

更多干货内容请关注微信公众号“AI 前线”,(ID:ai-front)
自从 DeepMind 的 AlphaGo 在 2016 年战胜人类围棋冠军一炮而红之后,各大科技巨头都机敏地嗅到了这门技术能红,纷纷紧紧跟上了这一新趋势和潮流。
谷歌的 DeepMind 当仁不让可以说是引领 RL 风潮的“第一人”。该公司的 AlphaGo 让人们重新提起了对 RL 的兴趣。除此之外,强化学习系统帮助 Google 数据中心降温系统的能源降低 40% 也是强化学习应用的另一个很好的例子。2018 年 1 月,谷歌 Google 发布 AutoML Vision,可以全自动训练 AI 无需写代码,并在一次图像内容分类的测试中,以 82% 的准确率击败了编写 AutoML 的研究人员。
OpenAI 一直是业界进行强化学习研究与应用的前沿阵地,曾开发出层次化的强化学习算法用来解决导航问题,让智能体能够快速掌握新的导航任务,给长序列动作学习带来新的曙光。OpenAI 还拥有用于研发和比较强化学习算法的工具包 OpenAI Gym,以及 2017 年提出,并被 OpenAI 设置为默认强化学习算法的近端策略优化(PPO)算法,能够控制更复杂的机器人。2018 年,OpenAI 在强化学习上火力全开,已经有多个重点研究方向浮出水面,如分布式深度强化学习中参数平均问题(Parameter Averaging)、通过生成模型,在不同的 GAMES 之间进行迁移问题、贪吃蛇项目 Slitherin 问题、 强化学习(RL)中的正规化(Regularization)问题等,相信会带给业界更多的惊喜。
微软 对强化学习的也是热情高涨,以深度强化学习作为其 AI 聊天机器人的核心技术。其于 2017 年收购加拿大人工智能创业公司 Maluuba 在论文 Multi-Advisor Reinforcement Learning 中强调了“多重引导强化学习机”,致力于研究开发一种机器智能工具,以分析无结构化文本,从而使人机交互更加自然,也在推动着 RL 发展。
此外,中国的 BAT 也均致力于 RL 的研究和应用之中,并且已经取得不错的成果。此外,涉及到实时性较强业务的公司大多也都有使用 RL,如新浪、美团、滴滴,以及 Prowler.io、Osaro、MicroPSI、英伟达、Mobileye 等公司也都是比较有名的 RL 研究企业。
首先,我们需要了解一下强化学习是什么?为什么会在围棋游戏中胜过人类专家?
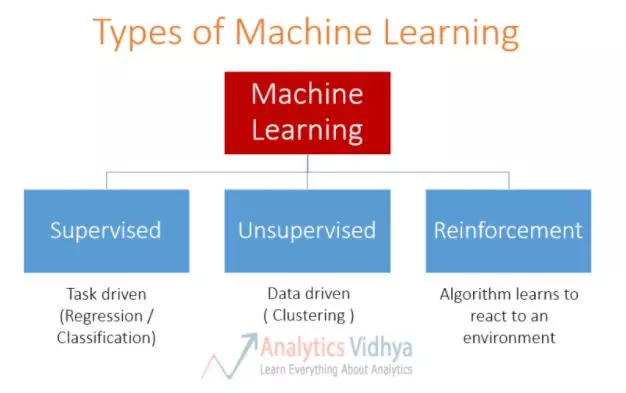
强化学习是机器学习的方法之一,我们对监督式和非监督式学习比较熟悉,还有另外一个大类就是强化学习。
简而言之,强化学习是指 autonomous agent,例如,人、动物、机器人或深度网络,通过奖励达到最大化,来学会在不确定环境中进行定位。
为什么强化学习会帮助 Alpha Go 战胜人类最强棋手取得胜利呢?这是因为 RL 与监督式学习不同,在国际象棋和围棋等赛事中,监督式学习不可能知道所有结果,但强化学习会在没有任何标签的情况下,通过先尝试做出一些行为得到一个结果,然后得到是对还是错的反馈(reward function),不断调整之前的行为,算法能够学习到在什么样的情况下选择什么样的行为可以得到最好的结果。通过强化学习,一个 agent 可以在探索和开发(exploration and exploitation)之间做权衡,并且选择一个最大的回报。
非监督式学习不是学习输入到输出的映射,而是模式。与之相比,强化学习也有其优点。还以围棋为例,非监督式学习会学习之前的做法向用户推荐其一,而强化学习则是通过先推荐少量方法,并不断获得反馈之后,构建最优的“知识图”。
这样,RL 相比其他方法的优势和特点使得 AI 算法胜过人类,成为围棋类游戏背后算法支持的得力助手,之后的围棋和类似游戏也都基本上沿袭了这一基因。
但除此之外,RL 的应用前景和用武之地还有很多,包括医疗、金融、广告等领域。
例如 阿里巴巴 在双 11 推荐场景中使用了深度强化学习与自适应在线学习,通过持续机器学习和模型优化建立决策引擎,对海量用户行为以及百亿级商品特征进行实时分析,帮助用户迅速发现宝贝,提高人和商品的 配对效率。比如,利用强化学习将 手机用户点击率提升了 10-20%。运用强化学习框架,阿里巴巴平台建立了一个消费者与系统互动的回路系统,由于系统的决策建立在最大化过程收益上,从而达到系统与用户的动态平衡,提高智能搜索和推荐流量投放的效率。
以百度为例,其因为 AI 投入扭转了不利局势,安全从低谷中走出。截至 2018 年 3 月 31 日的第一季度财报显示,百度第一季总营收猛增 31%,达 209 亿元人民币 (33.3 亿美元),净利润 67 亿元(11 亿美元),每股收益 16.6 人民币 (2.60 美元),均高于市场预期。这样的表现一方面得益于百度组织的优化调整,抛弃了许多累赘的业务,另一方面则要归功于对 AI 的投入在广告业务中获得了回报。百度在财报中表示,公司首次在广告系统中部署了强化学习,进而提高了广告投放效率,百度广告业务的增长离不开强化学习。在广告系统中加入强化学习模型后,它会实时记录浏览、点击、转化等关键数据,并通过自我学习对投放进行优化,让广告能更精准地匹配到目标客群,以此达到广告主“钱都花在刀刃上”的效果,花更少的钱,得到更精准的曝光。
和百度一样,Facebook、微软等要靠“金主爸爸”过活的平台也在广告系统中使用了 RL,如微软公布的一套名为“决策服务”的内部系统就应用于内容推荐和广告业务上。在相关领域其他 RL 应用还包括跨渠道营销优化和在线广告展示的实时竞价系统等。
RL 在高维控制问题中的应用,比如机器人,已经成为学术和工业界的一大研究主题。与此同时,一些创业公司也开始用 RL 为工业机器人来打造产品。有几家创业公司已经在为一些公司制作能让后者将 RL 和其他技术用进工业应用的工具,Bonsai 就是其中之一。工业自动化是另一个有前景的领域,比如 DeepMind 的强化学习技术帮助 Google 显着降低了其数据中心的能耗(HVAC)。
在语言处理领域,最重要的任务是让计算机可以更自然地与人交流。在这方面,RL 可以发挥很大的作用。如加拿大蒙特利尔大学 Yoshua Bengio 研究组提出的 MILABOT 的模型。该模型完全采用基于统计机器学习的方法,在处理和生成自然人类对话中做了尽可能少的假设。模型中每个组件的设计使用机器学习方法优化,通过强化学习对各个组件的输出进行优化。
另外,Facebook 的人工智能研究机构 FAIR 开源并公开发布的聊天机器人已经拥有了跟人类进行协商谈判、进行讨价还价的能力。通过监督学习 + 强化学习,这个聊天机器人不仅能理解字词和语义的对应关系,还能针对自己的目标制定策略,跟别人进行协商讨论达成一致。
摩根大通使用一套用于交易执行的系统。依托于 RL,这套系统被用于以可能的最快速度和最佳价格来执行交易。
作为 RL 的一个应用领域,自动驾驶近年来已经成为一个大热门,现在,无人车研究团队基本上都会在研究中将 RL 考虑在内,因为 RL 在自动驾驶策略学习方法、路线规划等方面非常有用。例如,奥迪无人车 RC 就使用了深度 RL。在特斯拉,Autopilot 总监 Jim Keller 离职之后由 Andrej Karpathy 担任人工智能和 Autopilot Vision 负责人,负责 Autopilot 软件团队。而 Andrej Karpathy 是可视化、深度学习、强化学习领域的专家,他在 RL 上的经验会进一步强调 RL 的战略意义。
除此之外,RL 还在制造业、教育和培训、仓储管理、动态定价、用户运输等领域有着广泛的应用前景。
然而,强化学习果真如表面上看起来这样光鲜亮丽吗?虽然从百度财报的简析中看了,强化学习在广告上的应用似乎对提升营收效果非常不错,阿里巴巴也宣称将 RL 首次用到了个性化和广告业务上带来了业务上的提升,但深究起来,我们会发现并没有数据直接表明 RL 在其中发挥了主要作用。
实际上,RL 在光鲜亮丽的外表之下,它并非一个完美的存在。正如吴恩达在旧金山 AI 大会上的主旨发言中所说,RL 需要 大量的数据,一个简单的任务就需要千万甚至上亿的数据,与此同时,需要与那些能够获取模拟数据的领域(比如游戏和机器人)建立联系,而这都不是容易的事。除此之外,入门 RL 之后会遇到各种难以解决的问题,甚至到最后会发现它其实并不是解决所有问题最好的方案,“术业有专攻”,RL 不能解决所有的问题。
深度学习强化本身存在 不稳定性:
看一个表示 DRL 模型随着尝试 random seed 数量下降的图,我们会发现几乎所有图里模型表现最终都会降到 0,如果运气不好很可能长时间模型的曲线都不会有任何变化。
即使知道超参数和随机种子,模型的细微差别会导致模型表现有天壤之别,甚至同一个算法在同一个任务上的表现会截然不同。
即便一切顺利,但随着时间变长,模型可能会突然原因不明地出状况,以至完全不工作,可能与过拟合和 variance 过大有关。
再如 存在噪声和反馈时间长的问题:强化学习需要从 reward 信号学习,且 reward 信号经常比较稀疏(sparse)、有噪声(noisy)、有延迟(delayed)。从执行动作(action)到产生 reward 的延迟,可能有上千步长,就是说强化学习没有标签表明在某种情况下应该做出什么样的行为,只有一个做出一系列行为后最终反馈回来的、能够判断当前选择的行为是好是坏的信号。而且强化学习的结果反馈是有延时的,有时候可能需要走了很多步以后才知道之前某步的选择是好还是坏,而在反应过来之后已经距那一步百步千步之遥了,因此会十分耗时。
最后,我们或许还应该思考一个问题:为什么谷歌并没有把强化学习用在广告上呢?是因为强化学习不稳定、存在噪声、反馈时间长等问题,还是百度将之写入财报更多是为了宣传效果?对这个问题的思考或许会让我们对炙手可热的强化学习有更加深刻和清醒的认识。不过这个问题大概跟陆奇的离开对于百度的未来到底会有多大的影响一样,只能等时间来给出答案了。
更多关于深度强化学习难以言说的“尴尬”之处,请参考:
