

本文使用正则表达式抓取豆瓣top250电影信息,存储到csv文件中
抓取信息
本文假设读者对正则表达式已经非常熟悉了,如果不熟悉的可以到网上找相关教程。
下面我们抓取豆瓣信息打印出来
import requests
import re
import csv
def parse(text):
pattern = re.compile('<li>.*?"title">(.*?)<'+
'.*?"title">(.*?)<.*?"other">(.*?)<'+
'.*?"playable">\[(.*?)\]'+ # 注意方括号要转义
'.*?"bd".*?p class="">(.*?)<'+ # 注意class后面有=""
'.*?"star".*?rating(.*?)-t'+
'.*?"v:average">(.*?)<'+
'.*?<span>(\d+)人'+
'.*?inq">(.*?)<.*?</li>', re.S)
for item in re.findall(pattern, text):
yield {
'title': item[0],
'other_title': (item[1].replace(' ', '') + item[2].replace(' ', '')).replace(' ', ''),
'playable': item[3],
'info': item[4].replace(' ', '').strip(),
'star': '.'.join(list(item[5])),
'score': item[6],
'comment_num': item[7],
'quote': item[8]
}
def get_all():
for i in range(10):
url = 'https://movie.douban.com/top250?start={}&filter='.format(i*25)
text = requests.get(url).text
yield from parse(text)
def main():
data = list(get_all())
print(data)
if __name__ == '__main__':
main()
使用正则匹配的基本形式是这样的<>(.*?)</>。上面只涉及提取,如果提取有困难可以考虑使用re.sub删除掉一些干扰字符,再进行提取。
存储CSV
直接上代码
import requests
import re
import csv
def parse(text):
pattern = re.compile('<li>.*?"title">(.*?)<'+
'.*?"title">(.*?)<.*?"other">(.*?)<'+
'.*?"playable">\[(.*?)\]'+ # 注意方括号要转义
'.*?"bd".*?p class="">(.*?)<'+ # 注意class后面有=""
'.*?"star".*?rating(.*?)-t'+
'.*?"v:average">(.*?)<'+
'.*?<span>(\d+)人'+
'.*?inq">(.*?)<.*?</li>', re.S)
for item in re.findall(pattern, text):
yield {
'title': item[0],
'other_title': (item[1].replace(' ', '') + item[2].replace(' ', '')).replace(' ', ''),
'playable': item[3],
'info': item[4].replace(' ', '').strip(),
'star': '.'.join(list(item[5])),
'score': item[6],
'comment_num': item[7],
'quote': item[8]
}
def get_all():
for i in range(10):
url = 'https://movie.douban.com/top250?start={}&filter='.format(i*25)
text = requests.get(url).text
yield from parse(text)
def main():
data = list(get_all())
with open('movies.csv', 'w', encoding = 'utf-8') as f:
w = csv.DictWriter(f, fieldnames = data[0].keys())
w.writeheader()
w.writerows(data)
if __name__ == '__main__':
main()
这里使用DictWriter来用字典存入,一般都是用Write将列表存入。这里用writerows一次存入多个字典,也可以用循环配合writerow一条一条写入。
抓取结果如下所示
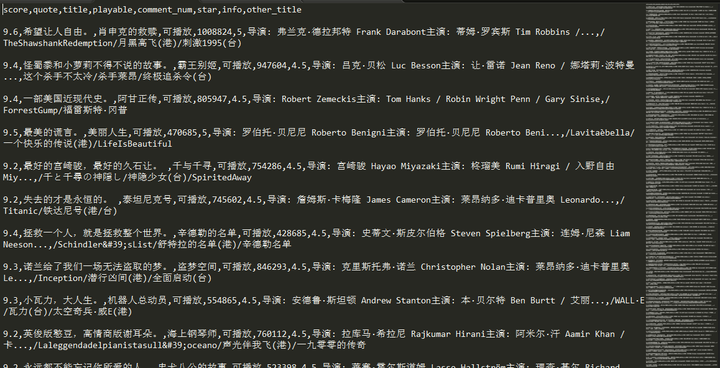
读取CSV文件方法如下
import csv
data_list = []
with open('movies.csv', 'r', encoding = 'utf-8') as f:
data = csv.DictReader(f)
for datai in data:
data_list.append(datai)
print(data_list)
对爬虫基础部分有问题的读者可以参考下面文章
专栏信息
专栏主页:python编程
专栏目录:目录
爬虫目录:爬虫系列目录
版本说明:软件及包版本说明
