

是不是被图片骗进来了?哈哈不要着急走,其实也不是跟图没关系,我们这次就是说断点续传的那些事。
我们写代码的有时候工作中会做一些上传/下载图片或者文件的操作。万一线路中断,不具备断点续传的 HTTP/FTP 服务器或下载软件就只能从头重传,比较好的 HTTP/FTP 服务器或下载软件具有断点续传能力,允许用户从上传/下载断线的地方继续传送,这样大大减少了用户的烦恼。
获取部分内容的范围请求
其实啊,为了实现中断恢复下载的需求,需要能下载指定下载的实体范围:
- 请求头中的Range来指定 资源的byte范围
- 响应会返回状态码206响应报文
- 对于多重范围的范围请求,响应会在首部字段Content-Type中标明multipart/byteranges 我们来模拟一下: 先打开我们的命令行工具,写上如下代码 (后面是我在百度上找的一个图片)
curl -v --header "Range:bytes=0-10" http://pic26.nipic.com/20130117/10558908_124756651000_2.jpg
运行一下得到的这个结果:
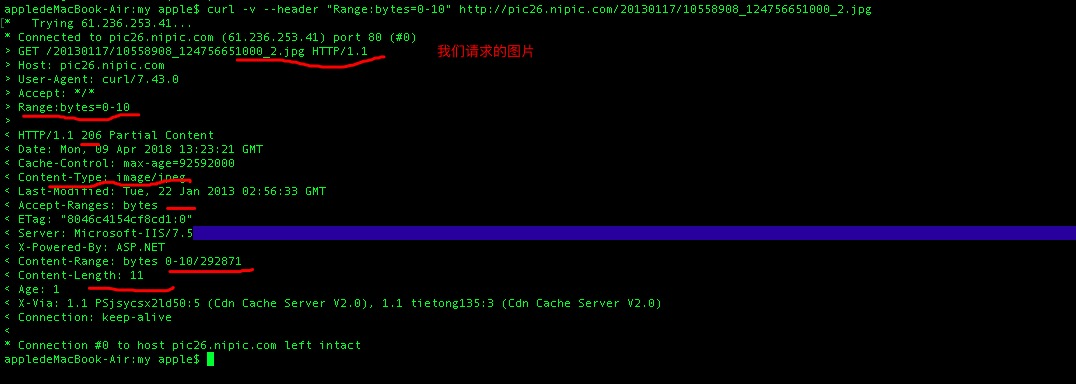
从http那段服务器返回给我们的信息可以看出如下信息(206代表服务器答应我们的range请求方式)
- Content-Type: image/jpeg 类型是图片
- Accept-Ranges: bytes 单位是bytes
- Content-Range: bytes 0-10/292871 请求段为0-10,总共有292871bytes
- Content-Length: 11 请求长度为11 知道这些之后我们可以简单模拟一下客户端和服务器端怎么做的:
服务器端代码
首先客户端要发一个头Range:bytes=0-10,然后服务端返回一个头 // Accept-Ranges:bytes // Content-Range:0-10/总大小
// 获取范围请求
let http = require('http');
let fs = require('fs');
let path = require('path');
let { promisify } = require('util');//这个模块是包装某个东西成为promise的。
let stat = promisify(fs.stat);
let server = http.createServer(async function (req, res) {
let p = path.join(__dirname, 'con.txt');
// 判断当前文件的大小
let statObj = await stat(p);
let start = 0;
let end = statObj.size - 1; // 读流是包前又包后的:statObj.size 是文件的大小。
let total = end
let range = req.headers['range'];
if (range) {//判断客户端是否有带range的请求
// 告诉它支持范围请求
res.setHeader('Accept-Ranges','bytes');
// ['匹配的字符串','第一个分组']
let result = range.match(/bytes=(\d*)-(\d*)/);
start = result[1]?parseInt(result[1]):start;
end = result[2]?parseInt(result[2])-1:end;
// 获取成功并且文件总大小是多少
// Content-Range:0-10/总大小
res.setHeader('Content-Range',`${start}-${end}/${total}`)
}
res.setHeader('Content-Type', 'text/plain;charset=utf8');
fs.createReadStream(p, { start, end }).pipe(res);
});
server.listen(3000);
这样一个简单的服务器端就写好了。
客户端代码
//首先要写一个options
let options = {
hostname:'localhost',
port:3000,
path:'/',
method:'GET'
}
let fs = require('fs');
let path = require('path');
let http = require('http');
let ws = fs.createWriteStream('./download.txt');
let pause = false;
let start = 0;
// 下载,每次获取10个
process.stdin.on('data',function(chunk){
chunk = chunk.toString();
if(chunk.includes('p')){ //输入p就是暂停
pause = true
}else{
pause = false;
download();
}
});
function download(){
options.headers = {
Range:`bytes=${start}-${start+10}`
}
start+=10;
// 发请求
http.get(options,function(res){
let range = res.headers['content-range'];
let total = range.split('/')[1];
let buffers = [];//创建一个缓存区,把读到的数据都放在里面
//,等到end的时候就整个取出来。
res.on('data',function(chunk){
buffers.push(chunk);
});
res.on('end',function(){
//将获取的数据写入到文件中
ws.write(Buffer.concat(buffers));
setTimeout(function(){
if(pause === false&&start<total){
download();
}
},1000)
})
})
}
download();
代码非常浅显易懂。 最后我们在同级目录下创建一个con.txt文件。用node执行一下客户端文件,就会实现功能啦。
场景校验
有时候即使终端发起续传请求是url对应问问价在服务器端已经发生变化,那么很显然此时需要一个标识问价唯一的方式,
- Etag(请求头) ===> if-none-match
- Last-Modified(请求头) ===> if-modified-since
Etag
Etag(Entity Tags)主要为了解决 Last-Modified 无法解决的一些问题。
- 一些文件也许会周期性的更改,但是内容并不改变(仅改变修改时间),这时候我们并不希望客户端认为这个文件被修改了,而重新 GET。
- 某些文件修改非常频繁,例如:在秒以下的时间内进行修改(1s 内修改了 N 次),If-Modified-Since 能检查到的粒度是 s 级的,这种修改无法判断(或者说 UNIX 记录 MTIME 只能精确到秒)。
- 某些服务器不能精确的得到文件的最后修改时间。
为此,HTTP/1.1 引入了 Etag。Etag 仅仅是一个和文件相关的标记,可以是一个版本标记,例如:v1.0.0;或者说 “627-4d648041f6b80” 这么一串看起来很神秘的编码。但是 HTTP/1.1 标准并没有规定 Etag 的内容是什么或者说要怎么实现,唯一规定的是 Etag 需要放在 “” 内,一般情况下Etag的值是时间+文件大小。
Last-Modified
If-Modified-Since,和 Last-Modified 一样都是用于记录页面最后修改时间的 HTTP 头信息,只是 Last-Modified 是由服务器往客户端发送的 HTTP 头,而 If-Modified-Since 则是由客户端往服务器发送的头,可以看到,再次请求本地存在的 cache 页面时,客户端会通过 If-Modified-Since 头将先前服务器端发过来的 Last-Modified 最后修改时间戳发送回去,这是为了让服务器端进行验证,通过这个时间戳判断客户端的页面是否是最新的,如果不是最新的,则返回新的内容,如果是最新的,则返回 304 告诉客户端其本地 cache 的页面是最新的,于是客户端就可以直接从本地加载页面了,这样在网络上传输的数据就会大大减少,同时也减轻了服务器的负担。 如果想了解具体怎么实现可以看看静态服务里面的缓存。
是不是跃跃欲试??
如果对你有帮助请点个赞噻!
