

ByteBuf是做什么用的?Netty中传递字节数据的容器。
ByteBuf的使用模式有那些?
| 使用模式 | 描述 | 优点 | 劣势 |
|---|---|---|---|
| 堆缓冲区 | 数据存存储在JVM的堆空间中,又称为支撑数组,通过 hasArray 来判断是不是在堆缓冲区中 | 没使用池化情况下能提供快速的分配和释放 | 发送之前都会拷贝到直接缓冲区 |
| 直接缓冲区 | 存储在物理内存中 |
|
|
| 复合缓冲 | 单个缓冲区合并多个缓冲区表示 | 操作多个更方便 | - |
ByteBuf如何访问?
- 下标访问:get,set开头的相关方法,不修改索引
- 索引访问:read,write开头的方法,根据已经访问过的字节对索引进行调整[索引是ByteBuf内置的readIndex和writeIndex]
ByteBuf本身有一定的容量限制,默认最大的是Integer.MAX_VALUE,超出范围抛IndeOutOfBoundsException
ByteBuf索引操作是怎样?
两个索引将ByteBuf分隔成3个区域
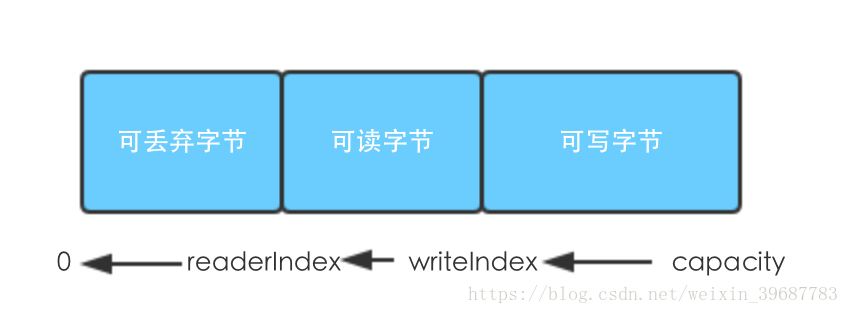
任何新分配的、包装的或者复制的默认大小readerIndex/writeIndex都是0,任何read或者skip开头的都会增加readerIndex已读字节数,write开头的操作则会增加writeIndex相应字节数。另外参数中包含ByteBuf且没有目标索引的[比如 readBytes(ByteBuf dest) writeBytes(ByteBuf dest)],会影响对应的readerIndex(写的方法影响readerIndex)writeIndex(读的方法影响writeIndex)。
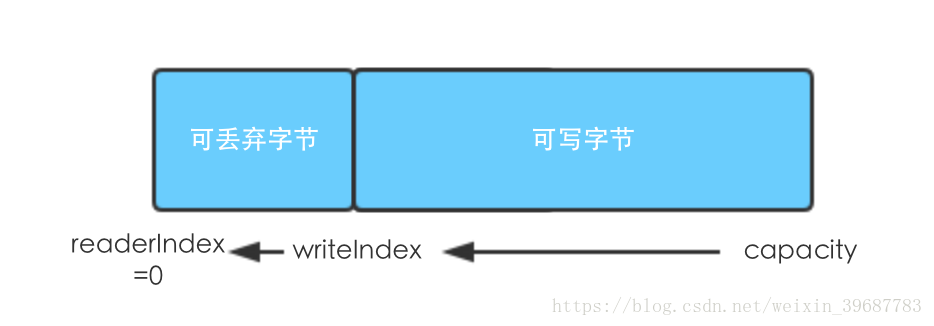
调用discardReadBytes()会移动可读字节到下标0,可读字节平移(原来可读字节的内容没有做擦除,只是移动了writeIndex)
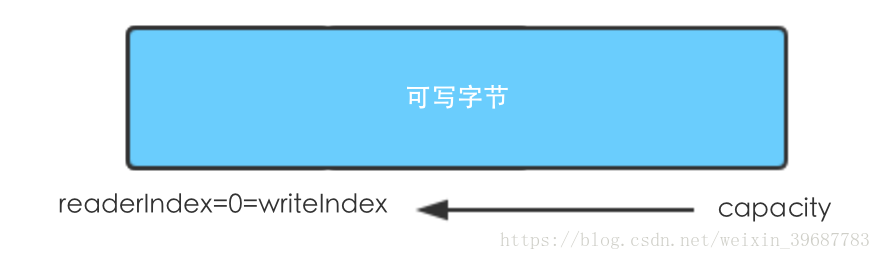
调用clear()方法,则仅重置索引,使得readIndex和writeIndex为0,不做任何内存复制
ByteBuf的派生缓冲区是什么?
ByteBuf专门呈现内容视图的方法,它们返回新的ByteBuf实例有自己的索引,但是内部存储共享,即它的内容修改了源实例也会改变。方法比如 slice / Unpooled.unmodifiableBuffer / order / readSlice / duplicate 。
需要完全独立的副本则选择使用 copy
ByteBuf有没有其它方式来管理实例?
- ByteBufAllocator:使用ChannelHandleContext(Channel每个都有不同的实例,或者ChannelHandler获取)能够拿到它的引用,Netty从4.1.x开始默认使用池化(PooledByteBufAllocator)实现,能最大程度的减少内存碎片,另外一种方式是非池化(UnpooledByteBufAllocator)每次返回一个新实例;
- Unpooled:一个工具类,提供静态方法创建未池化的ByteBuf
- ByteBufUtil:实现一些使用的方法,比如equals判断两个ByteBuf是不是相等,hexdump以十六进制打印ByteBuf内容
