

摘要:容器通过集装箱式的编译、打包、部署,大大提高了应用的迭代速度。对于架构师而言,容器带来的是分钟级的部署、秒级的伸缩与恢复、一个量级的迭代速度提升、50%左右的基础成本节省。
简介
容器通过集装箱式的编译、打包、部署,大大提高了应用的迭代速度。对于架构师而言,容器带来的是分钟级的部署、秒级的伸缩与恢复、一个量级的迭代速度提升、50%左右的基础成本节省。但是对于落地实施容器的开发者而言。80%的工作处理的是容器前和容器后的问题,容器前指的是如何本地开发、集成、测试并部署到容器环境;而容器后指的是如何对部署到容器环境后的监控、运维、告警与调优。今天我们主要来探讨的是如何在容器的环境中进行资源维度的监控。
先谈容器与监控
关于容器的监控方案有非常多的种类,大家耳熟能详的一些组件包括:prometheus、Telegraf、InfluxDB、Cadvisor、Heapster等等。但是从原理上来讲无外乎分为推模式采集与拉模式采集。推模式采集是指通过部署相应的agent,将监控的指标推送到server再进行数据聚合和报警的方式,例如Telegraf就是这种模式的代表。拉模式采集是指通过中心化的server使用API或者脚本等方式从容器直接拉取资源利用率的方式,而prometheus则是这种方式的集大成者。和传统应用监控相比,容器监控面临更大的挑战:首先由于容器更多的是在资源池中调度,传统的静态配置化的监控agent就变得非常麻烦,如果只在宿主机部署监控agent则会造成缺乏必要信息来识别监控对象;其次容器的生命周期与传统应用相比而言会更加短暂,而由容器抽象的上层概念例如swarm mode中的service或者kubernetes中的ReplicaSet、Deployment等等则没有太好的办法从采集的数据中进行反向的抽象,造成单纯的容器监控数据无法有效的进行监控数据的聚合和告警,一旦应用的发布可能会导致原有的监控与报警规则无法生效;最后容器的监控需要更多的维度,资源维度、逻辑资源的维度、应用的维度等等。
如何在容器服务上进行资源监控
其实容器之所以难以监控的主要原因在于无法将逻辑的概念和物理概念无法在监控数据、生命周期上面实现统一。阿里云容器服务Kubernetes与云监控进行了深度集成,用应用分组来抽象逻辑概念,今天我们来看下如何进行Kuberbetes的资源监控和告警。
首先Kubernetes节点从职能上分为Worker和Master两种不同的节点。Master节点上面通常会部署管控类型的应用,整体的资源要求以强鲁棒性为主;而Worker节点更多的承担实际的Pod调度,整体的资源以调度能力为主。当你创建一个Kubernetes集群时,容器服务会为你自动创建两个资源分组,一个是Master组,一个是Worker组。Master组中包含了Master节点以及与其相关的负载均衡器。Worker组包含了所有的工作节点。
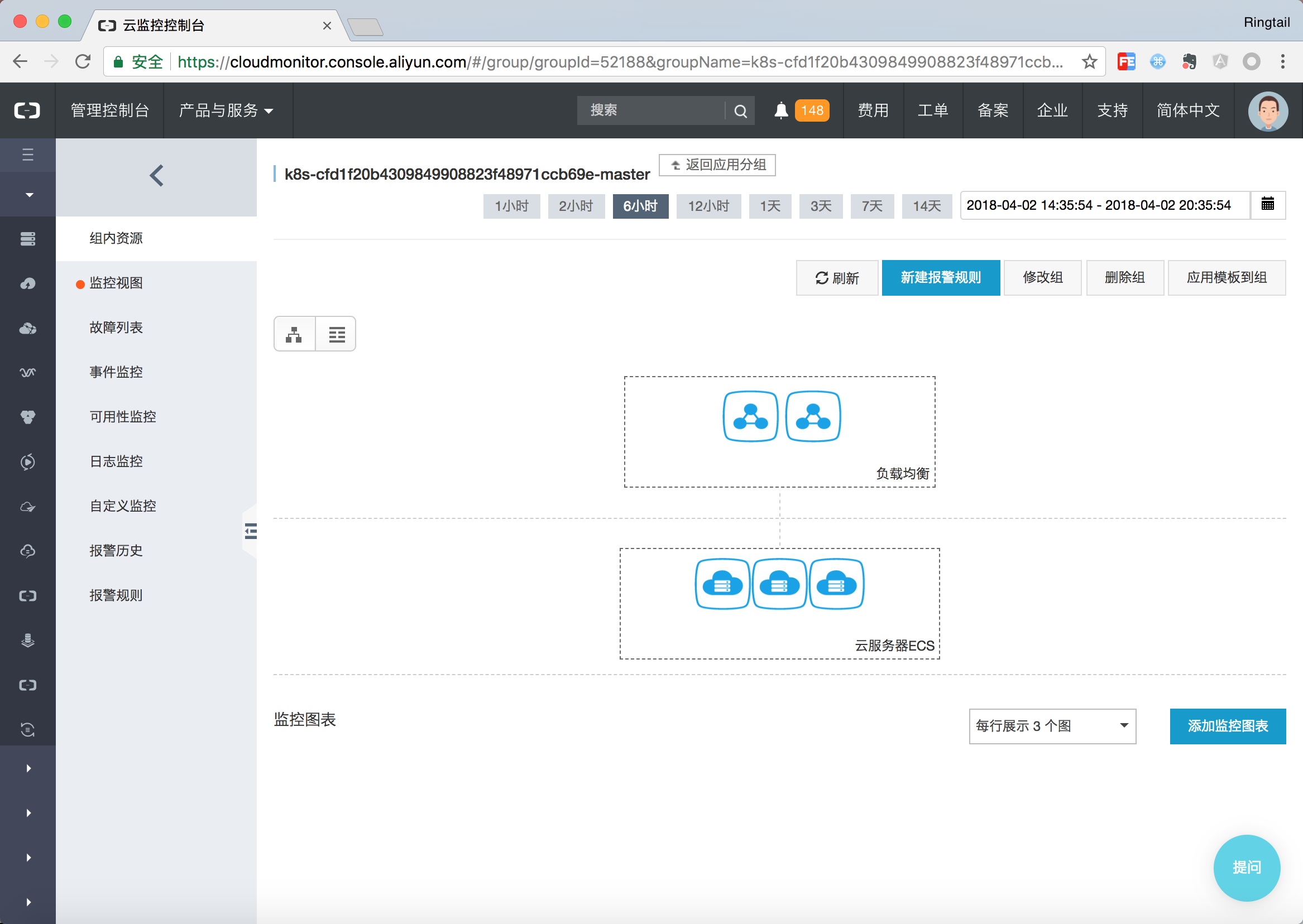
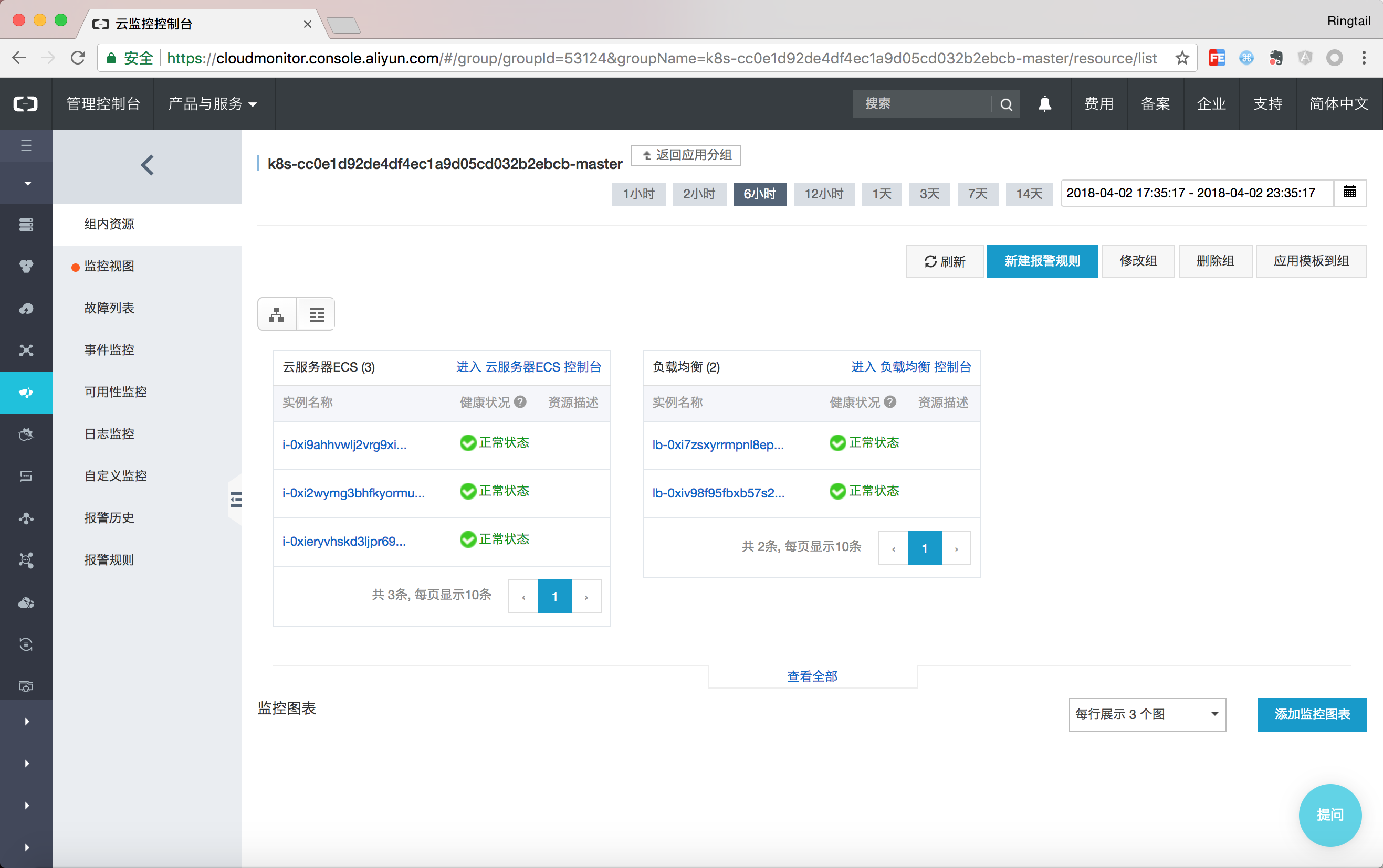
可以通过点击列表视图显示当前资源分组中的资源,例如本例中Master分组包含了三个Master节点以及2个SLB。另外任何在资源组下的资源的报警规则都会被自动继承,因此在拓扑总览页面即可看到所有资源的健康状态。
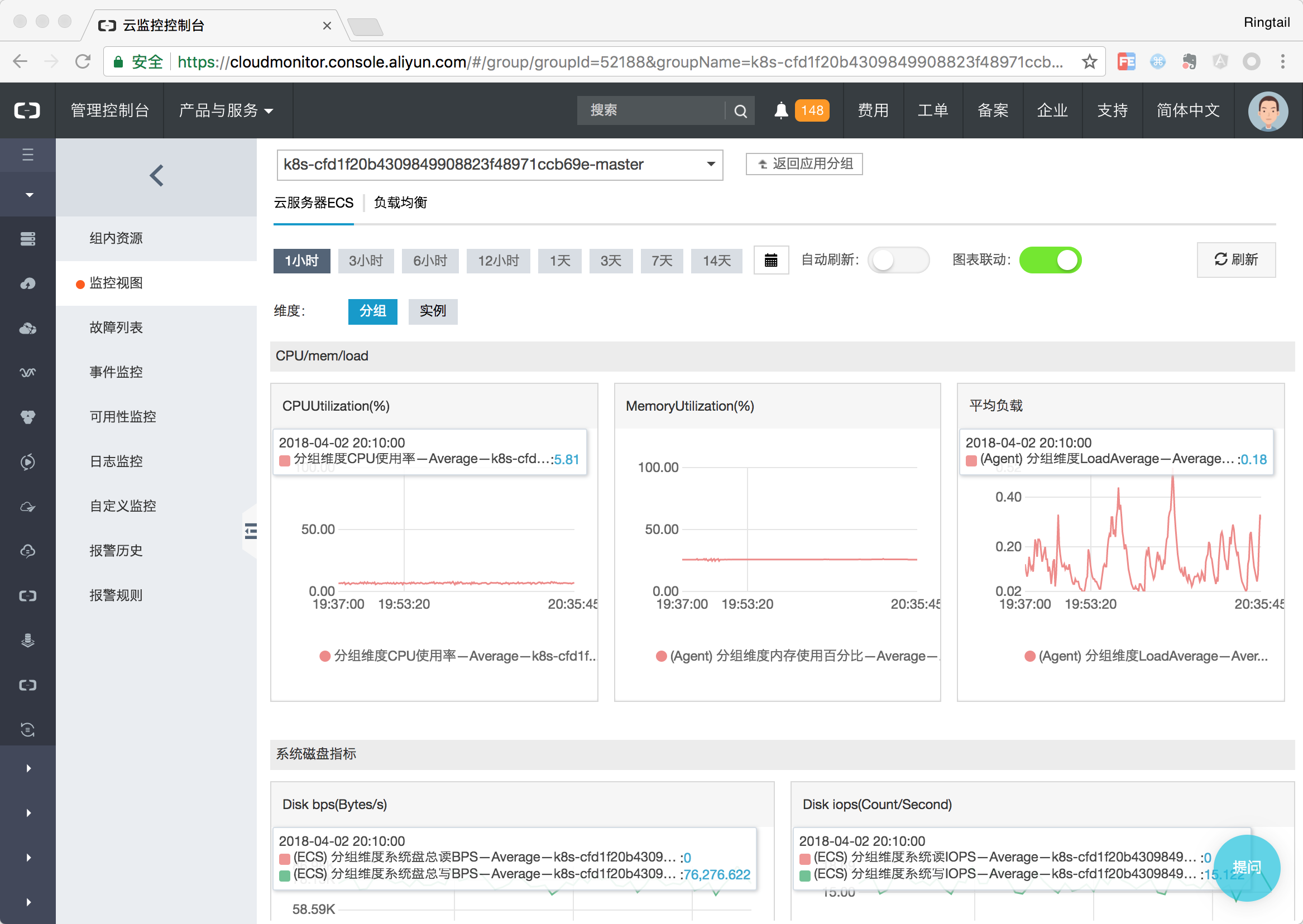
在监控视图中可以详细的在组级别以及实例级别查看详细的监控数据
对于Mater节点而言,其上运行的各种组件的健康状态是更加重要的,因此在Master分组中设置了所有节点的核心组件的健康检查,健康检查状态出现问题时即可通过钉钉、邮件、短信的方式在第一件获取到Kubernetes的集群状态。
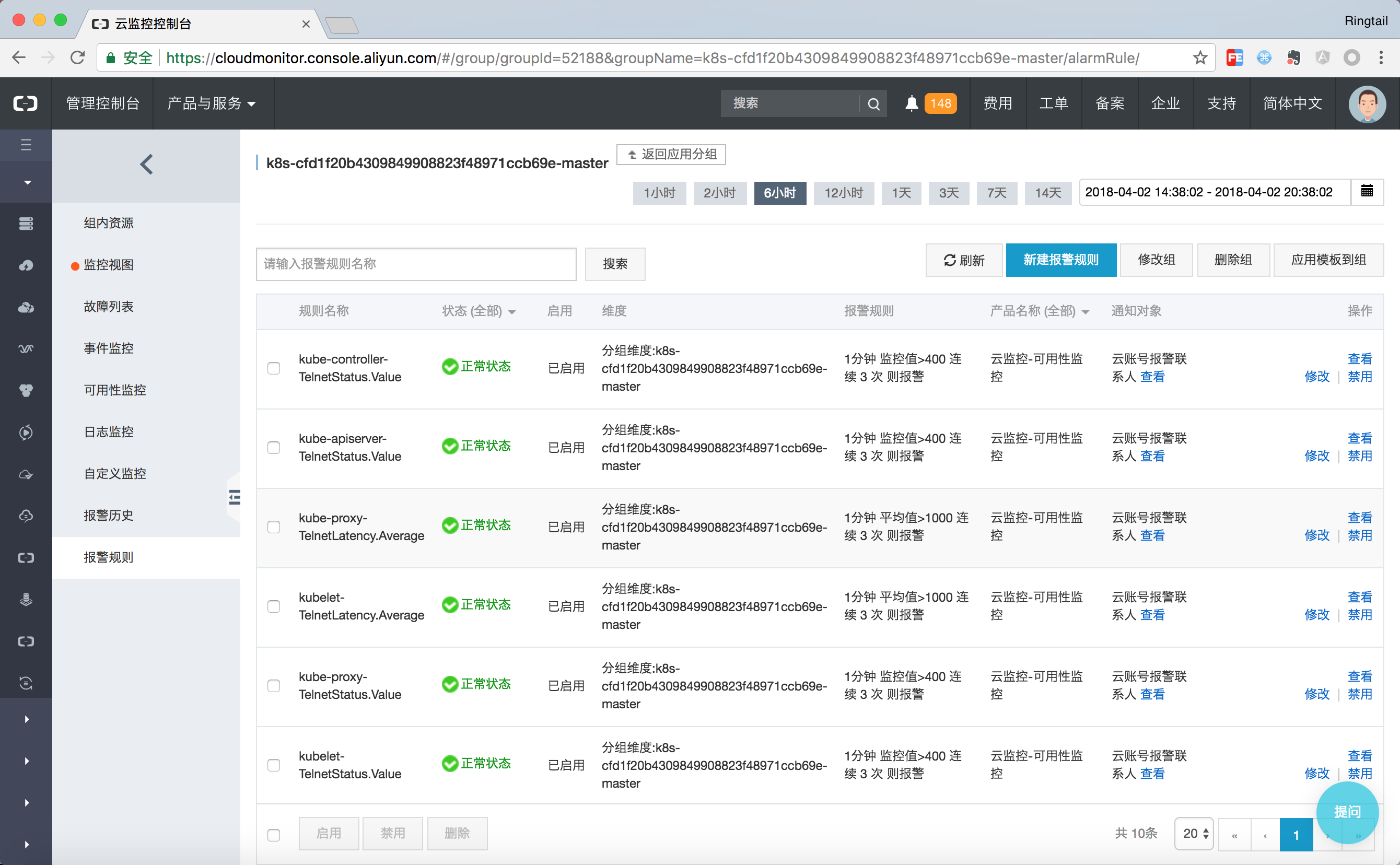
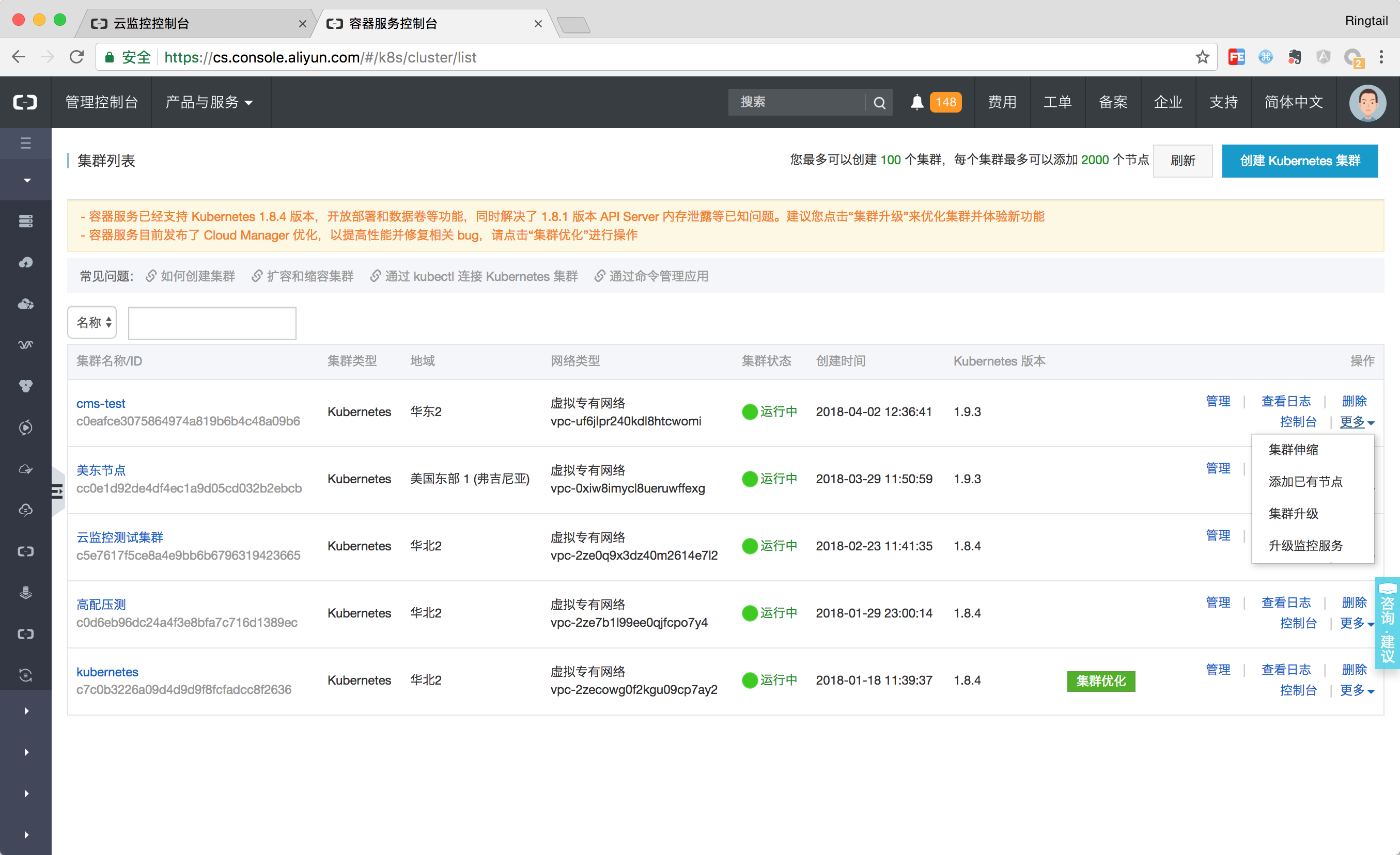
对于版本在1.8.4及以上的老集群而言,可以通过升级监控服务的方式快速建立资源报警分组。对于资源组中的资源可以通过新建报警规则的方式设置自定义的报警,而报警规则会自动应用到资源组中,且在集群自动伸缩等场景也会自动添加。
最后
本片文章我们讲解了如何如何通过资源分组进行监控与告警,针对kubernetes的pod、service的监控也即将在4月份进行发布,尽请期待。
阅读更多干货好文,请关注扫描以下二维码:

