

TensorFlow 是 Google 开发的一款用于机器学习的开源软件库。它能够在所有 Linux,Windows和 MacOS 平台上运行 CPU 和 GPU。Tensorflow 可用于设计,实现和训练深度学习模型。
今天我们就手把手教你如何使用 TensorFlow 搭建一个简单的神经网络,实现 TensorFlow 中的Hello World,只需七步,就能迅速入门。本文我们使用著名的鸢尾花(记住这个名字,以后你会经常遇到它)数据集来训练模型,然后让模型为给定的花朵正确分类。

鸢尾花数据集包含 3 种花,包括“山鸢尾”(Setosa),“杂色鸢尾”(Versicolor)和“维吉尼亚鸢尾”(Virginica)。为了识别每种花型,我们设定了 4 种花的属性,包括萼片长度,萼片宽度,花瓣长度和花瓣宽度。 我们下面会用 TensorFlow 搭建一个神经网络,让它根据这些因素正确识别出鸢尾花的种类。
我们下面会用 TensorFlow 搭建一个神经网络,让它根据这些因素正确识别出鸢尾花的种类。
首先,我们用训练数据集来训练我们的模型,然后我们会用测试数据集来测试其准确性。你可以从这里下载训练数据集,并在这里下载测试数据集。
第一步
首先,我们需要读取 .csv 文件中的数据并导入它们。Pandas 库可以很轻松处理这个问题。
Pandas 库中的 read_csv()函数将读取文件并将内容加载为指定的变量。对于函数的参数, 我们需要指定文件的路径,names 参数可以用来指定每个列的名字。

第二步
数据集中的花朵的类型都编码为 0,1 和 2。我们需要使用 one hot 方法将它们编码为 [1,0,0],[0,1,0] 和 [0,0,1]。这将使网络的训练和优化变得容易,因为网络的输出也是以 one hot 格式生成的。
然后我们需要定义训练集的 x,y 和测试集的 x,y。
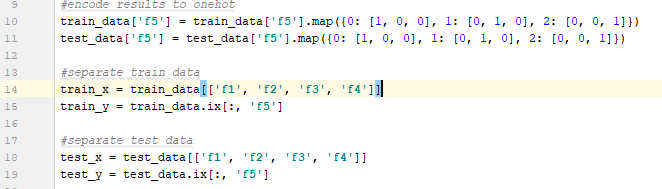
第三步
然后,它需要为输入(X),输出(Y)定义占位符,并定义网络的权重和偏差。这里我们有 4 列输入,因为数据集有 4 个特征和 3 列输出来映射 3 种类型的花。占位符的 shape 应该满足这一点。 此外,权重矩阵的 shape 必须是 4x3,而偏差必须是 3 的向量才能将输入映射到输出(无隐藏层)。

第四步
然后我们需要通过一个激活函数发送输出,这里可以用 Tensorflow 中的 soft-max 函数。为了该训练模型,我们需要计算模型的成本,也就是模型的输出中出现了多少错误,这里我们计算平均方差。然后我们可以训练模型,并使用 AdamOptimizer 降低成本。
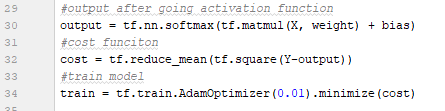
第五步
为了在培训后检查我们的模型是否准确,我们需要将我们的模型预测与实际结果进行比较。然后我们可以通过计算我们得到的正确结果来计算我们模型的准确性。

在此之后,我们需要开始训练模型。在此之前,我们首先需要使用 global_variables_initializer 函数初始化所有全局变量。
第六步
现在我们开始训练模型。每个 Tensor 执行必须在 Tensorflow 的会话中完成。因此,在训练之前我们需要创建一个会话,并且在完成所有工作后,我们需要关闭会话。

首先,执行初始化张量的变量,然后将模型训练 1000 次。训练时,我们需要指定训练数据集为 X,相应的结果为 Y,因为需要它们训练张量。这里在传递 Y 时,我们会迭代和创建一个新数组,以确保它的 shape 与上面定义的相同。在每次迭代中,将成本绘制成图形以便查看实际的训练效果。
第七步
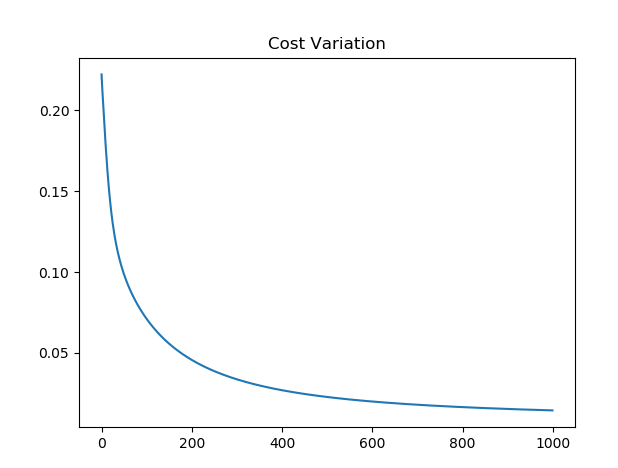
最后,当训练过程结束时,将成本变化图绘制出来并通过测试数据集测试模型的准确性。

经过 1000 次训练迭代后,可以获得 96.67% 的准确度,这个结果确实令人印象深刻,而成本变化图清楚的显示了每次迭代中减少成本后模型性能有了巨大改善。
本文能帮助 Tensorflow 的新手通过这个简单的例子来了解它的概念,从此开拓 TensorFlow 的星辰大海。
下面是本教程的全部 Python 代码,可以在免搭环境的集智主站自己敲一敲:
import tensorflow as tf
import pandas as pd
from matplotlib import pyplot as plt
#从CSV读取数据
train_data = pd.read_csv("iris_training.csv", names=['f1', 'f2', 'f3', 'f4', 'f5'])
test_data = pd.read_csv("iris_test.csv", names=['f1', 'f2', 'f3', 'f4', 'f5'])
#将数据编码为独热
train_data['f5'] = train_data['f5'].map({0: [1, 0, 0], 1: [0, 1, 0], 2: [0, 0, 1]})
test_data['f5'] = test_data['f5'].map({0: [1, 0, 0], 1: [0, 1, 0], 2: [0, 0, 1]})
#分离训练数据
train_x = train_data[['f1', 'f2', 'f3', 'f4']]
train_y = train_data.ix[:, 'f5']
#分离测试数据
test_x = test_data[['f1', 'f2', 'f3', 'f4']]
test_y = test_data.ix[:, 'f5']
#输入和输出的文件夹
X = tf.placeholder(tf.float32, [None, 4])
Y = tf.placeholder(tf.float32, [None, 3])
#权重和偏差
weight = tf.Variable(tf.zeros([4, 3]))
bias = tf.Variable(tf.zeros([3]))
#运行激活函数后的输出
output = tf.nn.softmax(tf.matmul(X, weight) + bias)
#cost funciton
cost = tf.reduce_mean(tf.square(Y-output))
#train model
train = tf.train.AdamOptimizer(0.01).minimize(cost)
#检查成功与否
success = tf.equal(tf.argmax(output, 1), tf.argmax(Y, 1))
#c计算准确率
accuracy = tf.reduce_mean(tf.cast(success, tf.float32))*100
#初始化变量
init = tf.global_variables_initializer()
#启动TensorFlow会话
with tf.Session() as sess:
costs = []
sess.run(init)
#训练模型1000次
for i in range(1000):
_,c = sess.run([train, cost], {X: train_x, Y: [t for t in train_y.as_matrix()]})
costs.append(c)
print("Training finished!")
#绘制代价图表
plt.plot(range(1000), costs)
plt.title("Cost Variation")
plt.show()
print("Accuracy: %.2f" %accuracy.eval({X: test_x, Y: [t for t in test_y.as_matrix()]}))
对于本文教程,谷歌此前发布过视频版,我们进行了译制,可以去集智主站上瞅瞅:戳这里。
新手福利
假如你是机器学习小白,但又希望能以最高效的方式学习人工智能知识,我们这里正好有个免费学习AI的机会,让你从零到精通变身AI工程师,不了解一下?
机会传送门:戳这里!!
这可能是正点赶上AI这班车的最好机会,不要错过哦。
