

把搜索到的关键字 test<em>1</em> 变成 test<strong style="color:#43B7FF">1</strong>
搜索到的关键字高亮,
if ([distributorMarketProduct.name containsString: @"<em>"]) {
NSString * rawStr = distributorMarketProduct.name;
// (lldb) po rawStr: test<em>1</em>
NSString * pattern = @"em\\>.+\\<\\/em";
NSError * error = nil;
NSRegularExpression * patternFormatter = [NSRegularExpression regularExpressionWithPattern: pattern options: NSRegularExpressionDotMatchesLineSeparators error: &error ];
NSArray<NSTextCheckingResult *> * textCheckingResults = [patternFormatter matchesInString: rawStr options: kNilOptions range: NSMakeRange(0, rawStr.length)];
NSMutableString * htmlStr = [NSMutableString stringWithString: rawStr];
NSTextCheckingResult * aResult = textCheckingResults.lastObject;
NSString * tempKeyStr = [rawStr substringWithRange: aResult.range ];
NSString * kWords = [tempKeyStr substringWithRange: NSMakeRange(3, tempKeyStr.length-7)];
for (NSTextCheckingResult * strCheckingResult in [textCheckingResults reverseObjectEnumerator]) {
NSString * templateStr = [NSString stringWithFormat: @"strong style=\"color:#43B7FF\"\\>%@<\\/strong" , kWords];
NSString * replaceStr = [patternFormatter replacementStringForResult: strCheckingResult inString: rawStr offset: 0 template: templateStr ];
[htmlStr replaceCharactersInRange: strCheckingResult.range withString: replaceStr];
}
// (lldb) po htmlStr: test<strong style="color:#43B7FF">1</strong>
NSAttributedString * attrStr = [[NSAttributedString alloc] initWithData: [htmlStr dataUsingEncoding: NSUnicodeStringEncoding] options: @{NSDocumentTypeDocumentAttribute: NSHTMLTextDocumentType} documentAttributes:nil error: nil ];
self.productsDescLabel.attributedText = attrStr;
}
代码很简单,不注释了。
NSHipster 做功能的 时候, 太好用了,
文尾的例子,改一下,就好了。

NSHipster
原文: NSRegularExpression (http://nshipster.com/nsregularexpression/)
原作者:Nate Cook (http://nshipster.com/authors/nate-cook/)
遇到问题,用NSRegularExpression
其实呢,有一些,是要注意的。
正则表达式是一种 DSL, 有一些讨论。说不好,毕竟 Regex 都是各种符号。说好,Regex简明强大,用途广泛。
公认的是,Cocoa 给NSRegularExpression 设计了冗长的API. 先比对下 Ruby ,这段 Ruby 代码的作用是,从HTML代码片段中提取URL.
htmlSource = "Questions? Corrections? <a href=\"https://twitter.com/NSHipster\"> @NSHipsteror</a> or <a href=\"https://github.com/NSHipster/articles\">on GitHub.</a>"
linkRegex = /<a\s+[^>]*href="([^"]*)"[^>]*>/i
links = htmlSource.scan(linkRegex)
puts(links)
# https://twitter.com/NSHipste
# https://github.com/NSHipster/articles
Ruby 代码三行,
现在看Swift 中用 NSRegularExpression ,同样的功能实现(从HTML代码片段中提取URL.)
let htmlSource = "Questions? Corrections? <a href=\"https://twitter.com/NSHipster\"> @NSHipsteror</a> or <a href=\"https://github.com/NSHipster/articles\">on GitHub.</a>"
let linkRegexPattern = "<a\\s+[^>]*href=\"([^\"]*)\"[^>]*>"
// 比起Ruby 的, 多了一个转义字符 '\'
let linkRegex = try! NSRegularExpression(pattern: linkRegexPattern, options: .caseInsensitive )
let matches = linkRegex.matches(in: htmlSource, range: NSRange(location: 0, length: htmlSource.utf16.count))
let links = matches.map{ result -> String in
let hrefRange = result.rangeAt(1)
let start = String.UTF16Index(encodedOffset: hrefRange.location)
let end = String.UTF16Index(encodedOffset: hrefRange.location + hrefRange.length)
return String(htmlSource.utf16[start..<end])!
}
print(links)
// ["https://twitter.com/NSHipster", "https://github.com/NSHipster/articles"]
{
效果图:
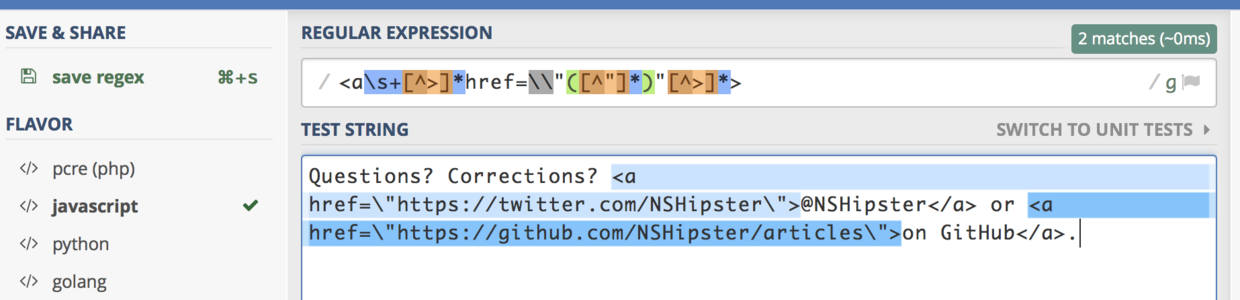
简单说明:
第一段,<a\\s+ , 先找 <a 两个特定字符, 再来一个转义,寻找一到多个空格。
第二段, [^>]* , 要求 紧接着的任意的字符串中,不能包含 > .
第三段, href=\" . 寻找紧接着 href=\"
第四段, ([^\"]*),紧接着的任意字符串不得包含 \"
第五段, \"[^>]*> , 先来一个 转义,再要求紧接着的字符串满足 ,* 和 > 之间, 不包含 > .
}
NSRegularExpression 不好的,就说到这里。
原文(英文原版)不会深入浅出地讲解正则表达式(要自己学习 通配符‘*’ ‘+’ , 反向引用‘^’ ,提前量‘[]’ ,等等 )
Swift 中的 Regex 学习, NSRegularExpression, NSTextCheckingResult , 注意下难点、特例, 就可以了。
字符串方法 , NSString Methods
上手 Cocoa 的正则,当然不用 NSRegularExpression .
NSString 中的range(of:...) 方法 可实现轻量级的字符串查找,需要用 .regularExpression 切换 regular expression mode . ( OC 的 NSString, 对应 Swift 中的 String)
let source="For NSSet and NSDictionary, the breaking..."
// Matches anything that looks like a Cocoa type:
// UIButton, NSCharacterSet, NSURLSession, etc.
let typePattern = "[A-Z]{3,}[A-Za-z0-9]+"
if let typeRange = source.range(of: typePattern , options: .regularExpression){
print("First type: \(source[typeRange])")
// First type: NSSet
}
{
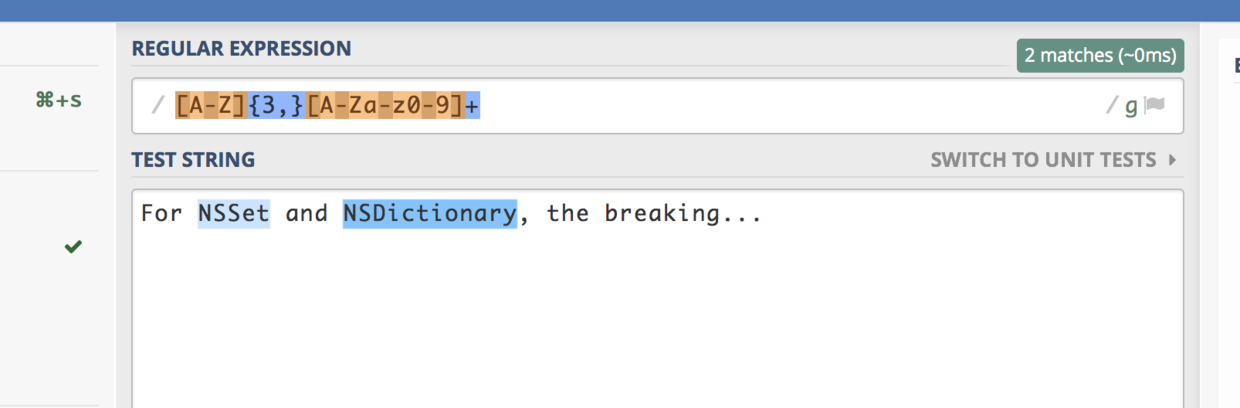
link: https://regex101.com/r/U7TC8v/1
第一段, [A-Z]{3,} , 用于匹配至少3个A-Z 中的字符。
第二段, [A-Za-z0-9]+ , 用于匹配至少一个该集合中的字符,A-Z 之间 加上 a-z 之间, 再加上 0-9 之间
}
替换也是常用的功能,同样的选项option, 使用 replacingOccurrences(of:with:...) .
下面,用一个看起来怪的代码,在上句中的coco 类型单词外面加括号。看起来清楚一些吧。
let markedUpSource = source.replacingOccurrences(of: typePattern, with: "`$0`", options: .regularExpression)
print(markedUpSource)
// "For `NSSet` and `NSDictionary`, the breaking...""
{
说明:
这里有一个 正则表达式中,获取正则分段的概念。
可以参见 这个链接: https://stackoverflow.com/questions/432493/how-do-you-access-the-matched-groups-in-a-javascript-regular-expression
}
用上面的替换模版,正则可以处理推导分组。西方有一个关于元音的字母变换,
let ourcesay = source.replacingOccurrences(of: "([bcdfghjklmnpqrstvwxyz]*)([a-z]+)", with: "$2$1ay", options: [.regularExpression,.caseInsensitive])
print(ourcesay)
// "orFay etNSSay anday ictionaryNSDay, ethay eakingbray..."
{
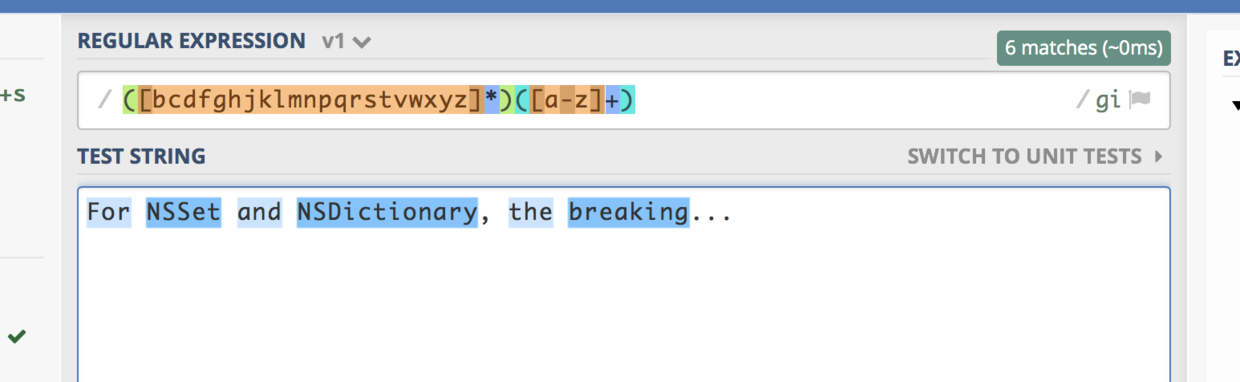
link : https://regex101.com/r/lZxWuY/2
第一段, ([bcdfghjklmnpqrstvwxyz]*) , 匹配不限长度的 不含 a e i o u 的 任意英文字母。
第二段, ([a-z]+) , 匹配 至少一个长度的 任意英文字母
}
很多需要运用正则的场景下,上面两个方法就可以了。复杂的功能实现,就要用到NSRegularExpression这个类了。首先, 解决Swift中的一个正则新手易犯错误。
NSRangeand Swift
比起 Foundation 的 NSString , Swift有着作用域更大、更复杂的API ,来处理字符串的字符和子串。Swift的标准库有四种接口来处理字符数据,可以用字符、Unicode 标量、UTF-8 码、 UTF-16 码 来获取字符串的数据。
这与 NSRegularExpression 相关,很多 NSRegularExpression 方法使用 NSRange, 用 NSTextCheckingResult 对象保存匹配到的数据。 NSRange 使用整型 integer ,记录他的起始点 location 和 字符长度 length 。但是字符串 String 是不用整型 integer 作为索引的
let range = NSRange(location: 4, length: 5)
// 下面的代码,是编不过的
source[range]
source.characters[range]
source.substring(with:range)
source.substring(with:range.toRange()!)
接着来。
Swift 中的 String 其实是通过 utf16 接口操作的,同 Foundation 框架下 NSString 的 API 一样。可以通过 utf16 接口的方法,用整型 integer 创建索引。
let start = String.UTF16Index(encodedOffset: range.location)
let end = String.UTF16Index(encodedOffset: range.location + range.length)
let substring = String(source.utf16[start..
// substring 现在是 "NSSet"
下面放一些 String 的 Util 代码,调用 Swift 相关正则的语法糖, 有 Objective-C 的感觉
extension String{
/// 这个 nsrange 属性 ,包含了字符串的所有范围
var nsrange: NSRange{
return NSRange(location:0,length:utf16.count)
}
/// 用之前给出的 nsrange 属性,返回一个字串。
/// 如果字符串中没有这个范围, 就 nil 了
func substring( with nsrange: NSRange) -> String?{
guard let range = Range(nsrange, in: self)
else { return nil }
return String( self[range] )
}
/// 返回 与之前掏出来的 nsrange 属性,等同的 range
/// 如果字符串中没有这个范围, 就 nil 了
func range(from nsrange: NSRange) -> Range?{
guard let range = Range(nsrange, in: self)
else { return nil }
return range
}
}
接下来体验的 NSRegularExpression ,有用到上面的 Util 方法。
NSRegularExpression 和 NSTextCheckingResult
之前学习了在字符串中找出第一个匹配到的数据,与匹配到的数据之间的替换。复杂些的情况,就要用到 NSRegularExpression 了。先造一个简单的文本各式匹配 miniPattern ,找出文本中的 *bold* 和 _italic_
造一个 NSRegularExpression 对象,要传入一个匹配规则的字符串 pattern ,还有一些选项可以设置。miniPattern 用星号 * 或 下划线 _ 开始查找匹配的单词。找到星号或下划线后,就匹配一个到多个字符的格式,用找到的第一个匹配的字符再次match终止一次查找。匹配到的首字母和文本,都会被保存到查询结果中。
let miniPattern = "([*_])(.+?)\\1"
let miniFormatter = try! NSRegularExpression(pattern: miniPattern, options: .dotMatchesLineSeparators)
// 如果 miniPattern 有误, NSRegularExpression 初始化就会抛异常。
如果 pattern有误, NSRegularExpression 初始化就会抛异常。一旦 NSRegularExpression 对象建好了,就可以用它处理不同的字符串。{
说明:
"([*_])(.+?)\\1" , 这个正则表达式 分三段,
第一段([*_]) ,匹配 中括号 中的 任意一个字符, 就是 * 或者 _ ;
第二段(.+?) , 匹配 长度大于1的 任意字符串;
第三段 \\1, 有一个转义字符, 匹配之前获取到的第一个同等字符串
}
let text = "MiniFormatter handles *bold* and _italic_ text."
let matches = miniFormatter.matches(in: text, options: [], range: text.nsrange )
// matches.count == 2
调用matches(in:options:range:) 方法,可以取出包含 NSTextCheckingResult 元素的数组。 多种文本处理类都有用到NSTextCheckingResult 类型,譬如 NSDataDetector 和 NSSpellChecker . 返回的数组中,一个匹配有一个NSTextCheckingResult .
通常要取得的是匹配到的范围,就在每个结果的range属性里面。通常要取得的还有,正则表达式中任意匹配到的范围。 可以通过numberOfRanges 属性 和rangeAt(_:) 方法,找出指定的范围。
range(at:)
Returns the result type that the range represents.
range(at:) 方法, 返回的结果就是对应的范围
Discussion
A result must have at least one range, but may optionally have more (for example, to represent regular expression capture groups).
Passingrange(at:)the value 0 always returns the value of the therangeproperty. Additional ranges, if any, will have indexes from 1 to numberOfRanges-1.
讨论下,
返回的结果,至少有一个范围。往往有更多,可选的。( 正则表达式捕获组,对应的)
range(at:) 方法返回的第一个结果,就是 range 属性的值。如果有额外的,返回的结果对应的索引就是从 1 到 numberOfRanges-1
引用下苹果文档, https://developer.apple.com/documentation/foundation/nstextcheckingresult/1416732-range
range 0 是完全匹配到的范围,也是肯定能取到的。
然后从第1个到 第(numberOfRanges - 1)个的 ranges 数组中的值,就是分段,对应每一段正则匹配的结果。
使用之前给出的NSRange的取子串方法,就可以用 range 来取出匹配到的结果。
for match in matches {
let stringToFormat = text.substring(with: match.range(at: 2) )!
switch text.substring(with: match.range(at: 1) )! {
case "*" :
print("Make bold: '\(stringToFormat)'")
case "_":
print("Make italic: '\(stringToFormat)'")
default: break
}
}
// 打印出
// Make bold: 'bold'
// Make italic: 'italic'
对于基础的替换,直接用stringByReplacingMatches(in:options:range:with:) 方法,String.replacingOccurences(of:with:options:) 的加强版 。上例中,不同的正则匹配 ( bold , italic),用不同的替换模版。
按照倒叙,循环访问这些匹配结果,这样就不会把后面的 match 范围搞乱。
var formattedText = text
Format:
for match inmatches.reversed () {
let template: String
switch text.substring(with: match.range(at:1) ) ?? ""{
case "*":
template = "$2"
case "_":
template = "$2"
default: break Format
}
let matchRange = formattedText.range(from:match.range)! // see above
let replacement = miniFormatter.replacementString( for: match, in: formattedText, offset: 0, template: template)
formattedText.replaceSubrange( matchRange , with: replacement)
}
// 'formattedText' is now:
// "MiniFormatter handles bold and italic text."
通过自定义的模版,调用miniFormatter.replacementString(for:in:...) 方法, 然后呢,每一个NSTextCheckingResult 实例会随之产生一个对应的替换字符串。
Expression and Matching Options , 表达式与匹配选项
NSRegularExpression 是高度可配置的。弄一个实例,或者调用执行正则匹配的方法,都可以传不同选项的组合。
NSRegularExpression.Options
* .caseInsensitive : 字母大小写忽略。 开启字母大小写忽略的匹配,就是 i 标记
* .allowCommentsAndWhitespace : 允许注释、空格。 忽略 # 和句尾间任意的空格和注释。所以所以你可以尝试格式化和记录正则匹配,有了注释和空格,正则会好读一点。 等价于 x 标记
* .ignoreMetacharacters: 忽略元符号,忽略关键字。String.range(of:options:) 方法中的去正则化,与 .regularExpression 正则选项相反。这实际上就是正则变为简单的文本搜索,忽略所有的正则关键字和运算符。
* .dotMatchesLineSeparators: 句点分行匹配。允许 , 关键字匹配换行符以及其他字符。就是 s 标记。
* .anchorsMatchLines: 句中锚点匹配。允许 ^ (开始)和 $ (结束)关键字,匹配句中的开始和结束。而不仅仅是输入的整段的开始和结尾。就是 m 标记
* .useUnixLineSeparators, .useUnicodeWordBoundaries: 最后两项优化了更多特定的行和字的边界处理。Unix 行分隔符。
NSRegularExpression.MatchingOptions 正则表达式的匹配选项
一个 NSRegularExpression 正则表达式实例中,可以传入选项来调整匹配的方法。
* .anchored: 锚定的。仅匹配搜索范围的开头第一段。
* .withTransparentBounds: 超过界限。允许正则在搜索范围前,向前查找。反之,向后查找。还有单词的边界。(尽管不适用于,实际的匹配字符)
static var withTransparentBounds: NSRegularExpression.MatchingOptions
Specifies that matching may examine parts of the string beyond the bounds of the search range, for purposes such as word boundary detection, lookahead, etc. This constant has no effect if the search range contains the entire string.
See enumerateMatches (in: options: range: using:) for a description of the constant in context.
苹果 链接: https://developer.apple.com/documentation/foundation/nsregularexpression.matchingoptions
* .withoutAnchoringBounds : 无锚定界限。 让 ^ 和 $ 关键字仅匹配字符串的开始和结尾,而不是搜索范围的开始和结束。
* .reportCompletion ( 报告完成 ) , .reportProgress ( 报告进度 ): 这些参数选项仅在下节讲的部分匹配方法中有用。当正则查找完成了,或者是耗时的匹配上有进度,相应选项会通知 NSRegularExpression 传入附加时间,调用枚举块。
Partial Matching 部分匹配
最后, NSRegularExpression 最强大的特性之一是,仅扫描字符串中需要的部分。处理长文本,挺有用的。处理耗资源的正则匹配,也是。
不要用这两个方法firstMatch(in:...) 和 matches(in:...) , 调用 enumerateMatches(in:options:range:using:) ,用闭包处理对应的匹配。
func enumerateMatches( instring :String, options:NSRegularExpression.MatchingOptions= [], range:NSRange, usingblock: (NSTextCheckingResult?,NSRegularExpression.MatchingFlags,UnsafeMutablePointer<ObjCBool>) ->Void)
苹果链接: https://developer.apple.com/documentation/foundation/nsregularexpression/1409687-enumeratematches
这个闭包接收三个参数,匹配的正则结果,一组标志选项, 一个布尔指针。 这个 bool 指针是一个只出参数,可以通过它在设定的时机停止处理。
可以用这个方法在 Dostoevsky 的 Karamazov兄弟一书中, 查找开始的几个名字。名字遵从的规则是,首名,中间父姓 ( 例如: “Ivan Fyodorovitch” )
let nameRegex = try! NSRegularExpression( pattern: "([A-Z]\\S+)\\s+([A-Z]\\S+(vitch|vna))" )
let bookString = ...
var names:Set = []
nameRegex.enumerateMatches( in: bookString, range: bookString.nsrange ){
( result , _ , stopPointer ) in
guard let result = result else { return }
let name = nameRegex.replacementString( for: result , in: bookString , offset : 0 , template: "$1 $2" )
names.insert(name)
// stop once we've found six unique names ,通过 Set 确保,6个不一样的名字文本
stopPointer.pointee = ObjCBool( names.count==6 )
}
// names.sorted():
// ["Adelaïda Ivanovna", "Alexey Fyodorovitch", "Dmitri Fyodorovitch",
// "Fyodor Pavlovitch", "Pyotr Alexandrovitch", "Sofya Ivanovna"]
通过这种途径,我们只需查找前 45 个匹配,而不是把全书中接近1300个名字都找一遍。性能显著提高。
一旦有所认识,NSRegularExpression 就会超级有用。除了 NSRegularExpression , 还有一个类NSDataDetector.NSDataDetector是一个用于识别有用信息的类,可以用来处理用户相关的文本,查找日期,地址与手机号码。通过Fundation 框架处理文本,NSRegularExpression 强大,健壮,有简洁的接口,也有深入
说明: 为了有意思一些, 我采取了意译。并加入了一些 Regex 细节与扩展资料。
文中 出现的 Swift 代码, 已校正到 Swift 4 .

谢谢观看
PS: 参考资料
文中的 Swift 代码,github 地址: https://github.com/dengV/regex_001
超好用的正则网站:101 ( https://regex101.com/ )
熟悉的 ray wenderlich tutorial: ( https://www.raywenderlich.com/30288/nsregularexpression-tutorial-and-cheat-sheet )
我升级了对应的Swift代码,github 链接 ( https://github.com/BoxDengJZ/Swift4-NSRegularExpression-Tutorial-Getting-Started )
