

1.关于Tusahre
Tushare是一个免费、开源的python财经数据接口包。主要实现对股票等金融数据从数据采集、清洗加工 到 数据存储的过程,能够为金融分析人员提供快速、整洁、和多样的便于分析的数据。其网址为:tushare.org/,打开之后的界面如下:
在界面左侧,可以看到能够抓取很多数据。
2.Tushare的安装与使用
在Tushare界面有对其安装与使用的介绍:
初步的调用方法为:
import tushare as ts
ts.get_hist_data('600848') #一次性获取全部日k线数据
得到结果:
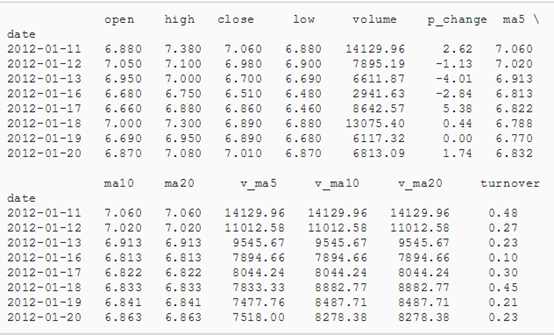
第一列是日期,后边的是各类价格,包括开盘价、最高价、收盘价等等,具体在Tushare里边都有详细介绍。
3.调用Tushare抓取上证指数并作可视化
上证指数的代码为00001,在这里抓取2017-01-01到2018-03-31期间的数据,并对其涨跌幅,也就是收益率进行初步可视化。代码如下:
import tushare as ts
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
df = ts.get_hist_data('000001',start='2017-01-01',end='2018-03-31')
df.head(10)
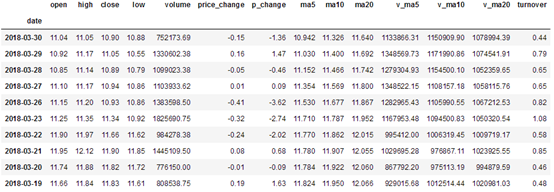
可以看到转去了上证指数的各类价格数据以及最后turnover的换手率。但是有一个问题就是数据的date的降序的,即日起从2018年3月往2017年1月排列的,需要排序。
sz=df.sort_index(axis=0, ascending=True) #对index进行升序排列
sz_return=sz[['p_change']] #选取涨跌幅数据
train=sz_return[0:255] #划分训练集
test=sz_return[255:] #测试集
#对训练集与测试集分别做趋势图
plt.figure(figsize=(10,5))
train['p_change'].plot()
plt.legend(loc='best')
plt.show()
plt.figure(figsize=(10,5))
test['p_change'].plot(c='r')
plt.legend(loc='best')
plt.show()
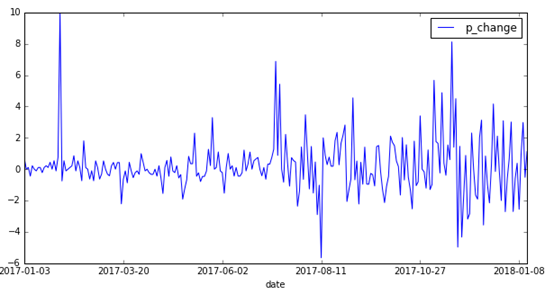
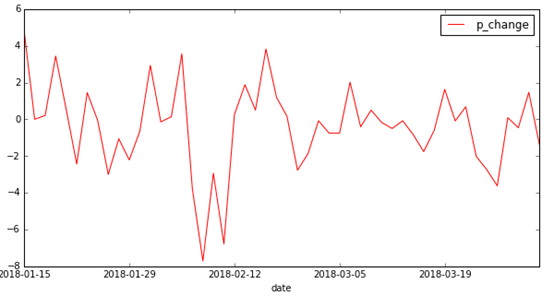
蓝色为训练集序列波动图,红色为测试集序列波动图。
4.对上证指数收益率做初步时间序列分析
(1)直接用最后一个值作为测试集的预测值
train.index =pd.to_datetime(train.index)#转换时间字符格式以方便作图
test.index =pd.to_datetime(test.index)
dd= np.asarray(train.p_change) #z转换成向量,以便加入y_hat中
y_hat = test.copy()
y_hat['naive'] = dd[len(dd)-1]
plt.figure(figsize=(12,8))
plt.plot(train.index, train['p_change'], label='Train')
plt.plot(test.index,test['p_change'], label='Test')
plt.plot(y_hat.index,y_hat['naive'], label='Naive Forecast')
plt.legend(loc='best')
plt.title("Naive Forecast")
plt.show()
#计算RMSE
from sklearn.metrics import mean_squared_error
from math import sqrt
rms = sqrt(mean_squared_error(test.p_change, y_hat.naive))
print(rms)
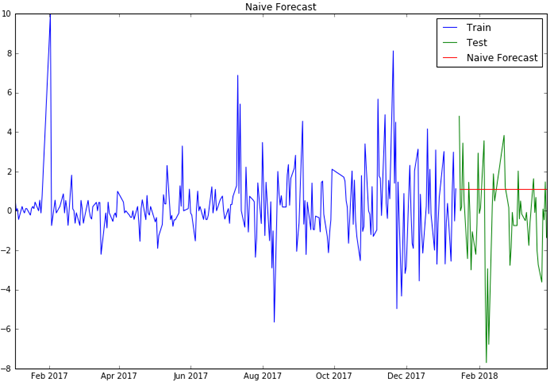
蓝色为训练集序列,绿色为测试集序列,红色为预测值序列,得到RMSE为2.7924。
(2)直接用训练集平均值作为测试集的预测值
#Simple Average
y_hat_avg = test.copy() #copy test列表
y_hat_avg['avg_forecast'] = train['p_change'].mean() #求平均值
plt.figure(figsize=(12,8))
plt.plot(train['p_change'], label='Train')
plt.plot(test['p_change'], label='Test')
plt.plot(y_hat_avg['avg_forecast'], label='Average Forecast')
plt.legend(loc='best')
plt.show()
rms = sqrt(mean_squared_error(test.p_change, y_hat_avg.avg_forecast))
print(rms)
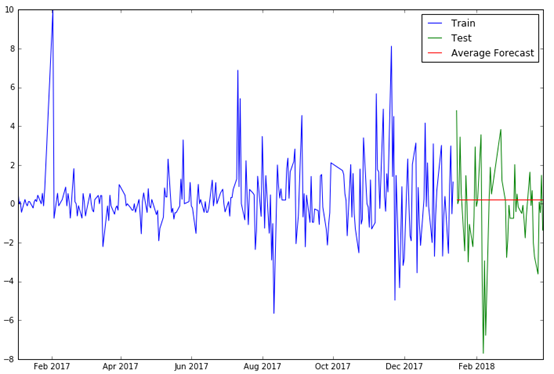
得到RMSE为2.4192。
(3)直接用移动平均法最后一个值作为测试集的预测值
#Moving Average
y_hat_avg = test.copy()
y_hat_avg['moving_avg_forecast'] = train['p_change'].rolling(30).mean().iloc[-1]
#30期的移动平均,最后一个数作为test的预测值
plt.figure(figsize=(12,8))
plt.plot(train['p_change'], label='Train')
plt.plot(test['p_change'], label='Test')
plt.plot(y_hat_avg['moving_avg_forecast'], label='Moving Average Forecast')
plt.legend(loc='best')
plt.show()
rms = sqrt(mean_squared_error(test.p_change, y_hat_avg.moving_avg_forecast))
print(rms)
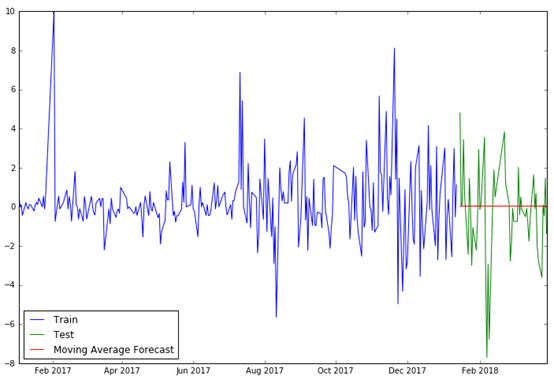
得到RMSE为2.3849。
可以看到,最后移动平均法的均方误差最低,预测效果最好。
