

周五, 由于同事给了一个下载书籍的网站。所以心血来潮,想写一个爬虫demo,把数据都爬下来。然后发现一个电影网站也是类似,于是乎。代码重用。
爬虫步骤
- 分析目标网页的特征
- 找到需要爬取的数据
- 多页面数据的跳转
- 数据存储
1. 分析目标网页的特征
我今天要爬取的页面数据就是 周读, http://www.ireadweek.com/, 页面结构很简答,先是使用requests + bs4配合爬取。发现页面没有使用js,也没有做反爬虫的机制,所以很简单。
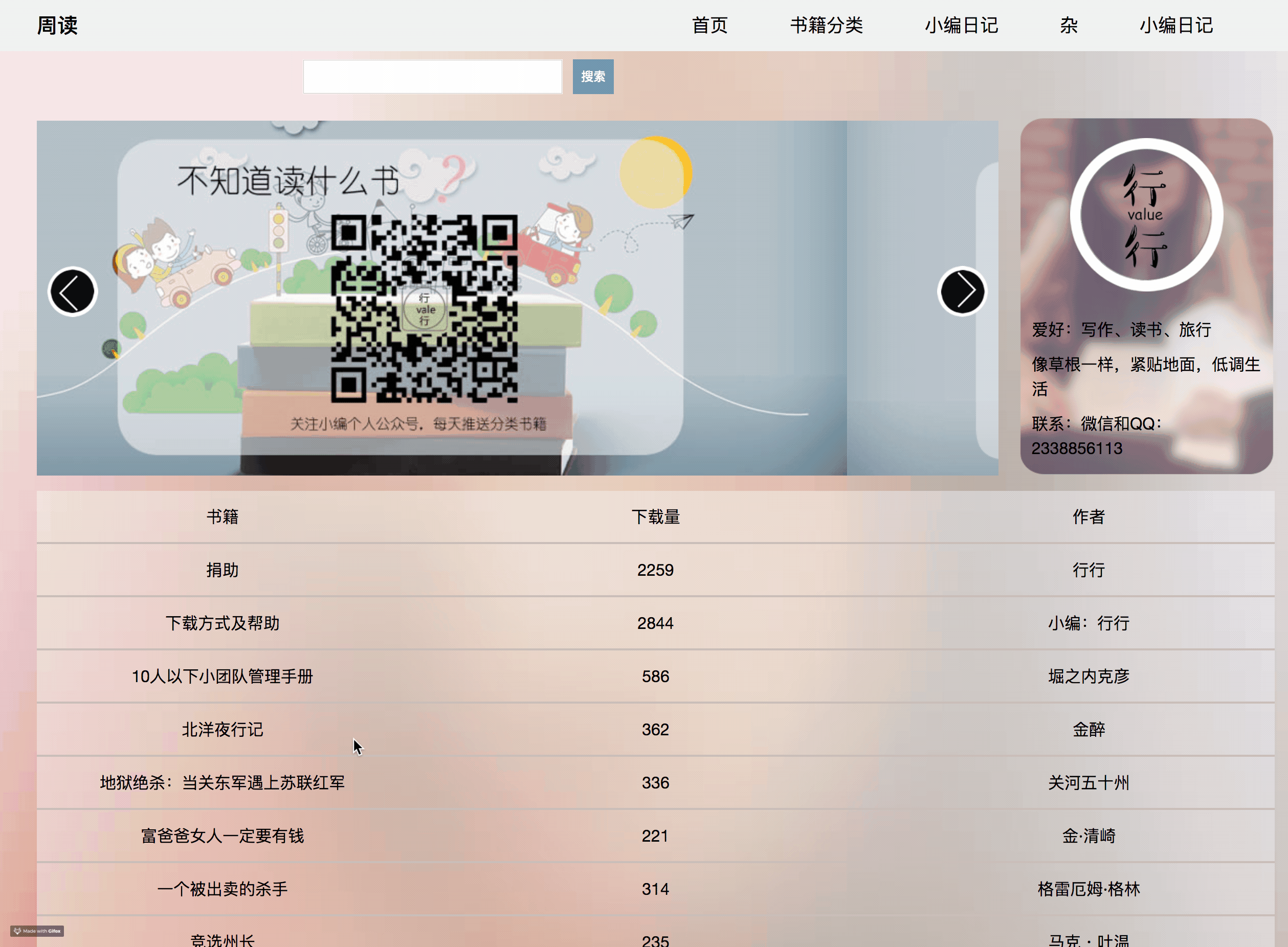
这个网站就两层结构, 主页->点击每个书籍->进入到书籍的详情页。我需要的数据也就是在详情页。如下图:
2. 找到需要爬取的数据
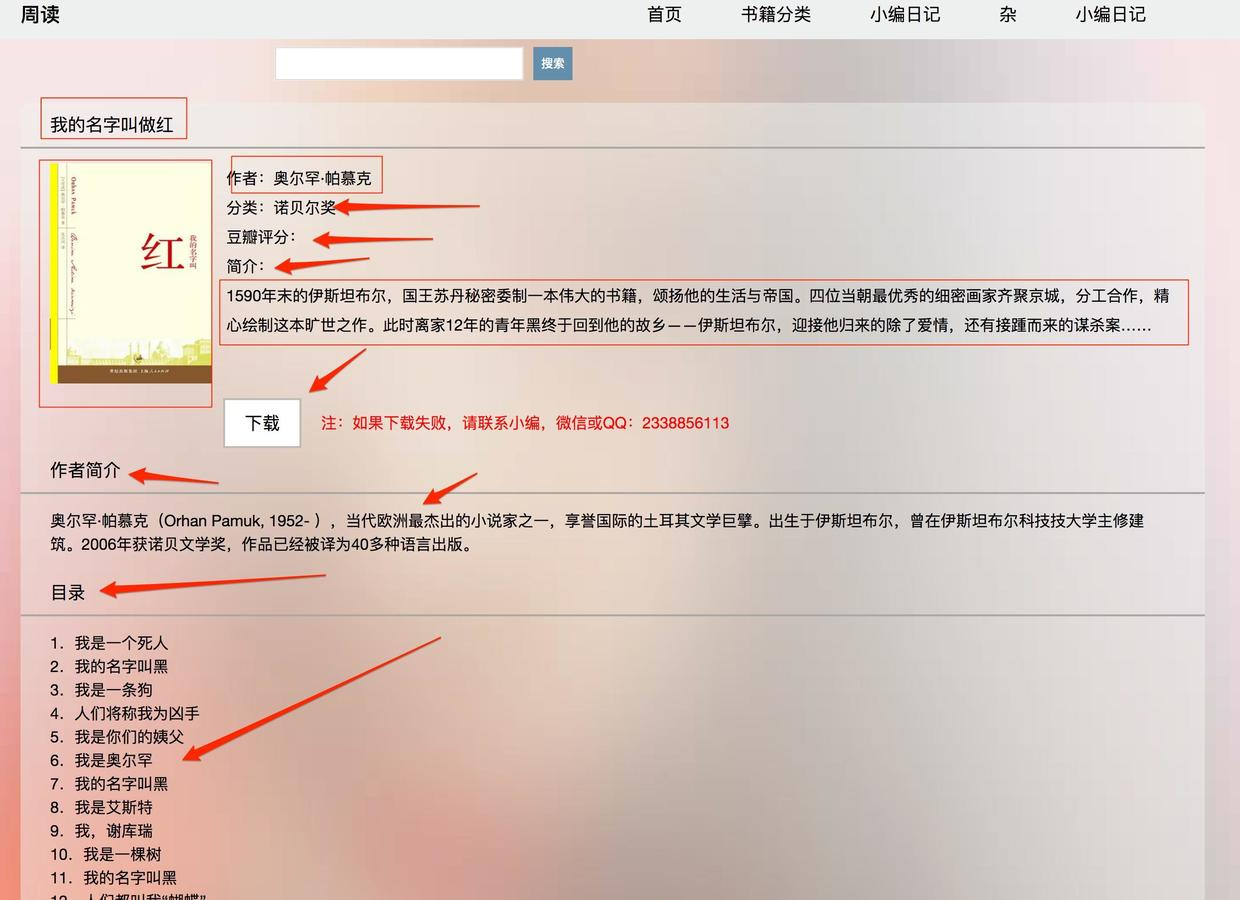
html_doc = response.body
soup = BeautifulSoup(html_doc, 'html.parser')
img_url = urljoin(CDN, soup.find('img').attrs.get('src').replace('//','/'))
download_url = soup.find('a', class_='downloads').attrs.get('href')
title = soup.find_all('div', class_='hanghang-za-title')
name = title[0].text
content = soup.find_all('div', class_='hanghang-za-content')
author_info = content[0].text
directory = '\n'.join([i.text.replace("\u3000", '') for i in content[1].find_all('p')])
info = soup.find('div', class_='hanghang-shu-content-font').find_all('p')
author = info[0].text.split('作者:')[1]
category = info[1].text.split('分类:')[1]
score = info[2].text.split('豆瓣评分:')[1]
introduction = info[4].text
3.多页面数据的跳转
这个主要是处理页面之间的跳转。就是使用下面的页码进行页面的跳转,我使用下一页。

next_url = urljoin(DOMAIN, soup.find_all('a')[-2].attrs.get('href'))
yield scrapy.Request(next_url, callback=self.parse)
由于没有使用具体的id,class,只能使用位置索引。
4.数据存储
数据存储,以前都是写到excel中或redis中,今天想写到mysql中,写到mysql可以使用pymysql或mysqlDB。 我选择使用ORM。 可以是SQLALCHEMY, Django Model. 我选择的是django model.
# django中
from django.db import models
# Create your models here.
class Book(models.Model):
id = models.IntegerField(primary_key=True)
name = models.CharField(max_length=255)
author = models.CharField(max_length=255)
category = models.CharField(max_length=255)
score = models.CharField(max_length=100)
img_url = models.URLField()
download_url = models.URLField()
introduction = models.CharField(max_length=2048)
author_info = models.CharField(max_length=2048)
directory = models.CharField(max_length=4096)
create_edit = models.DateTimeField(auto_now_add=True)
class Meta:
managed = False
db_table = "ireadweek"
# scrapy settings.py配置
import os
import sys
import django
sys.path.append(os.path.join(os.path.dirname(os.path.dirname(os.path.abspath(__file__))), ".."))
os.environ['DJANGO_SETTINGS_MODULE'] = 'Rino_nakasone_backend.settings'
django.setup()
# 在 scrapy中pipelines.py
from ireadweek.models import Book
import datetime
class RinonakasonePipeline(object):
def process_item(self, item, spider):
book = Book()
book.name = item.get('name')
book.author = item.get('author')
book.category = item.get('category')
book.score = item.get('score')
book.image_url = item.get('image_url')
book.download_url = item.get('download_url')
book.introduction = item.get('introduction')
book.author_info = item.get('author_info')
book.directory = item.get('directory')
book.create_edit = datetime.datetime.now()
book.save()
return item
# 在spider中引用
def parse_news(self, response):
item = IreadweekItem()
html_doc = response.body
soup = BeautifulSoup(html_doc, 'html.parser')
img_url = urljoin(CDN, soup.find('img').attrs.get('src').replace('//','/'))
download_url = soup.find('a', class_='downloads').attrs.get('href')
title = soup.find_all('div', class_='hanghang-za-title')
name = title[0].text
content = soup.find_all('div', class_='hanghang-za-content')
author_info = content[0].text
directory = '\n'.join([i.text.replace("\u3000", '') for i in content[1].find_all('p')])
info = soup.find('div', class_='hanghang-shu-content-font').find_all('p')
author = info[0].text.split('作者:')[1]
category = info[1].text.split('分类:')[1]
score = info[2].text.split('豆瓣评分:')[1]
introduction = info[4].text
item['name'] = name
item['img_url'] = img_url
item['download_url'] = download_url
item['author'] = author
item['author_info'] = author_info
item['category'] = category
item['score'] = score
item['introduction'] = introduction
item['directory'] = directory
return item
# 还有一个配置 settings.py
ITEM_PIPELINES = {
'RinoNakasone.pipelines.RinonakasonePipeline': 300,
}
技术要点
- scrapy
- django
- beautifulsoup
以上都要会使用,我还写了一个api接口。 http://127.0.0.1:8080/api/ireadweek/list/?p=400&n=20

另外一个网站是:
我项目的地址: https://github.com/jacksonyoudi/Rino_nakasone_backend
代码都在项目中。
