


若要独立用 Python 处理数据科学问题,Pandas 是绕不过去的。
新番
今天,花了一上午的时间,跟着这个 Youtube 系列教程,学习了 Pandas 中级技巧。
视频来自于 Data School。发布者是 Kevin Markham 。
在这个系列视频教程里, Kevin 将自己的 PYCON 2018 workshop 分成了10个部分全部精剪后释出。一步步带你领略 Pandas 的魅力。
我用了2个多小时,完成了他10个视频的全部内容。
收获颇丰。
利用教程中提到的美国交通警务数据来自于斯坦福开放警务项目(THE STANFORD OPEN POLICING PROJECT)。
这是数据大概的样子:
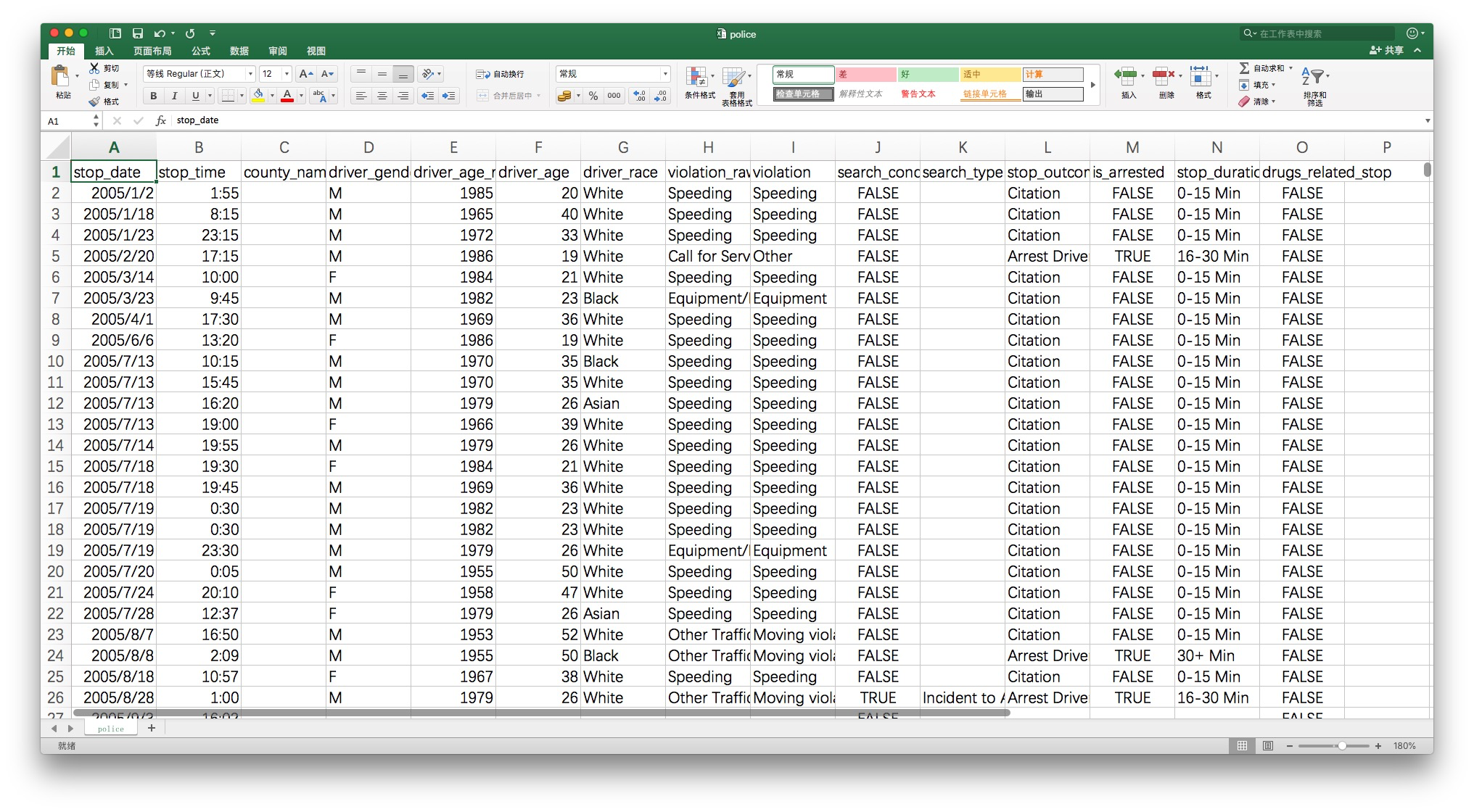
一步步按照 Kevin 的指令练习,你可以完成这些内容:
分析男女司机的交通违规都包括哪些类别?每一类占比如何?
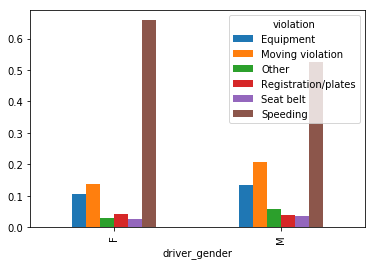
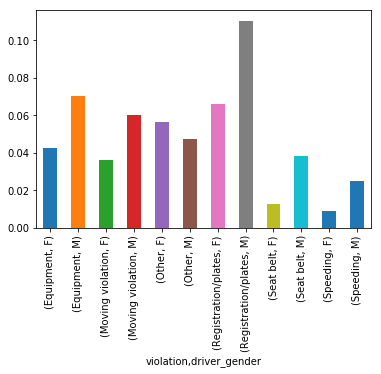
那些被搜查车辆的男女司机,各是由于什么原因?
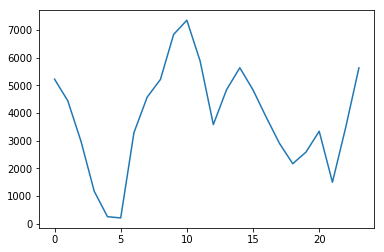
哪个时段,警察发现违规的数量最多?
不同违规行为里,司机年龄是如何分布的?

这些分析结果,只是这个教程的一小部分而已。
更妙的是,上述这些图形,几乎都是利用两三条 Pandas 语句,就可以做出。有的只需要一条就可以。
怎么样?有没有想学习的冲动?
教程与 ipynb 文件,都可以从这个github repo下载。
安装好 Anaconda 3之后,你就可以打开一个 Jupyter Notebook,跟着视频一起做了。
老友
说说我是怎么找到这么好的视频教程的。
其实一点儿也不稀奇。
因为我追 data school (Kevin Markham) 的视频,已经有好几年了。
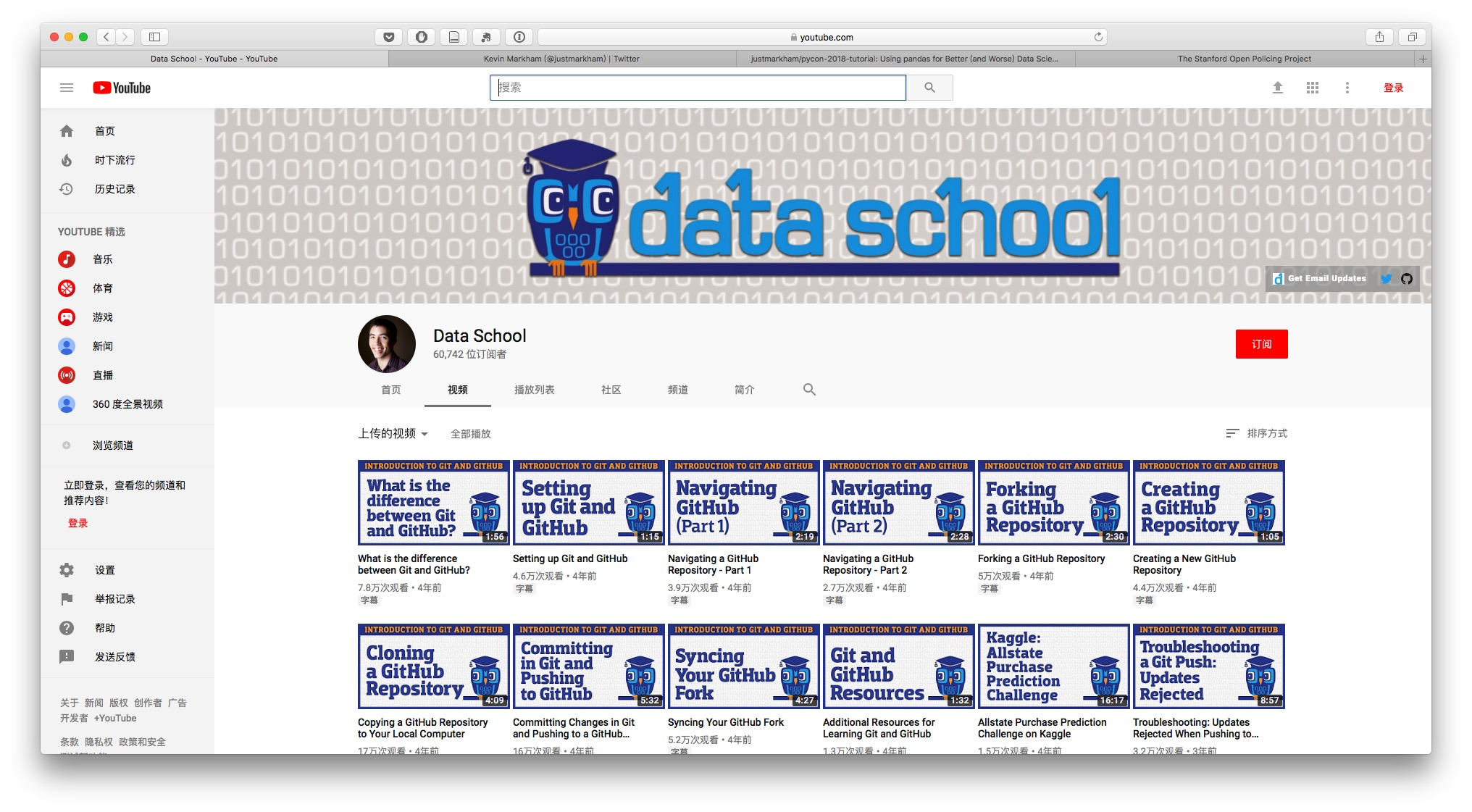
可以看到, Kevin 最早的视频,上传于 2014 年 4 月,讲述 git 和 github。
他还开设了官方网站 dataschool.io 。
后面一发不可收拾。讲的内容,几乎都是令人感兴趣的数据科学领域知识。
包括:
- R ,尤其是 dplyr。也是我们之前介绍过的 R 语言大师级人物 Hadley Wickham 的作品(参见《如何用 Python 和 API 收集与分析网络数据?》);
- 利用 Python 和 scikit-learn 做机器学习;
- 利用 Pandas 做数据整理;
- 用 Beautifulsoup 做网络爬虫。
我从2013年,开始自学 Python 。
其中有段时间,一直在追 dataschool 的更新。
从这些免费视频教程中,我受益良多。
2016年, Kevin 出品了一门付费课程,讲授如何使用 Python, scikit-learn 来进行自然语言处理(NLP)以及文本机器学习(machine learning for text)。
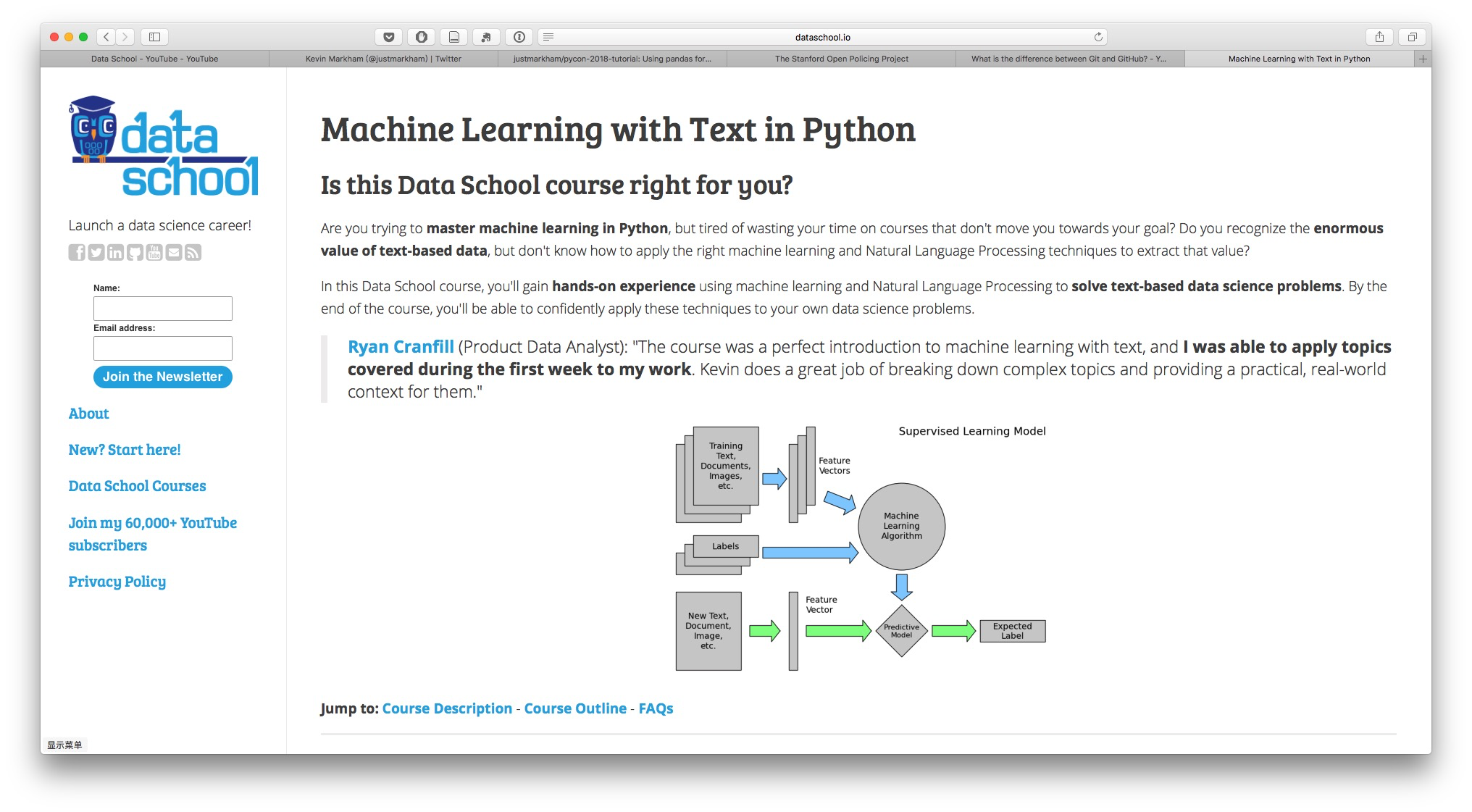
这是我第一次在主流课程平台(Coursera, Udacity, EdX, Datacamp)之外,付费购买课程。
售价不菲。
但是我觉得,这笔投资很有收获。
依靠这门课程获得的知识与技能,我带着研究生团队发布了3篇论文,其中2篇 EI 检索国际会议,一篇CSSCI国内核心期刊。3名研究生顺利毕业。
我也把这门课程中学到的知识,利用简书和微信公众号等途径,分享给了更多人。
案例式教学,详细讲述过程,用 Jupyter Notebook 分享全部代码与运行结果……
如果你常看我的公众号,对这种风格,应该不陌生吧?
对,Kevin 给了我很大影响。
但是,学完这门课之后,我发现 Kevin 的 Youtube 频道,一直出于停更状态。
我当时疑惑,他是不是和 mac 系统某著名编辑器作者一样,钱赚够了就一走了之退休了?
还好,几个月后,我从订阅邮件得知了他的去向:
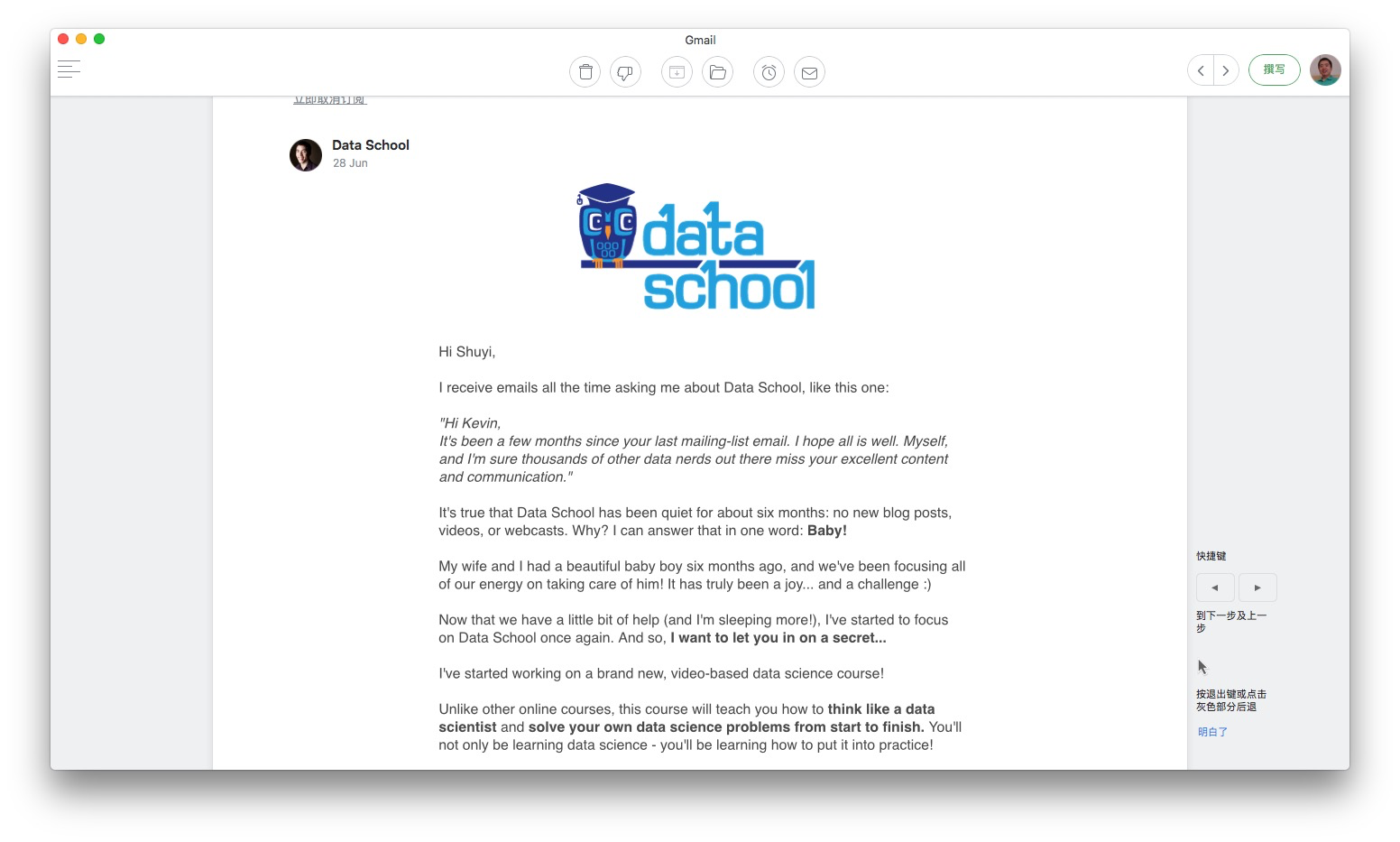
原来是喜得贵子,休陪产假去了。
所以,在 PyCon 2018 看见 Kevin 回归,我很开心。
教程
数据框 Pandas 的教程,我推荐你认真学习。
为什么呢?
因为数据科学分析全流程里面,人们似乎对爬虫(入口)和深度学习(出口)过于热衷,往往忘记了采集来的信息也许不是结构化的,而且里面存在着“不干净”(untidy)的数据,需要整理。
整理这样的数据,常用的工具,分别是 Python 中的 Pandas,以及 R 中的 tidyverse。
想想看,如果你用 Beautifulsoup, requests-html, scrapy 爬取数据,用 scikit-learn, keras, tensorflow 来做机器学习,那么你愿意中间跑出去一趟,到 R 里面做数据整理,再折腾回来吗?
所以,Pandas 比起 tidyverse 的主要优势,并不在于它的功能更强大,而在于它属于 Python 生态环境。
若要独立用 Python 处理数据科学问题,Pandas 是绕不过去的。
一旦你掌握了 Pandas 的数据框技术,就能轻松处理收集来的数据,同时为后面的模型建立做好充足的铺垫工作。
用什么教程来学习呢?
如果你对纸质阅读有偏爱,我推荐你看经典之作:Python for Data Analysis。这本书广受好评,口碑说明很多问题。
这本书有个问题,就是已经出版了将近6年,所以很多操作都已经过时了。
另外,所有纸质书的普遍问题,在于认知摄取维度单一。
相较而言,我更喜欢看视频教程,毕竟有个真人在演示,感觉好很多,也对自己的学习有个督促。
最起码,还能锻炼一下英语听说读写能力,是不是?
不过PyCon 2018 的这个教程,并不适合 Pandas 初学者。它的定位,是有一定基础的用户群体。
跟着教程开始做之前,我建议你先把 Pandas 的基础内容,学习一遍。
推荐的教程,是 Kevin 2016年的 Pandas 系列免费视频教程:Data analysis in Python with pandas。
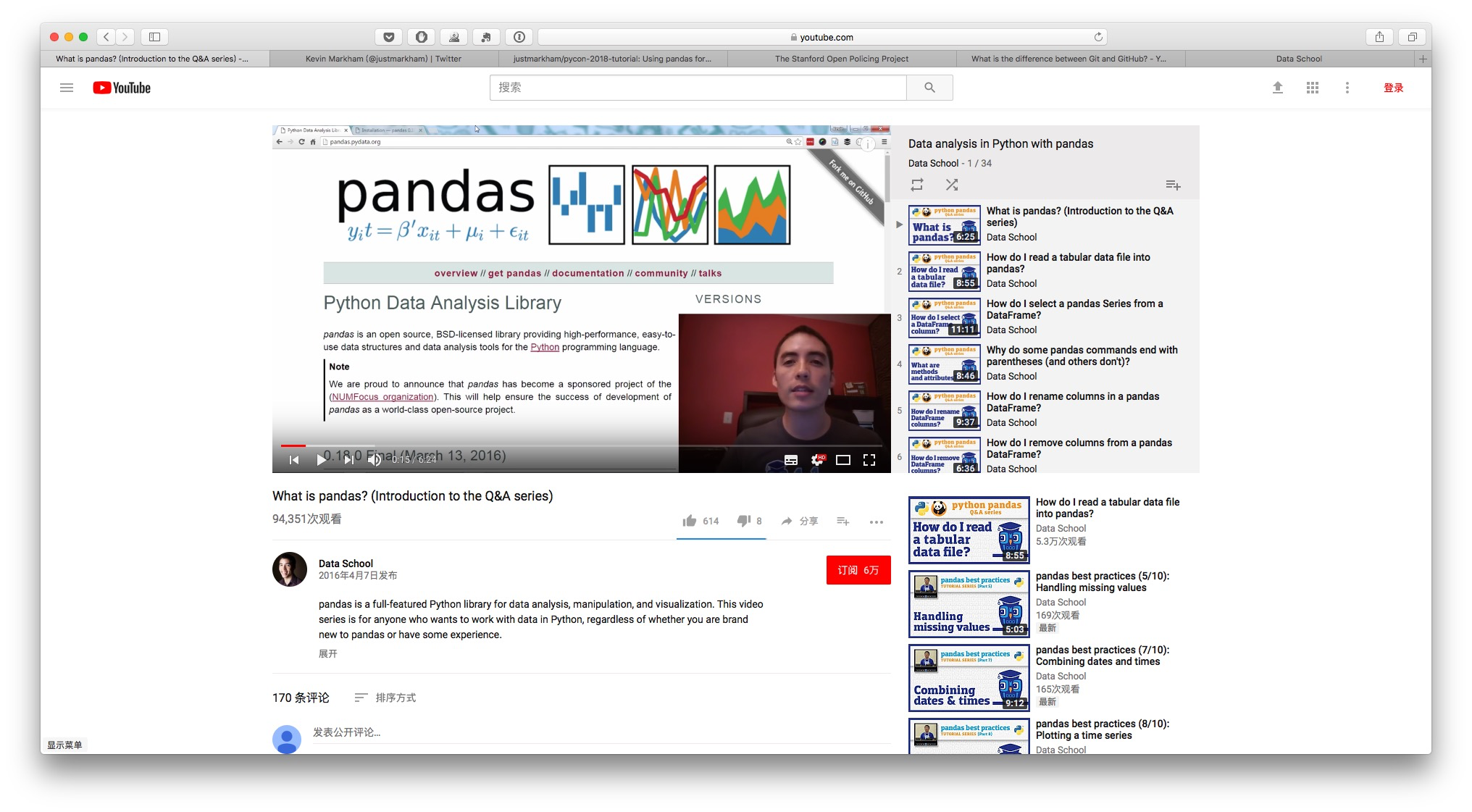
这个教程,从最简单的概念谈起,先教你怎么读取 csv 数据,然后一步步用具体问题引领你尝试、实践数据整理与分析操作。
可是,这个教程毕竟也已经出来两年了。
两年,对于一个成熟学科来说,也许还算不得什么。
不过,对于数据科学,那真可谓日新月异。
好在,2018年1月份, Kevin 发了两段更新视频教程,介绍了当前 Pandas 最新版本(0.22) 和 2016年时的版本(0.18)之间的区别,算是给教程打了个升级补丁。
有了这些前导内容做基础,相信你再来看 PyCon 2018 的视频,就轻松多了。
但是,我的建议,是不要局限于观看,而要一边看,一边打开 Jupyter Notebook 来实践。
唯其如此,才能真正提升应用技能,把 Pandas 的常用命令形成肌肉记忆。
祝学习进步!
喜欢请点赞。还可以微信关注和置顶我的公众号“玉树芝兰”(nkwangshuyi)。
如果你对数据科学感兴趣,不妨阅读我的系列教程索引贴《如何高效入门数据科学?》,里面还有更多的有趣问题及解法。
