

一、yellowbick简介
这个库我昨天刚刚在PyData2018看到的库,一开始觉得内容没啥用。后来翻看这个库的文档觉得对于机器学习帮助很大,就写了今天这篇文章。
yellowbrick是一款可视化分析和诊断库,可以帮助理解并优化模型。。
yellowbrick是一组名为Visualizers(可视器)的可视化诊断套件。它在scikit-learn的api基础上做了扩展,能让我们更容易的驾驭模型优化阶段。简而言之,yellowbrick将scikit-learn和matplotlib有机结合起来,通过可视化方式帮助我们优化。
http://www.scikit-yb.org/en/latest/quickstart.html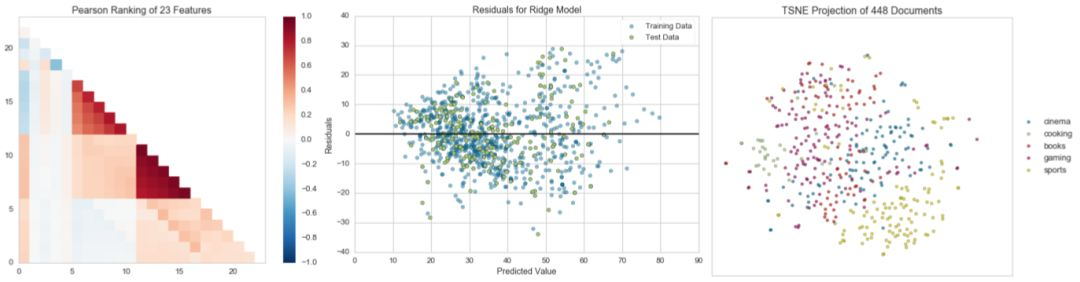
可视器-Visualizers
因为yellowbrick是在scikit基础上做的封装,Visualizers(可视器)实际上就是scikit中的estimator(评估器),Visualizers可以从数据中学习规律并通过可视化来增进我们对于数据的理解,进而优化模型。从scikit-learn角度看,当我们可视化数据特征空间,visualizer功能很类似与scikit的transformer。
二、 安装yellowbrick库
在终端中输入下面命令
pip3 install -U yellowbrick如果你使用anaconda自带jupyter notebook,那么你可能要在终端中使用下面的命令
conda install -c districtdatalabs yellowbrick三、小案例
由于这个库很有用,后面我会拿出时间学习这个库。今天就先只放yellowbrick的少部分案例,以后抽时间深挖下这个库。
3.1 实例的水平可视化
如果数据集特征数大于3,我们很难在坐标系中将其可视化。而yellowbrick的水平可视化方法,可以很好的解决这个问题。水平轴代表不同的特征,纵向代表特征的值。在这里我们使用scikit-learn中的iris数据集,该数据集有三种花,四种特征。
再重新解释下,yellowbrick是对scikit的封装,所以很多语法很类似。比如在可视器Visualizer跟Estimator类似,都有fit和transform方法。而Visualizer绘图时的我们只需要在visualizer上使用poof方法。
%matplotlib inlineimport matplotlib.pyplot as pltfrom sklearn.datasets import load_irisfrom yellowbrick.features import ParallelCoordinatesiris = load_iris()X = iris.datay = iris.target#Parallel Coordinates:实例的水平可视化visualizer = ParallelCoordinates()visualizer.fit_transform(X, y)#我发现这里仅使用fit效果与fit_transform画出来的图效果差不多。大家自己试一试visualizer.poof()
poof方法会最终绘图(在画布中会自动添加标题,轴标签等等),然后将其渲染到jupyter notebook或者GUI中。poof方法还可以将可视化效果保存到图片或者pdf文件中。
这两种写法我在notebook中运行没有看到有文件生成,但是在pycharm中运行并发现有这些文件生成。visualizer.poof(output='pcoords.png')visualizer.poof(output='pcoords.pdf')3.2 模型评估可视化
Visualizer不知可以对数据进行可视化,还可以对scikit-learn的模型进行评估、超参数调优(hyperparameter tuning )和算法选择。例如,为了生成一个分类报告的热力图,显示准确率、召回率和F1值信息,我们可以使用下面的 代码。
%matplotlib inlinefrom sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_splitfrom yellowbrick.classifier import ClassificationReportfrom sklearn.linear_model import LogisticRegression#读取数据iris = load_iris()X, y = iris.data, iris.target#将数据分为训练集合测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.4, random_state= 100)#初始化visualizer,该visualizer好像继承了model的能力model = LogisticRegression()visualizer = ClassificationReport(model)#visualizer开始学习训练集中的规律visualizer.fit(X_train, y_train)#visualizer评测模型学习效果visualizer.score(X_test, y_test)#可视化visualizer.poof()我们简单的解读下,横坐标分别是准确率、召回率、F值、纵坐标代表的是3种花。
其中第一种花(0)准确率达到100%,和第二种花(1)的达到93.3%, 第三种花(2)达到92.3%。
其他的召回率和F值都很好理解,我就不解说了。
3.3 将数据和模型评估同时可视化
yellowbrick还可以调用函数,直接同构两行代码将数据可视化和模型平柜可视化一起解决。这里我就不分训练测试了,
%matplotlib inlinefrom sklearn.datasets import load_irisfrom yellowbrick.features import parallel_coordinatesfrom yellowbrick.classifier import classification_reportfrom sklearn.linear_model import LogisticRegression#读取数据iris = load_iris()X, y = iris.data, iris.target#数据可视化parallel_coordinates(X, y)#模型评估classification_report(LogisticRegression(), X, y)
四、 大实例
4.1 共线性检验Rand2D
前面三个都比较简短,现在我们做一个比较完整的示例。在线性回归中,特征的选择要保证特征(变量)之间彼此尽量相互独立,不要出现共线性。我们使用Rank2D可视化器viasulizer来可视化两两变量间的相关系数。
我们使用共享单车数据集(bike sharing datasets),该数据已经存放到文件夹中,bikesharing.csv。通过分析该数据集我们希望根据季节,天气或假期等特征预测在特定小时内租用的自行车数量。
import pandas as pdfrom yellowbrick.features import Rank2D#读取数据data = pd.read_csv('bikeshare.csv')X = data[["season", "month", "hour", "holiday", "weekday", "workingday","weather", "temp", "feelslike", "humidity", "windspeed"]]y = data["riders"]visualizer = Rank2D()visualizer.fit_transform(X, y)visualizer.poof()
4.2 JointPlotVisualizer
从上面图可以看到,month和season相关性好像大于0.75,这个很好理解。feelslike与temp相关性接近于1,这个还需要进一步探索。我们使用JointPlotVisualizer来检查两者的关系。
from yellowbrick.features import JointPlotVisualizervisualizer = JointPlotVisualizer(feature='temp', target='feelslike')visualizer.fit(X['temp'], X['feelslike'])visualizer.poof()
从上面的图中,feelslike与temp有很强的线性关系,JointPlotVisualizer可以让我们很容易查看特征(变量)之间的相关性,以及特征值的范围和分布。需要指出的是横纵坐标轴是经过标准化处理,使得两变量的值分布在[0,1],防止量纲导致两变量对因变量影响力的大小缺乏真实性,无法做出科学的对比。
上图很有意思:
-
feelslike在0.25附近有少量的离群点,需要手动移除掉以保证最终的模型的质量。
-
我们发现温度越高,人们觉得越热。越冷,人们月的越冷。这提示我们,使用feelslike可能比temp更好,因为feelslike有可能对因变量的影响更具有真实性直接性。
4.3 残差分析
现在我们使用线性回归模型训练bikesharing数据,看看训练后线性回归模型的残差(Residuals)等信息。
from yellowbrick.regressor import ResidualsPlotfrom sklearn.linear_model import LinearRegressionfrom sklearn.model_selection import train_test_split#读取数据data = pd.read_csv('bikeshare.csv')X = data[["season", "month", "hour", "holiday", "weekday", "workingday","weather", "temp", "feelslike", "humidity", "windspeed"]]y = data["riders"]#分割训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.1, random_state=100)#初始化visualizer,继承LinearRegression的能力visualizer = ResidualsPlot(LinearRegression())visualizer.fit(X_train, y_train) #训练visualizer.score(X_test, y_test) #模型评估visualizer.poof()
残差图显示对预测值的误差,并允许我们寻找模型中的异方差性;例如误差最大的目标区域。残差的形状可以很好地告诉我们OLS(普通最小二乘)受到我们模型的特征强烈影响。 在这种情况下,我们可以看到预测值越低(车手数量越少),误差越低,但预测的车手数量越高,误差越高。
这表明我们的模型在某些目标区域有更多的噪声,或者两个变量是共线的,这意味着它们在它们关系中的噪声发生变化时注入误差。
残差图(residuals plot)还显示了模型中的误差是如何产生的,residulas = 0处的粗体水平线表示没有误差,并且该线之上或之下的任何点都表示误差的大小。 例如,大多数残差是负数,并且由于residuals = actual - predicted,这意味着 预测值大部分时间大于实际值。例如, 我们的模型主要是预测比实际骑手的数量更多。 此外,残差图的右上方有一个非常有趣的边界,表明模型空间中有一个有趣的影响;
在该模型的区域中可能某些特征被极大的加权了。
在上图中,因为训练集和测试集都被分配为不同的颜色。这有利于我们合理分割训练集和测试集,如果测试集误差不能很好的与训练集重合,那么训练的模型要么过拟合(overfit)要么欠拟合(underfit),据此我们可以得出在分割训练集和测试集之初,可能我们在分割前没有将数据打乱。
因为我们的训练集的判定系数( R 2 )是0.341,让我们看看能不能通过将数据标准化后将判定系数提高。yellowbrick这个例子有点复杂,会用到Ridge回归。对这方面我也不懂,百度了发现Lasso和Ridge经常出现在一起,我就一起科普一下。


Lasso回归可以使得一些特征的系数变小,甚至还是一些绝对值较小的系数直接变为0,增强模型的泛化能力
Ridge回归在不抛弃任何一个特征的情况下,缩小了回归系数,使得模型相对而言比较的稳定,但和Lasso回归比,这会使得模型的特征留的特别多,模型解释性差。
import numpy as npfrom sklearn.linear_model import RidgeCV #交叉检验Ridge回归from yellowbrick.regressor import AlphaSelectionalphas = np.logspace(-10, 1, 200)visualizer = AlphaSelection(RidgeCV(alphas=alphas))visualizer.fit(X, y)visualizer.poof()
在探索模型族时,要考虑的主要问题是模型的复杂度。 随着模型复杂度的增加,由于变化导致的误差增加,模型过度拟合并且不能推广到测试数据(未来或者未知的数据)。 然而,模型越简单,偏差就可能导致更多的误差;模型欠拟合会更频繁地错过目标(target,这里我不知道怎么翻译)。 大多数机器学习的目标是创建一个足够复杂的模型,找到偏差和方差之间的中间地带。
对于线性模型,复杂性来自特征本身以及根据模型分配的权重。 线性模型因此期望达到解释结果同时尽可能用最少数量的特征。 实现这一目标的一种技术是正则化,即引入一个称为alpha的参数,用于相互校正系数的权重并惩罚复杂性。 alpha和复杂度有相反的关系,阿尔法越高,模型的复杂性就越低,反之亦然。
这个问题因此成为你如何选择alpha。 一种技术是使用交叉验证(cross validation)来拟合多个模型,并选择具有最低误差的alpha。 AlphaSelection可视化工具可以让您做到这一点,并以可视化的方式显示正则化的行为。 正如您在上图中看到的那样,误差随着alpha值先降低后升高。在alpha=3.612达到误差最小值。 这使我们能够针对偏差/方差权衡并探索正则化方法的关系(例如Ridge和Lasso)。
我们现在使用PredicionError来可视化我们的模型,来看看真实值与预测值分布。
from sklearn.linear_model import Ridgefrom yellowbrick.regressor import PredictionErrorvisualizer = PredictionError(Ridge(alpha=3.612))visualizer.fit(X_train, y_train)visualizer.score(X_test, y_test)visualizer.poof()
按理想情况,所有的点应该分布在45%线(identity线)附近,但是现实情况肯定是预测值与真实值存在出入,所以最好的拟合结果应该是加粗黑色虚线(best fit)。就像残差图一样,这可以让我们看到误差发生的位置和幅度。
在这个图中,我们可以看到大多数实例密度小于200个骑手。 我们可能想尝试正交匹配追踪或样条拟合,以适应考虑到更多区域性的回归。 我们还可以注意到,残差图的奇怪拓扑结构似乎是用Ridge回归来修正的,并且我们的模型在大小值之间存在更多的平衡。 可能的是,Ridge正则化解决了两个特征之间存在的协方差问题。 随着我们使用其他模型形式进行分析,我们可以继续利用可视化工具快速比较并查看我们的结果。
Wow,终于写完了。这只是yellowbrick文档的快速入门(quickstart)部分,我再简单介绍yellowbrick完整的功能模块
四、yellowbrick各功能介绍
4.1特征可视化
-
Rank Features:单个或成对特征排序以检测关系
-
Parallel Coordinates:实例的水平可视化
-
Radial Visualization:围绕圆形图分离实例
-
PCA Projection:基于主成分分析映射实例
-
Manifold Visualization:通过流形学习实现高维可视化
-
Feature Importances:基于模型性能对特征进行排序
-
Recursive Feature Elimination:按重要性搜索最佳特征子集
-
Scatter and Joint Plots:通过特征选择直接进行数据可视化
4.2 分类可视化
-
Class Balance:了解类别分布如何影响模型
-
Class Prediction Error:展示分类的误差与主要来源
-
Classification Report:可视化精度、召回率和 F1 分数的表征
-
ROC/AUC Curves:受试者工作曲线和曲线下面积
-
Confusion Matrices:类别决策制定的视觉描述
-
Discrimination Threshold:搜索最佳分离二元类别的阈值
4.3 回归可视化
-
Prediction Error Plots:沿着目标域寻找模型崩溃的原因
-
Residuals Plot:以残差的方式展示训练和测试数据中的差异
-
Alpha Selection:展示 alpha 的选择如何影响正则化
4.4 聚类可视化
-
K-Elbow Plot:使用肘法(elbow method)和多个指标来选择 k
-
Silhouette Plot:通过可视化轮廓系数值来选择 k
4.5 模型选择可视化
-
Validation Curve:对模型的单个超参数进行调整
-
Learning Curve:展示模型是否能从更多的数据或更低的复杂性中受益
4.6 文本可视化
-
Term Frequency:可视化语料库中词项的频率分布
-
t-SNE Corpus Visualization:使用随机近邻嵌入来投影文档
往期文章
数据及代码获取
公众号粉丝刚刚突破5000,开通了流量主。希望大家多多支持

