

一、机器学习介绍
计算机程序,不是通过人类直接指定的规则,而是通过自身运行,学习事物的规律,和事物间的关联。
计算机程序所能够处理,只有数值和运算。
计算机程序不过是一段存储在硬盘上的零一代码,运行时被读取进内存,CPU 根据代码转换成的指令来做一组特定的操作,让这些01数字通过逻辑电路进行若干运算后,生成计算结果。
要让一段程序了解客观世界变化万千的事物,则必须将这些事物数值化,将事物的变化和不同事物之间的关联转化为运算。
当若干现实世界的事物转换为数值之后,计算机通过在这些数值之上的一系列运算来确定它们之间的关系,再根据一个全集之中个体之间的相互关系,来确定某个个体在整体(全集)中的位置。
举例,我说“苹果”的时候,有些人首先想到的不是苹果,而是乔帮主创立的科技公司。
但是,我继续说:“苹果一定要生吃,蒸熟了再吃就不脆了。”——在这句话里,“苹果”一词确定无疑指的是水果,而不是公司。
因为在我们的知识库里,都知道水果可以吃,但是公司不能吃。出现在同一句话中的 “吃”对“苹果”起到了限定作用——这是人类的理解。
对于计算机, “苹果”被输入进去的时候,就被转化为一个数值 Va。
经过计算,这个数值和对应“吃”的数值 Ve 产生了某种直接的关联,而同时和 Ve 产生关联的还有若干数值,它们对应的概念可能是“香蕉”(Vb)、“菠萝”(Vp)、“猕猴桃”(Vc)……
那么据此,计算机就会发现 Va、Vb、Vp、Vc 之间的某些关联(怎么利用这些关联,就要看具体的处理需求了)。
- 说到数值,大家可能本能的想到 int、double、 float……但实际上,如果将一个语言要素对应成一个标量的话,太容易出现两个原本相差甚远的概念经过简单运算相等的情况。
假设“苹果“被转化为2,而“香蕉”被转化为4,难道说两个苹果等于一个香蕉吗?
因此,一般在处理时会将自然语言转化成 n 维向量。只要转化方式合理,规避向量之间因为简单运算而引起歧义的情况还是比较容易的。
1、机器学习步骤
如果要把小猫变成一个基于机器学习模型的(Model-Based) 计算机程序,猫妈妈该怎么做呢?
猫妈妈应该这样做,应该给小猫看一些照片,并告诉小咪咪,有些是老鼠,有些不是,比如下面这些:

然后小猫通过对比发现:老鼠的耳朵是圆的,别的动物要么没耳朵,要么不是圆形耳朵;老鼠都有尾巴,比的动物有的有,有的没有;老鼠的鼻子是尖的,别的动物不一定是这样。
然后小猫就用自己学习到的:“老鼠是圆耳朵,有尾巴,尖鼻子的动物”的信念去抓老鼠,那么小猫就成了一个“老鼠分类器”。
小猫(在此处类比一个计算机程序)是机器(Machine),它成为“老鼠分类器“的过程,就叫做学习(Learning)。
猫妈妈给的那些照片是用于学习的数据(Data)。
猫妈妈告知要注意的几点,是这个分类器的特征(Feature)。
学习的结果——老鼠分类器——是一个模型(Model)。这个模型的类型可能是逻辑回归,或者朴素贝叶斯,或者决策树……总之是一个分类模型。
小猫思考的过程就是算法(Algorithm)。
无论有监督学习,还是无监督学习,都离不开这三要素。
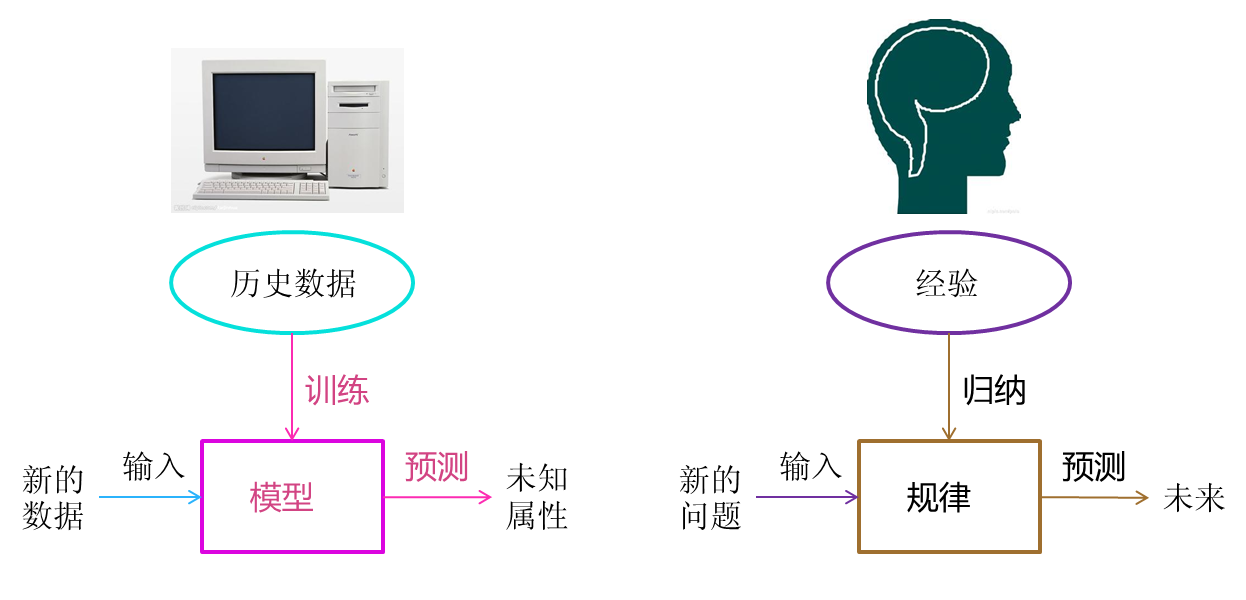
2、机器学习的过程与人类对历史经验归纳的过程
二、机器学习与人脸识别
计算机视觉=图像处理+机器学习。图像处理技术用于将图像处理为适合进入机器学习模型中的输入,机器学习则负责从图像中识别出相关的模式。
我们从人脸识别的例子中理解计算机视觉和机器学习之间的关系。
1、获取图片样本
计算机视觉需要用到大量的图片数据,除非自己本身有数据源,不然样本数据的来源就显得非常重要
(1)网络爬虫图片
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动的抓取万维网信息的程序或者脚本。
Python爬虫学习链接:http://python.jobbole.com/81332/
八爪鱼爬虫学习链接:http://www.bazhuayu.com/
(2)视频分解图片
从视频中可以获取大量的图片
import cv2
cap = cv2.VideoCapture("test.mp4")
# 获取一个视频打开cap 1 file name
isOpened = cap.isOpened
# 判断是否打开‘
print(isOpened)
fps = cap.get(cv2.CAP_PROP_FPS)
# 帧率
width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
# 获取宽度
height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
# 获取高度
print(fps,width,height)
i = 0
while(isOpened):
if i == 10:
break
else:
i = i+1
(flag,frame) = cap.read()
# 读取每一张 flag frame
fileName = 'image'+str(i)+'.jpg'
print(fileName)
if flag == True:
cv2.imwrite(fileName,frame,[cv2.IMWRITE_JPEG_QUALITY,100])
# 保存图片
print('end!')
结果:
<built-in method isOpened of cv2.VideoCapture object at 0x1136ce610>
29.008016032064127 540 960
image1.jpg
image2.jpg
image3.jpg
image4.jpg
image5.jpg
image6.jpg
image7.jpg
image8.jpg
image9.jpg
image10.jpg
end!
2、图像特征提取
图像特征提取三大算法:HOG特征,LBP特征,Haar特征
(1)HOG特征
方向梯度直方图(Histogram of Oriented Gradient, HOG)特征是一种在计算机视觉和图像处理中用来进行物体检测的特征描述子。它通过计算和统计图像局部区域的梯度方向直方图来构成特征。Hog特征结合 SVM分类器已经被广泛应用于图像识别中,尤其在行人检测中获得了极大的成功。需要提醒的是,HOG+SVM进行行人检测的方法是法国研究人员Dalal 在2005的CVPR上提出的,而如今虽然有很多行人检测算法不断提出,但基本都是以HOG+SVM的思路为主。
(2)LBP特征
LBP(Local Binary Pattern,局部二值模式)是一种用来描述图像局部纹理特征的算子;它具有旋转不变性和灰度不变性等显著的优点。它是首先由T. Ojala, M.Pietikäinen, 和D. Harwood 在1994年提出,用于纹理特征提取。而且,提取的特征是图像的局部的纹理特征;
(3)Haar特征
Haar特征分为三类:边缘特征、线性特征、中心特征和对角线特征,组合成特征模板。特征模板内有白色和黑色两种矩形,并定义该模板的特征值为白色矩形像素和减去黑色矩形像素和。Haar特征值反映了图像的灰度变化情况。例如:脸部的一些特征能由矩形特征简单的描述,如:眼睛要比脸颊颜色要深,鼻梁两侧比鼻梁颜色要深,嘴巴比周围颜色要深等。但矩形特征只对一些简单的图形结构,如边缘、线段较敏感,所以只能描述特定走向(水平、垂直、对角)的结构。
三大图像特征对比的详细介绍:http://dataunion.org/20584.html
2、opencv内置人脸分类器
opencv里面有内置的已经训练好的人脸分类器,但是仅限与对人脸进行检测,这里我们如果要训练自己的人脸识别分类器的话,要利用这个分类器进行检测和捕捉人脸,然后才能实现识别。
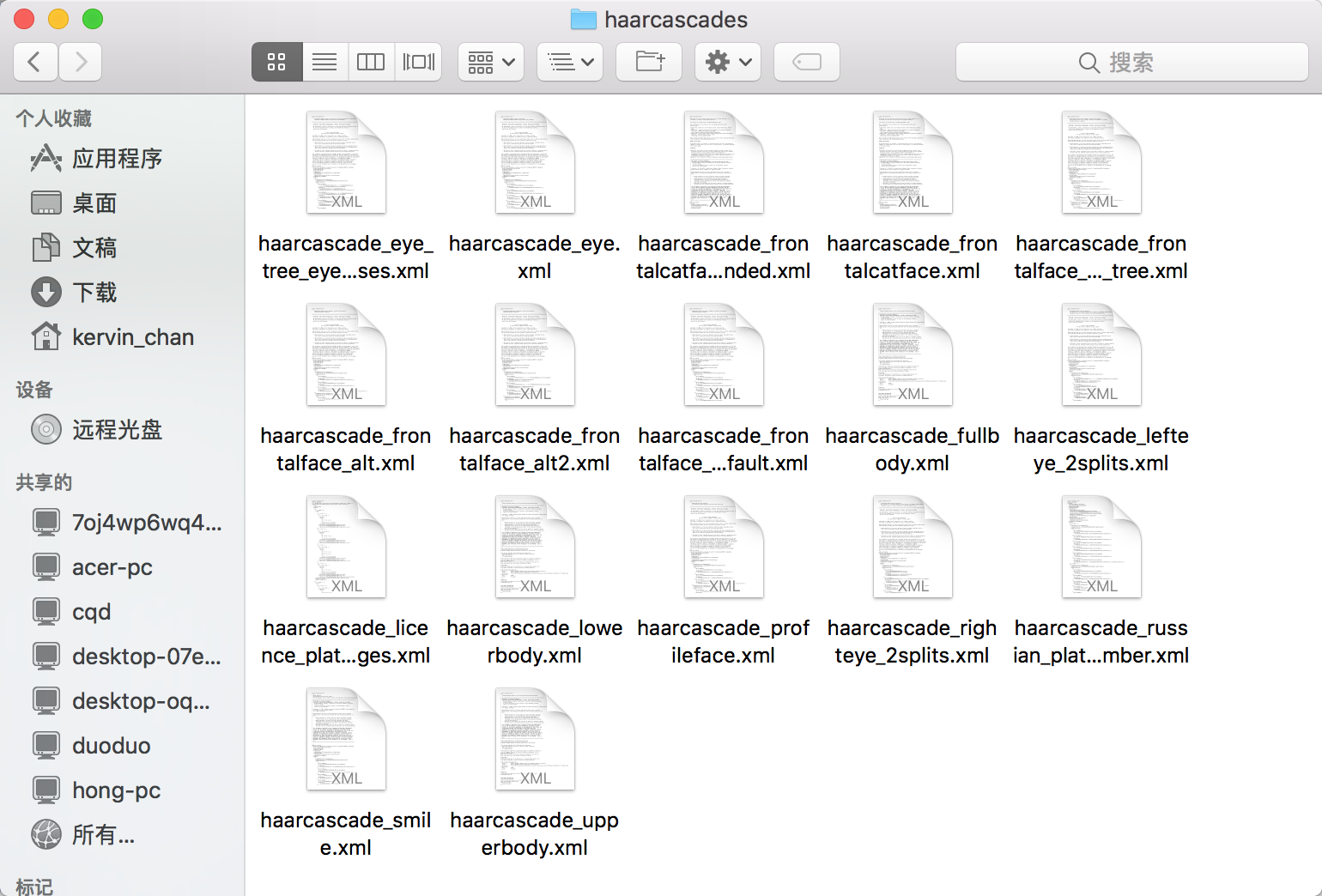
里面存放这各种已经训练好的分类器,有眼睛,人脸,左右眼等等。
