

前言
虽然前端面试中很少会考到算法类的题目,但是你去大厂面试的时候就知道了,对基本算法的掌握对于从事计算机科学技术的我们来说,还是必不可少的,每天花上 10 分钟,了解一下基本算法概念以及前端的实现方式。
另外,掌握了一些基本的算法实现,对于我们日常开发来说,也是如虎添翼,能让我们的 js 业务逻辑更趋高效和流畅。
算法介绍
希尔排序,也称递减增量排序算法,是插入排序的一种更高效的改进版本。希尔排序是非稳定排序算法。——维基百科
希尔排序是 D.L.Shell 于 1959 年提出来的一种排序算法,在这之前排序算法的时间复杂度基本都是 O(n²),希尔排序算法是突破该事件复杂度的第一批算法之一。
科学家希尔研究出来的这种排序方法,对直接插入排序改进后可以增加效率。
算法阐释
上一节我们讲到的「直接插入排序」,它的效率在数组本身就是基本有序以及元素个数较少时,它的效率是很高的。但问题就是,这两个条件本身就很苛刻。如何让程序争取实现这俩条件呢?答案就是讲原本有大量元素的数组进行分组,分隔成若干子数组,这样每个子数组的待排序的元素个数就比较少了,然后在子数组内分别进行「直接插入排序」,当整个数组基本有序时,再对全体元素进行一次「直接插入排序」。
所谓基本有序,就是小的元素基本在前面,大的基本在后面,不大不小的基本在中间。要注意像 [2, 1, 3, 6, 4, 7, 5, 8, 9] 这样的可以称为基本有序,但 [1, 5, 9, 3, 7, 8, 2, 4, 6] 这样的就谈不上了。
因此我们在分割子数组时,需要采取跳跃分割的策略:将相距某个增量的记录组成一个子数组,这样才能保证在子数组内分别进行直接插入排序后的得到的结果是基本有序,而不是局部有序。
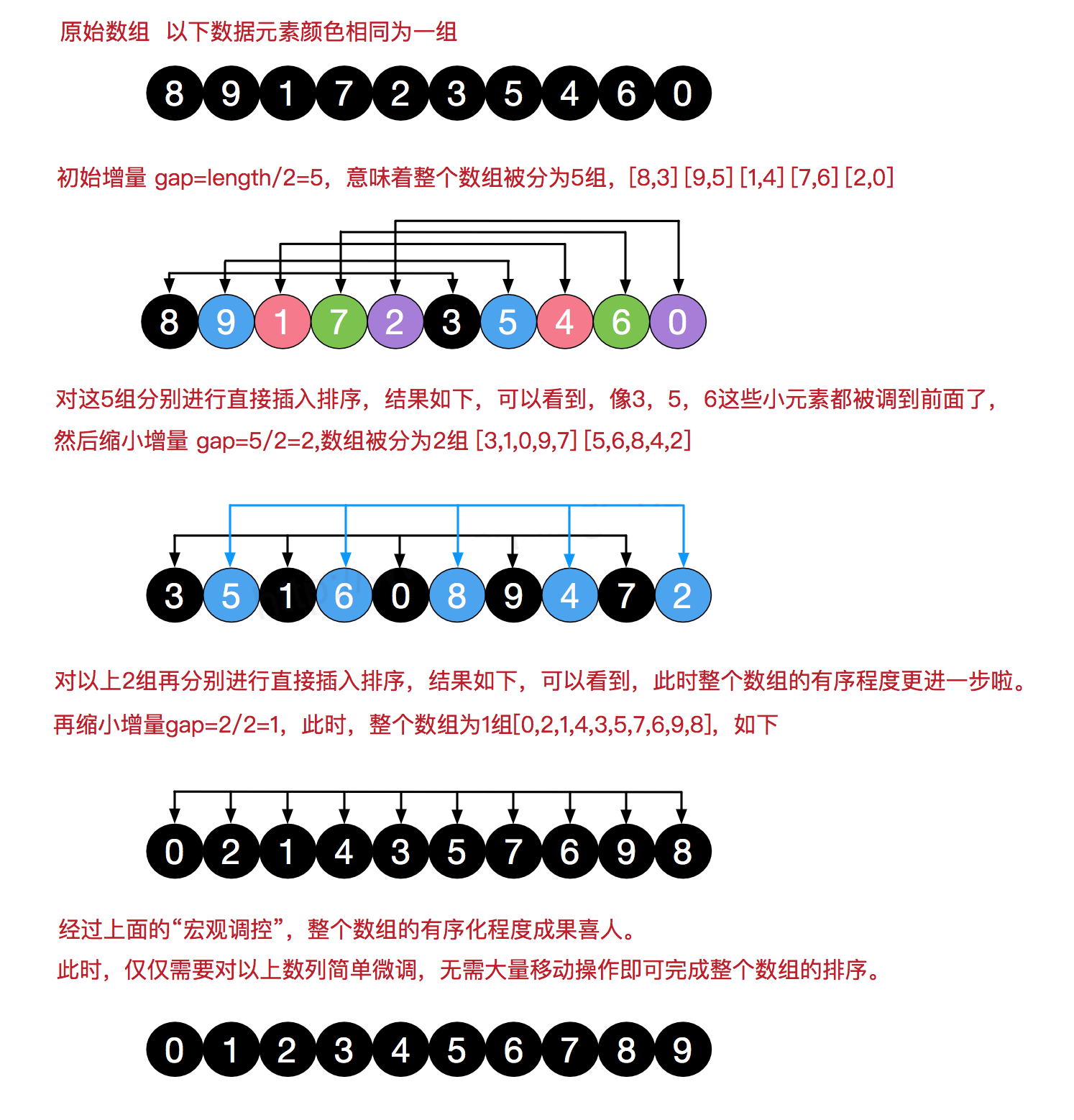
举例说明
这个算法无论怎么解释都会显得含糊不清,直接来个栗子,就拿上图来说明。
假设现在有一数组 arr:[8, 9, 1, 7, 2, 3, 5, 4, 6, 0],我们设定初始化步长为 gap = arr.length/2 = 10/2,即 5。按照我们上面说的「跳跃分割策略」,按增量为 5 分割子数组,将每列看成是一个子数组:
// 列1 列2 列3 列4 列5
8 9 1 7 2
3 5 4 6 0
然后对每列进行类直接插入排序,可得:
// 列1 列2 列3 列4 列5
3 5 1 6 0
8 9 4 7 2
则此时原数组顺序应变成:[3, 5, 1, 6, 0, 8, 9, 4, 7, 2],然后再缩小增量,gap = 5/2 = 2,则数组分割如下:
// 列1 列2
3 5
1 6
0 8
9 4
7 2
继续对每列进行直接插入排序,可得:
// 列1 列2
0 2
1 4
3 5
7 6
9 8
则此时元素组顺序应变成:[0, 2, 1, 4, 3, 5, 7, 6, 9, 8],这就是基本有序了。最后一轮再进行微调即可,所以此时增量应计算得为:gap = 2/2 = 1,则直接对数组应用直接插入排序即可,最后得到:
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
具体实现
var shell_sort = function(arr){
var i, j, temp, gap;
var len = arr.length;
// 逐步缩小增量
for (gap=len>>1; gap>=1; gap>>=1) {
// 类直接插入排序算法
for (i=gap; i<len; i++) {
if (arr[i] < arr[i-gap]) {
temp = arr[i];
for (j=i-gap; j>=0 && temp<arr[j]; j-=gap) {
// 记录后裔,查找插入位置
arr[j+gap] = arr[j];
}
// 插入
arr[j+gap] = temp;
}
}
}
return arr;
};
shell_sort([8, 9, 1, 7, 2, 3, 5, 4, 6, 0]);
不晓得大家有没有观察到,第一层循环里面的两层嵌套循环算法,其实就是「直接插入排序」,不同就在于多了一个变量 gap,但其实当 gap === 1 时,那就跟我们上一节学到的算法,是完全一样的。
算法实现总结
通过以上代码的剖析,大家可以看到,希尔排序的关键不是简单地按 1 为增量进行分组排序后,再合并整体排序;而是选好一个初始化增量,不断地递减增量,每次递减之间都需要经过一次直接插入排序,使得排序的效率提高。
另外只要最终增量为 1,则任何增量序列都可以工作,因为最终当增量为 1 时,算法就变为「直接插入排序」,这就保证了数据一定会被排序。
复杂度分析
Donald Shell最初建议步长选择为
n/2并且对步长取半直到步长达到1。虽然这样取可以比O(n²)类的算法(插入排序)更好,但这样仍然有减少平均时间和最差时间的余地。——维基百科
参考了一下维基百科及相关文章,获得如下结论:
- 希尔排序原始增量序列为
n/(2^i),也就是:n/2, n/4, ..., 1;最坏情况下时间复杂度为O(n²) - Hibbard 提出的增量序列为
2^k-1,也就是:1, 3, 7, ..., 2^k-1;最坏情况下时间复杂度为O(n^(3/2)) - Sedgewick 提出的增量序列为已知的最好增量序列,也就是:1, 5, 19, 41, 109, .... ;该项序列的项来自
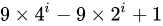 和
和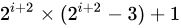
综上所述,希尔排序算法的出现,我们终于突破了慢速排序的时代,也即超越了时间复杂度为 O(n²)。后面的几篇文章,我们还会介绍更为高效的排序算法。
参考链接
faculty.simpson.edu/lydia.sinap…

觉得本文不错的话,分享一下给小伙伴吧~
