

编写目的
最近工作任务需要把原来使用Kettle的ETL流程迁移到Hadoop平台上,就需要找一个替代Kettle工作流部分的工具。在大数据环境下,常用的无非是Oozie,Airflow或者Azkaban。经过简单的评估之后,我们选择了轻量化的Airflow作为我们的工作流工具。
Airflow是一个工作流分配管理系统,通过有向非循环图的方式管理任务流程,设置任务依赖关系和时间调度。Airflow独立于我们要运行的任务,只需要把任务的名字和运行方式提供给Airflow作为一个task就可以。
安装流程
本次安装Airflow 1.8 ,而不是最新版的apache-airflow 1.9,主要原因是1.9版本的所有运行都是基于UTC时间的,这样导致在配置调度信息的时候不够直观。目前开发中的2.0版本已经可以设置本地时区,但是还没有公开发布。
系统准备
Python 3.5 :Anaconda 4.2环境
MySQL 5.6 :使用LocalExcutor模式,所有DAG信息保存在后端数据库中。
OS 用户:etl
创建数据库
后端使用MySQL数据库来保存任务信息,先在数据库中建立database和user。如下
create database airflow;
grant all privileges on airflow.* to 'airflow'@'%' identified by 'airflow';
flush privileges;
环境变量
Airflow在运行过程中会使用全局环境变量,所以必须先在~/.bash_profile 中增加变量如下
export AIRFLOW_HOME=/home/etl/airflow
安装airflow
使用pip安装airflow以及依赖的数据库驱动之后,需要进行初始化。这个过程会生成默认的配置文件ariflow.cfg,后续的配置修改就通过这个文件进行。
# 默认安装1.8版本,因为1.9版本的名字变成了apache-airflow
pip install airflow
# 因为需要连接MySQL数据库,所以需要安装驱动
pip install airflow[mysql]
# 初始化数据库,这一步是必须的,否则无法生成默认配置文件
airflow initdb
# 创建需要的文件夹,否则运行时会报错找不到默认文件夹
mkdir dags
mkdir logs
启用Web权限
默认情况下airflow的web管理台是没有用户密码的,在迁移到正式环境之前,我们需要启用权限机制。
在airflow.cfg中设置如下选项
[webserver]
authenticate = True
auth_backend = airflow.contrib.auth.backends.password_auth
启用权限之后,在第一次登录之前必须手动通过python REPL来设置初始用户
import airflow
from airflow import models, settings
from airflow.contrib.auth.backends.password_auth import PasswordUser
user = PasswordUser(models.User())
user.username = 'airflow'
user.email = 'airflow@xxx.com'
user.password = 'airflow'
session = settings.Session()
session.add(user)
session.commit()
session.close()
exit()
修改数据库连接
因为使用MySQL作为元数据库,所以还需要配置数据库的连接参数。在airflow.cfg中设置如下选项
[core]
executor = LocalExecutor
sql_alchemy_conn = mysql://airflow:airflow@192.168.100.57:3306/airflow?charset=utf8
更改数据库连接方式之后,需要重新执行一次初始化操作。
airflow initdb
其他参数修改
还有一些零散的配置不好归类,就统一记录在这里。
任务成功,失败或重试后发送邮件通知的配置
[email]
email_backend = airflow.utils.email.send_email_smtp
[smtp]
smtp_host = smtp.mxhichina.com
smtp_starttls = False
smtp_ssl = False
# Uncomment and set the user/pass settings if you want to use SMTP AUTH
smtp_user = bialert@xxx.com
smtp_password = ******
smtp_port = 25
smtp_mail_from = bialert@xxx.com
默认情况下,Web界面会把样例DAG都显示出来非常混乱。除了在数据库中删除样例DAG之外,也可以通过配置不显示这部分样例。
# 不显示样例DAG
load_examples = False
Airflow的catchup机制,会在你启动一个DAG的时候,把当前时间之前未执行的job依次执行一次。这个好处是可以把遗漏的调度任务进行补足,但是在很多时候我们并不需要这个特性。通过修改配置,可以禁止catchup,如下
[scheduler]
# 避免执行catchup,即避免把当前时间之前未执行的job都执行一次
catchup_by_default = False
WEB管理
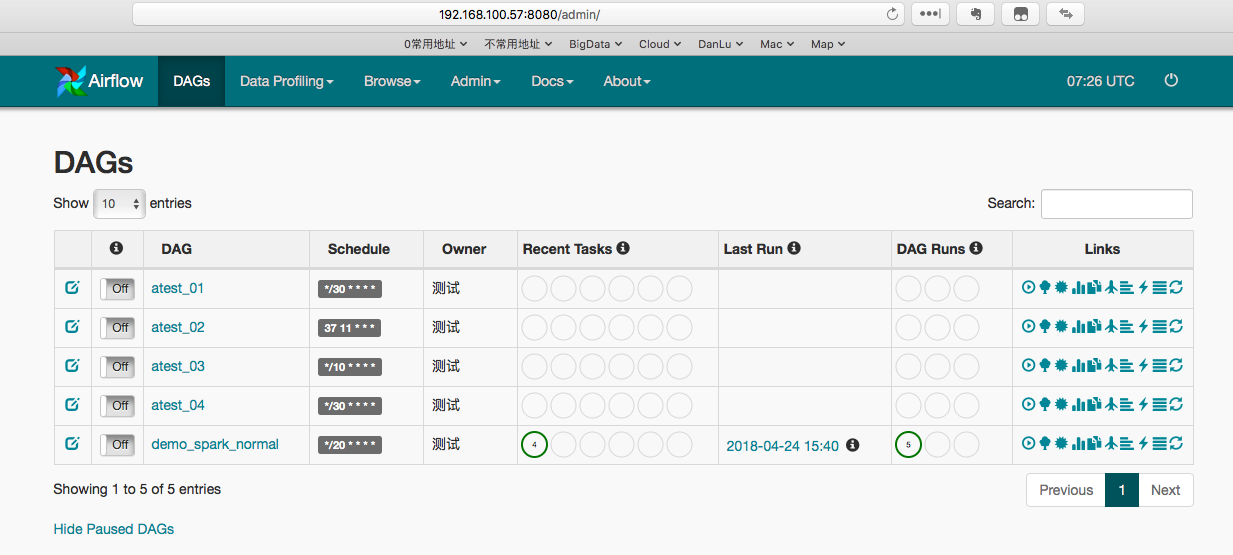
WEB界面
在默认的8080端口页面上,可以对DAG进行日常操作,包括但不限于启动,停止,查看日志等。界面如下图
管理脚本
当前版本Airflow没有提供关闭脚本,也没有提供一个便捷的办法来彻底删除DAG。为了方便测试,我写了一个管理脚本来处理相关的任务。
脚本调用方式如下
$ ./airflow_util.py -h
usage: airflow_util.py [-h] [-k] [-s] [--clear CLEAR] [--delete DELETE]
optional arguments:
-h, --help show this help message and exit
-k, --kill 关闭Airflow
-s, --start 启动Airflow
--clear CLEAR 删除历史日志
--delete DELETE 提供需要删除的DAG ID
管理脚本源代码如下
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import argparse
import pymysql
import subprocess
import time
#连接配置信息
config = {
'host':'127.0.0.1',
'port':3306,
'user':'airflow',
'password':'airflow',
'db':'airflow',
'charset':'utf8',
}
# 删除历史日志
def clear_log(num):
print("Clear logs before {0} days ...".format(num))
cmd = "find %s -maxdepth 1 -type d -mtime +%d | xargs -i rm -rf {}"
subprocess.call(cmd % ('./logs',num), shell=True)
subprocess.call(cmd % ('./logs/scheduler',num), shell=True)
# 通过杀掉后台进程来关闭Airflow
def kill_airflow():
print("Stoping Airflow ...")
# exclude current file in case the file name contains keyword 'airflow'
cmd = "ps -ef | grep -Ei 'airflow' | grep -v 'grep' | grep -v '%s' | awk '{print $2}' | xargs -i kill -9 {}" % (__file__.split('/')[-1])
subprocess.call(cmd, shell=True)
# 启动Airflow
def start_airflow():
kill_airflow()
time.sleep(3)
print("Starting Airflow Webserver ...")
subprocess.call("rm logs/webserver.log", shell=True)
subprocess.call("nohup airflow webserver >>logs/webserver.log 2>&1 &", shell=True)
print("Starting Airflow Scheduler ...")
subprocess.call("rm logs/scheduler.log", shell=True)
subprocess.call("nohup airflow scheduler >>logs/scheduler.log 2>&1 &", shell=True)
# 删除指定DAG ID在数据库中的全部信息。
# PS:因为SubDAG的命名方式为 parent_id.child_id ,所以也会把符合这种规则的SubDAG删除!
def delete_dag(dag_id):
# 创建连接
connection = pymysql.connect(**config)
cursor = connection.cursor()
sql="select dag_id from airflow.dag where (dag_id like '{}.%' and is_subdag=1) or dag_id='{}'".format(dag_id, dag_id)
cursor.execute(sql)
rs = cursor.fetchall()
dags = [r[0] for r in rs ]
for dag in dags:
for tab in ["xcom", "task_instance", "sla_miss", "log", "job", "dag_run", "dag_stats", "dag" ]:
sql="delete from airflow.{} where dag_id='{}'".format(tab, dag)
print(sql)
cursor.execute(sql)
connection.commit()
connection.close()
#
def main_process():
parser = argparse.ArgumentParser()
parser.add_argument("-k", "--kill", help="关闭Airflow", action='store_true')
parser.add_argument("-s", "--start", help="启动Airflow", action='store_true')
parser.add_argument("--clear", help="删除历史日志", type=int)
parser.add_argument("--delete", help="提供需要删除的DAG ID")
args = parser.parse_args()
if args.kill:
kill_airflow()
if args.start:
start_airflow()
if args.clear:
clear_log(args.clear)
if args.delete:
delete_dag(args.delete)
if __name__ == '__main__':
main_process()
编写DAG
原生Airflow的工作流通过简单的python脚本来进行定义(有一些第三方扩展可以实现拖放模式的定义)。
普通DAG
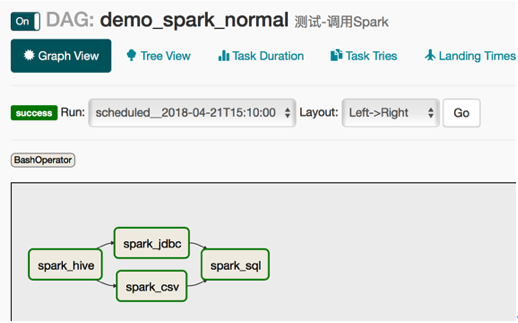
对于task不是特别多的场景,把所有task都定义在同一个py文件里面即可。如下,定义了4个task
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import airflow
from airflow.models import DAG
from airflow.operators.bash_operator import BashOperator
from datetime import timedelta, datetime
template_caller = "sh /home/etl/jupyter_home/etl_script/spark_scheduler/subdir/caller_spark.sh -m {0} -f {1} "
template_file = '/home/etl/jupyter_home/etl_script/spark_scheduler/subdir/{0}'
default_spark_master = 'spark://192.168.100.51:7077'
#-------------------------------------------------------------------------------
default_args = {
'owner': '测试',
'depends_on_past': False,
'start_date': datetime(2018,4,24,14,0,0),
'email': ['xxx@xxx.com'],
'email_on_failure': True,
}
#-------------------------------------------------------------------------------
dag = DAG(
'demo_spark_normal',
default_args=default_args,
description='测试-调用Spark',
schedule_interval='*/20 * * * *')
#-------------------------------------------------------------------------------
# spark operator
cmd = template_caller.format(default_spark_master, template_file.format('hive_rw.ipynb'))
t1 = BashOperator( task_id='spark_hive', bash_command=cmd , dag=dag)
cmd = template_caller.format(default_spark_master, template_file.format('jdbc_rw.ipynb'))
t2 = BashOperator( task_id='spark_jdbc', bash_command=cmd , dag=dag)
cmd = template_caller.format(default_spark_master, template_file.format('csv_relative.py'))
t3 = BashOperator( task_id='spark_csv', bash_command=cmd , dag=dag)
cmd = template_caller.format(default_spark_master, template_file.format('pure_sql.sql'))
t4 = BashOperator( task_id='spark_sql', bash_command=cmd , dag=dag)
#-------------------------------------------------------------------------------
# dependencies
t1 >> t2 >> t4
t1 >> t3 >> t4
SubDAG
当一个工作流里面的task过多,UI显示会比较拥挤,这种场景下可以通过把task分类到不同SubDAG中的办法来实现。在具体编写上,又可以分为单一py文件和多个py文件的方案。
单一文件
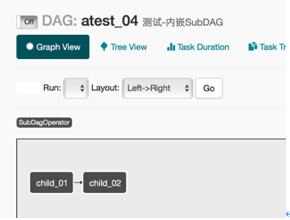
这种情况下,我们把DAG和SubDAG都写在一个py文件里面。优点是只有一个文件易于编写,缺点是如果task比较多的话,文件不易管理。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from datetime import datetime, timedelta
from airflow.models import DAG
from airflow.operators.subdag_operator import SubDagOperator
from airflow.operators.bash_operator import BashOperator
from datetime import datetime
PARENT_DAG_NAME = 'atest_04'
#CHILD_DAG_NAME = 'child_dag'
default_args = {
'owner': '测试',
'depends_on_past': False,
}
main_dag = DAG(
dag_id=PARENT_DAG_NAME,
default_args=default_args,
description='测试-内嵌SubDAG',
start_date=datetime(2018,4,21,16,0,0),
schedule_interval='*/30 * * * *'
)
# Dag is returned by a factory method
def sub_dag(parent_dag_name, child_dag_name, start_date, schedule_interval):
dag = DAG(
'%s.%s' % (parent_dag_name, child_dag_name),
schedule_interval=schedule_interval,
start_date=start_date,
)
t1 = BashOperator(
task_id='print_{}'.format(child_dag_name),
bash_command='echo sub key_{} `date` >> /home/etl/airflow/test.log'.format(child_dag_name),
dag=dag)
return dag
#
sub_dag_1 = SubDagOperator(
subdag=sub_dag(PARENT_DAG_NAME, 'child_01', main_dag.start_date, main_dag.schedule_interval),
task_id='child_01',
dag=main_dag,
)
sub_dag_2 = SubDagOperator(
subdag=sub_dag(PARENT_DAG_NAME, 'child_02', main_dag.start_date, main_dag.schedule_interval),
task_id='child_02',
dag=main_dag,
)
#
sub_dag_1 >> sub_dag_2
多个文件
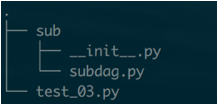
当SubDAG比较多的场景下,把DAG文件保存在独立的py文件中是一种更好的方法。文件目录结构如下
主文件如下
PS:因为在airflow中调用其他文件的过程中会出现找不到model的错误,所以在主文件中增加了一句处理路径的语句。如果有更好的办法,可以对这个进行替换。
sys.path.append(os.path.abspath(os.path.dirname(__file__)))
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import sys, os
sys.path.append(os.path.abspath(os.path.dirname(__file__)))
from datetime import datetime, timedelta
from airflow.models import DAG
from airflow.operators.subdag_operator import SubDagOperator
from datetime import datetime
from sub.subdag import sub_dag
PARENT_DAG_NAME = 'atest_03'
CHILD_DAG_NAME = 'child_dag'
default_args = {
'owner': '测试',
'depends_on_past': False,
}
main_dag = DAG(
dag_id=PARENT_DAG_NAME,
default_args=default_args,
description='测试-独立SubDAG',
start_date=datetime(2018,4,14,19,0,0),
schedule_interval='*/10 * * * *',
catchup=False
)
sub_dag = SubDagOperator(
subdag=sub_dag(PARENT_DAG_NAME, CHILD_DAG_NAME, main_dag.start_date,
main_dag.schedule_interval),
task_id=CHILD_DAG_NAME,
dag=main_dag,
)
子文件如下
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from airflow.models import DAG
from airflow.operators.bash_operator import BashOperator
# Dag is returned by a factory method
def sub_dag(parent_dag_name, child_dag_name, start_date, schedule_interval):
dag = DAG(
'%s.%s' % (parent_dag_name, child_dag_name),
schedule_interval=schedule_interval,
start_date=start_date,
)
t1 = BashOperator(
task_id='print_1',
bash_command='echo sub 1 `date` >> /home/etl/airflow/test.log',
dag=dag)
return dag
Schedule和Trigger
在DAG上,任务的触发由两个主要参数定义,start_date 和 schedule_interval 。一个DAG第一次被触发的时间点是 start_date + schedule_interval。举例如下:
start_date 2018-04-20 14:00:00
schedule_interval */30 * * * *
那第一次触发会在14:30发生,但是执行的是14:00的任务。根据激活DAG时间的不同,会发生不同的触发。
- 如果激活时间还不到第一次触发时间(如14:10激活),那第一次触发在14:30会准时进行。
- 如果激活时间超过第一次触发(如15:40激活),那根据catchup=True配置,会发生多次backfill操作,即把所有空缺的部分进行依次触发,具体就是14:00, 14:30, 15:00这几次任务。为啥最后一次不是15:30?因为在15:30这个时间点执行的其实是15:00的那一次任务。
- 如果激活时间超过第一次触发(如15:40激活),那根据catchup=False配置,会把空缺的最后一次进行触发。
综上,如果希望每30分钟触发一次,并且第一次触发发生在14:00,那么设置的start_date就应该是 13:30:00,这样在14:00的时候,就会触发第一次任务。
附录
修改默认日志级别
在1.8版本中,不能直接通过cfg文件来配置LOGGING LEVEL,所以采用修改源码的方式实现这个功能。
PS:在1.9之后的版本中,据说可以直接进行配置,我没有测试。
vi /opt/anaconda3/lib/python3.5/site-packages/airflow/settings.py
# 修改此处代码,把默认的INFO修改成WARN即可
LOGGING_LEVEL = logging.WARN
