

本节我们来用TensorFlow来实现深度学习模型,用来实现验证码识别的过程,这里我们识别的验证码是图形验证码,首先我们会用标注好的数据来训练一个模型,然后再用模型来实现这个验证码的识别。
验证码
首先我们来看下验证码是怎样的,这里我们使用Python的captcha库来生成即可,这个库默认是没有安装的,所以这里我们需要先安装这个库,另外我们还需要安装pillow库,使用pip3即可:
1 | pip3 install captcha pillow |
安装好之后,我们就可以用如下代码来生成一个简单的图形验证码了:
12345678from captcha.image import ImageCaptchafrom PIL import Image text = '1234'image = ImageCaptcha()captcha = image.generate(text)captcha_image = Image.open(captcha)captcha_image.show()运行之后便会弹出一张图片,结果如下:
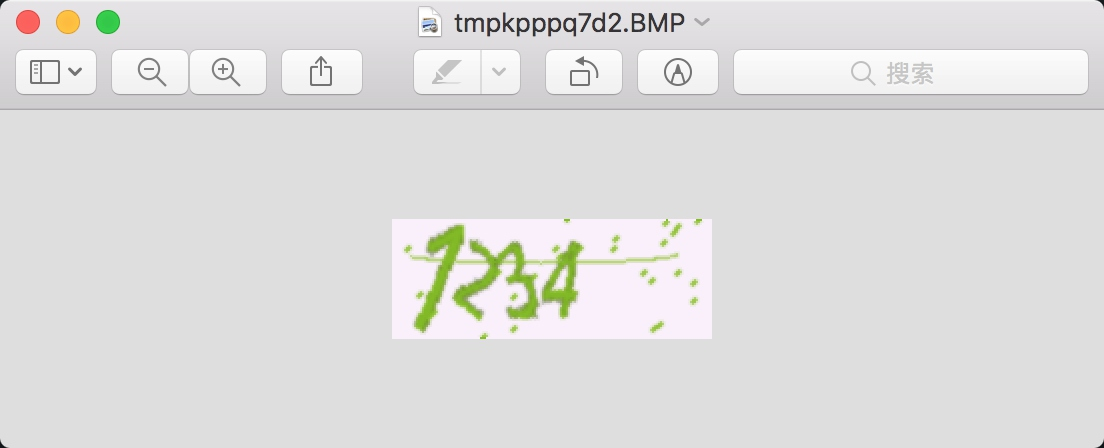
可以看到图中的文字正是我们所定义的text内容,这样我们就可以得到一张图片和其对应的真实文本,这样我们就可以用它来生成一批训练数据和测试数据了。
预处理
在训练之前肯定是要进行数据预处理了,现在我们首先定义好了要生成的验证码文本内容,这就相当于已经有了label了,然后我们再用它来生成验证码,就可以得到输入数据x了,在这里我们首先定义好我们的输入词表,由于大小写字母加数字的词表比较庞大,设想我们用含有大小写字母和数字的验证码,一个验证码四个字符,那么一共可以的组合是(26 + 26 + 10)^ 4 = 14776336种组合,这个数量训练起来有点大,所以这里我们精简一下,只使用纯数字的验证码来训练,这样其组合个数就变为10 ^ 4 = 10000种,显然少了很多。
所以在这里我们先定义一个词表和其长度变量:
123VOCAB = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']CAPTCHA_LENGTH = 4VOCAB_LENGTH = len(VOCAB)这里VOCAB就是词表的内容,即0到9这10个数字,验证码的字符个数即CAPTCHA_LENGTH是4,词表长度是VOCAB的长度,即10。
接下来我们定义一个生成验证码数据的方法,流程类似上文,只不过这里我们将返回的数据转为了Numpy形式的数组:
123456789101112131415from PIL import Imagefrom captcha.image import ImageCaptchaimport numpy as np def generate_captcha(captcha_text): """ get captcha text and np array :param captcha_text: source text :return: captcha image and array """ image = ImageCaptcha() captcha = image.generate(captcha_text) captcha_image = Image.open(captcha) captcha_array = np.array(captcha_image) return captcha_array这样调用此方法,我们就可以得到一个Numpy数组了,这个其实是把验证码转化成了每个像素的RGB,我们调用一下这个方法试试:
12captcha = generate_captcha('1234')print(captcha, captcha.shape)内容如下:
123456789[[[239 244 244] [239 244 244] [239 244 244] ..., ..., [239 244 244] [239 244 244] [239 244 244]]] (60, 160, 3)可以看到它的形状是(60,160,3),这其实代表验证码图片的高度是60,宽度是160,是60×160像素的验证码,每个像素都有RGB值,所以最后一维即为像素的RGB值。
接下来我们需要定义label,由于我们需要使用深度学习模型进行训练,所以这里我们的标签数据最好使用One-Hot编码,即如果验证码文本是1234,那么应该词表索引位置置1,总共的长度是40,我们用程序实现一下One-Hot编码和文本的互相转换:
12345678910111213141516171819202122232425262728def text2vec(text): """ text to one-hot vector :param text: source text :return: np array """ if len(text) > CAPTCHA_LENGTH: return False vector = np.zeros(CAPTCHA_LENGTH * VOCAB_LENGTH) for i, c in enumerate(text): index = i * VOCAB_LENGTH + VOCAB.index(c) vector[index] = 1 return vector def vec2text(vector): """ vector to captcha text :param vector: np array :return: text """ if not isinstance(vector, np.ndarray): vector = np.asarray(vector) vector = np.reshape(vector, [CAPTCHA_LENGTH, -1]) text = '' for item in vector: text += VOCAB[np.argmax(item)] return text这里text2vec()方法就是将真实文本转化为One-Hot编码,vec2text()方法就是将One-Hot编码转回真实文本。
例如这里调用一下这两个方法,我们将1234文本转换为One-Hot编码,然后在将其转回来:
123vector = text2vec('1234')text = vec2text(vector)print(vector, text)运行结果如下:
1234[ 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0.]1234这样我们就可以实现文本到One-Hot编码的互转了。
接下来我们就可以构造一批数据了,x数据就是验证码的numpy数组,y数据就是验证码的文本的一个热门编码,生成内容如下:
1234567891011121314151617181920212223242526272829303132333435363738import randomfrom os.path import join, existsimport pickleimport numpy as npfrom os import makedirs DATA_LENGTH = 10000DATA_PATH = 'data' def get_random_text(): text = '' for i in range(CAPTCHA_LENGTH): text += random.choice(VOCAB) return text def generate_data(): print('Generating Data...') data_x, data_y = [], [] # generate data x and y for i in range(DATA_LENGTH): text = get_random_text() # get captcha array captcha_array = generate_captcha(text) # get vector vector = text2vec(text) data_x.append(captcha_array) data_y.append(vector) # write data to pickle if not exists(DATA_PATH): makedirs(DATA_PATH) x = np.asarray(data_x, np.float32) y = np.asarray(data_y, np.float32) with open(join(DATA_PATH, 'data.pkl'), 'wb') as f: pickle.dump(x, f) pickle.dump(y, f)这里我们定义了一个get_random_text()方法,可以随机生成验证码文本,然后接下来再利用这个随机生成的文本来产生对应的x,y数据,然后我们再将数据写入到pickle文件里,这样就完成了预处理的操作。
构建模型
有了数据之后,我们就开始构建模型吧,这里我们还是利用train_test_split()方法将数据分为三部分,训练集,开发集,验证集:
1234567with open('data.pkl', 'rb') as f: data_x = pickle.load(f) data_y = pickle.load(f) return standardize(data_x), data_y train_x, test_x, train_y, test_y = train_test_split(data_x, data_y, test_size=0.4, random_state=40)dev_x, test_x, dev_y, test_y, = train_test_split(test_x, test_y, test_size=0.5, random_state=40)接下来我们使用者三个数据集构造三个数据集对象:
123456789# train and dev datasettrain_dataset = tf.data.Dataset.from_tensor_slices((train_x, train_y)).shuffle(10000)train_dataset = train_dataset.batch(FLAGS.train_batch_size) dev_dataset = tf.data.Dataset.from_tensor_slices((dev_x, dev_y))dev_dataset = dev_dataset.batch(FLAGS.dev_batch_size) test_dataset = tf.data.Dataset.from_tensor_slices((test_x, test_y))test_dataset = test_dataset.batch(FLAGS.test_batch_size)然后初始化一个迭代器,并绑定到这个数据集上:
12345# a reinitializable iteratoriterator = tf.data.Iterator.from_structure(train_dataset.output_types, train_dataset.output_shapes)train_initializer = iterator.make_initializer(train_dataset)dev_initializer = iterator.make_initializer(dev_dataset)test_initializer = iterator.make_initializer(test_dataset)接下来就是关键的部分了,在这里我们使用三层卷积和两层全连接网络进行构造,在这里为了简化写法,直接使用TensorFlow的图层模块:
1234567891011121314151617# input Layerwith tf.variable_scope('inputs'): # x.shape = [-1, 60, 160, 3] x, y_label = iterator.get_next()keep_prob = tf.placeholder(tf.float32, [])y = tf.cast(x, tf.float32)# 3 CNN layersfor _ in range(3): y = tf.layers.conv2d(y, filters=32, kernel_size=3, padding='same', activation=tf.nn.relu) y = tf.layers.max_pooling2d(y, pool_size=2, strides=2, padding='same') # y = tf.layers.dropout(y, rate=keep_prob) # 2 dense layersy = tf.layers.flatten(y)y = tf.layers.dense(y, 1024, activation=tf.nn.relu)y = tf.layers.dropout(y, rate=keep_prob)y = tf.layers.dense(y, VOCAB_LENGTH)这里卷积核大小为3,padding使用SAME模式,激活函数使用relu。
经过全连接网络变换之后,y的形状就变成了[batch_size,n_classes],我们的标签是CAPTCHA_LENGTH个One-Hot向量拼合而成的,在这里我们想使用交叉熵来计算,但是交叉熵计算的时候,标签参数向量最后一维各个元素之和必须为1,不然计算梯度的时候会出现问题。详情参见TensorFlow的官方文档:
https://www.tensorflow.org/api_docs/python/tf/nn/
注:虽然这些类是互斥的,但它们的概率不一定是。所有需要的是每行标签是有效的概率分布。如果它们不是,则梯度的计算将不正确。
但是现在的标签参数是CAPTCHA_LENGTH个One-Hot向量拼合而成,所以这里各个元素之和为CAPTCHA_LENGTH,所以我们需要重新reshape一下,确保最后一维各个元素之间为1:
1 2 | y_reshape = tf.reshape(y, [-1, VOCAB_LENGTH]) y_label_reshape = tf.reshape(y_label, [-1, VOCAB_LENGTH]) |
这样我们就可以确保最后一维是VOCAB_LENGTH长度,而它就是一个One-Hot向量,所以各元素之和必定为1。
然后损失和准确就好计算了:
1234567# losscross_entropy = tf.reduce_sum(tf.nn.softmax_cross_entropy_with_logits(logits=y_reshape, labels=y_label_reshape))# accuracymax_index_predict = tf.argmax(y_reshape, axis=-1)max_index_label = tf.argmax(y_label_reshape, axis=-1)correct_predict = tf.equal(max_index_predict, max_index_label)accuracy = tf.reduce_mean(tf.cast(correct_predict, tf.float32))再接下来执行训练即可:
12345678910111213141516171819# traintrain_op = tf.train.RMSPropOptimizer(FLAGS.learning_rate).minimize(cross_entropy, global_step=global_step)for epoch in range(FLAGS.epoch_num): tf.train.global_step(sess, global_step_tensor=global_step) # train sess.run(train_initializer) for step in range(int(train_steps)): loss, acc, gstep, _ = sess.run([cross_entropy, accuracy, global_step, train_op], feed_dict={keep_prob: FLAGS.keep_prob}) # print log if step % FLAGS.steps_per_print == 0: print('Global Step', gstep, 'Step', step, 'Train Loss', loss, 'Accuracy', acc) if epoch % FLAGS.epochs_per_dev == 0: # dev sess.run(dev_initializer) for step in range(int(dev_steps)): if step % FLAGS.steps_per_print == 0: print('Dev Accuracy', sess.run(accuracy, feed_dict={keep_prob: 1}), 'Step', step)在这里我们首先初始化train_initializer,将iterator绑定到train数据集上,然后执行train_op,获得损失,acc,gstep等结果并输出。
训练
运行训练过程,结果类似如下:
12345678910...Dev Accuracy 0.9580078 Step 0Dev Accuracy 0.9472656 Step 2Dev Accuracy 0.9501953 Step 4Dev Accuracy 0.9658203 Step 6Global Step 3243 Step 0 Train Loss 1.1920928e-06 Accuracy 1.0Global Step 3245 Step 2 Train Loss 1.5497207e-06 Accuracy 1.0Global Step 3247 Step 4 Train Loss 1.1920928e-06 Accuracy 1.0Global Step 3249 Step 6 Train Loss 1.7881392e-06 Accuracy 1.0...验证集准确率95%以上。
测试
训练过程我们还可以每隔几个Epoch保存一下模型:
123# save modelif epoch % FLAGS.epochs_per_save == 0: saver.save(sess, FLAGS.checkpoint_dir, global_step=gstep)当然也可以取验证集上准确率最高的模型进行保存。
验证时我们可以重新刷新一下模型,然后进行验证:
1234567891011# load modelckpt = tf.train.get_checkpoint_state('ckpt')if ckpt: saver.restore(sess, ckpt.model_checkpoint_path) print('Restore from', ckpt.model_checkpoint_path) sess.run(test_initializer) for step in range(int(test_steps)): if step % FLAGS.steps_per_print == 0: print('Test Accuracy', sess.run(accuracy, feed_dict={keep_prob: 1}), 'Step', step)else: print('No Model Found')验证之后其准确率基本是差不多的。
如果要进行新的Inference的话,可以替换下test_x即可。
结语
以上便是使用TensorFlow进行验证码识别的过程,代码见:
本资源首发于崔庆才的个人博客静觅: Python3网络爬虫开发实战教程 | 静觅
如想了解更多爬虫资讯,请关注我的个人微信公众号:进击的Coder
weixin.qq.com/r/5zsjOyvEZ… (二维码自动识别)
