

Puppeteer测试
简介:
Puppeteer 是一个 node 库,提供了一组用来操作 chrome 的 API, 一个 headless chrome (ui界面可配置)。 需要支持async, await 官方也提倡使用ES7标准
运行环境:
node >= v7.6.0
npm i puppeteer -S
API地址:
https://github.com/GoogleChrome/puppeteer
实例介绍
本次测试基于express 框架的基础上 所用到的npm包如下:
- express
- puppeteer
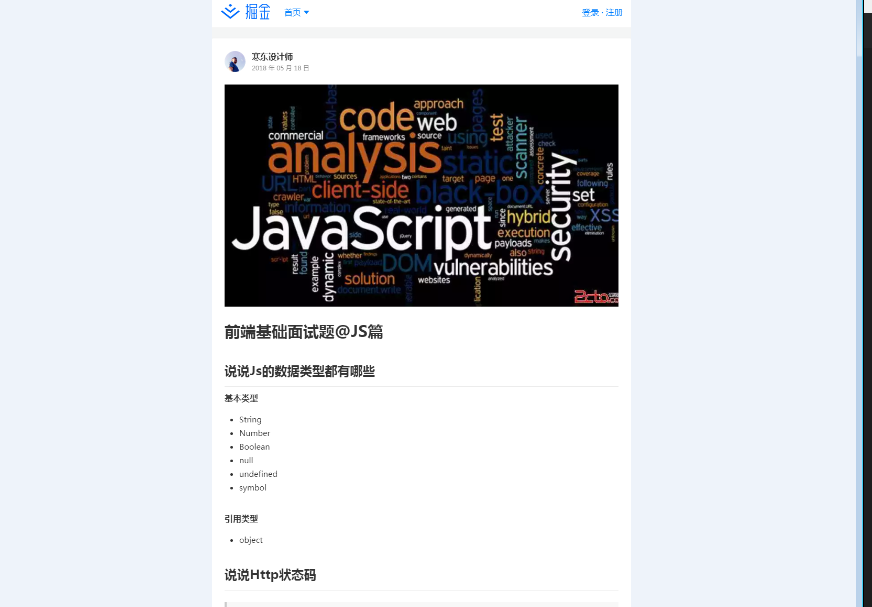
案例1:打开掘金文章并截图
前提条件:express 基本的了解和使用
app.get('/', function (req, res) {
(async ()=>{
const browser = await (puppeteer.launch({
timeout: 15000,
ignoreHTTPSErrors: true,
devtools: false,
headless: true
}));
const page = await browser.newPage();
await page.goto('https://juejin.cn/post/6844903607368679437');
await page.screenshot({
path:'photo/juejin.png',
type:'png',
fullPage : true
});
// res.send(JSON.stringify(list));
browser.close();
})()
})
大家也注意到了的开篇写的puppeteer 的写法是ES7的标准 其实 promise.then的写法很丑 所以说想研究的朋友还是用ES7的好
上述文本中的 puppeteer.launch 函数 用来运行puppeteer并创建一个bowswer的实例对象,可传options (具体参数参照官网api)
borwser.newPage()函数作用就是创建一个page实例用来访问我们的url地址,这里我给的是掘金的一篇文章 page.goto(url) 函数的作用就是访问当前的url地址
screenshot 函数的作用就是截图 options 主要有 path、type、fullPage 等等 就不一一介绍了。很轻松的就完成了截图的操作,是不是觉得很简单。headless chrome 与其他几个不同 它的逻辑操作是用户,而PhantomJS 、webdriver都是从程序角度出发的,所以说前端用起来会更顺手。
下面是案例截图:
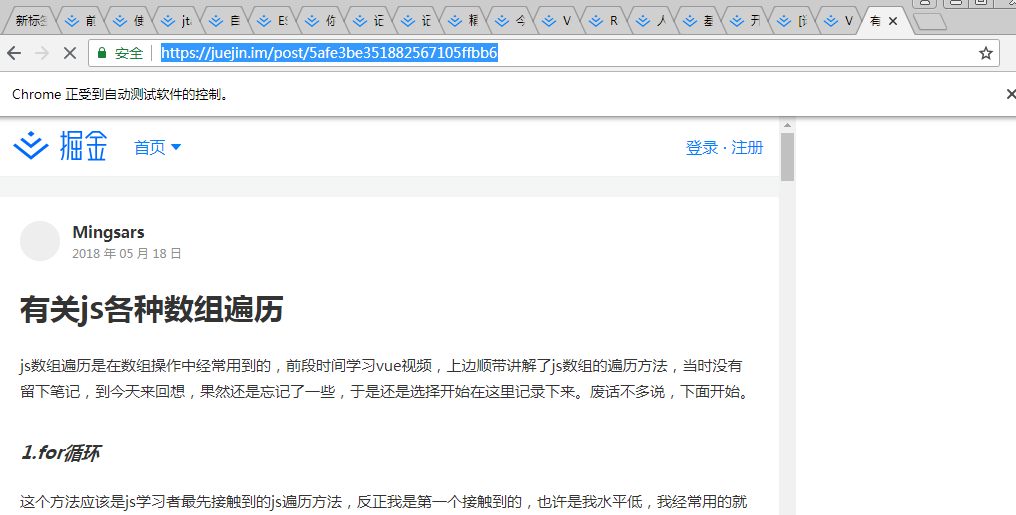
案例2:获取掘金前端板块列表中最新的文章数据
app.get('/juejin',function(req,res){
(async ()=>{
console.log(new Date());
let browser = await puppeteer.launch({
timeout:15000,
headless:false,
ignoreHTTPSErrors:true
});
let page = await browser.newPage();
let arr = [];
await page.goto('https://juejin.im/welcome/frontend');
await page.waitFor(500);
let sources = await page.evaluate(()=>{
let con = Array.from(document.querySelectorAll('.entry-list > li a.title'));
return con.map(item =>item.href);
});
for(let i =0;i<sources.length;i++){
let page = await browser.newPage();
await page.goto(sources[i],{timeout:0});
let html = await page.evaluate(()=>{
let content = Array.from(document.querySelectorAll('div.article-area'));
return content.map(con => con.textContent);
})
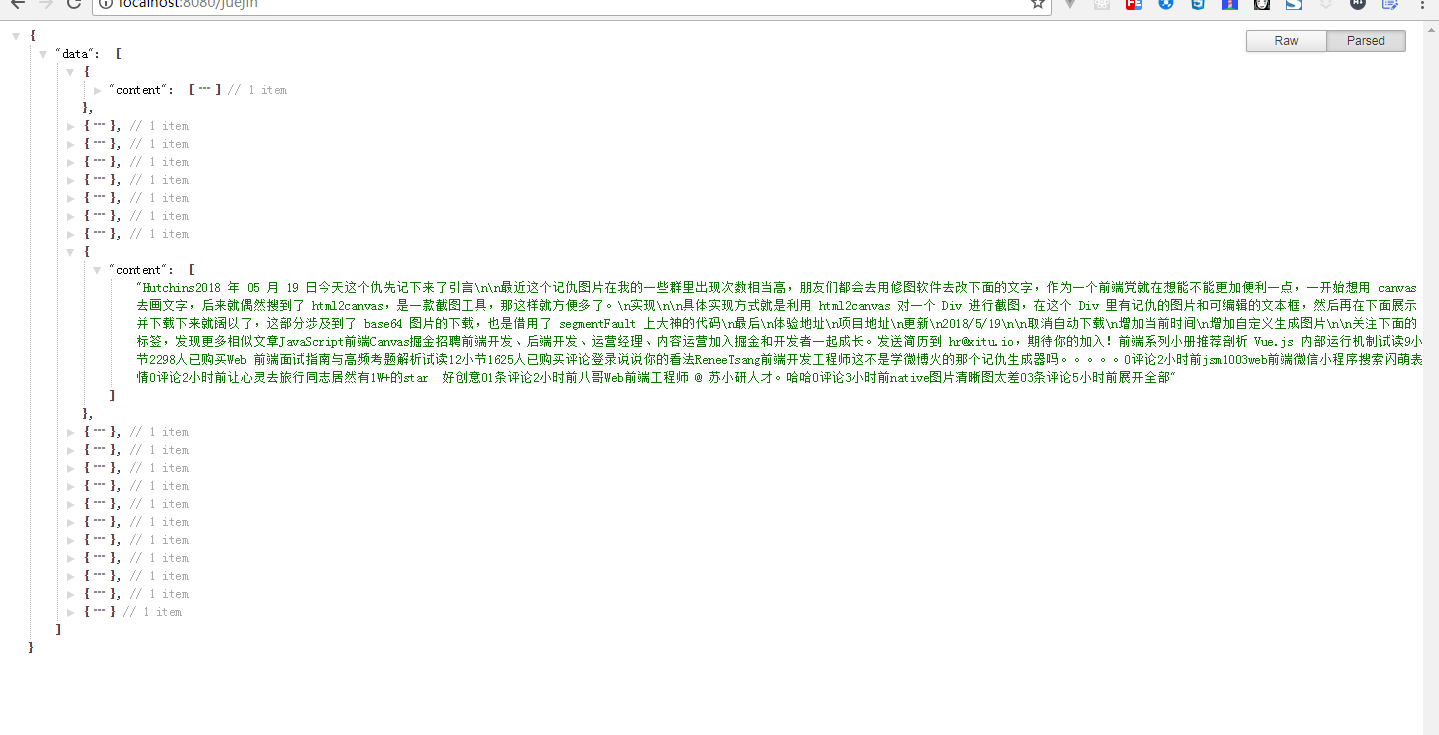
arr.push({'content':html})
}
res.send({'data':arr});
await browser.close();
console.log(new Date());
console.log('end');
})()
})
上述代码中的访问url就不在讲解了 主要讲解从列表中获取 所有文章的地址 然后访问个个网址提取文章的内容。
page.evaluate 函数的主要用途是添加可执行的JavaScript代码段到page中我们需要的是获取元素中的地址,所以我们先要找到元素的位置,开控制台找元素就不用多说了把,page.evaluate 函数中 documentSelectorAll 就是来找携带地址的a 元素。
Array.from 类似于创建新array实例一样 我们获取到了元素的href 然后 return 出来。
for循环去遍历拿到的地址列表 创建新的page页面然后去访问 去找到文字内容的节点然后返回出来 在这里我定义了一个数据 用来接收每个页面文章的内容,for循环完成后 通过res.send函数 返回给前端页面,这样就可以在前端看到我获取到的数据了。
borwser.close() 那肯定就是关闭浏览器啊,都操作完了肯定是要结束的啊。 文中的page.waitFor() 功能类似我们的timeout 函数差不多
案例2运行截图:
案例2数据截图:
以上就是Puppeteer 的测试实例讲解,有兴趣的同学可以深入研究研究,案例太多就不一一解释了。
英文不好的同学看看这个博客 把 有很多常用的api介绍
https://blog.csdn.net/u010142437/article/details/79136182
