

zookeeper源码分析系列文章:
- Zookeeper源码分析(一) ----- 源码运行环境搭建
- Zookeeper源码分析(二) ----- zookeeper日志
- Zookeeper源码分析(三) ----- 单机模式(standalone)运行
原创博客,纯手敲,转载请注明出处,谢谢!
如你所知,zk的运行方式有两种,独立模式和复制模式。很显然复制模式是用来搭建zk集群的,因此我把复制模式称为集群模式。在之前的文章中我们已经对独立模式下运行zk的源码进行相关分析,接下来我们一起来研究研究Zk集群模式下的源码。
集群模式下的调试不像独立模式那么简单,也许你可能会问,那是否需要多台物理机来搭建一个zk集群呢?其实也不需要,单台物理机也是可以模拟集群运行的。因此,下文我们将按照以下目录开展讨论:
一、zk集群搭建及相关配置
zk配置集群其实非常简单,在上篇博客中讲到,zk在解析配置文件时会判断你配置文件中是否有类似server.的配置项,如果没有类似server.的配置项,则默认以独立模式运行zk。相反,集群模式下就要求你进行相应的配置了。下面将一步一步对搭建环境进行讲解:
- 1、在zk的conf目录中增加3个配置文件,名字分别为
zoo1.cfg、zoo2.cfg和zoo3.cfg
其内容分别如下:
zoo1.cfg
tickTime=200000
initLimit=10
syncLimit=5
dataDir=E:\\resources\\Zookeeper\\zookeeper-3.4.11\\conf\\data\\1
dataLogDir=E:\\resources\\Zookeeper\\zookeeper-3.4.11\\conf\\log\\1
maxClientCnxns=2
# 服务器监听客户端连接的端口
clientPort=2181
server.1=127.0.0.1:2887:3887
server.2=127.0.0.1:2888:3888
server.3=127.0.0.1:2889:3889
zoo2.cfg
tickTime=200000
initLimit=10
syncLimit=5
dataDir=E:\\resources\\Zookeeper\\zookeeper-3.4.11\\conf\\data\\2
dataLogDir=E:\\resources\\Zookeeper\\zookeeper-3.4.11\\conf\\log\\2
maxClientCnxns=2
# 服务器监听客户端连接的端口
clientPort=2182
server.1=127.0.0.1:2887:3887
server.2=127.0.0.1:2888:3888
server.3=127.0.0.1:2889:3889
zoo3.cfg
tickTime=200000
initLimit=10
syncLimit=5
dataDir=E:\\resources\\Zookeeper\\zookeeper-3.4.11\\conf\\data\\3
dataLogDir=E:\\resources\\Zookeeper\\zookeeper-3.4.11\\conf\\log\\3
maxClientCnxns=2
# 服务器监听客户端连接的端口
clientPort=2183
server.1=127.0.0.1:2887:3887
server.2=127.0.0.1:2888:3888
server.3=127.0.0.1:2889:3889
上面相关通用的配置项在此处我就不做一一解释,相关含义在上篇文章中都有提到。下面我们重点关注下clientPort属性和server.x属性。
clientPort代表服务器监听客户端连接的端口,换句话说就是客户端连接到服务器的那个端口。该属性的默认配置一般都是2181,那为什么我们这里要写成2181,2182,2183呢?其实原因很简单,因为我们的集群式搭建在单台物理机上面,为了防止端口冲突,我们设置3台zk服务器分别监听不同的端口。
至于server.x属性,用于配置参与集群的每台服务器的地址和端口号。其格式为:
server.x addressIP:port1:port2
其中x表示zk节点的唯一编号,也就是我们常说的sid的值,下面讲到zk选举的时候将会进一步讲解。你可能会很好奇port1和port2之间有什么区别,在zk中,port1表示fllowers连接到leader的端口,port2表示当前结点参与选举的端口。之所以要这么设计,其实我觉得在ZAB协议中,当客户端发出的写操作在服务器端执行完毕时,leader节点必须将状态同步给所有的fllowers,leader和fllowers之间需要进行通信嘛!另外一种是所有节点进行快速选举时,各个节点之间需要进行投票,投票选出完一个leader节点之后需要通知其他节点。所以说,明白端口含义即可,它们就是区别作用罢了。
- 2、创建3个
myid文件
zk在集群模式下运行时会读取位于dataDir目录下的myid文件,如果没有找到,则会报错。因此,下面我们将分别在对应的dataDir下新建myid文件,该文件的内容填写当前服务器的编号,也就是我们上面说到的server.x中的x值。
E:\\resources\\Zookeeper\\zookeeper-3.4.11\\conf\\data\\1下创建该文件,文件内容为序号1E:\\resources\\Zookeeper\\zookeeper-3.4.11\\conf\\data\\2下创建该文件,文件内容为序号2E:\\resources\\Zookeeper\\zookeeper-3.4.11\\conf\\data\\3下创建该文件,文件内容为序号3
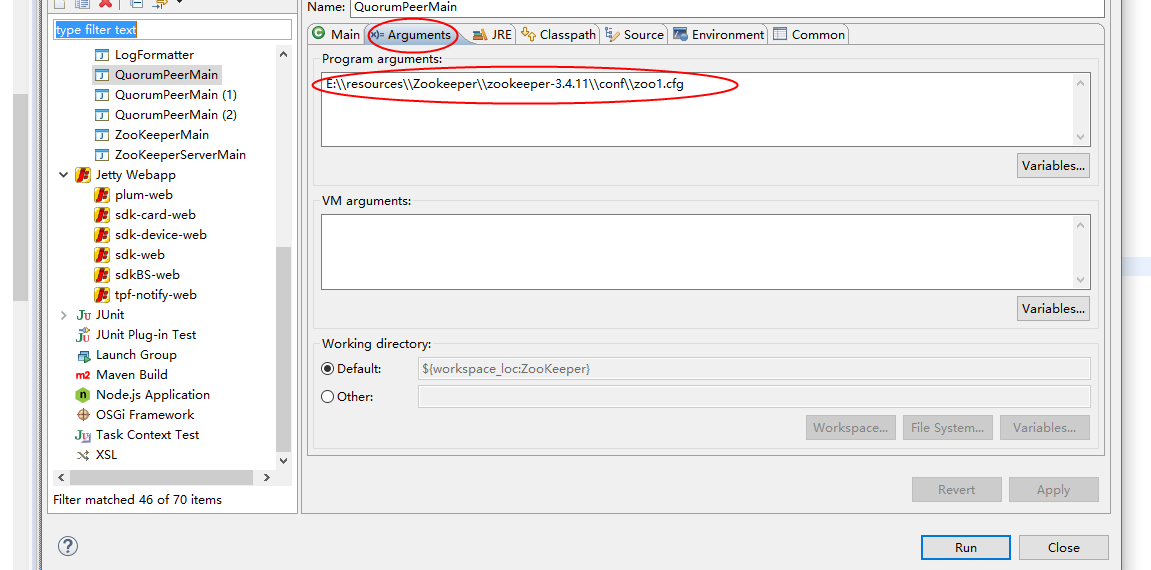
- 3、分别采用不同的配置文件运行
QuorumPeerMain的main()方法即可。配置文件路径可以这样传给eclipse,如下图:
上面讲的内容似乎和源码打不上边,嗯,别着急,下面就讲源码。
首先我们看看zk是如何解析server.x标签的,进入QuorumPeerConfig类的parseProperties()方法,你将看到如下代码片段:
// 判断属性是否以server.开始
if (key.startsWith("server.")) {
int dot = key.indexOf('.');
// 获取sid的值,也就是我们server.x中的x值
long sid = Long.parseLong(key.substring(dot + 1));
// 将配置值拆分为数组,格式为[addressIP,port1,port2]
String parts[] = splitWithLeadingHostname(value);
if ((parts.length != 2) && (parts.length != 3) && (parts.length != 4)) {
LOG.error(value + " does not have the form host:port or host:port:port "
+ " or host:port:port:type");
}
// 代表当前结点的类型,可以是观察者类型(不需要参与投票),也可以是PARTICIPANT(表示该节点后期可能成为follower和leader)
LearnerType type = null;
String hostname = parts[0];
Integer port = Integer.parseInt(parts[1]);
Integer electionPort = null;
if (parts.length > 2) {
electionPort = Integer.parseInt(parts[2]);
}
}
上面源码将会根据你的配置解析每一个server配置,源码也不是很复杂,接下来我们将看看zk如何读取dataDir目录下的myid文件,继续在QuorumPeerConfig的parseProperties()方法中,找到如下代码片段:
File myIdFile = new File(dataDir, "myid");
// 必须在快照目录下创建myid文件,否则报错
if (!myIdFile.exists()) {
throw new IllegalArgumentException(myIdFile.toString() + " file is missing");
}
// 读取myid的值
BufferedReader br = new BufferedReader(new FileReader(myIdFile));
String myIdString;
try {
myIdString = br.readLine();
} finally {
br.close();// 注意,优秀的人都不会丢三落四,对于打开的各种io流,不用的时候记得关闭,不要浪费资源
}
二、zk集群模式下的初始化
在zk中,无论是独立模式运行还是复制模式运行,其初始化的步骤都可以归为:
- 1、解析配置文件
- 2、初始化运行服务器
对于配置文件的解析,我们在上一篇文章和本文上节已做出相关分析。我们重点看下zk集群模式运行的相关源码,让我们进入QuormPeerMain类的runFromConfig()方法,源码如下:
/**
* 加载配置运行服务器
* @param config
* @throws IOException
*/
public void runFromConfig(QuorumPeerConfig config) throws IOException {
LOG.info("Starting quorum peer");
try {
// 创建一个ServerCnxnFactory,默认为NIOServerCnxnFactory
ServerCnxnFactory cnxnFactory = ServerCnxnFactory.createFactory();
// 对ServerCnxnFactory进行相关配置
cnxnFactory.configure(config.getClientPortAddress(), config.getMaxClientCnxns());
// 初始化QuorumPeer,代表服务器节点server运行时的各种信息,如节点状态state,哪些服务器server参与竞选了,我们 可以将它理解为集群模式下运行的容器
quorumPeer = getQuorumPeer();
// 设置参与竞选的所有服务器
quorumPeer.setQuorumPeers(config.getServers());
// 设置事务日志和数据快照工厂
quorumPeer.setTxnFactory(
new FileTxnSnapLog(new File(config.getDataDir()), new File(config.getDataLogDir())));
// 设置选举的算法
quorumPeer.setElectionType(config.getElectionAlg());
// 设置当前服务器的id,也就是在data目录下的myid文件
quorumPeer.setMyid(config.getServerId());
// 设置心跳时间
quorumPeer.setTickTime(config.getTickTime());
// 设置允许follower同步和连接到leader的时间总量,以ticket为单位
quorumPeer.setInitLimit(config.getInitLimit());
// 设置follower与leader之间同步的时间量
quorumPeer.setSyncLimit(config.getSyncLimit());
// 当设置为true时,ZooKeeper服务器将侦听来自所有可用IP地址的对等端的连接,而不仅仅是在配置文件的服务器列表中配置的地址(即集群中配置的server.1,server.2。。。。)。 它会影响处理ZAB协议和Fast Leader Election协议的连接。 默认值为false
quorumPeer.setQuorumListenOnAllIPs(config.getQuorumListenOnAllIPs());
// 设置工厂,默认是NIO工厂
quorumPeer.setCnxnFactory(cnxnFactory);
// 设置集群数量验证器,默认为半数原则
quorumPeer.setQuorumVerifier(config.getQuorumVerifier());
// 设置客户端连接的服务器ip地址
quorumPeer.setClientPortAddress(config.getClientPortAddress());
// 设置最小Session过期时间,默认是2*ticket
quorumPeer.setMinSessionTimeout(config.getMinSessionTimeout());
// 设置最大Session过期时间,默认是20*ticket
quorumPeer.setMaxSessionTimeout(config.getMaxSessionTimeout());
// 设置zkDataBase
quorumPeer.setZKDatabase(new ZKDatabase(quorumPeer.getTxnFactory()));
quorumPeer.setLearnerType(config.getPeerType());
quorumPeer.setSyncEnabled(config.getSyncEnabled());
// 设置NIO处理链接的线程数
quorumPeer.setQuorumCnxnThreadsSize(config.quorumCnxnThreadsSize);
quorumPeer.start();
quorumPeer.join();
} catch (InterruptedException e) {
// warn, but generally this is ok
LOG.warn("Quorum Peer interrupted", e);
}
}
在处理客户端请求方面,集群模式和独立模式都是使用ServerCnxnFactory的相关子类实现,默认采用基于NIO的NIOServerCnxnFactory,对于QuormPeer类,你可以把它想象成一个容器或者上下文,它包含着集群模式下当前结点的所有配置信息,如哪些服务器参与选举,每个节点的状态等等。当该方法运行至quorumPeer.join();时,当前线程将阻塞,直到其他所有线程退出为止。
让我们进入quorumPeer.start()方法,看看它做了什么动作:
public synchronized void start() {
// 初始化是内存数据库
loadDataBase();
// 用于处理程序为捕获的异常和处理客户端请求
cnxnFactory.start();
// 选举前相关配置
startLeaderElection();
// 线程调用本类的run()方法,实施选举
super.start();
}
zk本身运行时会在内存中维护一个目录树,也就是一个内存数据库,初始化服务器时,zk会从本地配置文件中装载数据近内存数据库,如果没有本地记录,则创建一个空的内存数据库,同时,快照数据的保存也是基于内存数据库完成的。
三、zk集群模式下如何进行选举?
小编目测了代码之后发现zk应该是采用JMX来管理选举功能,但由于小编对JMX暂时不熟悉,因此,此部分将不结合源码进行解释,直接说明zk中选举流程。
首先每个服务器启动之后将进入LOOKING状态,开始选举一个新的群首或者查找已经存在的群首,如果群首存在,其他服务器就会通知这个新启动的服务器,告知那个服务器是群首,于此同时,新的服务器会与群首建立链接,以确保自己的状态和群首一致。
对于群首选举时发送的消息,我们称之为通知消息。当服务器进入LOOKING状态时,会想集群中所有其他节点发送一个通知,该同志包括了自己的投票信息vote,vote的数据结构很简单,一般由sid和zxid组成,sid表示当前服务器的编号,zxid表示当前服务器最大的事务编号,投票信息的交换规则如下:
- 1、如果voteZxid > myzxid 或者 (voteZxid = myZxid 且 voteId > mySid ) ,保留当前的投票信息
- 2、否则修改自己的投票信息,将voteZxid赋值给myZxid,将voteId赋值给mySid
总之就是先比较事务ID,如果相等,再比较服务器编号Sid。如果一个服务器接收到的所有通知都一样时,则表示群首选举成功(zxid最大或者sid最大)
四、为什么说组成zk集群的节点数最好为奇数,且建议为3个节点?
Zk集群建议服务器的数量为奇数个,其内部采用多数原则,因为这样能使得整个集群更加高可用。当然这也是由zk选举算法决定的,一个节点虽然可以为外界提供服务,但只有一个节点的zk还能算作是集群吗?很明显不是,只能说是独立模式运行zk。
假设我们配置的机器有5台,那么我们认为只要超过一半(即3)的服务器是可用的,那么整个集群就是可用的,至于为什么一定要数量的半数,这是由于zk中采用多数原则决定的,具体可以查看QuorumMaj类,该类有个校验多数原则的方法,代码如下:
/**
* 这个类实现了对法定服务器的校验
* This class implements a validator for majority quorums. The
* implementation is straightforward.
*/
public class QuorumMaj implements QuorumVerifier {
private static final Logger LOG = LoggerFactory.getLogger(QuorumMaj.class);
// 一半的服务器数量,如果是5,则half=2,只要可用的服务器数量大于2,则整个zk就是可用的
int half;
/**
* Defines a majority to avoid computing it every time.
*/
public QuorumMaj(int n) {
this.half = n / 2;
}
/**
* Returns weight of 1 by default.权重
*/
public long getWeight(long id) {
return (long) 1;
}
/**
* Verifies if a set is a majority.
*/
public boolean containsQuorum(HashSet<Long> set) {
return (set.size() > half);//传入一组服务器id,校验必须大于半数才能正常提供服务
}
}
我们再来看看QuormPeerConfig类中的parseProperties()方法中的代码片段:
// 只有2台服务器server
if (servers.size() == 2) {
// 打印日志,警告至少需要3台服务器,但不会报错
LOG.warn("No server failure will be tolerated. " + "You need at least 3 servers.");
} else if (servers.size() % 2 == 0) {
LOG.warn("Non-optimial configuration, consider an odd number of servers.");
}
该代码片段对你配置文件中配置的服务器数量进行校验,如果是偶数或者等于2,则会发出诸如“该配置不是推荐配置”的警告,如果服务器数量等于2,则不能容忍哪怕1台服务器崩溃。
为了加深印象,我们来看看为什么zk推荐使用奇数台服务器。
- 如果配置3台服务器,那么当一台挂了以后,3台服务器中的2台票数过半,可以选出一台leader;
- 如果配置4台,那么允许1台挂掉,这和只有3台服务器是一样的,为节省成本,何不选择3台,但是当4台中2台挂了之后,那么4台中可用的2台票数没过半无法选择出leader
