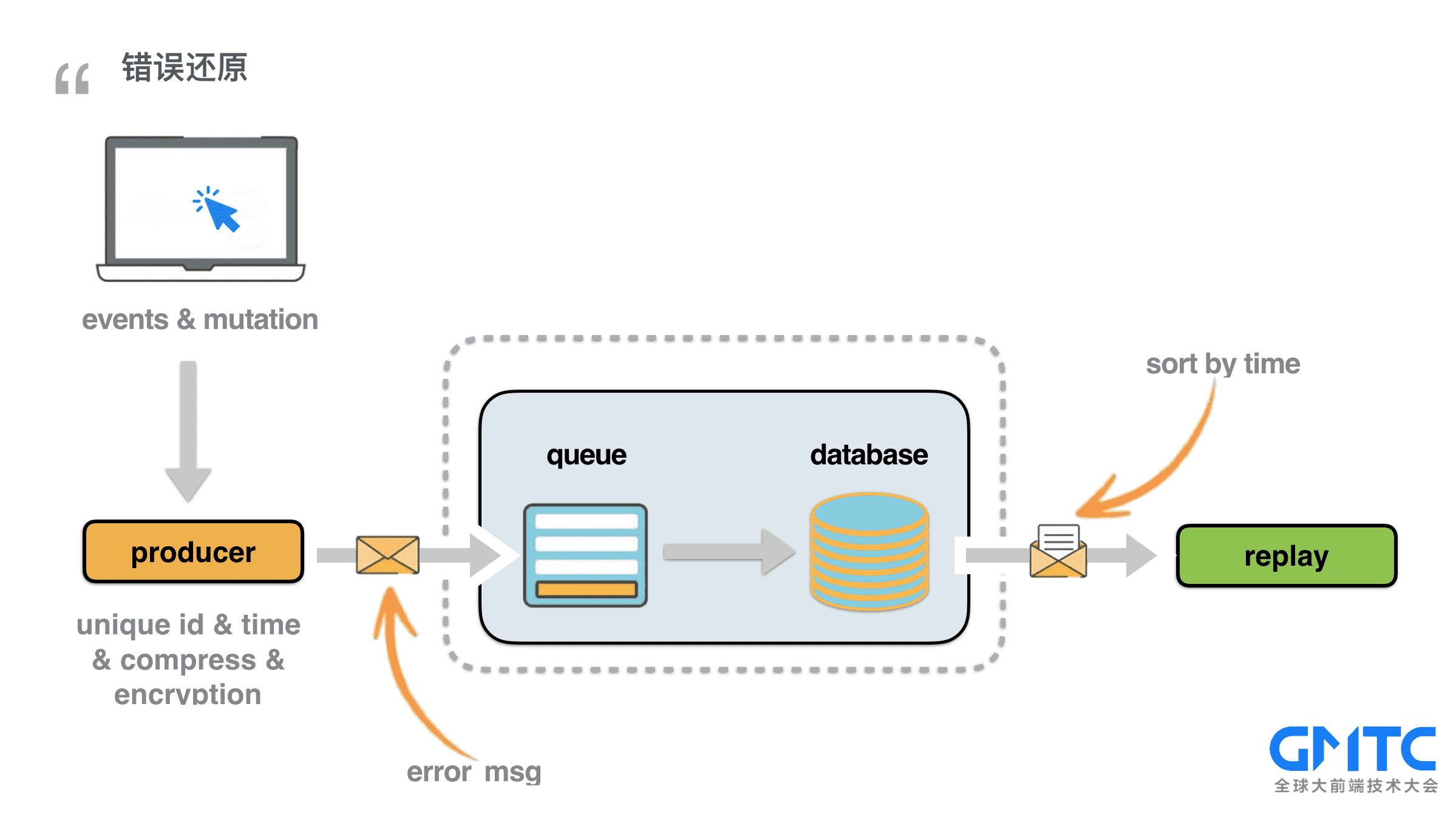
就从大家最感兴趣的错误还原讲起,大家可能在猜测,是不是把整个页面录制成视频了。其实不是这样的,视频太大了,不可能出错了把一个视频发到服务端,这样是对用户资源的严重浪费。先看示意图(跟着箭头从左到右)
* 首先,每一次会话都有一个唯一的session ID,这是串联起所有行为的纽带。
* 其次,用户行为又分成两个部分,其一是用户的操作,比如鼠标滑动,点击,页面滚动等,其二是页面的变化。这两者我们都统称为用户行为,记录在同一个队列中。
* 一开始的时候,系统会记录下初始的页面作为第一帧,这是唯一的一次完整页面记录。
* 针对用户操作,我们会记录事件的类型,鼠标位置等关键信息,保存到队列中。
* 针对页面变动,我们会起一个mutationObserve侦听页面的改动,每次只记录改动的部分,保存到队列中。
* 无论是事件还是页面改动,都是对等的一帧,每一帧都会有当前时间,与上一帧间隔时间等基本信息用户还原。
* 一旦出错,SDK就把队列发送到监控系统,并清空当前队列。
* 还原端根据记录的行为队列,根据时间逐一播放出来。最终形成一个类似于视频的效果。
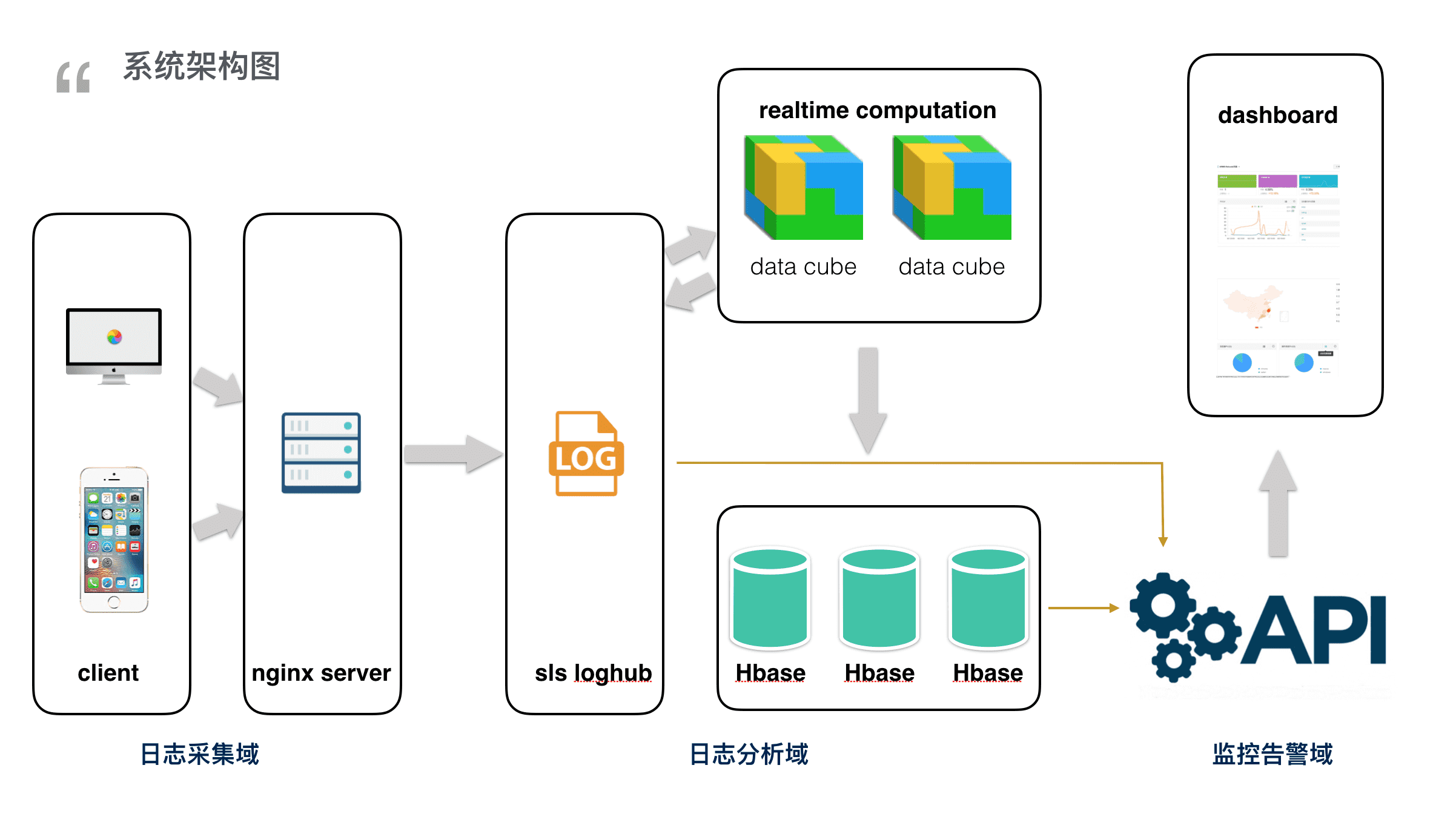
大家可能觉得还不过瘾,接下来为大家讲一下阿里云ARMS前端监控系统的整体架构。
首先从左到右分成三个域。分别是日志采集域,日志分析域和监控告警域。在日志采集域,客户端通过SDK将信息上报到Nginx服务器, 日志服务SLS在Nginx服务器上起一个agent,去把日志信息同步过去,日志到了SLS就相当于到了一个大的蓄水池。再通过实时计算引擎的计算,结果部分存储到HBase,另一部分结果回存到SLS日志服务用于搜索。
最终通过restful API向前端提供数据,前端渲染出数据dashboard.
是不是感觉很简单地样子,有句话叫做【看山跑死马】,山看起来就在眼前, 可就算骑马过去马都会累死。那就让我们一起来揭开它的神秘面纱吧。

接下来重点介绍跟前端同学工作密切相关的日志采集域,相比业界,我们的日志采集还是有很多可圈可点之处的。比如说:
* 静默采集: 只需要一行代码接入SDK就行了,所有的API请求、资源加载、JS错误、性能等都自动监控起来了。省去了繁琐的配置。
* 单元测试 + 自动化测试:前端监控的目的就是去监控前端的异常情况,不给页面带来新的异常这是我们的底线,对此,我们有完善的单元测试和自动化测试去保障SDK本身的质量。
* (SDK出错隔离):但实际上任何系统都不能保证自己不会出错,那么万一SDK本身报错了,我们还有异常隔离机制,确保出错也不会影响业务的运行。

这些内容我都不详细展开,那接下来我重点讲一下,阿里云前端监控是如何突破局限优雅地上报日志
大家都知道,http徵求意見稿rfc2616规定浏览器对于一个域名,同时只能有 2 个连接。而PV、UV、ajax请求、JS逻辑错误、页面资源加载等等都会触发上报,同时2个连接明显不够用,可能会造成网络阻塞,上报延迟
后来在修正稿rfc7230中去掉了这个限制, 只规定了限制数量,但并未指定具体数字,浏览器也实际放宽了限制。比如Chrome是同时6个连接。
然而,一个请求独占一个连接,有时候6个连接也是不够用的
大家可能会想, 那既然规范都没有指定要限制多少条,那浏览器为什么还要限制6条呢?其实也是出于公平和安全考虑,如果不限制数量,理论上一个客户端就能占用大量服务器资源,甚至压垮服务器。
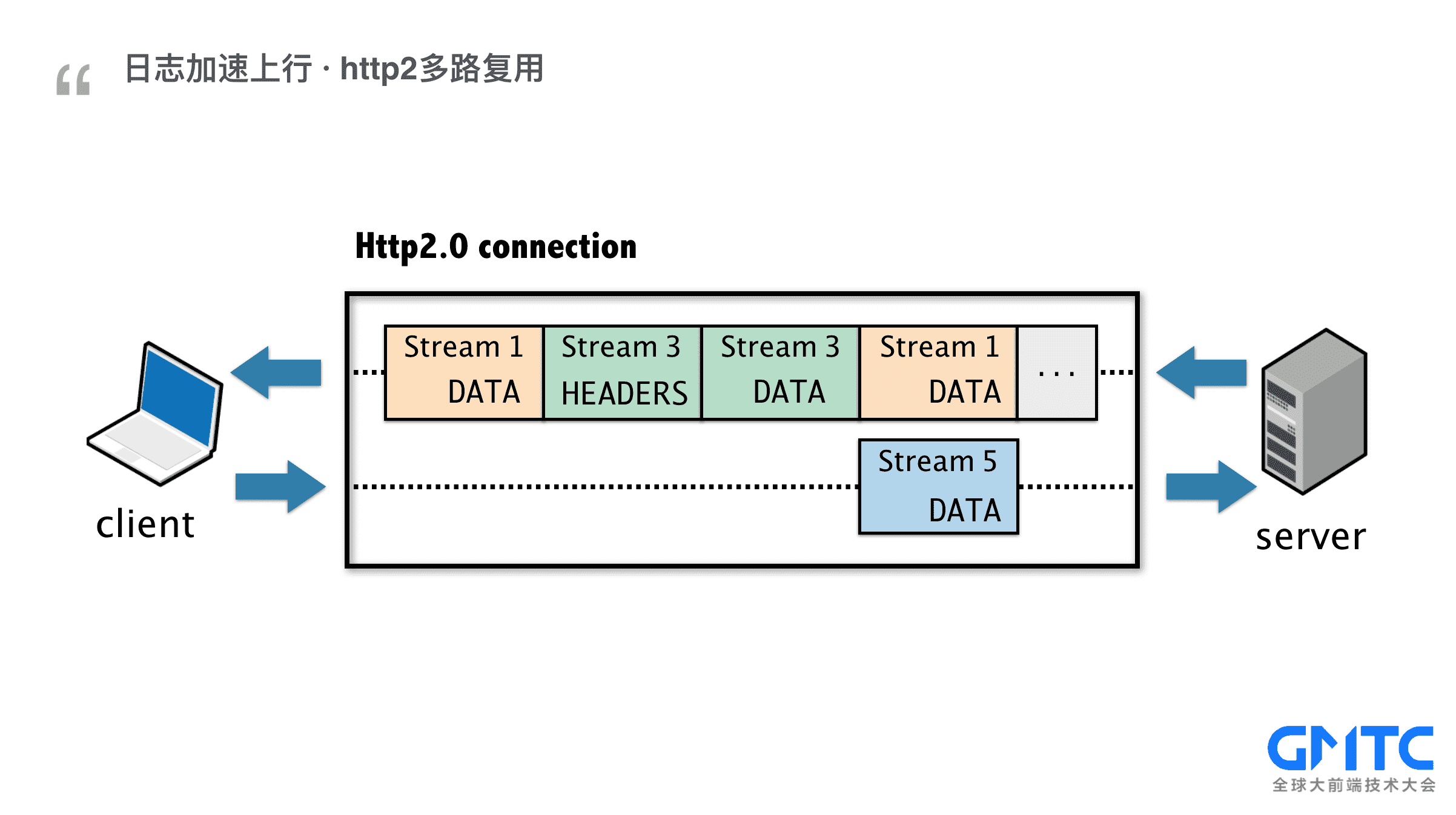
那如何突破限制呢?有一个绝招:就是升级到http2, 利用h2的多路复用特性
一个连接上打开多个流,还可以双向数据传输,轻松突破6路并行限制。
* 思考一下:在http1时代的把资源散列在不同域名下还有效吗?实际上非但不能提升性能,反而会新增连接开销。

突破6路限制就够了吗?我们再来看看另一个很容易被忽略的部分:http头部损耗。
* http请求中,每次请求都会包含一系列的请求头来描述请求的资源和特性等。而头部没经过任何压缩,每次请求都要占用200-800个字节,如果带上一个比较大的cookie,甚至会超过1K,
* 而我们实际的日志数据大小仅仅只有10 - 50字节,头部消耗占了90%以上
* 另外,据Htpp Archive统计数据,平均每个页面上百个请求,越来越多的流量消耗在头部
* 最致命的是,UserAgent等信息不会频繁变动,每次请求都传输是一种严重的浪费。
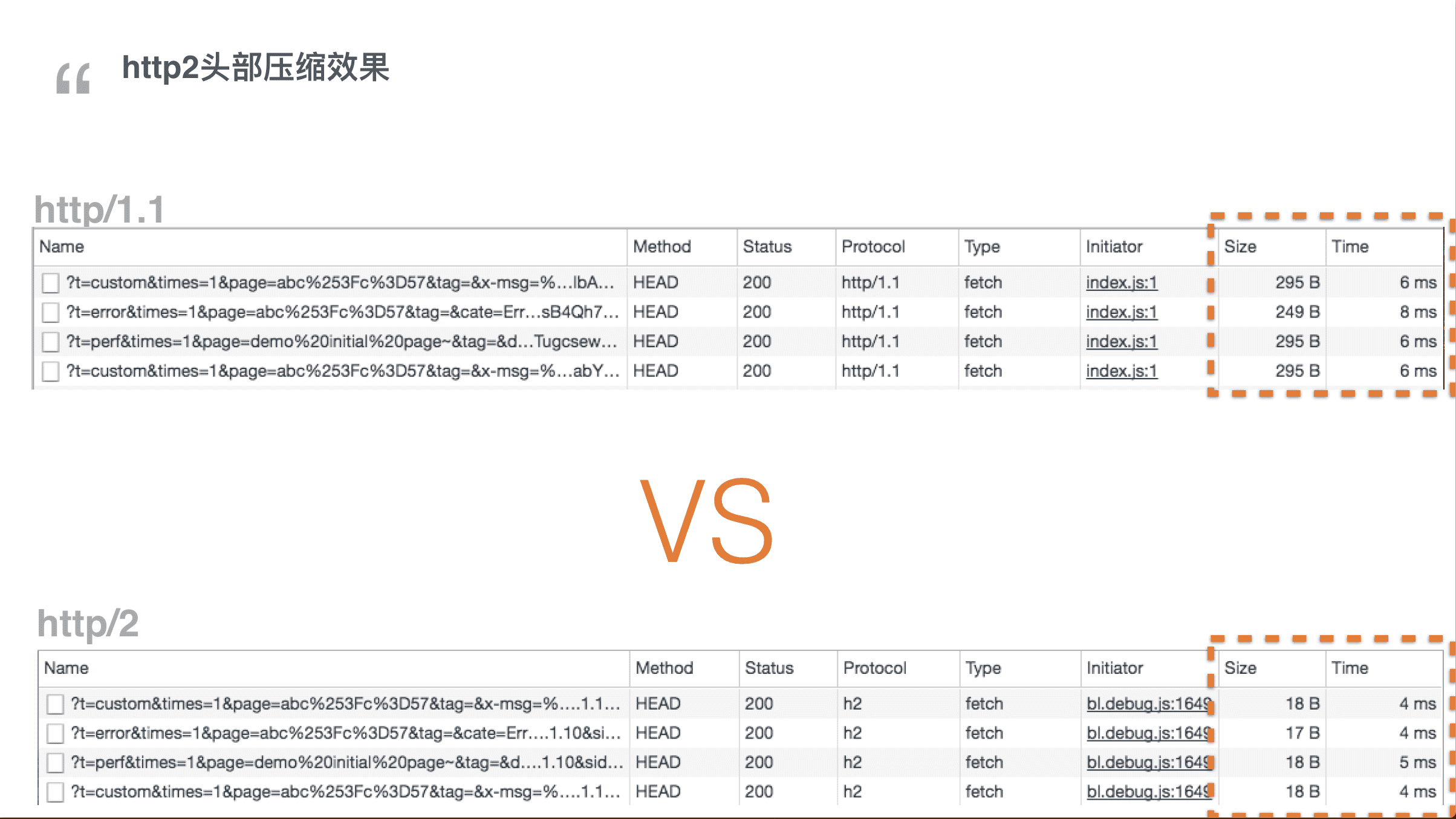
再次利用h2头部压缩。先来看看采用h1和h2的效果对比。
h1下请求大小295 字节, 而h2仅仅只有18 字节,大小只有区区16分之一,请求时间也从6ms降低到了4毫秒。
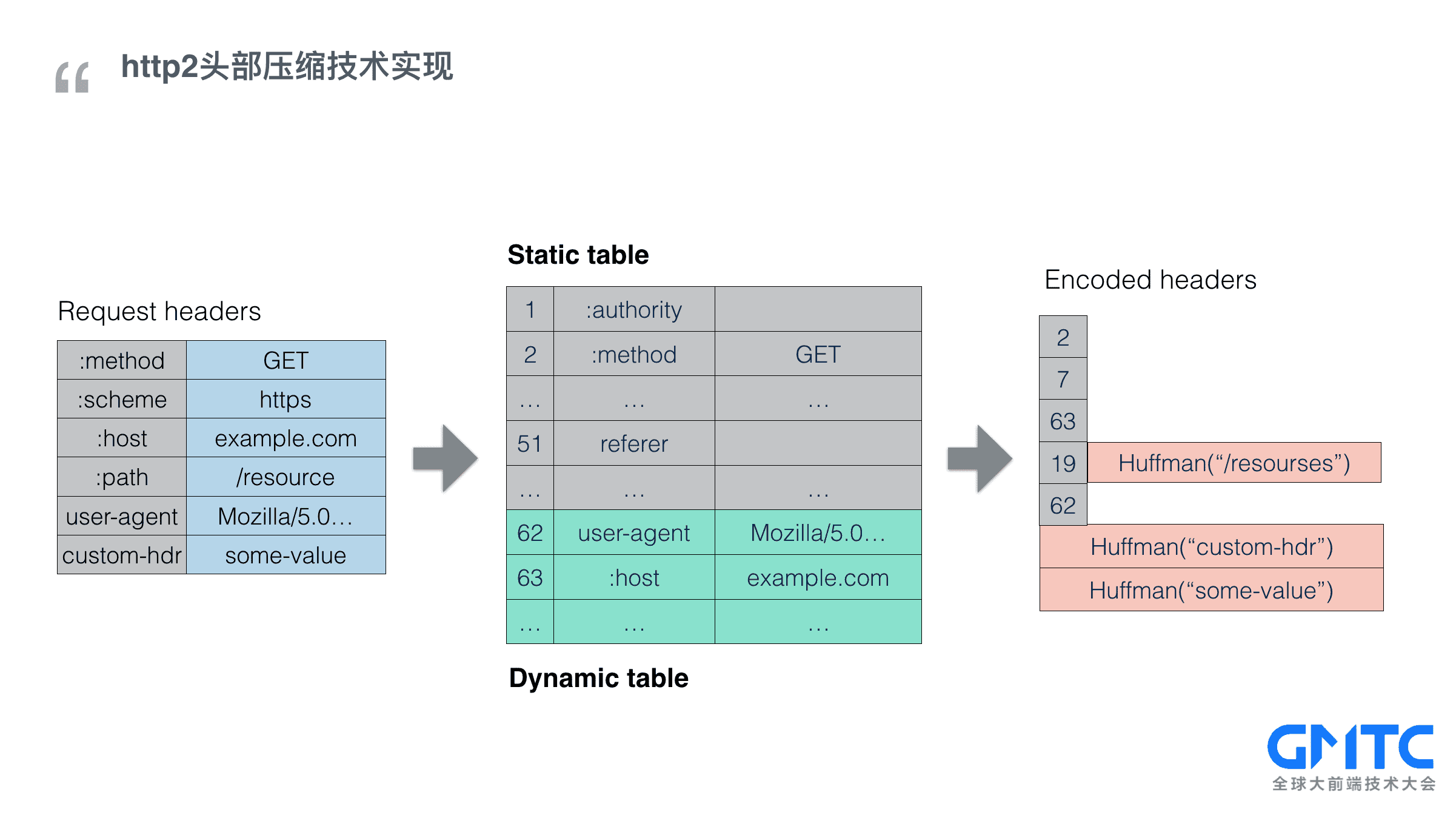
太神奇了,来快速地过一下http2头部压缩是如何实现的:
* 首先协议里预设了一个静态字典,用来表示常用的头部字段,比如图中,2就是 method get. 以前需要把完整的key-value对发过去,现在只需要把一个数字发过去,大小大幅缩小。
* 其次,客户端和服务端会共同维护一个动态表,动态表用来干啥呢?举个例子,比如useragent, 每个用户的useragent值是不一样的,没法放到静态表中去约定。但是对于同一个用户会话,useragent是不会改变,这样的值,就由客户端和服务端协商决定存入动态表,这样第一次传输过去之后,以后就只需要传入动态表中的一个编码就行了,图中的62和63就是这样的情况。连接中发送的请求越多,就越能丰富动态表中的值,越到后面,请求性能越好(佐证了域名散列的方式不可取)
* 还有一类情况,值总是变来变去,也没法保存到动态表中。这时候,只能直接压缩了。在h2中采用的是Huffman压缩算法,能把数字或字符最短压缩到5个字节,最大压缩率是37.5%

其实除了头部压缩外,还有很多办法减少体积,比如
* 采用http 204返回无响应体的response
* 采用post请求合并多条日志,共用请求头
* 错误调用堆栈中经常会出现很多的文件url,占了不少空间,可以考虑将他们抽取成一个变量
时间关系,日志采集部分就到此为止。
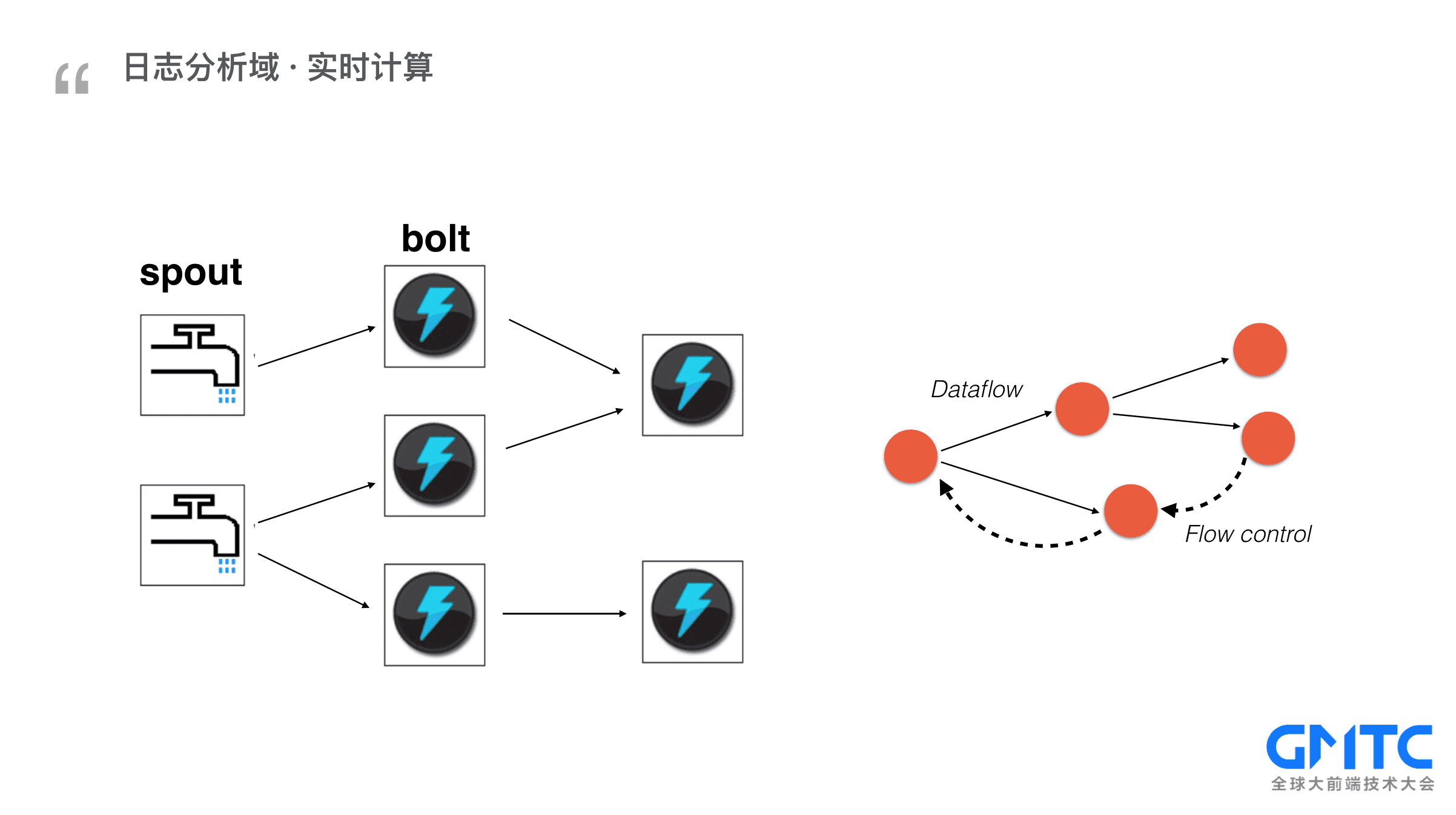
接下来我们来看看一个监控系统最核心的部分:实时计算。
实时计算采用的是业界已经非常成熟的流计算,简单地过一下概念。
这是一张表示流计算的经典结构图,有两种组件,水龙头是spout,代表数据源, 闪电是bolt, 代表处理逻辑。这里面有两个很重要的特征。
* 其一是计算能力弹性,如果有更大的日志量流入,能够动态调度更多的算力来保障计算的实时性
* 其二是反压。每个计算节点都可以根据自己的负载情况反压上一级的计算节点,从而实现计算任务的更合理地分配。
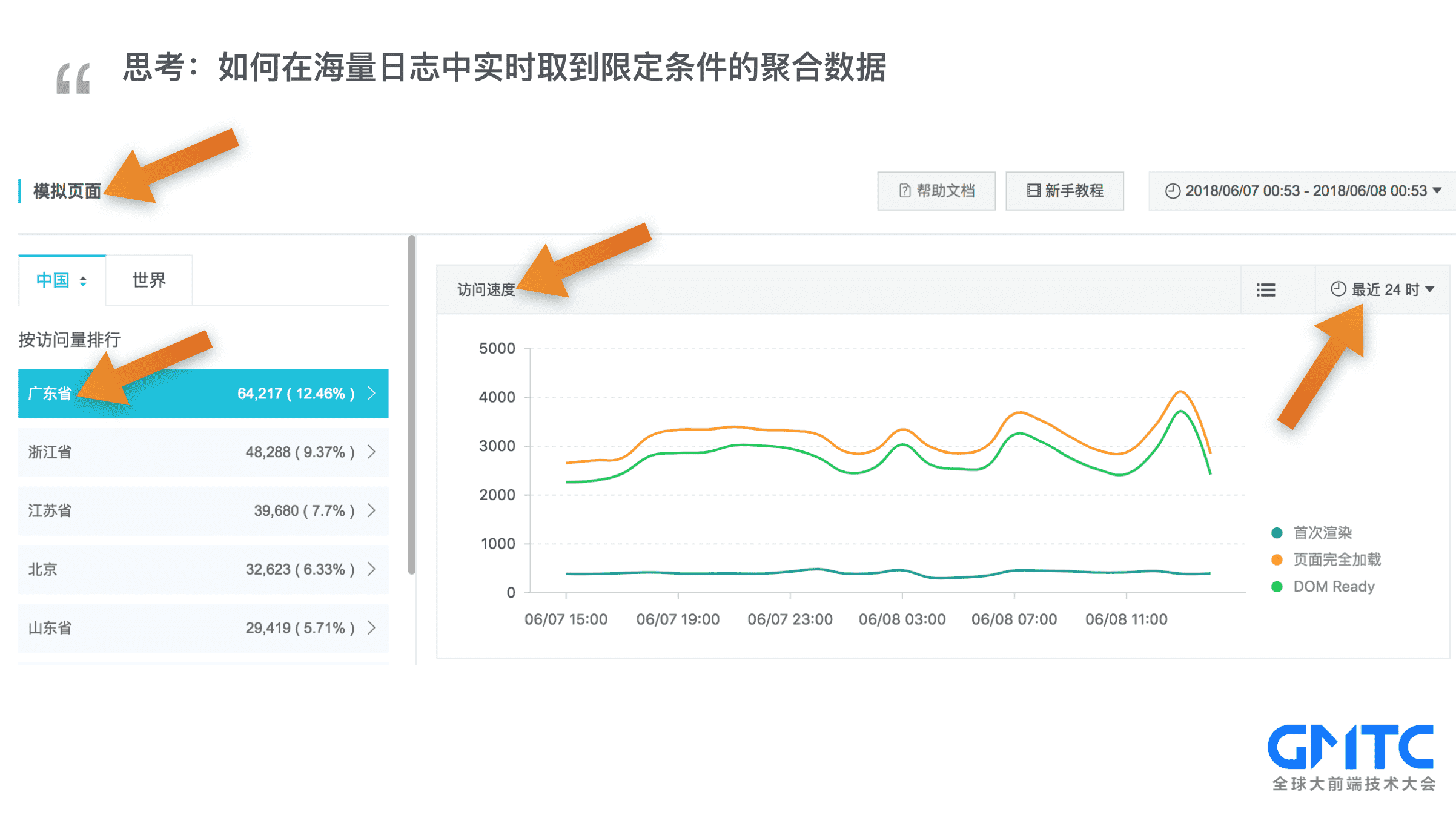
思考一下:如何在海量日志中实时取到限定条件的聚合数据?如图所示,我想实时拿到【模拟页面】在【广东省】【最近24小时】【访问速度】走势
分析一下,如果需要画出这样的走势图,每个小时画一个点,需要取24个点的值,每个节点写个SQL把符合条件的数据求平均,
如果数据量很小的时候,取24次数据勉强性能上勉强可以忍受。
但是如果作为一个SASS系统,监控系统会接入非常多的项目,每时每刻都有大量的数据上报。系统也会积累海量的数据。取一个节点需要多少时间呢?参考离线计算大概要15分钟, 24个节点,预估需要6个小时。这明显是不可接受的。那阿里云前端监控是如何做到实时拿数据的呢?
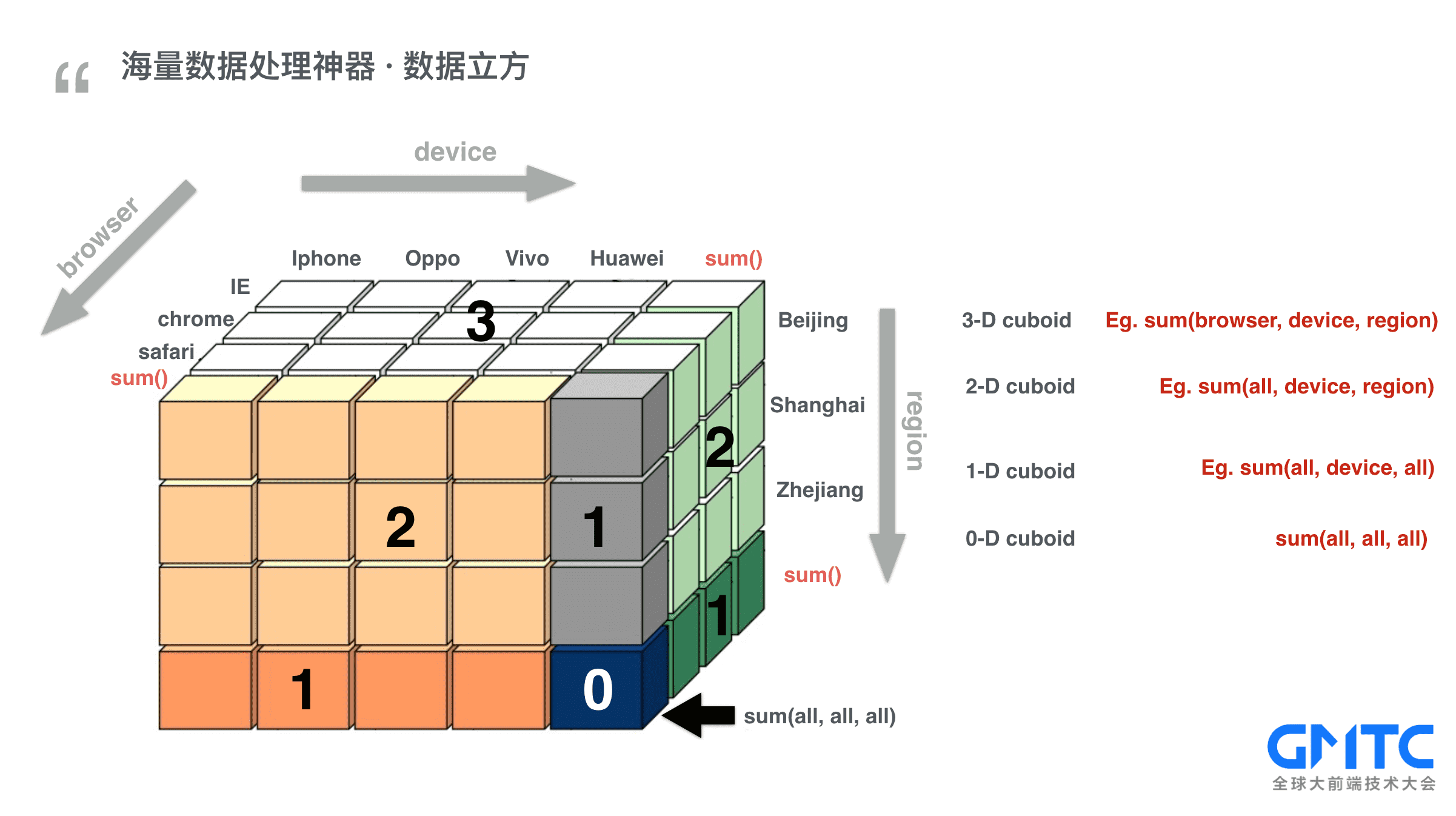
这就需要用到我们的大数据处理神器dataCube(数据立方),我们来剖析下数据立方是如何解决实时性的问题的。
如图所示: 拿浏览器、设备、地理区域三个维度为例,组成一个三维的数据立方。立方中的每个小格子代表一个聚合数据。
请看图中数字3所在的格子,3代表三维,也就是Vivo设备、chrome浏览器在北京地区的聚合量
再看一个黄色切面上的数字2,黄色切面代表浏览器维度的聚合,也就是上海地区Vivo设备的聚合量,包括所有的浏览器。
再看最右下角的数字0代表0维,也就是所有的聚合量,包括所有的浏览器、所有的设备、所有的地区。
数据立方的秘密就是把所有格子的值都预先计算出来,下次要取值,直接取数据立方的某个值就好了,本质上是一种空间换时间的思路。

看一个我们实际的处理场景,元数据经过流计算之后,每分钟、每小时、每天都会产生一个数据立方。而这个数据立方多达90多维。回到之前的案例,如果我想限定若干个条件拿到24小时趋势图,我只需要24个数据立方中把指定位置的小格子取出来就行了。计算时间就能大幅压缩到秒级别。
【思考案例】数据立方本质上是把所有可能的组合提前算出结果,结果数量是一个笛卡尔积,如果某个维度的值非常多(比如淘宝商品详情url中product id不断变化, 导致url的值就有上千万个), 直接导致维度爆炸, 该如何解?
由于时间限制,今天的主题就到此为止。有兴趣的同学可以加我们的技术交流群,谢谢大家。
本文来自阿里云前端监控团队,转载请注明出处
