

演讲嘉宾简介:
李曦鹏,现任英伟达devTech团队高级软件工程师,毕业于中国科学院过程工程研究所,拥有近10年CUDA/HPC编程经验。主要负责深度神经网络和高性能计算的性能优化。
以下内容根据演讲嘉宾视频分享以及PPT整理而成。
本次的分享主要分为两部分:
一、TensorRT理论介绍:基础介绍TensorRT是什么;做了哪些优化;为什么在有了框架的基础上还需要TensorRT的优化引擎。
二、TensorRT高阶介绍:对于进阶的用户,出现TensorRT不支持的网络层该如何处理;低精度运算如fp16,大家也知道英伟达最新的v100带的TensorCore支持低精度的fp运算,包括上一代的Pascal的P100也是支持fp16运算,当然我们针对这种推断(Inference)的版本还支持int8,就是说我们用8位的整型来取代原来的fp32做计算,大家可以想象速度上肯定会有很大提升,但是也会需要进行一些额外的工作。
随着传统的高性能计算和新兴的深度学习在百度、京东等大型的互联网企业的普及发展,作为训练和推理载体的GPU也被越来越多的使用。我们团队的目标是让大家能更好地利用GPU,使其在做深度学习训练的时候达到更好的效果。
一、TensorRT理论解释
TensorRT项目立项的时候名字叫做GPU Inference Engine(简称GIE),Tensor表示数据流动以张量的形式。所谓张量大家可以理解为更加复杂的高维数组,一般一维数组叫做Vector(即向量),二维数组叫做Matrix,再高纬度的就叫Tensor,Matrix其实是二维的Tensor。在TensoRT中,所有的数据都被组成最高四维的数组,如果对应到CNN中其实就是{N, C, H, W},N表示batch size,即多少张图片或者多少个推断(Inference)的实例;C表示channel数目;H和W表示图像或feature maps的高度和宽度。TR表示的是Runtime。
下图是NVDIA针对深度学习平台的一系列完整的解决方案(官网有更新版本)。如果大家对深度学习有些了解的话可能会知道,它分为训练和部署两部分,训练部分首先也是最重要的是构建网络结构,准备数据集,使用各种框架进行训练,训练要包含validation和test的过程,最后对于训练好的模型要在实际业务中进行使用。训练的操作一般在线下,实时数据来之后在线训练的情况比较少,大多数情况下数据是离线的,已经收集好的,数据更新不频繁的一天或一周一收集,数据更新频繁的可能几十分钟,在线下有大规模的集群开始对数据或模型进行更新,这样的训练需要消耗大量的GPU,相对而言一般会给一个比较大的batchsize,因为它的实时性要求相对较低,一般训练模型给的是128,甚至有些极端的1024,大的batch的好处是可以充分的利用GPU设备。但是到推断(Inference)的时候就是不同的概念了,推断(Inference)的时候只需要做一个前向计算,将输入通过神经网络得出预测的结果。而推断(Inference)的实际部署有多种可能,可能部署在Data Center(云端数据中心),比如说大家常见的手机上的语音输入,目前都还是云端的,也就是说你的声音是传到云端的,云端处理好之后把数据再返回来;还可能部署在嵌入端,比如说嵌入式的摄像头、无人机、机器人或车载的自动驾驶,当然车载的自动驾驶可能是嵌入式的设备,也可能是一台完整的主机,像这种嵌入式或自动驾驶,它的特点是对实时性要求很高。同样的,Data Center也是对实时性要求很高,做一个语音识别,不能说说完了等很长时间还没有返回,所以在线的部署最大的特点是对实时性要求很高,它对latency非常敏感,要我们能非常快的给出推断(Inference)的结果。做一个不同恰当的比方,训练(Training)这个阶段如果模型比较慢,其实是一个砸钱可以解决的问题,我们可以用更大的集群、更多的机器,做更大的数据并行甚至是模型并行来训练它,重要的是成本的投入。而部署端不只是成本的问题,如果方法不得当,即使使用目前最先进的GPU,也无法满足推断(Inference)的实时性要求。因为模型如果做得不好,没有做优化,可能需要二三百毫秒才能做完一次推断(Inference),再加上来回的网络传输,用户可能一秒后才能得到结果。在语音识别的场景之下,用户可以等待;但是在驾驶的场景之下,可能会有性命之庾。
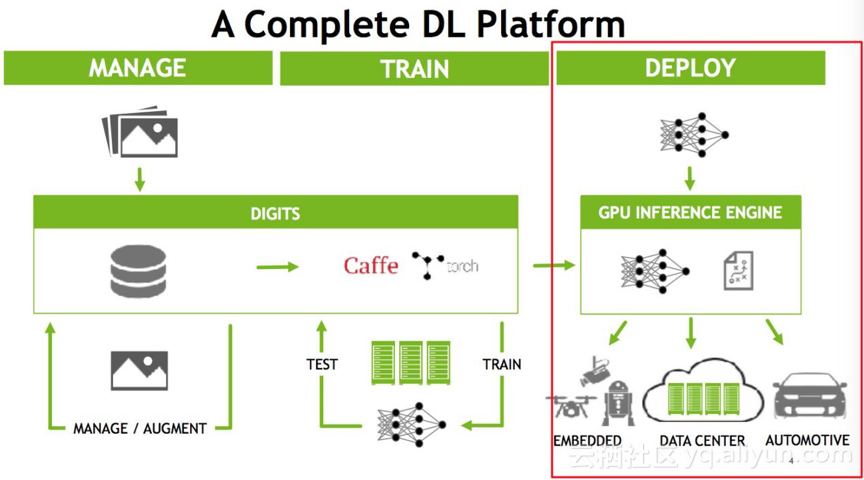
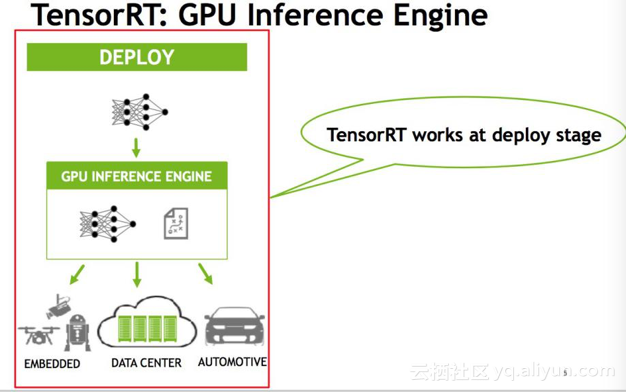
在部署阶段,latency是非常重要的点,而TensorRT是专门针对部署端进行优化的,目前TensorRT支持大部分主流的深度学习应用,当然最擅长的是CNN(卷积神经网络)领域,但是的TensorRT 3.0也是有RNN的API,也就是说我们可以在里面做RNN的推断(Inference)。
最典型的应用是图片的分类,这也是最经典的,实际上也是深度学习目前解决的比较好的一些问题。其他的例如,图片的语义分割、目标检测等都是以图片分类网络为基础进行改进的。目标检测是比较典型的例子(如下图),训练(Training)是对已经打好框的图片进行前向计算,得出的框和实际的框(ground truth)进行对比,然后再做后向更新,更新模型。真正做推断(Inference)的时候,比如一个摄像头,基本上要保证是实时的,也就是说起码要保证每秒25-30帧的速度,鉴于实际应用可能是二三十路摄像头同时进来的数据,这时候必须保证一块卡做到实时处理,还是比较有挑战性的工作。

总结一下推断(Inference)和训练(Training)的不同:
1. 推断(Inference)的网络权值已经固定下来,无后向传播过程,因此可以
1)模型固定,可以对计算图进行优化
2) 输入输出大小固定,可以做memory优化(注意:有一个概念是fine-tuning,即训练好的模型继续调优,只是在已有的模型做小的改动,本质上仍然是训练(Training)的过程,TensorRT没有fine-tuning
2. 推断(Inference)的batch size要小很多,仍然是latency的问题,因为如果batch size很大,吞吐可以达到很大,比如每秒可以处理1024个batch,500毫秒处理完,吞吐可以达到2048,可以很好地利用GPU;但是推断(Inference)不能做500毫秒处理,可以是8或者16,吞吐降低,没有办法很好地利用GPU.
3. 推断(Inference)可以使用低精度的技术,训练的时候因为要保证前后向传播,每次梯度的更新是很微小的,这个时候需要相对较高的精度,一般来说需要float型,如FP32,32位的浮点型来处理数据,但是在推断(Inference)的时候,对精度的要求没有那么高,很多研究表明可以用低精度,如半长(16)的float型,即FP16,也可以用8位的整型(INT8)来做推断(Inference),研究结果表明没有特别大的精度损失,尤其对CNN。更有甚者,对Binary(二进制)的使用也处在研究过程中,即权值只有0和1。目前FP16和INT8的研究使用相对来说比较成熟。低精度计算的好处是一方面可以减少计算量,原来计算32位的单元处理FP16的时候,理论上可以达到两倍的速度,处理INT8的时候理论上可以达到四倍的速度。当然会引入一些其他额外的操作,后面的讲解中会详细介绍FP18和INT8;另一方面是模型需要的空间减少,不管是权值的存储还是中间值的存储,应用更低的精度,模型大小会相应减小。
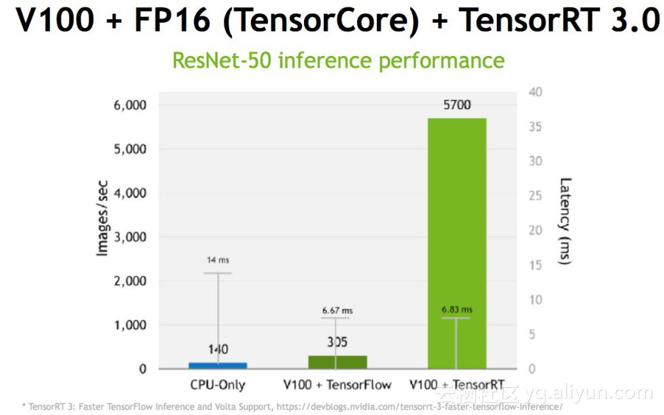
下图展示的是TensorRT的效果,当然这是一个比较极端的例子,因为该例中使用的是最先进的GPU卡V100,V100添加了专门针对深度学习优化的TensorCore,TensorCore可以完成4×4矩阵的半精度乘法,也就是可以完成一个4×4的FP16矩阵和另外一个4×4的FP16矩阵相乘,当然可以再加一个矩阵(FP16 或FP32),得到一个FP32或者FP16的矩阵的过程。TensorCore在V100上理论峰值可以达到120 Tflops.(开个玩笑,电影终结者中整个天网的计算能力相当于两块V100)。回到图中,先看一下如果只是用CPU来做推断(Inference),首先它的吞吐只能达到140,也就是说每秒只能处理140张图片,同时整个处理过程需要有14ms的延迟,也就是说用户提交请求后,推断(Inference)阶段最快需要14ms才能返回结果;如果使用V100,在TensorFlow中去做推断(Inference),大概是6.67ms的延时,但是吞吐只能达到305;如果使用V100加TensorRT,在保证延迟不变的情况下,吞吐可以提高15倍,高达5700张图片每秒,这个差别是很大的。十几倍的吞吐的提升实际上是在保证延迟的情况下成本的缩减 。
回到TensorRT的主题,之前大家普遍存在的一个疑问是在训练过程中可以使用不同的框架,为什么推断(Inference)不能用各种框架,比如TensorFlow等。当然是可以用的,但是问题是灵活性和性能是一种trade-off的关系,这是在做深度学习或训练过程中经常会遇到的一个问题。比如像TensorFlow的设计初衷是为各种各样的操作来做准备的,在早期的框架,例如Caffe中很多前后处理并不在框架里面完成,而是通过额外的程序或脚本处理,但是TensorFlow支持将所有的操作放入框架之中来完成,它提供了操作(Operation)级别的支持,使得灵活性大大提高,但是灵活性可能是以牺牲效率为代价的。TensorFlow在实现神经网络的过程中可以选择各种各样的高级库,如用nn来搭建,tf.nn中的convolution中可以加一个卷积,可以用slim来实现卷积,不同的卷积实现效果不同,但是其对计算图和GPU都没有做优化,甚至在中间卷积算法的选择上也没有做优化,而TensorRT在这方面做了很多工作。
在讲TensorRT做了哪些优化之前, 想介绍一下TensorRT的流程, 首先输入是一个预先训练好的FP32的模型和网络,将模型通过parser等方式输入到TensorRT中,TensorRT可以生成一个Serialization,也就是说将输入串流到内存或文件中,形成一个优化好的engine,执行的时候可以调取它来执行推断(Inference)。
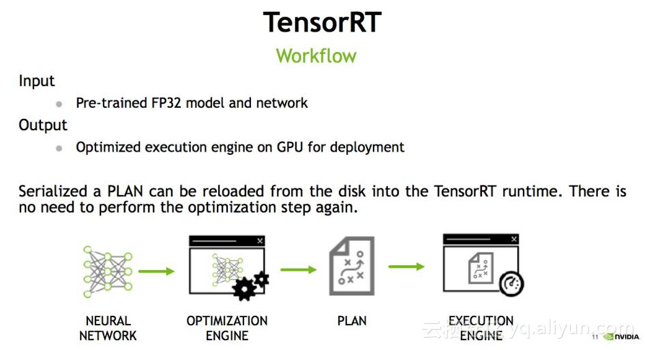
如上图所示TensorRT整个过程可以分三个步骤,即模型的解析(Parser),Engine优化和执行(Execution)。暂时抛开TensorRT,如果让大家从头写一个深度学习模型的前向过程,具体过程应该是
1) 首先实现NN的layer,如卷积的实现,pooling的实现。
2) 管理memory,数据在各层之间如何流动。
3) 推断(Inference)的engine来调用各层的实现。
以上三个步骤在TendorRT都已经实现好了,用户需要做的是如何将网络输入到TensorRT中。目前TensorRT支持两种输入方式:
1. 一种是Parser的方式,即模型解析器,输入一个caffe的模型,可以解析出其中的网络层及网络层之间的连接关系,然后将其输入到TensorRT中,但是TensorRT是如何知道这些连接关系呢?答案是API。
2. API接口可以添加一个convolution或pooling。而Parser是解析模型文件,比如TensorFlow转换成的uff,或者是caffe的模型,再用API添加到TensorRT中,构建好网络。构建好后就可以做优化。
a) 考虑到一个情况,如果有一个网络层不支持,这个有可能,TensorRT只支持主流的操作,比如说一个神经网络专家开发了一个新的网络层,新型卷积和以前的卷积都不一样,TensorRT是不知道是做什么的。比如说最常见的检测网络,有一些网络层也是不支持的,这个时候涉及到customer layer的功能,即用户自定义层,构建用户自定义层需要告诉TensorRT该层的连接关系和实现方式,这样TensorRT才能去做。
b) 目前API支持两种接口实现方式,一种是C++,另一种是Python,Python接口可能在一些快速实现上比较方便一些。
c) Parser目前有三个,一个是caffe Parser,这个是最古老的也是支持最完善的;另一个是uff,这个是NV定义的网络模型的一种文件结构,现在TensorFlow可以直接转成uff;另外下一个版本3.5或4.0会支持的onnx,是Facebook主导的开源的可交换的各个框架都可以输出的,有点类似于文档编辑中的word格式或AutoCAD中CAD的格式,虽然是由一个公司提出,但是有希望成为一个标准,各个APP去支持这个标准。像pytorch和caffe 2都是支持这个格式的,这个目前只在NGC (NVDIA GPU Cloud)上支持,但是下一个版本发行都会支持。如果某个公司新推出一个特别火的框架不支持怎么办,仍然可以采用API的方式,一层一层的添加进去,告诉TensorRT连接关系,这也是OK的。
模型解析后,engine会进行优化,具体的优化稍后会介绍。得到优化好的engine可以序列化到内存(buffer)或文件(file),读的时候需要反序列化,将其变成engine以供使用。然后在执行的时候创建context,主要是分配预先的资源,engine加context就可以做推断(Inference)。
以上是TensorRT的整个过程,大家在疑惑TensorRT是否支持TensorFlow,首先大家写的网络计算层可能都是支持的,但是有些网络层可能不支持,在不支持的情况下可以用customer layer的方式添加进去,但是有时候为了使用方便,可能没办法一层一层的去添加,需要用模型文件形式,这个取决于Parser是否完全支持。相对而言,大家在框架有过比较后会发现,caffe这个框架的特点是非常不灵活,如果要添加一个新的网络层,需要修改源代码;TensorFlow的优点却是非常的灵活。
刚才讲到TensorRT所做的优化,总结下来主要有这么几点:
第一,也是最重要的,它把一些网络层进行了合并。大家如果了解GPU的话会知道,在GPU上跑的函数叫Kernel,TensorRT是存在Kernel的调用的。在绝大部分框架中,比如一个卷积层、一个偏置层和一个reload层,这三层是需要调用三次cuDNN对应的API,但实际上这三层的实现完全是可以合并到一起的,TensorRT会对一些可以合并网络进行合并;再比如说,目前的网络一方面越来越深,另一方面越来越宽,可能并行做若干个相同大小的卷积,这些卷积计算其实也是可以合并到一起来做的。
第二,比如在concat这一层,比如说这边计算出来一个1×3×24×24,另一边计算出来1×5×24×24,concat到一起,变成一个1×8×24×24的矩阵,这个叫concat这层这其实是完全没有必要的,因为TensorRT完全可以实现直接接到需要的地方,不用专门做concat的操作,所以这一层也可以取消掉。
第三,Kernel可以根据不同的batch size 大小和问题的复杂程度,去选择最合适的算法,TensorRT预先写了很多GPU实现,有一个自动选择的过程。
第四,不同的batch size会做tuning。
第五,不同的硬件如P4卡还是V100卡甚至是嵌入式设备的卡,TensorRT都会做优化,得到优化后的engine。
下图是一个原始的GoogleNet的一部分,首先input后会有多个卷积,卷积完后有Bias和ReLU,结束后将结果concat(连接拼接)到一起,得到下一个input。
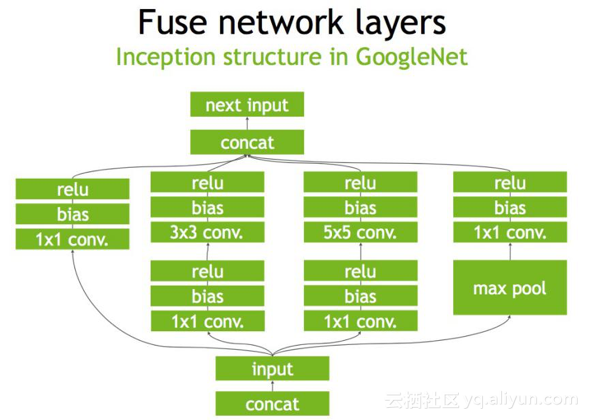
以上的整个过程可以做些什么优化呢?首先是convolution, Bias和ReLU这三个操作可以合并成CBR,合并后的结果如下所示,其中包含四个1×1的CBR,一个3×3的CBR和一个5×5的CBR。
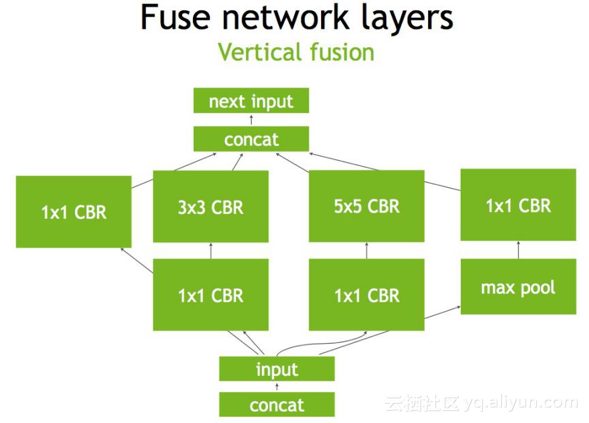
接下来可以继续合并三个相连的1×1的CBR为一个大的1×1的CBR(如下图),这个合并就可以更好地利用GPU。
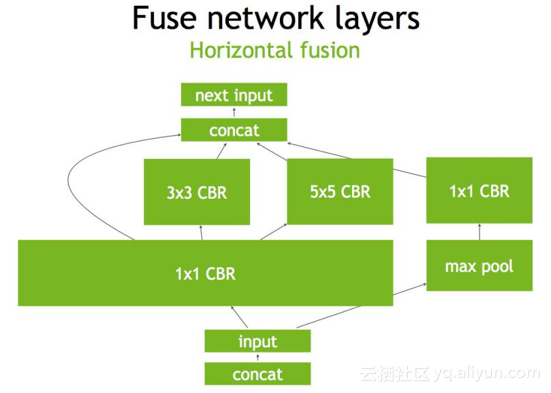
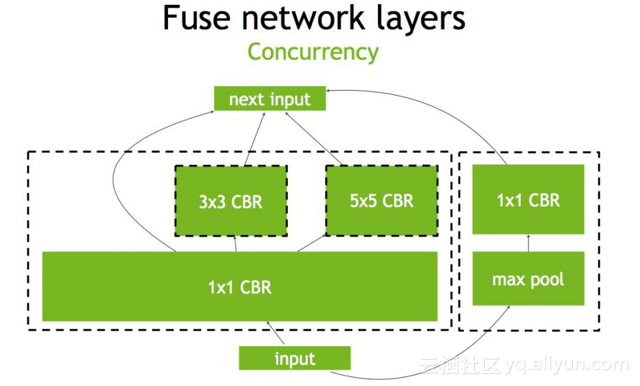
继而concat层可以消除掉,直接连接到下一层的next input(如下图)。
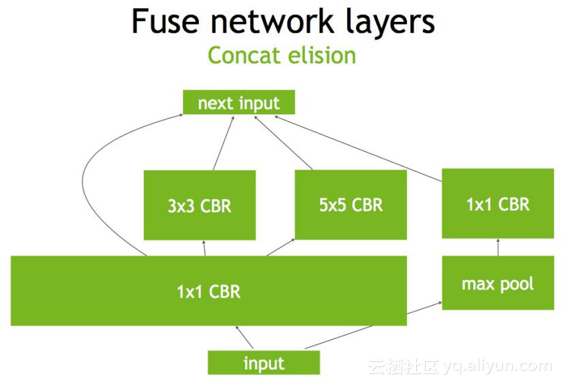
另外还可以做并发(Concurrency),如下图左半部分(max pool和1×1 CBR)与右半部分(大的1×1 CBR,3×3 CBR和5×5 CBR)彼此之间是相互独立的两条路径,本质上是不相关的,可以在GPU上通过并发来做,来达到的优化的目标。
二、TensorRT高级特征介绍
前面介绍了TesorRT的基础,更多信息可以查询官网,或者反馈给我。接下来和大家分享一些TensorRT比较高级的特征,这块主要针对有一定经验或者做过一些线上部署的人。
1. 插件支持
首先TensorRT是支持插件(Plugin)的,或者前面提到的Customer layer的形式,也就是说我们在某些层TensorRT不支持的情况下,最主要是做一些检测的操作的时候,很多层是该网络专门定义的,TensorRT没有支持,需要通过Plugin的形式自己去实现。实现过程包括如下两个步骤:
1) 首先需要重载一个IPlugin的基类,生成自己的Plugin的实现,告诉GPU或TensorRT需要做什么操作,要构建的Plugin是什么样子,其实就是类似于开发一个应用软件的插件,需要在上面实现什么功能。
2) 其次要将插件添加到合适的位置,在这里是要添加到网络里去。
注意,只有TensorRT 2.1和更高的版本支持插件的功能(该视频讲的时候的版本是3.0.2,支持插件功能)。
2. 低精度支持
低精度指的是之前所说过的FP16和INT8,其中FP16主要是Pascal P100和V100(tensor core)这两张卡支持;而INT8主要针对的是 P4和P40这两张卡,P4是专门针对线上做推断(Inference)的小卡,和IPhone手机差不多大,75瓦的一张卡,功耗和性能非常好。
3. Python接口和更多的框架支持
TensorRT目前支持Python和C++的API,刚才也介绍了如何添加,Model importer(即Parser)主要支持Caffe和Uff,其他的框架可以通过API来添加,如果在Python中调用pyTouch的API,再通过TensorRT的API写入TensorRT中,这就完成了一个网络的定义。
TensorRT去做推断(Inference)的时候是不再需要框架的,用Caffe做推断(Inference)需要Caffe这个框架,TensorRT把模型导进去后是不需要这个框架的,Caffe和TensorFlow可以通过Parser来导入,一开始就不需要安装这个框架,给一个Caffe或TensorFlow模型,完全可以在TensorRT高效的跑起来。
三、用户自定义层
使用插件创建用户自定义层主要分为两个步骤:
第一步是创建使用IPlugin接口创建用户自定义层,IPlugin是TensorRT中预定义的C++抽象类,用户需要定义具体实现了什么。
第二步是将创建的用户自定义层添加到网络中,如果是Caffe的模型,不支持这一层,将名字改成IPlugin是可以识别的,当然还需要一些额外的操作,说明这一层的操作是对应哪个Plugin的实现;而对于Uff是不支持Plugin的Parser,也就是说TensorFlow的模型中有一个Plugin的话,是不能从模型中识别出来的,这时候需要用到addPlugin()的方法去定义网络中Plugin的相关信息。
IPlugin接口中需要被重载的函数有以下几类:
1) 确定输出:一个是通过int getNbOutput()得到output输出的数目,即用户所定义的一层有几个输出。另一个是通过Dims getOutputDimensions (int index, const Dims* inputs, int nbInputDims) 得到整个输出的维度信息,大家可能不一定遇到有多个输出,一般来讲只有一个输出,但是大家在做检测网络的时候可能会遇到多个输出,一个输出是实际的检测目标是什么,另一个输出是目标的数目,可能的过个输出需要设定Dimension的大小。
2) 层配置:通过void configure() 实现构建推断(Inference) engine时模型中相应的参数大小等配置,configure()只是在构建的时候调用,这个阶段确定的东西是在运行时作为插件参数来存储、序列化/反序列化的。
3) 资源管理:通过void Initialize()来进行资源的初始化,void terminate()来销毁资源,甚至中间可能会有一些临时变量,也可以使用这两个函数进行初始化或销毁。需要注意的是,void Initialize()和void terminate()是在整个运行时都被调用的,并不是做完一次推断(Inference)就去调用terminate。相当于在线的一个服务,服务起的时候会调用void Initialize(),而服务止的时候调用void terminate(),但是服务会进进出出很多sample去做推断(Inference)。
4) 执行(Execution):void enqueue()来定义用户层的操作
5) 序列化和反序列化:这个过程是将层的参数写入到二进制文件中,需要定义一些序列化的方法。通过size_t getSerializationSize()获得序列大小,通过void serialize()将层的参数序列化到缓存中,通过PluginSample()从缓存中将层参数反序列化。需要注意的是,TensorRT没有单独的反序列化的API,因为不需要,在实习构造函数的时候就完成了反序列化的过程
6) 从Caffe Parser添加Plugin:首先通过Parsernvinfer1::IPlugin* createPlugin()实现nvcaffeparser1::IPlugin 接口,然后传递工厂实例到ICaffeParser::parse(),Caffe的Parser才能识别
7) 运行时创建插件:通过IPlugin* createPlugin()实现nvinfer1::IPlugin接口,传递工厂实例到IInferRuntime::deserializeCudaEngine()
四、用户自定义层-YOLOv2实例
我们用一个例子YOLOv2来给大家讲一下完整的流程:
准备:首先要准备 Darknet framework(https://github.com/pjreddie/darknet.git),它是一个非常小众的cfg的形式,然后需要准备需要训练的数据集(VOC 2007 & VOC 2012),测试的指令如下:
./darknet detector test cfg/voc.data cfg/yolo-voc-relu.cfg \
backup/yolo-voc-relu_final.weights \ data/dog.jpg
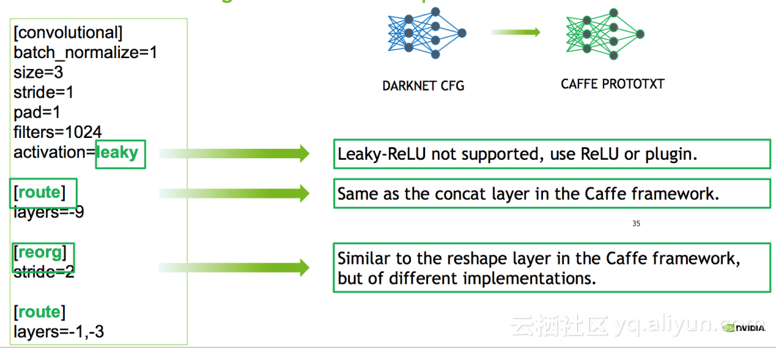
模型转换:如下图所示,根据darknet的配置文件生成caffe的prototxt文件,注意使用ReLu而不是leaky-ReLu;另外darknet中存储顺序不同,首先存储偏移;darknet的配置文件中padding的意义不同,pad = 1表示有padding,darknet中padding的大小是Kernel的大小除以2。
以下是darknet cuDNN和TensorRT FP32的性能对比,FP32是4.8ms,而Darknet是11.3ms。

五、低精度的推断(Inference)
TensorRT通过使用Pascal GPU低精度的技术,实现高性能。以下是FP16和INT8两种类型的性能对比。

1. FP16 推断(Inference)
TensorRT支持高度自动化的FP16推断(Inference),解析模型要将模型的的数据类型设置为DataType::kHALF,同时通过builder- >setHalf2Mode(true)指令将推断(Inference)设置为FP16的模式。需要注意两点,一点是FP16推断(Inference)不需要额外的输入,只需要输入预先训练好的FP32模型,另一点是目前只有Tesla P100/V100支持原生的FP16。
下图展示了将模型从FP32转换成FP16,并以FP16的形式存储的过程:

2.  INT8 推断(Inference)
对于INT8 推断(Inference),需要生成一个校准表来量化模型。接下来主要关注INT8推断(Inference)的几个方面,即:如何生成校准表,如何使用校准表,和INT8推断(Inference)实例。
1) 如何生成校准表?
校准表的生成需要输入有代表性的数据集, 对于分类任务TensorRT建议输入五百张到一千张有代表性的图片,最好每个类都要包括。生成校准表分为两步:第一步是将输入的数据集转换成batch文件;第二步是将转换好的batch文件喂到TensorRT中来生成基于数据集的校准表,可以去统计每一层的情况。
2) 如何使用校准表?
校准这个过程如果要跑一千次是很昂贵的,所以TensorRT支持将其存入文档,后期使用可以从文档加载,其中存储和加载的功能通过两个方法来支持,即writeCalibrationCache和readCalibrationCache。最简单的实现是从write()和read()返回值,这样就必须每次执行都做一次校准。如果想要存储校准时间,需要实现用户自定义的write/read方法,具体的实现可以参考TensorRT中的simpleINT8实例。
3) INT8推断(Inference)实例
通过下图的实例可以发现,在YOLOv2实例中,使用TensorRT INT8做推断(Inference)的性能可以达到2.34ms。

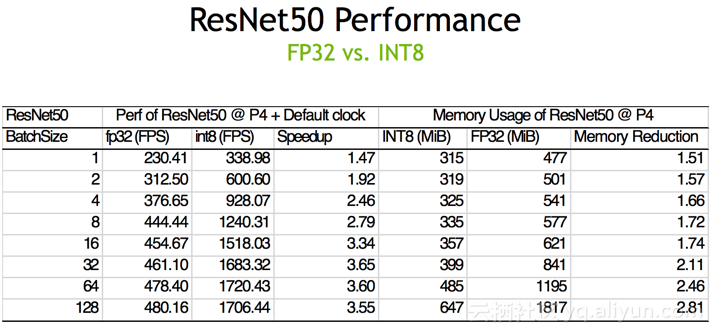
下图展示了用ResNet50中FP32和INT8的性能对比,可以发现,对于P4卡,在bachsize是64的时候,INT8推断(Inference)大概可以达到1720fps,相对于FP32有3.6倍的加速,这个是相当可观的。
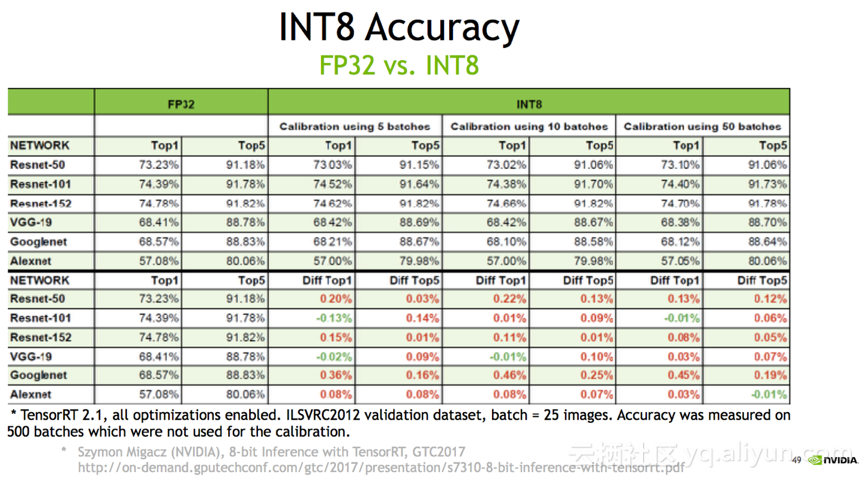
至于大家关心的精度问题对比(如下图),INT8通过用5张图,10张图,50张图去修正,精度相差基本上都是在百分之零点零几,这个效果是非常好的。
最后总结一下TensorRT的优点:
1. TensorRT是一个高性能的深度学习推断(Inference)的优化器和运行的引擎;
2. TensorRT支持Plugin,对于不支持的层,用户可以通过Plugin来支持自定义创建;
3. TensorRT使用低精度的技术获得相对于FP32二到三倍的加速,用户只需要通过相应的代码来实现。
视频链接:https://yq.aliyun.com/video/play/1381
本文由云栖志愿小组李杉杉整理,编辑百见
