

之前有不少人做过分析红楼梦前后是否为同一人所写,自己也想做个实现, 通过监督与非监督的方法来做个判断。
预处理
首先将红楼梦的txt文本保存在 datasets目录下。
提示:我用的mac os系统,当发现打不开txt文本或者python读取失败, 是编码的问题。
我的解决方案:用浏览器打开 txt文本,复制。在vscode或者任意编辑器下新建文件,粘贴保存即可。
import os
import numpy as np
import pandas as pd
import re
import sys
import matplotlib.pyplot as plt
下面是对txt文本的预处理,将全部文本分为120章节,保存为csv文件,代码如下:
def text2csv():
with open("./datasets/hongloumeng.txt", "r") as f:
text = f.read()
reg = "第[一二三四五六七八九十百]+回"
l = re.split(reg, text)
l = [i for i in l if len(i) > 200]
index = range(1, 121)
result = pd.DataFrame({
"id":index,
"text":l
})
result.to_csv('./datasets/hongloumeng.csv', index=False)
text2csv()
简单解释: 首先读取全部文本,用正则表达式reg匹配章节,切分章节回, 去除内容小于200字的章节,最后为120章节,保存为csv文件。 提示:在spilt过程中,章节内容中也会出现匹配情况,全本搜索找到内容中的相关匹配项,删除即可。
提取关键字
text = pd.read_csv("./datasets/hongloumeng.csv")
首先是读取csv文件。
下面使用python的第三方库jieba分词, 基于tf-idf算法进行关键字提取。
tf-id:阮一峰
对该算法的理解可以参考上述博客,大概有3篇文章, 简单易懂。
import jieba
import jieba.analyse
vorc = [jieba.analyse.extract_tags(i, topK=1000) for i in text["text"]]
vorc = [" ".join(i) for i in vorc]
简单解释: 第3行:使用算法对每个章节中最关键的1000个词进行关键词提取。 第4行:由于后续处理词向量的格式时空格加关键词, 所以进行简单转换。
# 查看第一章关键词
vorc[0]
输出如下:
'士隐 雨村 道人 那僧 那僧道 丫鬟 蠢物 世人 封肃 英莲 弟子 红尘 下世 那道人 意欲 一段 空空 不知 神仙 二人 故事 甄家 风流 风月 那僧笑 忘不了 此石 补天 无材 一僧 仙师 满纸 有个 警幻 自谓 这日 凡心 甄士隐 朝代 女子 石头记 贾雨村 富贵 入世 忽见 原来 小童 仙子 历来 不过 如此 安身 不觉 家人 晚生 石头 年纪 而已 功名 再者 离合悲欢 何方 心中 明白 神瑛侍者 卖字 只得 如今 便是 六千五百 来历 了结 女儿 几个 老先生 因见 粗蠢 适闻 之德 这石 知是 之族 适趣 子建 有处 永昼 珠草 罕闻 一闻 因笑 看时 街前 方欲 口内念 心下 时飞 中来 之句 二字 因思 霍启 你解 解得切 说些 不尽 文君 有些 跛足 葫芦 书房 青埂峰 一块 无稽 二仙 太虚幻境 可贺 些须 小解 岳丈 不可 只有 不惑 灌溉 折变 善哉 有意 半世 便携 封氏 未闻 说道 和尚 不可胜数 何敢 一日 回来 一绝 昌明 田庄 投胎 野史 闺阁 自便 仕宦 不曾 太爷 之事 佳节 其中 言词 美玉 荣华富贵 趁此 解闷 父母 儿孙 过去 谈笑 冤家 进去 起身 甘露 衣食 一道 风尘 黄道 团圆 早已 知己 街坊 抱负 玄机 啼哭 荒山 日日 字迹 趣味 人氏 失落 听见 自己 之苦 只是 出来 长叹 及至 三万 施礼 经历 诗词 中秋 只见 踪影 一二 幸而 荒唐 此案 隔壁 前人 进京 繁华 不能 大半 一味 传奇 半夜 想来 日 .......'
生成词向量
下面使用sklearn中的CountVectorizer对上述提取的关键词生成词向量。
python代码实现可以参考我之前写的博客 机器学习之贝叶斯分类
其中简单介绍了如何构建词集或者词袋模型,生成词向量。
代码如下:
from sklearn.feature_extraction.text import CountVectorizer
vertorizer = CountVectorizer(max_features=5000)
train_data_features = vertorizer.fit_transform(vorc)
简单解释: 首先生成5000个特征的vertorizer, 对vorc进行训练转换, 得到120个词向量。
接着转为array形式,进行聚类。
train_data_features = train_data_features.toarray()
train_data_features.shape
# (120, 5000)
非监督聚类分析
这里做个假设:假定红楼梦前后不是一个人所写,那么用词方面也会有区别。通过聚类算法,如果得到的结果有明显的界限, 那么可以进行初步判断。下面是我的可视化过程: 代码如下:
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=2, random_state=0).fit(train_data_features[0:120])
print(kmeans.labels_)
X = range(1, len(train_data_features) + 1)
Y = kmeans.labels_
plt.plot(X, Y, "o")
plt.plot([80,80], [0, cluster], "-")
简单解释:首先使用kmeans聚类算法,k=2分为两类,打印其类别。基于先前的假设,后四十回为高鹗缩写,因此在80回有明显的区分。 下面看结果:
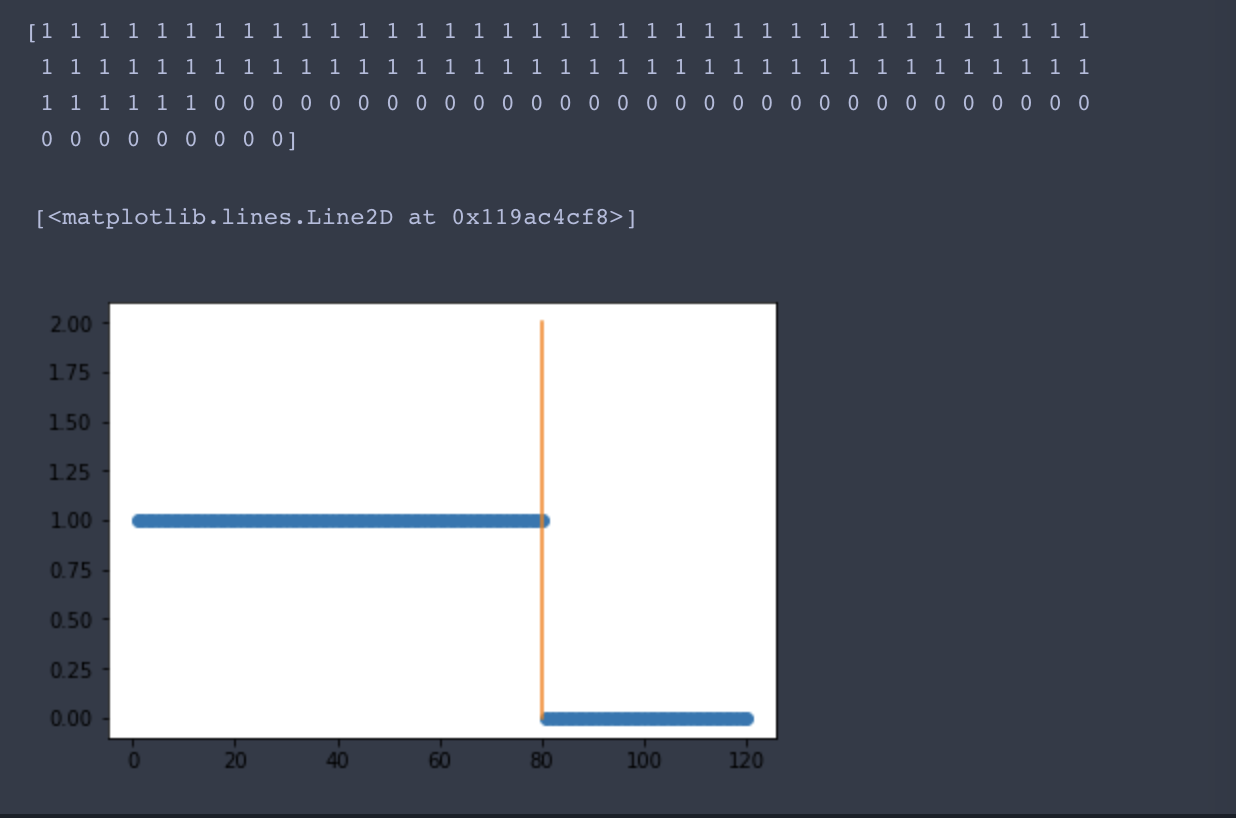
可以看到前80回和后四十回有明显的区分,为了加强验证,可以将k设为不同的值,进行横向对比。 如下:
cluster = 8
f = plt.figure(figsize=(20, 5))
for i in range(3, cluster + 1):
subplot = "1" + str(cluster) + str(i)
kmeans = KMeans(n_clusters=i, random_state=0).fit(train_data_features[0:120])
X = range(1, len(train_data_features) + 1)
Y = kmeans.labels_
ax = f.add_subplot(subplot)
plt.plot(X, Y, "o")
plt.plot([83,83], [0, cluster], "-")
可视化结果如下:
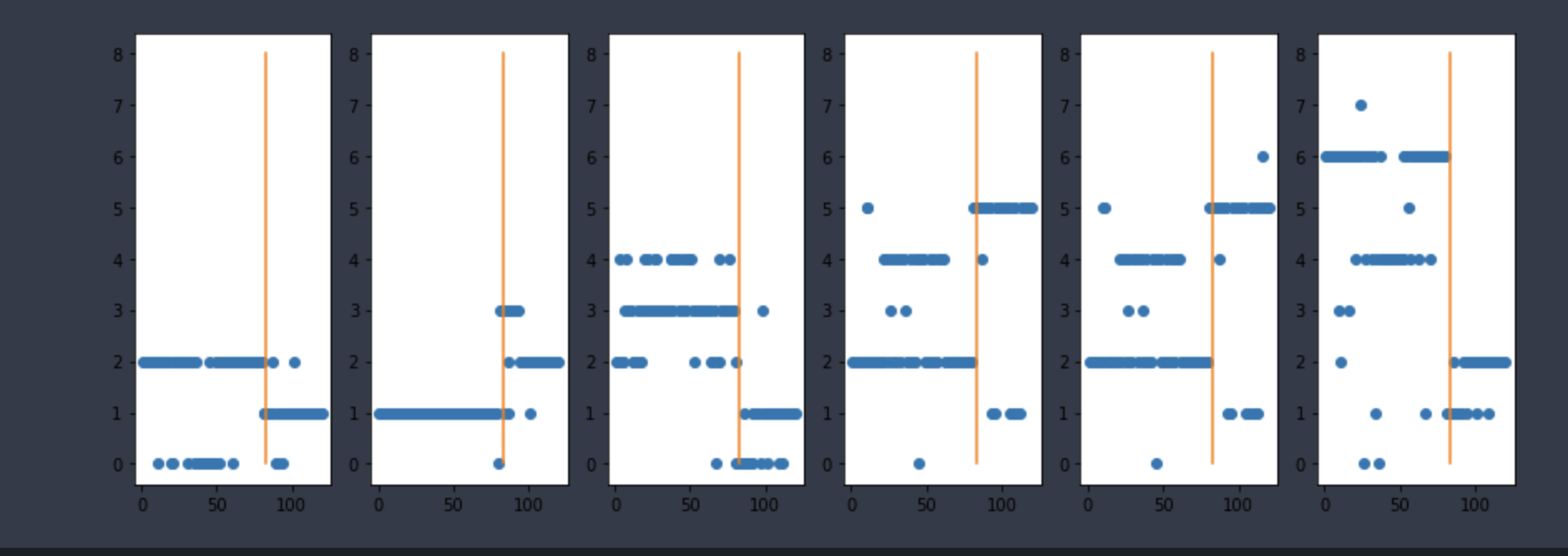
简单解释:
k分为为3, 4, 5, 6 ,7, 8。
首先查看第一图,每一行的点表示分为同一类,可以看到同三类。可以看到后四十回中有少量的章节被分为0,2类,但是大部分还是归为一类,这就表示后十四回的行文风格与前80回有不同。
第二图是分为4类的情况,后面也基本得到类似的情况。
基于以上分析及横向比较,可以初步推断前80回合和后80回不是同一个人所写。
简单做个验证
提出疑问:是否因为情节的变化,导致用词习惯,频率有所差异。 这里使用其他两部名著三国演义和水浒传来做个纵向对比。文本预处理,词向量生成都是一样的。具体可看我写的代码。最后的可视化结果如下: 首先是三国演义:
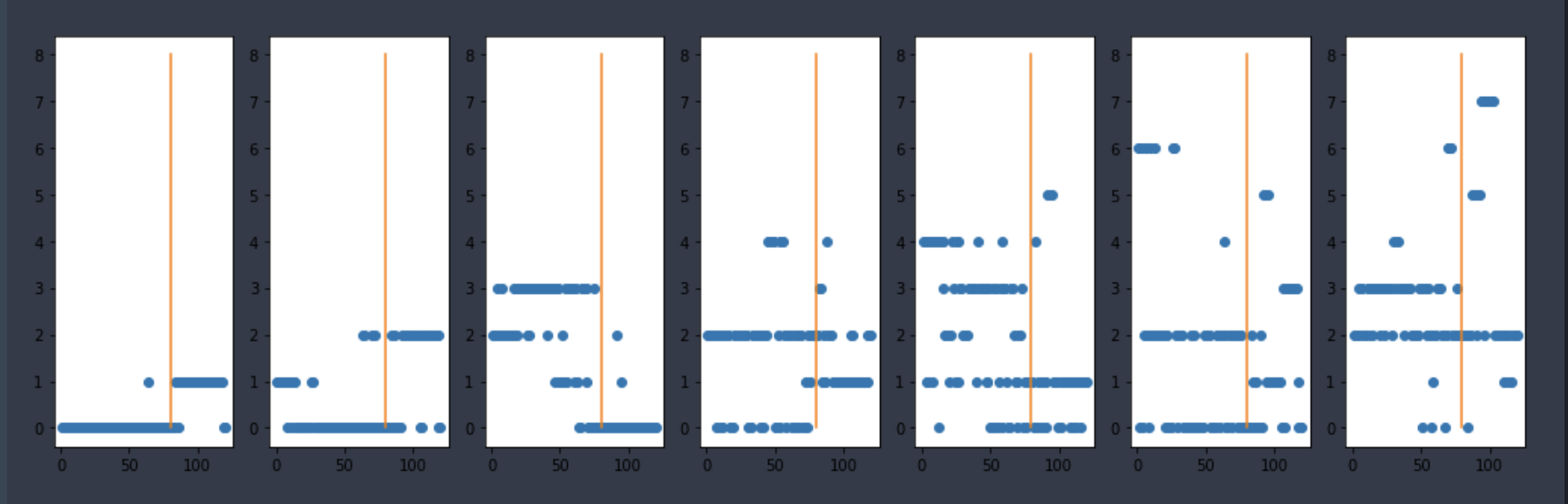
水浒传的结果:
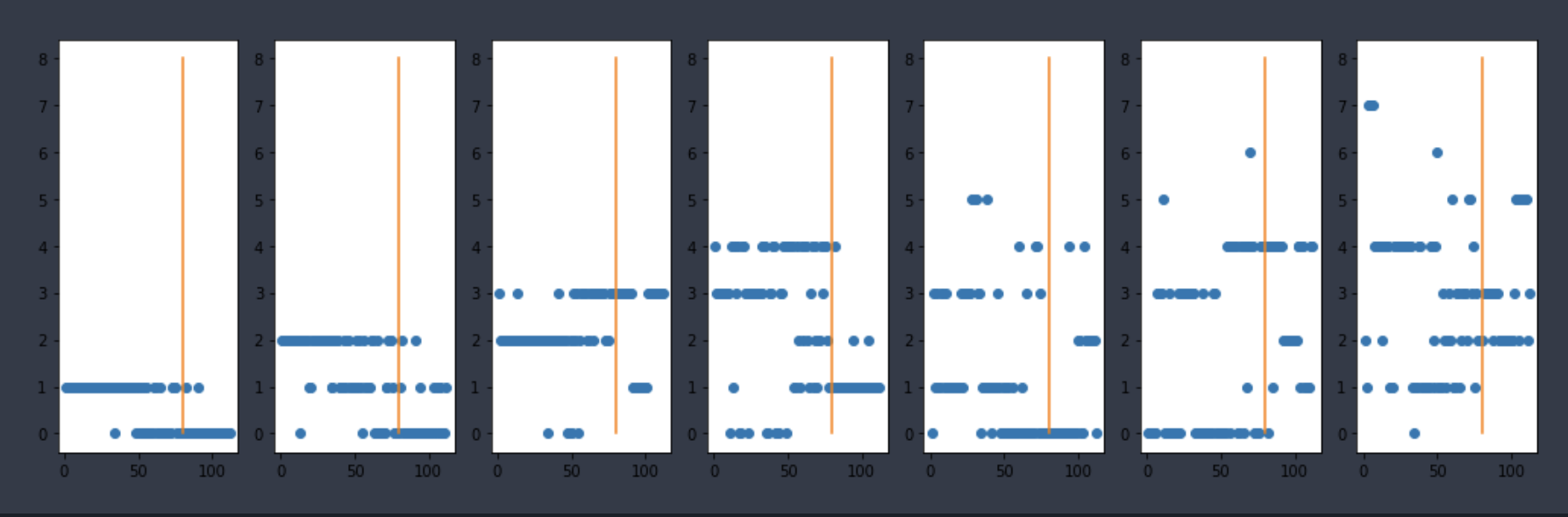
可以做自己的判断。
后面会写一篇文章介绍贝叶斯, 也是用于红楼梦作者判断,内容跟之前给出的链接差不多,类似于情感分析。
总结
- 文本预处理
- jieba tf-idf 算法分词
- 词向量生成
- kmeans聚类算法
