

基本概念
首先理解两个概念,有些东西是为了让机器认识的,有些东西是为了让人认识的。
进制(2,3,8,10,16)都是为了机器可以直接理解的。
编码(ASCII,unicode,utf-8),把只有机器认识的二进制体现为人一眼就能看明白的字符。
基础知识
- 二进制:0-1
- 八进制:0-7
- 十进制:0-9
- 16进制:0-f
位,字节,字符,字符串
- 位:bit 表现形式: 0或者1 ,最底层的体现
- 字节:byte 等于8bit 表现形式:八位的bit 一起, 如01010101,组合起来可以代表某些字符
- 字符:char 至少是1个字节即8bit. (注意:不同编码下的1字符所包含的字节是不一样的)
- 字符串:一串字符组合而成
编码
- ASCII:1个字符=1个字节=8bit。
- unicode:1个字符=2个字节=16bit。
- utf-8:可变长的编码,一个字符等于1~4个字节。
关系,转换
1. 数字
python里,整数 通过int(),bin(),oct(),hex()进行转换。
>>> 10
10
>>> bin(10)
'0b1010'
>>> oct(10)
'0o12'
>>> hex(10)
'0xa'
>>> int('0b1010',base=2)
10
>>> int('0o12',base=8)
10
2. 字符
python里,字符 通过chr(),ord()进行转换。
>>> ord('汗')
27735
>>> chr(27735)
'汗'
>>> bin(27735)
'0b110110001010111'
>>> ord('a')
97
>>> chr(97)
'a'
>>> bin(97)
'0b1100001'
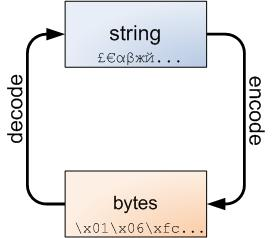
3.码制之间的转换
参考下图, 通过encode(),decode()进行转换(默认是utf8)
>>> tmp_str = '汗'
>>> tmp_str.encode()
b'\xe6\xb1\x97'
>>> b'\xe6\xb1\x97'.decode()
'汗'
重点,utf8 和 unicode 之间的区别
一个汉字,在 utf8里面是三个字节,在unicode 里面是两个字节。 不逼逼,看疗效
>>> tmp_str
'日'
>>> tmp_str.encode('unicode_escape')
b'\\u65e5'
>>> tmp_str.encode('utf8')
b'\xe6\x97\xa5'
>>> b'\\u65e5'.decode('unicode_escape')
'日'
>>> b'\xe6\x97\xa5'.decode('utf8')
'日'
