

阮一峰推特更新推荐一篇外文,闲来无聊,就(工具)翻译一波,菜鸟英文欢迎指正。原文链接
文中包含大量演示案例,如果有人关注这篇文章可以给我留言,我将继续整合中文版代码演示案例。

前因后果
在这篇文章中,我们将重温Gabriel Groner 对圣杯计划的贡献。格罗纳发明了一个非常聪明的程序,它识别手印的字母、数字、标点符号和几何图形。该程序能够正确识别第一时间用户绘制的90%个符号。格罗纳在一个1966兰德的备忘录中记录了他的方法,用于实时识别手写文本。在这篇文章中,我将介绍一个简单的格罗纳识别器,它只能够识别大写字母和大写字母。
演示源码github,欢迎交流。
进入正文
The RAND Tablet 初认识
人们使用RAND平板与圣杯互动,一个压力敏感开关安装在笔的顶端。所有的输入都会转化为xy平面坐标系的点。据记录,触控笔的位置每四毫秒为一对(x,y)坐标。
下面我们模拟了一个画板:移动指针并按下鼠标,这模拟了将手写笔压在平板表面上的动作。在不释放鼠标的情况下,将指针移动到平板表面,以形成标记。当你对标记满意时,释放鼠标按钮。试着通过绘制一些数字(2, 3, 6)和字母(C,M,S)来获得在平板电脑上工作的感觉。
Smoothing 平滑处理
你可能已经注意到,在平板上面的标记会出现一些难看的锯齿,并且滑动速度越快拐点越明显,这个是因为每四毫秒记录一个坐标。为了消除这些锯齿格罗纳决定使平板电脑的输出平滑。
该方案通过对新到达的数据点与先前平滑的数据点进行平均来平滑数据,从而减少由于由平板测量的笔位置的离散性引起的噪声。即((x1-x)*n,(y1-y)*n)
平滑操作是通过将每个新量化的数据点的位置与最后平滑的数据点的位置进行平均来执行的。我们可以通过在每一个量化的数据点和最近平滑的数据点之间画一条直线来几何平均地执行这个平均值。然后,我们沿着这条线将量化点滑动到先前平滑的点。我们进一步滑动点,我们越强调平滑的效果。你可以使用下面的画板直观体验。量化的数据点用蓝色绘制,平滑点将用黑色绘制。这三个按钮允许您指定每个点应该沿着指南滑动多远。更高的百分比将导致更平滑的曲线。
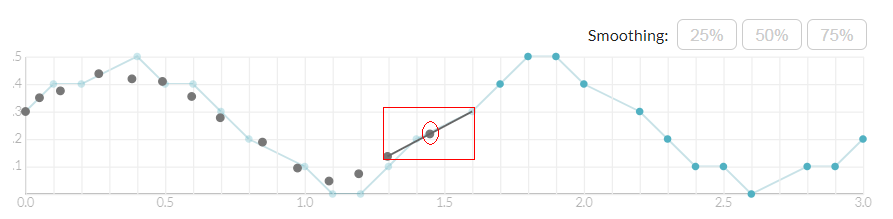
这个简单的平滑方案使我们能够摆脱不想要的数据,同时仍然保持笔划的总体姿态。但是平滑是一个破坏性的过程,因此,选择合适的平滑因子至关重要。
绘制下面的画板观察这个平滑方案将如何影响。可以通过拖动右边的滑块来改变每个笔划平滑的程度。我建议你在画板的左下方到右上方画一条直线,然后慢慢地拖动滑块,看看笔画是如何随着平滑量的变化而变换的。
Smoothing Factor: 0.43 滑动系数
XSi = 0.43XSi-1 + 0.57XRi
YSi = 0.43YSi-1 + 0.57YRi
XRi,YRi = coordinates of ith raw point 画板中的原始点
XSi,YSi = coordinates of ith smoothed point 平滑之后的点
【图三】
Thinning 细化
您应该注意到上面的案例生成了大量的数据,特别是当指针在平板电脑上缓慢移动时。因为我们只对每个笔画的一般形状感兴趣,所以这些数据点(太密集)实际上是不必要的。格罗纳采用了一个非常简单的细化方案来去除这些不必要的点。它可以几何描述如下:在第一数据点周围画一个正方形。在这个方块内的所有后续点都将被丢弃。然后,方块被重新定位在下一个点并且这个过程被重复。正方形的大小决定了需要细化的程度。这种细化方案在下面叫做可视化。
“Thinning”是从笔迹中删除一些数据点的过程。这是通过比较一个新的平滑数据点的位置与在细化轨道上的最后一点的位置来完成的。如果这些点相距甚远,则分析方案接受作为平滑轨迹的一部分的平滑点;否则,将被丢弃。细化消除了轨道中的小干扰,并通过大幅减少数据点的数量来减少数据处理要求。【图四】
下一个画板允许您在任意输入下对这种细化方案进行实验。原始数据点用蓝色绘制,稀疏点用黑色绘制。在最近变薄的点上,“稀疏平方”画成粉红色。首先在平板电脑上画一个符号,然后通过拖动图右下角的滑块来改变细化系数。你应该注意到,即使在非常剧烈地细化下,也可以保持大多数笔触的基本形状。格罗纳发现,即使丢弃了百分之七十的原始数据,他也能获得令人满意的结果。
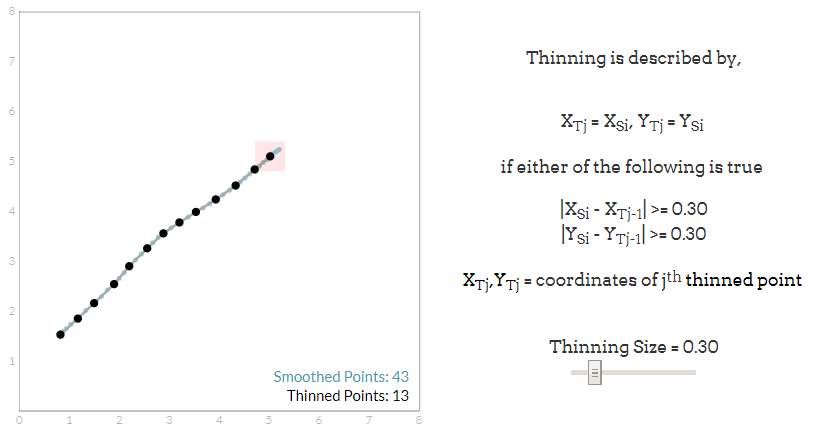
Thinning Size = 0.30 细化系数
|XSi - XTj-1| >= 0.30 绝对值大于系数的保留
|YSi - YTj-1| >= 0.30
Curvature 曲率
曲率是最明显的轨道特性,它不依赖于位置和大小,而是描述了轨道的形状。Freeman已经提出了一个有用的近似曲率是由细化轨道中的点产生的量化方向段的序列。KuHL和伯恩斯坦在他们的字符识别方案中使用了这种近似。事实上,伯恩斯坦发现不需要使用每个量化方向的持续时间,而是简单地列出量化方向上的变化。而KuHL和伯恩斯坦都使用八个可能的方向,这里所描述的识别方案仅使用四个。与其他特征结合使用已经提供了足够的特征来识别。
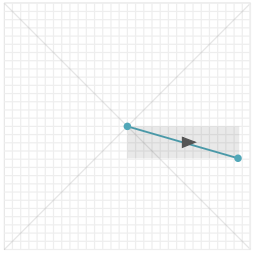
在平滑和细化处理之后,每个数据点被分配一个方向。有点令人震惊的是,格罗纳发现仅仅在描述笔画曲率时只考虑基数方向就足够了。因此,每个点被认为是向上、向下、向左或向右移动的结果。我们可以通过两个点形成的矩形来判断方向:如果这个矩形宽大于高,那么这个点是代表一个向左或向右的运动。如果矩形高大于宽,则点是向上或向下移动的结果。你可以用右视图来确定基数方向的确定。
if |XTj - XTj-1| >= |YTj - YTj-1|
right if XTj - XTj-1 >= 0
left if XTj - XTj-1 < 0
if |XTj - XTj-1| < |YTj - YTj-1|
up if YTj - YTj-1 >= 0
down if YTj - YTj-1 < 0
尽管每个点都被分配了一个基本方向,但是格罗纳字符识别器只使用方向的变化。这允许我们丢弃冗余数据点,并且实现每个笔画曲率的非常紧凑的表示。在该平板上,方向的变化以黑色绘制,冗余方向以浅灰色呈现。
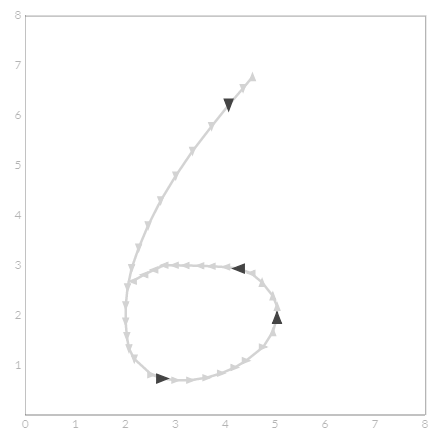
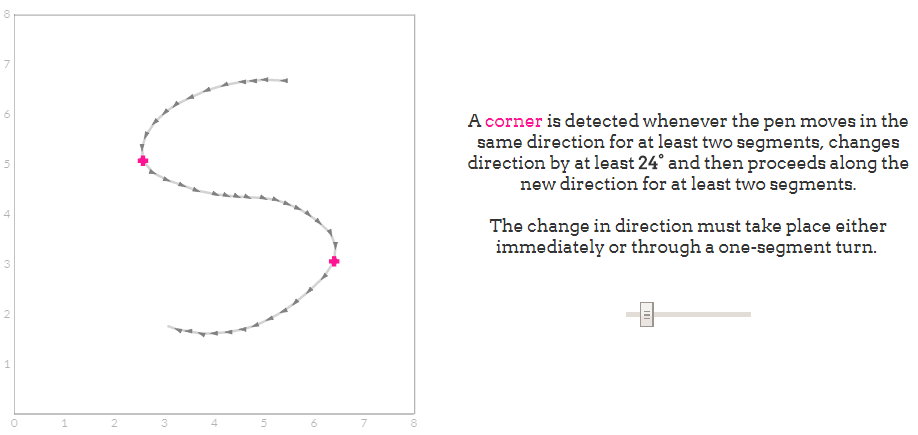
Corners 拐角
虽然每个笔画的曲率可以用于对用户意图做出猜测,但是一些符号不能仅使用方向信息彼此区分。例如,“5”和“S”的绘制,这两个方向都会产生相同的方向段。格罗纳决定用拐角的存在或不存在来解决这些歧义。例如,一个“5”通常会在符号的左手边画上一个或两个角,而一个“S”一般会在没有任何角的情况下画出来。
角检测是以相对简单的方式实现的。我们给每个输入点分配一个基数方向,格罗纳也给每个点分配16个可能方向。当笔在相同的方向上移动两个段,改变方向至少90°时检测到拐角。
在下面的平板上画一些数字、字母和基本形状,以查看动作中的角点检测算法。识别器将用粉红色十字标记角。你可以使用在平板电脑右边的滑块来测试90°以外的阈值。花一些时间绘制字符,其中角是一个有区别的特征(5,s,C,G,方和圆),然后缓慢地调整滑块。
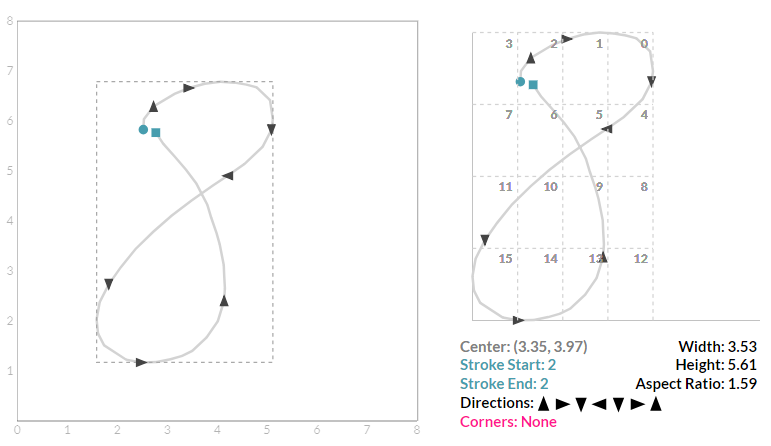
Size and Position Features 尺寸和位置特征
平板上的每一个标记都被包装成笔画描述。笔划描述是记录中显著特征的表示。这个描述使我们能够轻松地回答问题:“用户是否在左上角画了这个符号,然后在右下角停止绘图?”“如果这个问题的答案是肯定的,那么用户很有可能画出2或Z。”用户是否把笔从表面上提起,离他们开始画的地方很近?如果是这样的话,用户可能会画出像O或8那样的闭合行程。笔画描述还捕捉笔划的简单特征,如宽度、高度和纵横比。这些特征使我们能够回答这样的问题:“你能把这个符号形容为胖还是瘦?”“这个问题的答案可能有助于我们区分7和1。
当画出笔画时,其X(水平)和Y(垂直)极值不断更新。当笔被抬起到指示笔画完成时,分析方案使用这些极端来计算符号的高度和宽度以英寸的分数、其纵横比(高度与宽度的比率)以及其相对于原点的中心。它将由符号极值定义的矩形区域划分为4×4网格。然后,开始(笔下)和结束(笔向上)点以及拐角位置,每个被编码为位于这16个区域中的一个区域,从而相对于符号定位它们。
在下面的虚拟平板上画上一些字母和数字。开始绘图的位置用蓝色圆圈标出,停止绘图的位置用蓝色正方形标记。
Character Recognition 字符识别
“符号的识别基于与数据相关的测试序列。在决策过程中的每一步都有几个潜在的标识。其中一些通过测试轨道的主要特征而被消除。在任何步骤应用的特定测试取决于该步骤中可能的标识集,以及已经检查过的轨道的那些特征。因此,决策方案具有树形结构。它最初的设计是基于对四个用户的笔迹的检查。作者改变其结构,以适应额外的符号变化,因为他获得更多的经验。”
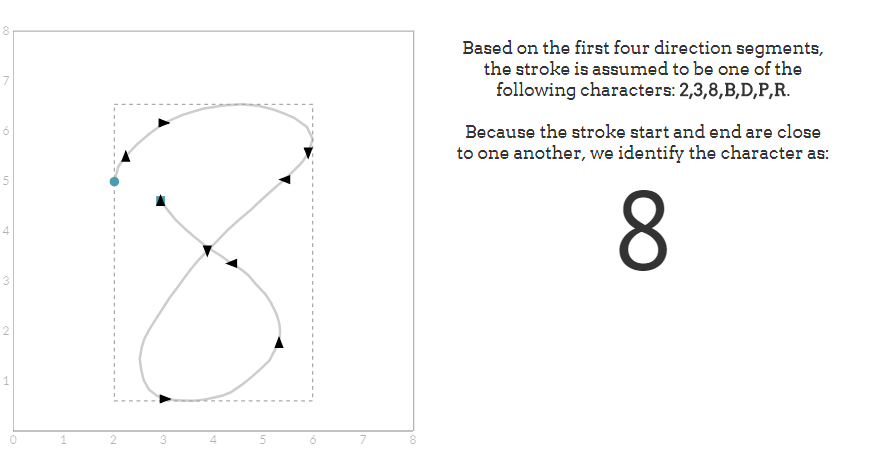
识别器首先根据笔画的前四个基本方向生成潜在字符列表。不能直接或不使用这些前四个方向绘制的笔画立即被忽略。有时,前四个方向提供足够的信息来精确地识别字符。例如,一个向下、向右、然后停止的笔划可以立即被识别为L。通常,前四个方向不会导致立即识别,我们将留下一个潜在字符列表。举例来说,一个开始的行程可能是0,2或3。

我们可以通过测试笔画描述的其他方面来解决这些歧义。例如,如果笔划在符号的右下角结束则可以识别为2;在符号的左下角结束为3;起始位置和结束位置都在符号的顶部彼此靠近来识别0。在实践中,决策过程是通过编写一个大的IF语句级联来实现的。在这个过程中没有“魔术”。并且决策树需要改进和修改会遇到写某些字符的新的和意外的方法。
我在本文中提出的识别器能够识别大写字母和数字,它们是在一个笔划中绘制的。换句话说,每一个字符都必须一笔全部画出来。格罗纳的原始识别器能够识别多笔画字符,允许用户以原来习惯的方式输入文本。格罗纳的目标是保持用户现有习惯,使用户不需要适应他们的写作风格。事实上,Alan Kay声称,该系统的主要动机之一是排除打字教学的需要。因为我的目标远没有那么雄心勃勃——为了解释格罗纳所使用的基本方法——我决定实现一个更简单的单笔画变体的识别器。多笔画识别并不比单笔画识别复杂得多,但有点复杂。如果你有兴趣自己去执行,格罗纳的原备忘录中清楚地阐明了这种方法。
我的约束,所有字符必须在一个笔画完成,它希望用户能大致按照下面的词汇输入字母和数字。特别是F和X,需要来自用户的一点不自然的心理扭曲。点击一个笔画看到它正在绘制的动画(翻译截图不支持动画,需要请查看原网址)。
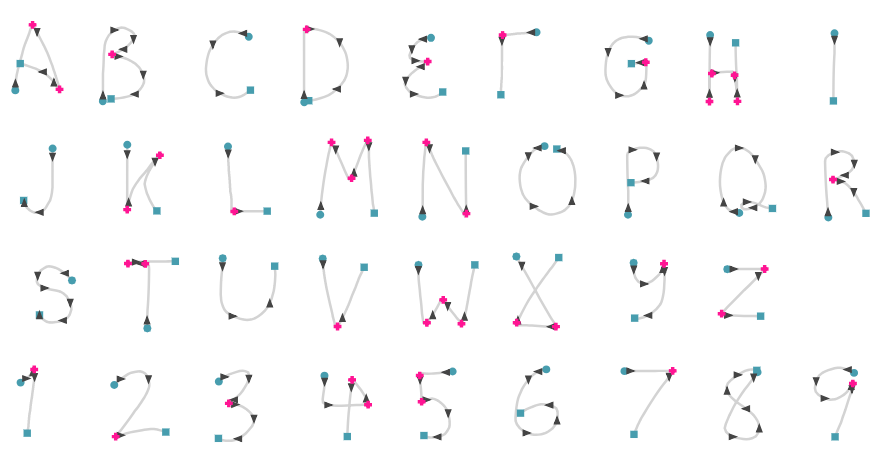
当绘制一个给定的字符时,必须遵循一般的形状,格罗纳的方法是足够健壮的,以便在绘制字符时允许大量的变化和松弛。例如,所有下列笔划将被标识为数字3。

结语
为什么2016年(这篇文章是2016年写的)的人要关心上个世纪的手写识别算法?自从格罗纳的备忘录出版以来,五年已经过去了,圣杯已经从主流节目和HCI社区的经典中消失了,为什么要花时间重读格罗纳的原著,更不用说这篇文章了?
对我来说,格罗纳的工作是有趣的,不是因为它允许一个人将文本传送到计算机系统,而是因为它允许人类通过高带宽的绘画媒介与计算机接口。在本文中,我关注的是文本,因为这是格罗纳原创作品的一个主要焦点,但我看到这项技术在图形和类似手势的识别和处理方面有着更为引人注目的应用。绘画是一种非常强大的交流方式,我非常喜欢绘画可以作为一种主要的或辅助的与我们个人电脑进行交流的方法。肯-佩林的ChalTalk是这一原理的一个很好的例子,我强烈推荐你看他的演示,如果你怀疑格罗纳的方法应用于文本识别之外的任务。
翻译自 -Jack Schaedler Berlin, 2016
