

更多干货内容请关注微信公众号“AI 前线”,(ID:ai-front)
搜索排序的传统方法是通过各种方法对商品进行打分,最后按照每个商品的分数进行排序。这样传统的搜索排序方法就无 法考虑到展示出来的商品之间相互的影响。类似地,传统的针对单个商品估计 ctr、cvr 的方法也都基于这样一个假设:商品 的 ctr、cvr不会受到同时展示出来的其他商品 (我们称为展示 context) 的影响。而实际上一个商品的展示 context 可以影响到 用户的点击或者购买决策:假如一个商品周边的商品都和它比较类似,但是价格却比它便宜,那么用户买它的概率不会 高;反之如果周边的商品都比它贵,那么用户买它的概率就会大增。
如果打破传统排序模型展示 context 没有影响的假设,该如何进行排序呢?为此,我们首次提出了一种考虑商品间相互影响的全局排序方法。我们将电商排序描述成一个全局优化问题,优化的目标是反应用户满意度的商品成交额:GMV(Gross Merchandise Volume)。准确地说,全局排序的优化目标是最大化 GMV 的数学期望。计算 GMV 的数学期望需要知道商品 的成交概率,而商品的成交概率是彼此相互影响的,因此我们又提出了考虑商品间相互影响的成交概率估计模型。
首先, 我们提出了一种全局特征扩展的思路,在估计一个商品的成交概率时,将其他商品的影响以全局特征的形式加入到概率估 计模型中,从而在估计时考虑到了其他商品的影响。然后,我们进一步提出了通过 RNN 模型来精确考虑商品的排序顺序对 商品成交概率的影响。通过使用 RNN 模型,我们将电商排序变成了一个序列生成的问题,并通过 beam search 算法来寻找 一个较好的排序。我们在淘宝无线主搜索平台上进行了大量的实验,相对于当时的淘宝无线主搜算法,取得了GMV 提升 5% 的效果。
全局排序阶段的输入是要排序的 N 个商品,输出则是 N 商品的排序结果。
我们用 S = (1, … , N) 表示基础排序输出的 top‑N 商品序列;O 表示 S 的全排列集合,o = (o1, … , oN ) ∈ O 表示 S 的一个排列;另外,用 di 表示商品 i 在排序 o 中的位置,即 odi = i;c(o, i) 表示商品 i 在排序 o 中的展示 contex 全局排序 t,具体定义后面会分情况讨论;
v(i) 表示商品 i 的价值。
我们将目标定义为本次搜索产生的 GMV,于是在给定 c(o, i) 的情况下,就有:
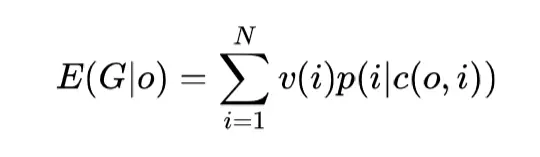
全局排序的最终目标就是找到一个期望收益最大的排序:
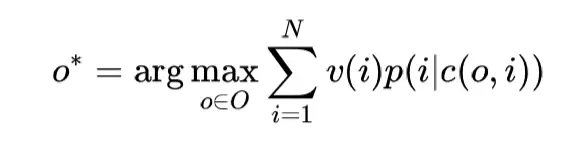
寻找这个最优排序需要解决两个问题:
问题 1. p(i|c(o, i)) 这个概率如何去准确地估计;
问题 2. 寻找 o∗是个组合优化的问题,暴力搜索的时间复杂度是 N! 的,需要找到合理高效的近似算法。
问题 1 是提高效果的关键,估计得越准,后面组合优化的效果越明显,反之则会导致第二步的组合优化没有意义。从理论上讲,c(o, i) = (o1, … , oN ) 是 i 的完整的展示 context,但是如果完整地考虑展示 context,问题 2 的组合优化复杂
度很难降低下来。为了能更高效求解问题 2,需要对 c(o, i) 进行适当地简化。根据对 c(o, i) 的简化程度,我们把全局排序模型分成了两类,分别在下面介绍。
电商搜索全局排序方法
第一类模型只利用展示 context 的商品集合信息,而不去深究真实的展示 context 的顺序,即 c(o, i) = S ∖ {i}。直观上理
解,第一类模型假设用户在判断是否购买商品 i 的时候,只记得他看过所有的商品集合 S,而不在意 S 中商品的出现顺序。
这种情况相当于用户知道自己的挑选集合,从中比较和挑选出最想购买的商品。我们将商品 i 本身的特征成为局部特征 fi,l。这时可以把商品 i 的局部特征 fi,l 与其他候选商品的局部特征进行比较,得到这个商品的特征与候选集合其他商品比较的结果,并且把这些比较的结果作为包含全局信息的特征加入到 p(i|c(o, i)) 的预测中。
以价格特征为例,我们会按照价格纬度对 S 排序,将商品 i 的价格位次均匀地归一化成 [0, 1] 之间的一个值(最贵的价格变成变成 1,最便宜的价格变成 0),这样 i 的价格特征就扩展出了i 的价格全局特征。
通过上述的方式可以对 fi,l 的每一维按照其位次扩展,得到相应的全局特征 fi,g,最终我们将局部和全局特征拼接起来作为考虑了展示 context 的商品 i 的特征 fi = (fi,l, fi,g)。这时展示 context 通过特征扩展而加入到模型中来,帮助模型预测成交概率 p(i|c(o, i))。
在第一类模型的假设下,问题 2 的组合优化就变得很简单了。商品集合是静态的,因此各个商品的成交概率能分别独立计算出来。
但是 DNN 计算出的 p(i|c(o, i)) 没有考虑到商品 i 的排序位次,应该根据根据 position bias 对 p(i|c(o, i)) 做一个修正,即 p(i|c(o, i))bias(di)。对于求解问题 2 来说,我们不需要具体知道 bias(di) 的值,只需要知道 bias 随着位置从前往后依次降低就可以了,因为这时只要按照 v(i)p(i|c(o, i)) 从高到低对商品进行排序,就一定能得到收益最大的排序。
第二类模型不仅仅考虑展示 context 的商品集合信息,还精确地考虑到排在 i 之前的商品的顺序。与第一类模型类似,展示 context 的商品集合信息还是通过扩展全局特征的方式加入到了每个商品的特征中,即 fi = (fi,l, fi,g)。但是与第一类模型不同,计算 p(i|c(o, i)) 时,第二类模型还考虑了排在 i 前面的真实顺序,即 p(i|c(o, i)) = p(i|o1, o2, . . . , odi−1),这样问题 1 变成了一个序列概率估计的问题,最直观的方法就是用 RNN 来计算 p(i|c(o, i))。
与第一类模型不同的是,由于我们考虑了排在 i 之前的商品的顺序,前面商品的排序变化会影响商品 i 的成交概率。这时就不能分别独立计算每个商品的收益了,因为商品 i 的收益要受到排在它前面的商品的影响;而在最终排序确定之前,无法知道商品 i 之前的排序是什么,而且我们的目标就是去确定这样一个最优的排序。同时,正是因为只考虑了排在 i 之前的商品顺序,使得我们可以从前往后一步一步地排序,每一步选择排在当前位置的商品。
为了便于理解,可以先看一种简单的情况:分位排序。
所谓分位排序是指在排序时先将收益最大的一个商品排到第一位,然后条件在第一个商品之上,重新计算剩余商品的收益,并选出收益最大的商品排到第二位,依次类推。很明显分位排序是一种贪婪的算法。beam search 算法可以理解为贪婪算法的扩展,beam search 在每一步搜索的时候会保留收益最大的 k 个序列,一直到最后一步,再返回最好的一个序列。
原始的 RNN 模型解决不好长距离依赖的问题:当我们计算第 20 个位置的商品成交概率时,排在头 4 位的商品几乎就没有任何影响了。而排在前面的商品由于是用户最先看到的,一般会有较深的印象,对后面商品的影响不应该被忽略。为了使模型有能力考虑到长距离和对排序位置的依赖,我们设计了一种新的 attention 机制加入到 RNN 的网络中。
通过这种引入 attention 并且加入位置 embedding 的方式,模型可以根据数据自动学习不同位置 attention 该如何调节以得到更好的预测结果。直观来看,模型的结构图如下:
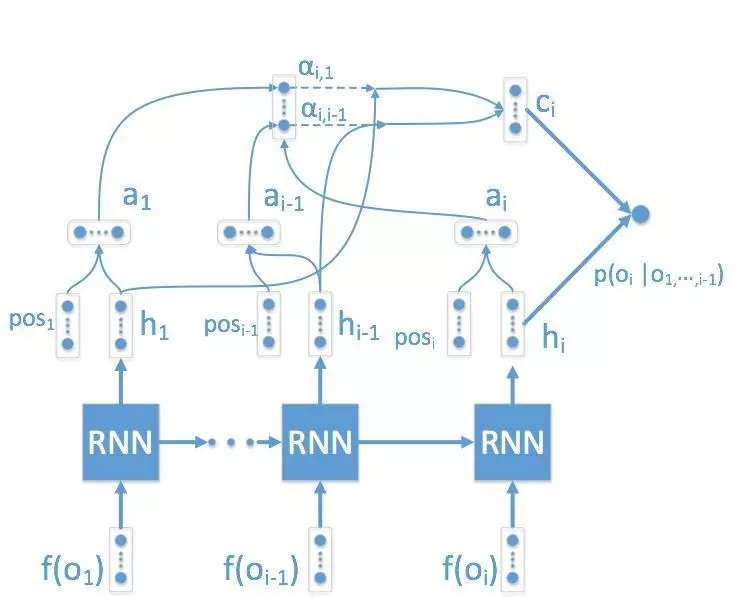
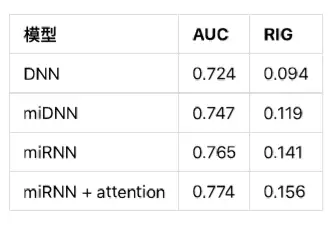
其中 DNN 是只使用 fi,l 作为特征的 baseline。reDNN 是使用全局特征 fi = (fi,l, fi,g) 的 DNN 全局排序模型,miRNN 是 RNN 全局排序模型,miRNN+attention 是增加了我们的 attention 机制的 RNN 模型。
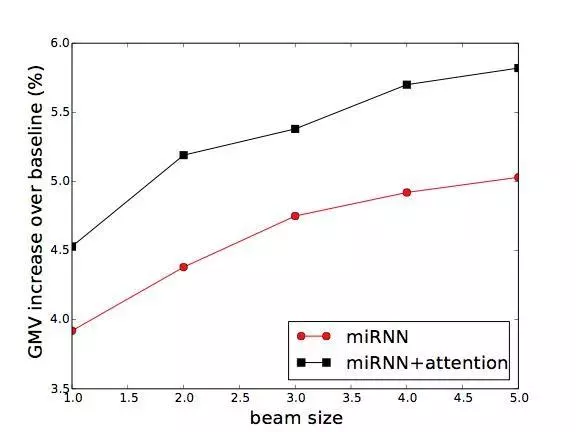
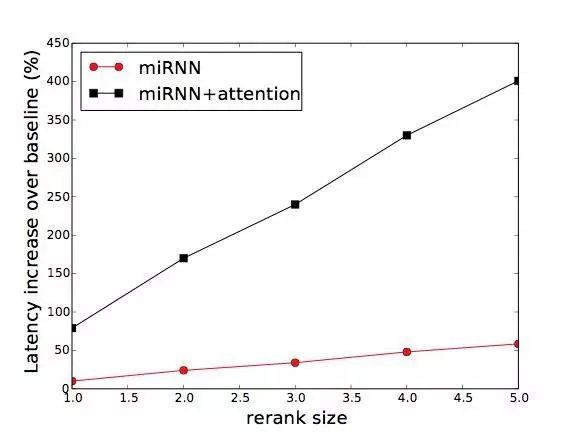
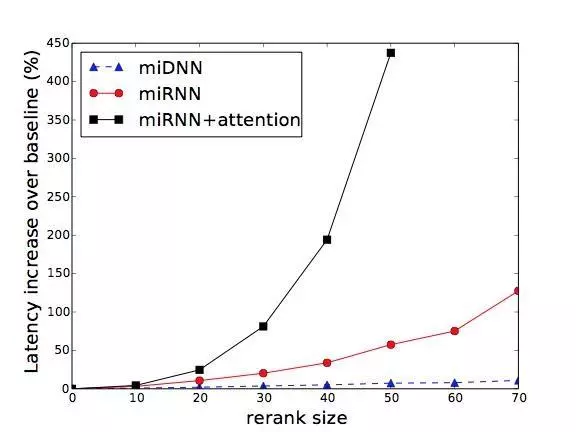
使用 miRNN 和 miRNN + attention 模型做排序,算法的时间分别是Θ(kN 2) 和Θ(kN 3),其中 N 是被排序的商品数,k 是 beam search 算法的 beam size 参数。对于淘宝搜索这样的大规模的搜索平台来说,这样的复杂度显然是太高了。
不过我们可以在 baseline 排序的基础上,只对排在最前面的 N 个商品进行排序,只要 N 取得不大,计算量就是可以承担的。同时,因为排在前面的商品对效果的影响最大,对这些商品重新排序的收益也比较大。
我们对比了不同 N 和 k 下,本文提出的各种全局排序方法的 GMV 增长(反应模型效果),搜索引擎 latency(反应计算负担)的增长曲线:
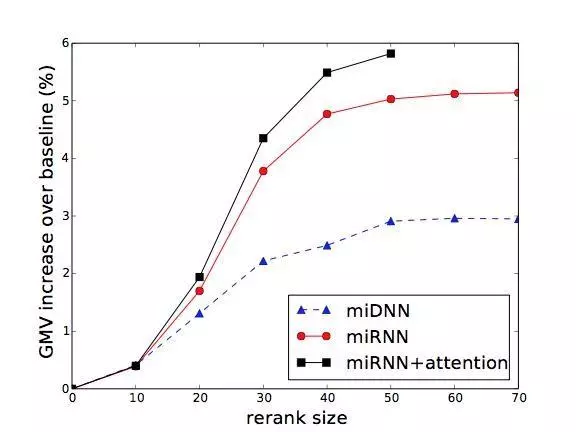
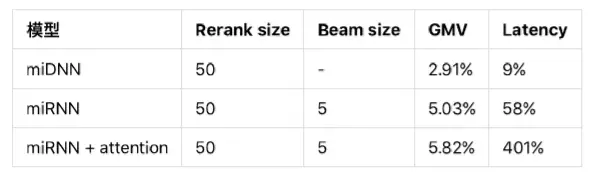
最终效果总结:GMV、搜索引擎 Latency 想对于 baseline DNN 的增长:
我们首次提出了考虑商品间相互影响的电商全局排序方法,并在淘宝主搜索上取得了明显的效果。目前最大的问题就是 RNN 的方法效果虽然更好一些,但是带来的计算负担太大,如何减少计算量将是重要的研究方向。
