


更多干货内容请关注微信公众号“AI 前线”,(ID:ai-front)
OpenAI 这篇文章一出,很多人对之表示赞赏,但同时也引发了一些争论,甚至一些人表示了对算力提升如此之快的担忧,评论中有人发出疑问:
奇点会比预计的来的早吗?
比摩尔定律还快,这很恐怖啊。
超级 AI 不会在智能手机芯片,而是会在大规模云端计算机上出现。这意味着这些公司计算水平提高的速度更重要。
还有一些专家大拿表示对文中一些观点不敢苟同:
加州大学伯克利分校副教授 Ben Recht 在 Twitter 上吐槽,称人们对算力增长的解读简直疯狂,并连发几条评论表明自己的观点:
如果你把 Alphabet(财大气粗的谷歌母公司)的研究工作排除掉,体现出来的趋势就会完全不同。
从 VGG 到 ResNets(重大突破)并不需要算力指数级增长。
你怎么不说从注意力 LSTMs 发展到注意力模型,翻译的复杂性也降低了呢?
这里所说的与 flop 提升最相关的应用(神经架构搜索和数据)算不上什么重大突破。
他还认为 Jeremy Howard 对这篇文章的点评很到位。

我认为这完全是在倒退。工程师们就喜欢玩这种游戏,所以他们会用所能拿到的所有资源来做这件事。这个图只能说明深度学习研究员能够得到的资源变多了——仅此而已。
他的推文下有不少讨论:
Jonathan Raiman:这篇文章的观点难道不是这种趋势表明我们有越来越多的方式来使用数据中心规模的计算力进行机器学习训练,而且这些系统不是单台机器,因此可以超越摩尔定律吗? 这并不违反帕金森定律(官僚主义或官僚主义现象的一种别称),但没有这些进步,我们很难进行 1v1 dota 或 Alpha Zero 训练。
Will Knight:OpenAI 的分析非常棒,但我不认为 AI 的性能总是会随着计算能力的提高而进步。要是这样的话,多搞些数据和 GPU 就可以解决所有问题了。
也有人回复称:
Smerity:我也倾向于相信 ML 力有不逮的一面,但是我觉得他们的观点是说:是否存在一种基础技术(架构搜索,自动操作...),它可以利用巨大的算力完成特定任务,而完成此任务所需的算力是个天文数字。
AlphaGo / AlphaGoZero 在论文和博客表现都太过完美了,赢得一场游戏所需的计算量是令人吃惊的,希望有类似的技术提高能够真正用于实际用途吧...
Jason Taylor:这是一个乘法效应:摩尔定律(对单个 GPU)和进入该领域的资本(买更多的 GPU)。
那么到底是什么样的文章引起了这么大的争议呢?
AI 前线将 OpenAI 原文编译如下:
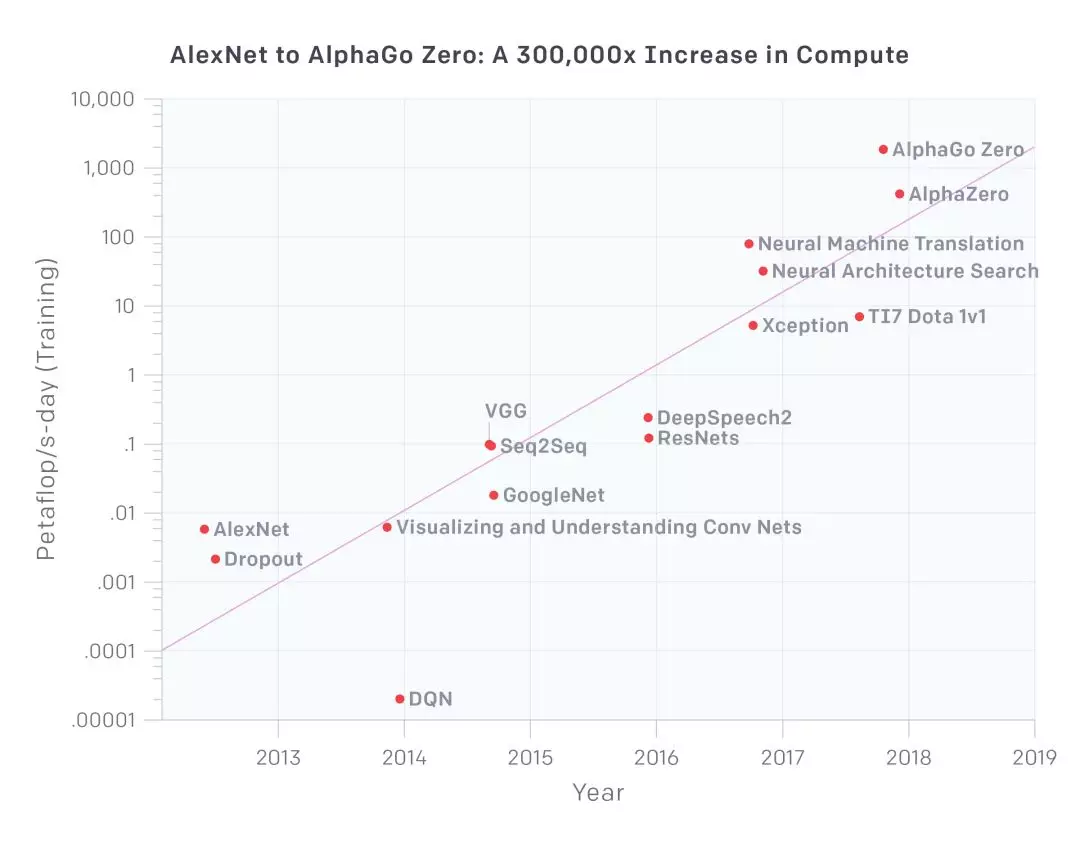
对数标度
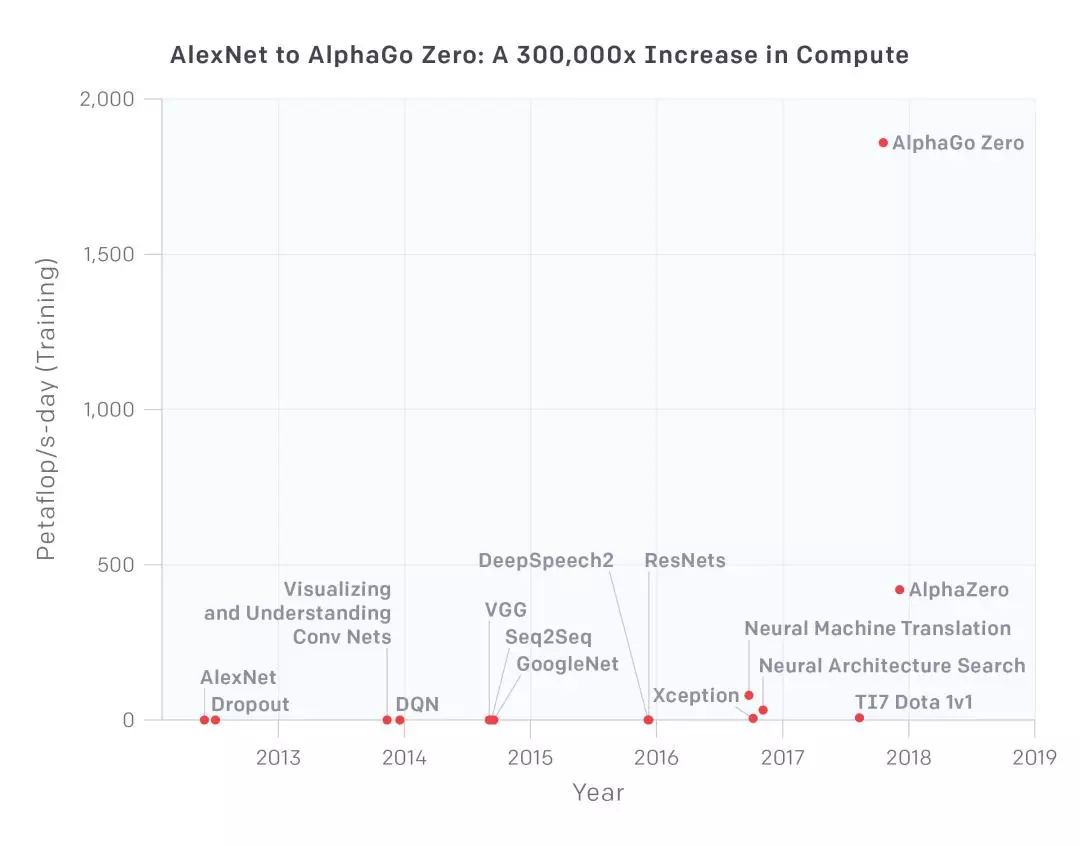
线性标度
该图表显示了以 petaflop / s-days 为单位的计算总量,用于训练相对熟悉的选定结果,计算时长较长,并提供了足够多的信息来估计所用的计算力。petaflop/s-day (pfs-day) 指在一天时间内执行 10^15 次神经网络操作,或总计大约 10^20 次操作。计算时长作为一种度量,相当于能源的千瓦时。我们不测量硬件的峰值理论 FLOPS,而是估计实际操作的数量。我们单独运作加法和乘法,将所有加法或乘法计算作为单次计算,而不考虑数值精度(这使得“FLOP”略微有点用词不当),并忽略集成模型(http://web.engr.oregonstate.edu/~tgd/publications/mcs-ensembles.pdf )。文末附录为该图表的示例计算。达到最好效果时的翻倍时间显示为 3.43 个月。
推动人工智能发展的因素有三个:算法创新、数据(可以是监督数据或交互式环境),以及可用于训练的算力。算法创新和数据一般很难度量,但计算力是可量化的,这使得衡量 AI 进步的因素成为可能。当然,使用大规模计算有时会暴露我们当前算法的缺点。但至少在许多现有领域中,算力提高通常会带来性能提高,并且往往是对算法进步的补充。
本文中,我们认为与此相关的数字并不是单个 GPU 的速度,也不是最大数据中心的容量,而是用于训练单个模型的计算量 - 这是与模型性能最为相关的数字。每个模型的计算与总体计算有很大不同,因为并行性(http://learningsys.org/nips17/assets/slides/dean-nips17.pdf 硬件和算法)限制了模型的大小,或者训练有用的部分有多少。当然,重要的突破仍然是通过适量的计算来实现的 - 本文仅涵盖计算能力的内容。
这一趋势为每年约增加 10 倍。其中一部分原因是定制硬件的进步,它使得系统能够在一定价格条件下(GPU 和 TPU)每秒执行更多的操作,但这主要是由于研究人员努力寻找可并行使用更多芯片,让操作更经济促成的。
图表显示,算力发展的历史大致可以分为四个不同的时代:
2012 年之前:将 GPU 用于 ML 并不常见,这导致图表中的任何一项成果都很难实现。
2012 年到 2014 年:在许多 GPU 上进行训练的基础架构并不常见,因此大多数结果是使用 1-8 个 GPU 得出的,额定功率为 1-2 TFLOPS,总共为 0.001-0.1 pfs-days。
2014 年至 2016 年:大规模使用了 10-100 GPU,额定功率为 5-10 TFLOPS,0.1-10 pfs-days。数据并行性收益递减意味着更大规模的训练没有多大价值。
2016 年至 2017 年:允许更大算法并行性的方法(如大批量、体系结构搜索和专家级迭代)以及专用硬件(如 TPU 和更快的互连)大大提高了这些上限,至少对于某些应用程序而言。
AlphaGoZero / AlphaZero 是大规模使用并行算法最有名的例子,现在这种规模的算法在算法上已经可用于许多其他应用程序,并且可能已经在生产环境中进行了。
我们有充足的理由相信,图表中显示的趋势可能会继续下去。许多硬件初创公司正在开发 AI 专用芯片,其中一些宣称他们将在未来 1 - 2 年内大幅增加 FLOPS / Watt(与 FLOPS / $ 相关)。简单地重新配置硬件以减少成本来完成相同数量的操作也可能会带来更多收益。在并行性方面,原则上我们可以对上述许多的算法创新做乘法组合,例如体系结构搜索和大规模并行 SGD 相结合。
另一方面,成本最终将限制并行性,并且芯片的效率也有物理上的限制。我们知道,今天进行最大规模训练所采用的硬件成本达数百万美元(尽管摊销成本要低得多),但目前大多数神经网络计算仍然用于推理(部署),而不是训练,这意味着公司可以重新调整用途或购买更多的芯片进行训练。因此,如果有足够的经济激励措施,我们可以进行更大规模的平行训练,从而使这一趋势持续数年。数据显示,全世界的硬件总预算每年达 1 万亿美元,因此绝对的限制还很遥远。总的来说,考虑到上述数据,计算指数上涨的趋势,在特定硬件上进行 ML,以及经济激励等因素,我们认为这种趋势不会在短期内消失。
过去的趋势不足以预测这种趋势将持续多久,或者继续下去会发生什么。但即使是计算力的增长速度在合理预期范围之内,也意味着从现在开始,我们有必要重视解决安全和恶意使用 AI 的问题了。前瞻之见对于负责任的决策和技术发展至关重要,我们必须走在这些趋势之前,而不是在它到来时才幡然醒悟。
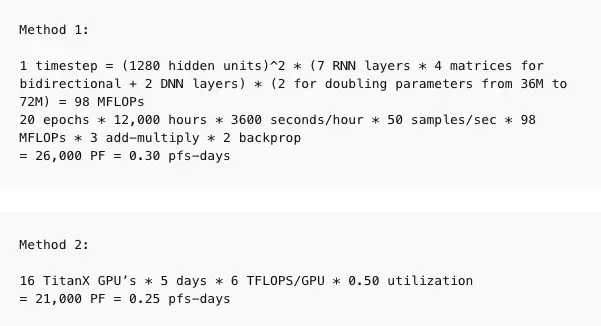
我们使用两种方法用于生成这些数据点。当我们有足够的信息时,直接在每个训练样例中描述的架构中计算 FLOP 的数量(相加和相乘),并乘以训练期间的前向和后向通道总数。当我们没有足够的信息来直接计算 FLOP 时,我们查看 GPU 的训练时间和使用的 GPU 总数,并设定使用效率(通常为 0.33)。在大多数论文中,我们能够使用第一种方法,但少数论文中我们使用第二种方法,并且尽可能对两者进行一致性检查。计算并不是精确的,我们的目标是把精确度保持在 2-3 倍的范围内。以下是一些示例计算。
当作者给出正向传递中的操作数时,这种方法特别简单,就像在 Resnet 论文中(特别是 Resnet-151 模型 https://arxiv.org/pdf/1409.4842.pdf )一样:

运算也可以在一些已知的深度学习框架中以编程方式进行,或者我们可以简单地手动计算。如果一篇论文提供了足够的信息来进行计算,结果会非常准确,但在某些情况下,论文不包含所有必要的信息,作者也无法公开这些信息。
如果我们不能直接进行计算,可以通过计算 GPU 数量和训练时长,并根据 GPU 利用率估计运算量。我们强调,这里不计算峰值理论 FLOPS,而是使用理论 FLOPS 的假定分数来估计实际 FLOPS。根据经验,我们通常假设 GPU 的利用率为 33%,CPU 的利用率为 17%,除非我们有更具体的信息(例如我们与作者交谈或工作在 OpenAI 上完成)。
举例来说,在 AlexNet 的论文中表示“我们的网络需要花费五到六天的时间在两个 GTX 580 3GB GPU 上进行训练”。根据我们的假设,这意味着总计算量为:

我们的目标是估计数量级。在实践中,当两种方法都可用时,通常效果很好(对于 AlexNet,我们也可以直接计算运算量)。

https://arxiv.org/abs/1207.0580

https://arxiv.org/abs/1311.2901

https://arxiv.org/abs/1312.5602

https://arxiv.org/abs/1409.3215
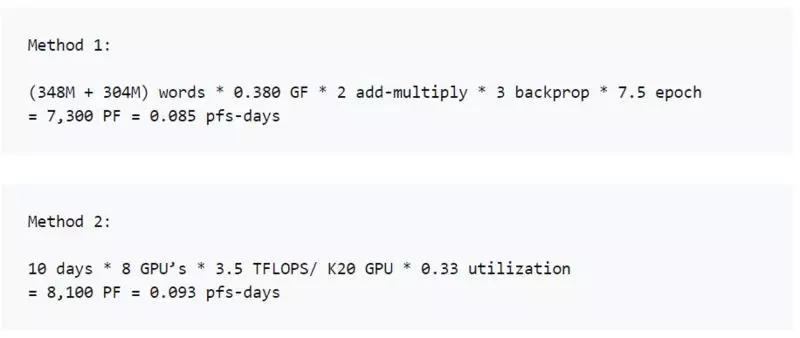
https://arxiv.org/pdf/1409.1556.pdf
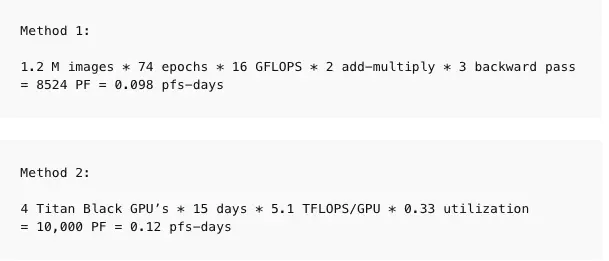
https://arxiv.org/abs/1512.02595

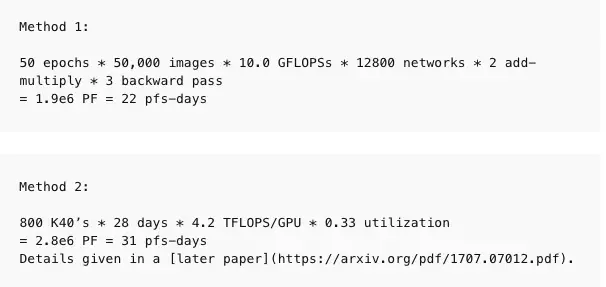

大规模计算当然不是产生重要结果的必要条件,最近得出的许多重要结果就是仅使用了适量的计算力得出的。以下是使用适量计算力得出结果的一些例子,它提供了足够的信息来估算计算力。我们没有使用很多方法来估计这些模型的计算结果,从上限来说,我们对所有缺失的信息进行了保守估计,因此具有更大的整体不确定性。这对我们的定量分析并不重要,但挺有趣的,我们认为值得分享一下:
你需要的是注意力: 0.089 pfs-days (6/2017)
https://arxiv.org/abs/1706.03762
Adam 优化器: 少于 0.0007 pfs-days (12/2014)
https://arxiv.org/abs/1412.6980
学会匹配和翻译: 0.018 pfs-days (09/2014)
https://arxiv.org/abs/1409.0473
GANs: 少于 0.006 pfs-days (6/2014)
https://arxiv.org/abs/1406.2661
Word2Vec: 少于 0.00045 pfs-days (10/2013)
https://arxiv.org/abs/1310.4546
变分自动编码器: less than 0.0000055 pfs-days (12/2013)
https://arxiv.org/abs/1312.6114
感谢 Katja Grace、Geoffrey Irving、Jack Clark、Thomas Anthony 和 Michael Page 对本文的贡献。
原文链接:
https://blog.openai.com/ai-and-compute/
