

原文来自我的github
0.前言
本文主要介绍了捕获和非捕获的概念,并举了一些例子,这些都是正则表达式在js中进阶的一些用法。后面有彩蛋哦
1.捕获
1.1RegExp对象的相关属性
一般用()括住的就是捕获组,而且类似于算术中的括号,从左到右,逐层去括号。比如存在(A)((B)C)这种,他捕获到的将会是(A)((B)C)、(B)、((B)C),并在内存中存放,可以通过RegExp对象的$属性来访问到。
/(1((2)3))/.test('123')
RegExp.$1 //123
RegExp.$2 //23
RegExp.$3 //2
/(((1)2)3)/.test('123')
RegExp.$1 //123
RegExp.$2 //12
RegExp.$3 //1
这个顺序,按左括号的顺序来算的,第几个(就表示第几个$符号属性,一般从1开始,最多$9
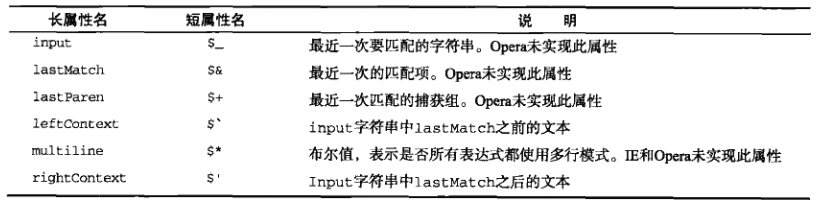
还有一些旧的RegExp长属性名,在高级程序设计108页里面
于是,我们经常有一个这样的需求,将一个这样子的字符串转为数组:
"[a,[b],c]",我知道很多人肯定说JSON.parse,恭喜,答对了。
然后控制台给你的的奖励是: Uncaught SyntaxError: Unexpected token a
在这里转过去的不是字符串abc,而是变量abc,所以就直接报错:Unexpected token a in JSON at position 1,想要parse,那么这个字符串应该是这样子"['a',['b'],'c']",这时候,我们可以用正则把他们换掉:
"[a,[b],c]".replace(/\w+/g,"'$&'"),
上面高程都说了$&匹配的是最近匹配的结果,我们把匹配到的字串变成被两个引号包围的字符串,这次在parse就能正常用了。
另外,简写的话还是有很多不兼容的问题的,最好写全称
1.2数字的反向引用
有的人就问,用正则怎么匹配AABB类型的词语?比如高高兴兴、亮晶晶这些。在正则里面反斜杠+数字就可以做到,表示重复第n个捕获组的内容,这个n和上面$后面的数字同理:
/(.)\1(.)\2/.test('高高兴兴') //TRUE,第一个和第二个相同,第三四个相同
/(.)(.)\2/.test('亮晶晶') // TRUE ,后面两个相同
1.3 replace
replace第二个参数还可以是一个函数,他的参数是matches,...catches,index。即是匹配结果,捕获组,匹配位置,准确来说,第一个参数是匹配结果,最后一个参数是匹配位置,中间所有的参数都是捕获组。
于是对于一个常见的小需求:让字符串的连续字符变成一个
'aaaabbbbccc' =>'abc'
我们可以这样子写
'aaaabbbbccc' .replace(/(\w)\1+/g,function(a){
return a[0]
})
//当然还可以这样子
'aaaabbbbccc' .replace(/(\w)\1+/g,'$1')
//还可以手动设置
'aaaabbbbccc' .replace(/(\w)\1+/g,function(a){
return a
}(1))//111
2.非捕获
以 (?) 开头的组是非捕获组,它不捕获文本 ,也不针对组合计进行各种操作,不将匹配到的字符存储到内存中,从而节省内存。也就是上面所讲的$属性他都不会具有。一般用于只需要检测结果的情况。 (?:a)非捕获一个a
/(?:a)1(?:b)/.test('a1b') //true
RegExp.$1 //''
var reg = /(?:\d{4})-(\d{2})-(\d{2})/
var date = '2018-01-02'
reg.test(date)
RegExp.$1 // 01
RegExp.$2 // 02
2.1断言
也有人叫前瞻,顾名思义,就是往前面(右边)看,看看是不是某个东西。
(?=x) 匹配后面是x的数据 :
/i am (?=a)/.test('i am a') //你右边是a
(?!x) 匹配后面不是x的数据
/i am (?!a)/.test('i am b') //你右边不是a
2.2筛选
(?!B)[A-Z]:在大写字母集合中,除去B
/(?!B)[A-Z]/.test('A') //true
/(?!B)[A-Z]/.test('B') //false
3.匹配模式
3.1惰性匹配和贪婪模式
*? 重复0次或更多次 +? 重复一次或更多次 ?? 重复0次或一次 {n,}? 重复n次或更多次 {n,m}? 重复n到m次
以上所有的匹配都是尽可能的少重复,只要满足条件就行了,不继续匹配了,在某个程度来说也是性能优化的方法之一。 那么贪婪模式就是没有做了上面的措施的都属于贪婪模式,比如正则元字符、量词单独出现的情况。
对于字符串'abbba'使用/ab*/g和/ab*? /g 贪婪模式:ab* 结果:abbb 和 a,第一次找到了a,继续找发现后面接几个b也是符合的,直到发现了第二个a才停止,再找到第二个a 惰性匹配:ab*? 结果:a 和 a,第一次找到了a,*的要求是不需要b也可以,所以停止,接着又找到第二个a
彩蛋:
检测一个数是否是质数的方法 相信大家都见过一个很强大的函数,一行代码判断出一个数是不是质数:
function isPrime(n){
return n<2?false:!/^(11+?)\1+$/.test(Array(n+1).join('1'))
}
看上去好像很牛逼,容我细细道来: 首先最小的质数是2,所以先判断是否小于2 如果大于2,先创建一个长度是n的字符串,里面铺满了1。Array(n+1)创建n+1个空位(undefined),再用1作为分隔符分开转化为字符串,所以就得到一个长度为n的字符串,全是1组成
- ^11+?怎么理解 表示以1开头,后面惰性匹配多个1(1个或者无穷个)
- \1+$怎么理解 表示重复^11+?这段匹配到的内容
- 合起来怎么理解 神奇的地方来了,首先,惰性匹配的是一个1,也就是11,后面重复11的整数次,也就是重复2次4次6次...等等,如果刚刚好匹配到了,说明这个数能被整除,说明他不是质数。如果后面的字符串不能构成2的整数倍个11,那么第一轮惰性匹配失败。 接着第二轮惰性匹配,匹配11,也就是前面捕获的是111,那么后面就开始重复111的整数倍,如果刚刚好能匹配完,说明不是质数 接着第三轮,匹配111,捕获到1111,后面重复1111的整数倍 ... 直到不能再匹配,说明这个数就是质数。 其实,里面相当于循环
for(var i = 2;i<n;i++){
if(n%i==0){return false}
}
return true
正则的强大,真的是法力无边。jQuery作者的正则,号称世界上最强的选择器sizzle,就是强大正则做出来的(晚点再更新sizzle解读)
