

本文用beautifulsoup4库抓取stackoverflow上python最新问题,存储到json文件。前半部分通过抓取多个字段练习beautifulsoup的使用,后半部分介绍json模块
关于beautifulsoup的使用可以参考这篇文章BeautifulSoup全面总结
爬虫代码
import requests # 导入网页请求库
from bs4 import BeautifulSoup # 导入网页解析库
import re
import json
class Stack(object):
def __init__(self):
self.baseurl = 'https://stackoverflow.com' # 用于与抓取的url拼接
self.starturl = 'https://stackoverflow.com/questions/tagged/python' # 初始url
def start_requests(self, url): # 发起请求
r = requests.get(url)
return r.content
def parse(self, text): # 解析网页
soup = BeautifulSoup(text, 'html.parser')
divs = soup.find_all('div', class_ = 'question-summary')
for div in divs:
# 一些中间变量
gold = div.find('span', title = re.compile('gold'))
silver = div.find('span', title = re.compile('silver'))
bronze = div.find('span', title = re.compile('bronze'))
tags = div.find('div', class_ = 'summary').find_all('div')[1].find_all('a')
# 用生成器输出字典
yield {
# 这部分每一条都有代表性
'title': div.h3.a.text,
'url': self.baseurl + div.h3.a.get('href'),
'answer': div.find('div', class_ = re.compile('status')).strong.text,
'view': div.find('div', class_ = 'views ').text[: -7].strip(),
'gold': gold.find('span', class_ = 'badgecount').text if gold else 0,
'tagnames': [tag.text for tag in tags],
# 下面的从知识的角度上讲都和上面一样
'vote': div.find('span', class_ = 'vote-count-post ').strong.text,
'time': div.find('div', class_ = 'user-action-time').span.get('title'),
'duration': div.find('div', class_ = 'user-action-time').span.text,
'username': div.find('div', class_ = 'user-details').a.text,
'userurl': self.baseurl + div.find('div', class_ = 'user-gravatar32').a.get('href'),
'reputation': div.find('span', class_ = 'reputation-score').text,
'silver': silver.find('span', class_ = 'badgecount').text if silver else 0,
'bronze': bronze.find('span', class_ = 'badgecount').text if bronze else 0,
'tagurls': [self.baseurl + tag.get('href') for tag in tags]
}
# 启动爬虫
def start(self):
text = self.start_requests(self.starturl)
items = self.parse(text)
s = json.dumps(list(items), indent = 4, ensure_ascii=False)
with open('stackoverflow.json', 'w', encoding = 'utf-8') as f:
f.write(s)
stack = Stack()
stack.start()
抓取结果如下图所示
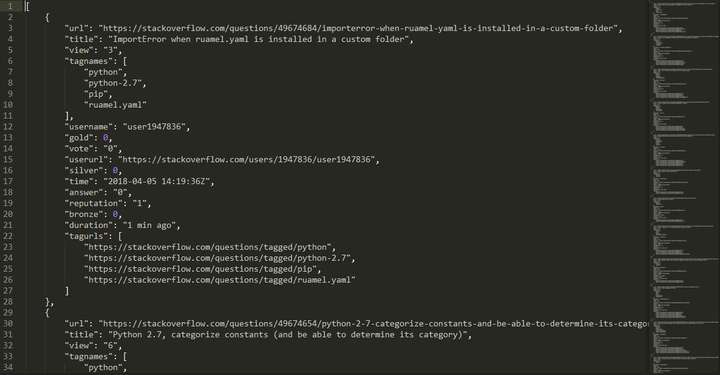
上面代码的基础已经在前面文章中讲过,有问题可以参考下面文章
json模块介绍
json是一个内置模块,无需自己安装,模块主要就用两个函数json.dumps和json.loads
- 前者可以把一个list dict的python对象变成样子相同的字符串,这样转化一般用于存储到json文件中,因为json文件的形式和list dict是一样的,而存储文件需要使用字符串(或者bytes)
- 后者将list dict样子的字符串转化为python对象,如果读取json文件,得到的就是这样的字符串,通过这个转化将其变成python可以处理的list dict
示例代码展示如下
import json
a = [{'name':'Bob', 'age': 20}, {'name': 'Mary', 'age': 18}]
s = json.dumps(a)
s # 一个字符串
# '[{"age": 20, "name": "Bob"}, {"age": 18, "name": "Mary"}]'
b = json.loads(s)
b[0]
# {'age': 20, 'name': 'Bob'}
b[0].get('age')
# 20
存储到文件时,为了让字符串展示更好看一些,还有编码问题,一般加参数如下
存储到文件
s = json.dumps(a, indent = 4, ensure_ascii=False)
with open('a.json', 'w', encoding = 'utf-8') as f:
f.write(s)
参数indent指定一些缩进,不然写到文件里所有字符都堆在一起不方便看。
ensure_ascii则是存储内容涉及中文时需要指定(上面抓取stackoverflow没有中文,所以其实是不需要指定的,只是为了引出这个参数才这么用)
从文件中读取
with open('a.json', encoding = 'utf-8') as f:
s = f.read()
b = json.loads(s)
专栏信息
专栏主页:python编程
专栏目录:目录
爬虫目录:爬虫系列目录
版本说明:软件及包版本说明
