

本文为你展示,如何用Python把许多PDF文件的文本内容批量提取出来,并且整理存储到数据框中,以便于后续的数据分析。
问题
最近,读者们在后台的留言,愈发五花八门了。
写了几篇关于自然语言处理的文章后,一种呼声渐强:
老师,pdf中的文本内容,有没有什么方便的方法提取出来呢?
我能体会到读者的心情。
我展示的例子中,文本数据都是直接可以读入数据框工具做处理的。它们可能来自开放数据集合、网站API,或者爬虫。
但是,有的时候,你会遇到需要处理指定格式数据的问题。
例如pdf。
许多的学术论文、研究报告,甚至是资料分享,都采用这种格式发布。
这时候,已经掌握了诸多自然语言分析工具的你,会颇有“拔剑四顾心茫然”的感觉——明明知道如何处理其中的文本信息,但就是隔着一个格式转换的问题,做不来。
怎么办?
办法自然是有的,例如专用工具、在线转换服务网站,甚至还可以手动复制粘贴嘛。
但是,咱们是看重效率的,对不对?
上述办法,有的需要在网上传输大量内容,花费时间较多,而且可能带来安全和隐私问题;有的需要专门花钱购买;有的干脆就不现实。
怎么办?
好消息是,Python就可以帮助你高效、快速地批量提取pdf文本内容,而且和数据整理分析工具无缝衔接,为你后续的分析处理做好基础服务工作。
本文给你详细展示这一过程。
想不想试试?
数据
为了更好地说明流程,我为你准备好了一个压缩包。
里面包括本教程的代码,以及我们要用到的数据。
请你到 这个网址 下载本教程配套的压缩包。
下载后解压,你会在生成的目录(下称“演示目录”)里面看到以下内容。
演示目录里面包含:
- Pipfile: pipenv 配置文件,用来准备咱们变成需要用到的依赖包。后文会讲解使用方法;
pdf_extractor.py: 利用pdfminer.six编写的辅助函数。有了它你就可以直接调用pdfminer提供的pdf文本内容抽取功能,而不必考虑一大堆恼人的参数;demo.ipynb: 已经为你写好的本教程 Python 源代码 (Jupyter Notebook格式)。
另外,演示目录中还包括了2个文件夹。
这两个文件夹里面,都是中文pdf文件,用来给你展示pdf内容抽取。它们都是我几年前发表的中文核心期刊论文。
这里做2点说明:
- 使用我自己的论文做示例,是因为我怕用别人的论文做文本抽取,会与论文作者及数据库运营商之间有知识产权的纠纷;
- 分成2个文件夹,是为了向你展示添加新的pdf文件时,抽取工具会如何处理。
pdf文件夹内容如下:
newpdf文件夹内容如下:
数据准备好了,下面我们来部署代码运行环境。
环境
要安装Python,比较省事的办法是装Anaconda套装。
请到 这个网址 下载Anaconda的最新版本。
请选择左侧的 Python 3.6 版本下载安装。
如果你需要具体的步骤指导,或者想知道Windows平台如何安装并运行Anaconda命令,请参考我为你准备的 视频教程 。
安装好Anaconda之后,打开终端,用cd命令进入演示目录。
如果你不了解具体使用方法,也可以参考 视频教程 。
我们需要安装一些环境依赖包。
首先执行:
pip install pipenv
这里安装的,是一个优秀的 Python 软件包管理工具 pipenv 。 安装后,请执行:
pipenv install --skip-lock
pipenv 工具会依照Pipfile,自动为我们安装所需要的全部依赖软件包。
终端里面会有进度条,提示所需安装软件数量和实际进度。
装好后,根据提示我们执行:
pipenv shell
这样,我们就进入本教程专属的虚拟运行环境了。
注意一定要执行下面这句:
python -m ipykernel install --user --name=py36
只有这样,当前的Python环境才会作为核心(kernel)在系统中注册,并且命名为py36。
此处请确认你的电脑上已经安装了 Google Chrome 浏览器。
我们执行:
jupyter notebook
默认浏览器(Google Chrome)会开启,并启动 Jupyter 笔记本界面:
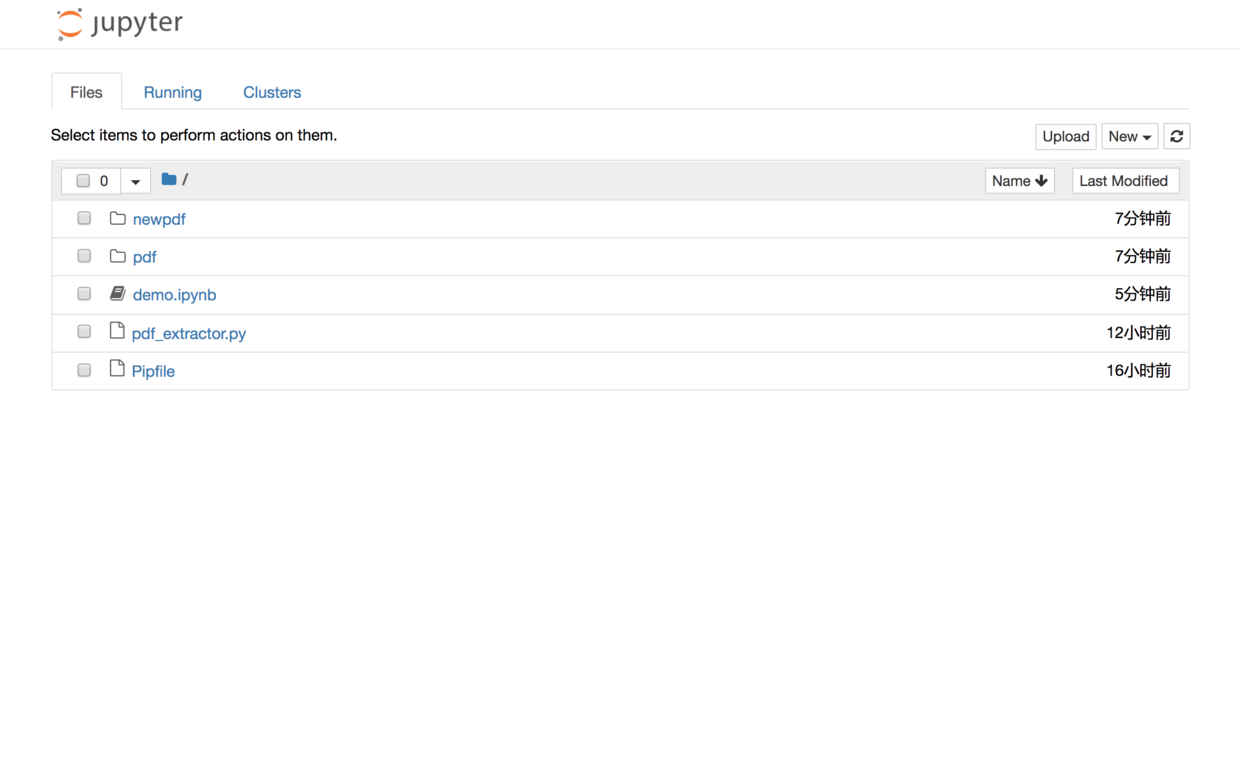
你可以直接点击文件列表中的第一项ipynb文件,可以看到本教程的全部示例代码。
你可以一边看教程的讲解,一边依次执行这些代码。
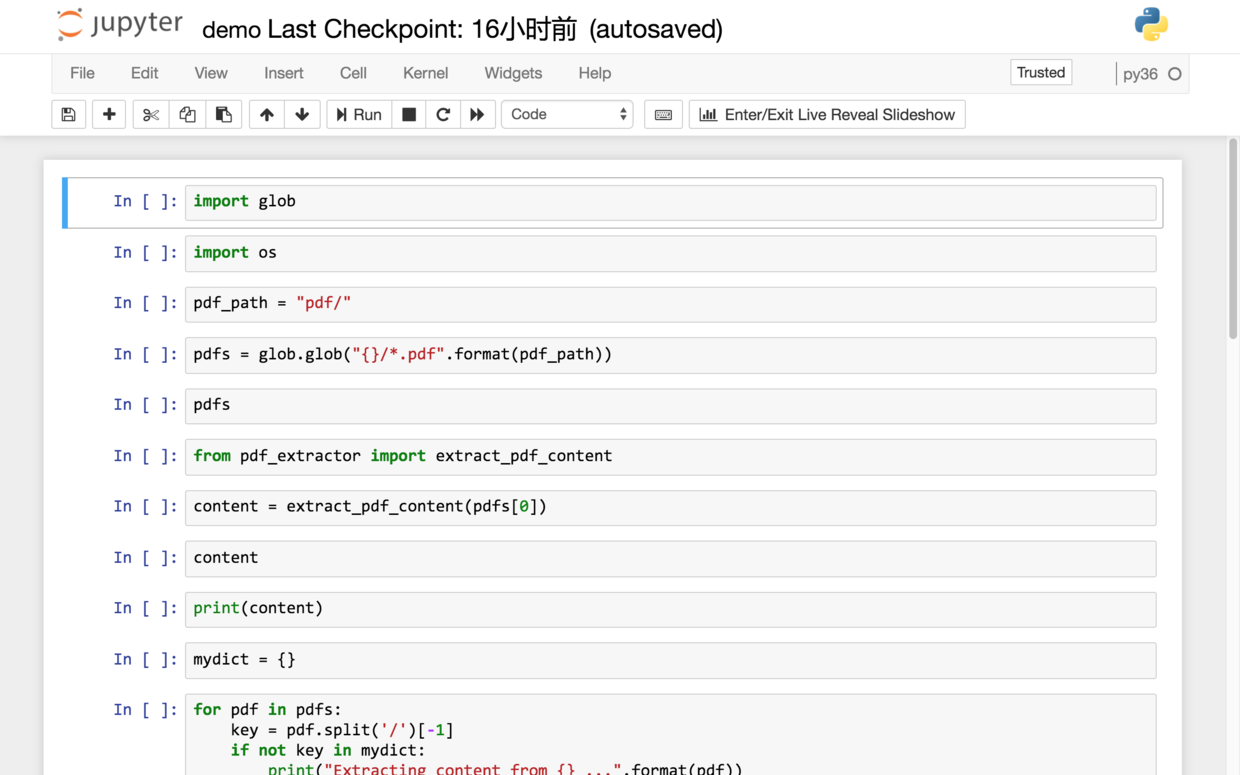
但是,我建议的方法,是回到主界面下,新建一个新的空白 Python 3 笔记本(显示名称为 py36 的那个)。
请跟着教程,一个个字符输入相应的内容。这可以帮助你更为深刻地理解代码的含义,更高效地把技能内化。
当你在编写代码中遇到困难的时候,可以返回参照 demo.ipynb 文件。
准备工作结束,下面我们开始正式输入代码。
代码
首先,我们读入一些模块,以进行文件操作。
import glob
import os
前文提到过,演示目录下,有两个文件夹,分别是pdf和newpdf。
我们指定 pdf 文件所在路径为其中的pdf文件夹。
pdf_path = "pdf/"
我们希望获得所有 pdf 文件的路径。用glob,一条命令就能完成这个功能。
pdfs = glob.glob("{}/*.pdf".format(pdf_path))
看看我们获得的 pdf 文件路径是否正确。
pdfs
['pdf/复杂系统仿真的微博客虚假信息扩散模型研究.pdf',
'pdf/面向影子分析的社交媒体竞争情报搜集.pdf',
'pdf/面向人机协同的移动互联网政务门户探析.pdf']
经验证。准确无误。
下面我们利用 pdfminer 来从 pdf 文件中抽取内容。我们需要从辅助 Python 文件 pdf_extractor.py 中读入函数 extract_pdf_content。
from pdf_extractor import extract_pdf_content
用这个函数,我们尝试从 pdf 文件列表中的第一篇里,抽取内容,并且把文本保存在 content 变量里。
content = extract_pdf_content(pdfs[0])
我们看看 content 里都有什么:
content

显然,内容抽取并不完美,页眉页脚等信息都混了进来。
不过,对于我们的许多文本分析用途来说,这无关紧要。
你会看到 content 的内容里面有许多的 \n,这是什么呢?
我们用 print 函数,来显示 content 的内容。
print(content)

可以清楚看到,那些 \n 是换行符。
通过一个 pdf 文件的抽取测试,我们建立了信心。
下面,我们该建立辞典,批量抽取和存储内容了。
mydict = {}
我们遍历 pdfs 列表,把文件名称(不包含目录)作为键值。这样,我们可以很容易看到,哪些pdf文件已经被抽取过了,哪些还没有抽取。
为了让这个过程更为清晰,我们让Python输出正在抽取的 pdf 文件名。
for pdf in pdfs:
key = pdf.split('/')[-1]
if not key in mydict:
print("Extracting content from {} ...".format(pdf))
mydict[key] = extract_pdf_content(pdf)
抽取过程中,你会看到这些输出信息:
Extracting content from pdf/复杂系统仿真的微博客虚假信息扩散模型研究.pdf ...
Extracting content from pdf/面向影子分析的社交媒体竞争情报搜集.pdf ...
Extracting content from pdf/面向人机协同的移动互联网政务门户探析.pdf ...
看看此时字典中的键值都有哪些:
mydict.keys()
dict_keys(['复杂系统仿真的微博客虚假信息扩散模型研究.pdf', '面向影子分析的社交媒体竞争情报搜集.pdf', '面向人机协同的移动互联网政务门户探析.pdf'])
一切正常。
下面我们调用pandas,把字典变成数据框,以利于分析。
import pandas as pd
下面这条语句,就可以把字典转换成数据框了。注意后面的reset_index()把原先字典键值生成的索引也转换成了普通的列。
df = pd.DataFrame.from_dict(mydict, orient='index').reset_index()
然后我们重新命名列,以便于后续使用。
df.columns = ["path", "content"]
此时的数据框内容如下:
df

可以看到,我们的数据框拥有了pdf文件信息和全部文本内容。这样你就可以使用关键词抽取、情感分析、相似度计算等等诸多分析工具了。
篇幅所限,我们这里只用一个字符数量统计的例子来展示基本分析功能。
我们让 Python 帮我们统计抽取内容的长度。
df["length"] = df.content.apply(lambda x: len(x))
此时的数据框内容发生以下变化:
df

多出的一列,就是 pdf 文本内容的字符数量。
为了在 Jupyter Notebook 里面正确展示绘图结果,我们需要使用以下语句:
%matplotlib inline
下面,我们让 Pandas 把字符长度一列的信息用柱状图标示出来。为了显示的美观,我们设置了图片的长宽比例,并且把对应的pdf文件名称以倾斜45度来展示。
import matplotlib.pyplot as plt
plt.figure(figsize=(14, 6))
df.set_index('path').length.plot(kind='bar')
plt.xticks(rotation=45)
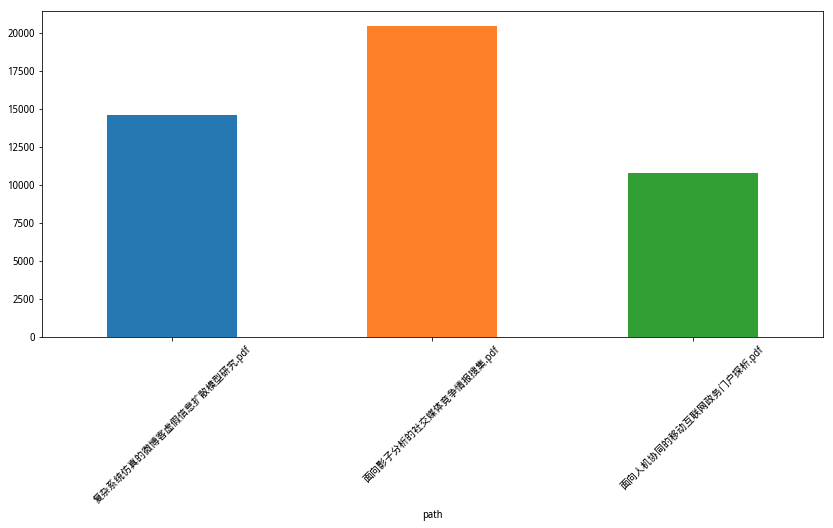
可视化分析完成。
下面我们把刚才的分析流程整理成函数,以便于将来更方便地调用。
我们先整合pdf内容提取到字典的模块:
def get_mydict_from_pdf_path(mydict, pdf_path):
pdfs = glob.glob("{}/*.pdf".format(pdf_path))
for pdf in pdfs:
key = pdf.split('/')[-1]
if not key in mydict:
print("Extracting content from {} ...".format(pdf))
mydict[key] = extract_pdf_content(pdf)
return mydict
这里输入是已有词典和pdf文件夹路径。输出为新的词典。
你可能会纳闷为何还要输入“已有词典”。别着急,一会儿我用实际例子展示给你看。
下面这个函数非常直白——就是把词典转换成数据框。
def make_df_from_mydict(mydict):
df = pd.DataFrame.from_dict(mydict, orient='index').reset_index()
df.columns = ["path", "content"]
return df
最后一个函数,用于绘制统计出来的字符数量。
def draw_df(df):
df["length"] = df.content.apply(lambda x: len(x))
plt.figure(figsize=(14, 6))
df.set_index('path').length.plot(kind='bar')
plt.xticks(rotation=45)
函数已经编好,下面我们来尝试一下。
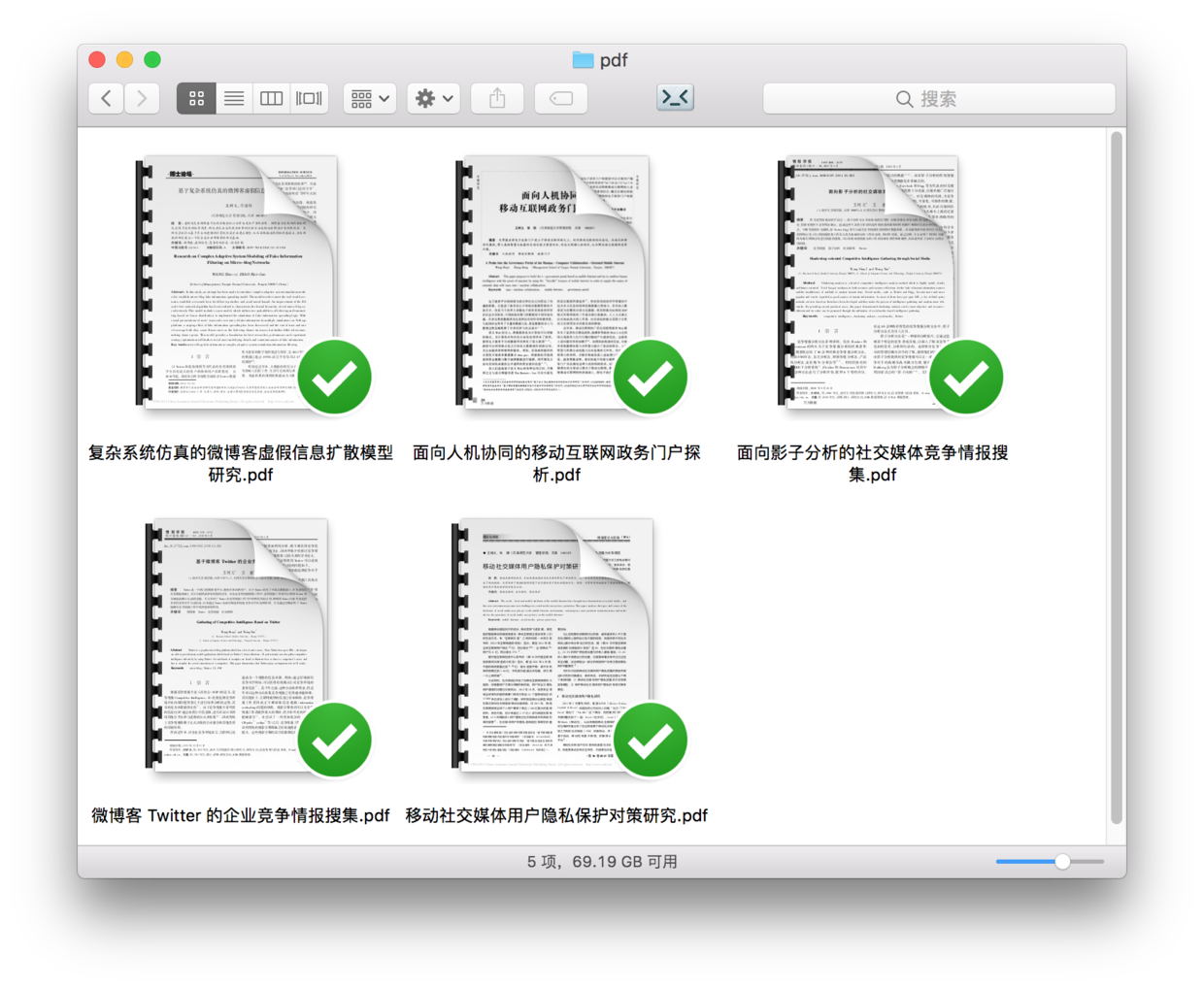
还记得演示目录下有个子目录,叫做newpdf对吧?
我们把其中的2个pdf文件,移动到pdf目录下面。
这样pdf目录下面,就有了5个文件:
我们执行新整理出的3个函数。
首先输入已有的词典(注意此时里面已有3条记录),pdf文件夹路径没变化。输出是新的词典。
mydict = get_mydict_from_pdf_path(mydict, pdf_path)
Extracting content from pdf/微博客 Twitter 的企业竞争情报搜集.pdf ...
Extracting content from pdf/移动社交媒体用户隐私保护对策研究.pdf ...
注意这里的提示,原先的3个pdf文件没有被再次抽取,只有2个新pdf文件被抽取。
咱们这里一共只有5个文件,所以你直观上可能无法感受出显著的区别。
但是,假设你原先已经用几个小时,抽取了成百上千个pdf文件信息,结果你的老板又丢给你3个新的pdf文件……
如果你必须从头抽取信息,恐怕会很崩溃吧。
这时候,使用咱们的函数,你可以在1分钟之内把新的文件内容追加进去。
这差别,不小吧?
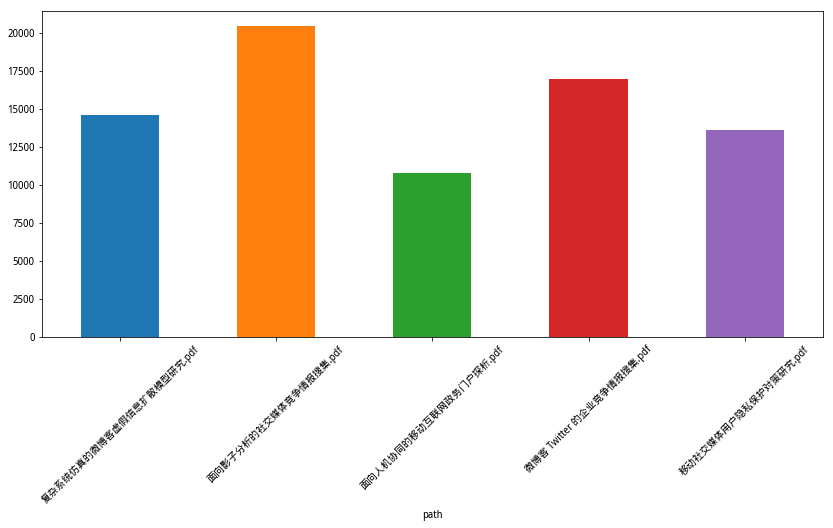
下面我们用新的词典,构建数据框。
df = make_df_from_mydict(mydict)
我们绘制新的数据框里,pdf抽取文本字符数量。结果如下:
draw_df(df)
至此,代码展示完毕。
小结
总结一下,本文为你介绍了以下知识点:
- 如何用glob批量读取目录下指定格式的文件路径;
- 如何用pdfminer从pdf文件中抽取文本信息;
- 如何构建词典,存储与键值(本文中为文件名)对应的内容,并且避免重复处理数据;
- 如何将词典数据结构轻松转换为Pandas数据框,以便于后续数据分析。
- 如何用matplotlib和pandas自带的绘图函数轻松绘制柱状统计图形。
讨论
你之前做的数据分析工作中,遇到过需要从pdf文件抽取文本的任务吗?你是如何处理的?有没有更好的工具与方法?欢迎留言,把你的经验和思考分享给大家,我们一起交流讨论。
喜欢请点赞。还可以微信关注和置顶我的公众号“玉树芝兰”(nkwangshuyi)。
如果你对数据科学感兴趣,不妨阅读我的系列教程索引贴《如何高效入门数据科学?》,里面还有更多的有趣问题及解法。
