

我为啥要知道浏览器渲染过程,嗯...面试会问....但最重要的是了解它工作原理,让你在弄它时,游刃有余。
先看下浏览器有什么。
浏览器的主要组件为:
- 用户界面 - 除了浏览器主窗口显示的您请求的页面外,其他显示的各个部分都属于用户界面。
- 浏览器引擎 - 在用户界面和呈现引擎之间传送指令。
- 呈现引擎 - 负责显示请求的内容。如果请求的内容是 HTML,它就负责解析 HTML 和 CSS 内容,并将解析后的内容显示在屏幕上。
- 网络 - 用于网络调用,比如 HTTP 请求。其接口与平台无关,并为所有平台提供底层实现。
- 用户界面后端 - 用于绘制基本的窗口小部件,比如组合框和窗口。其公开了与平台无关的通用接口,而在底层使用操作系统的用户界面方法。
- JavaScript 解释器-用于解析和执行 JavaScript 代码。
- 数据存储-这是持久层。浏览器需要在硬盘上保存各种数据,例如cookie。浏览器还支持诸如localStorage,IndexedDB,WebSQL和FileSystem之类的存储机制。
浏览器(如Chrome)运行渲染引擎的多个实例时:每个选项卡都在单独的进程中运行。
从网络请求到HTML数据,并显示页面的流程: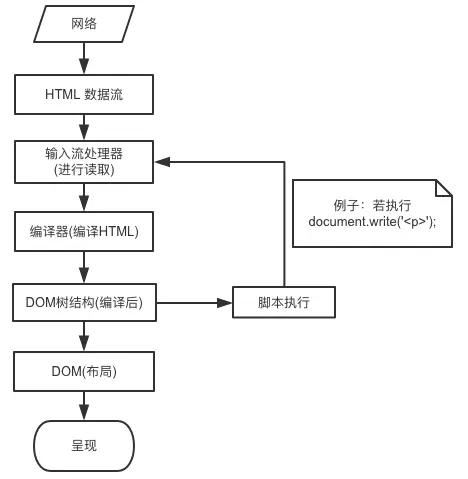
当网页访问并接受到返回数据时,浏览器会尝试解析(为HTML)。
获取返回的数据流后,第一步进行读取解析,后面会进行的编译HTML到DOM布局呈现,这都是呈现引擎需要做的事情。
呈现引擎所做的事: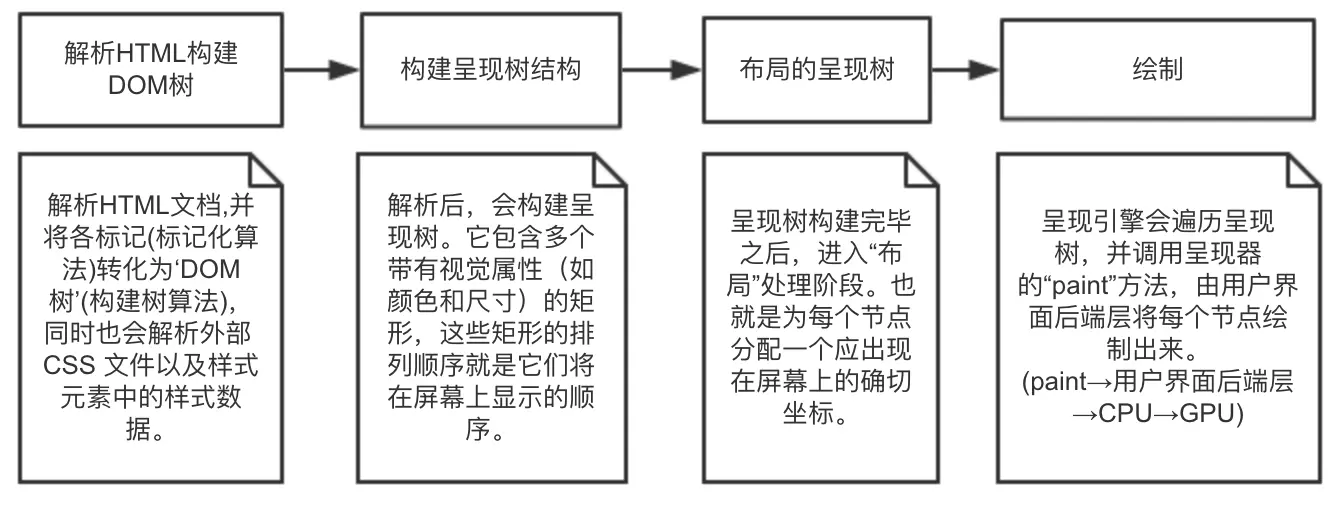
对于呈现引擎来说,这是渐进的过程。
在不断接收和处理来自网络的其余内容的同时,呈现引擎会将部分内容解析并显示出来。
浏览器内核不同,解析的流程有可能会不一样(以WebKit与Mozilla 的 Gecko 为例):
可以看到 Gecko 解析的流程多于WebKit,并在官方的术语上有着些许不同,另外呈现树与DOM树不一定相同,后面会做说明。
HTML解析器的输出“解析树”是由 DOM 元素和属性节点构成的树结构,DOM 是文档对象模型 (Document Object Model) 的缩写。也会有外部内容(例如 JavaScript)与 HTML 元素之间的接口。
一个HTML的例子来说明DOM树:
<html>
<body>
<p>
Hello World
</p>
<div><img src="example.png"/></div>
</body>
</html>生成的DOM树:
HTML 的标记化算法:
在呈现引擎中,为了构建DOM树,HTML解析器需要使用标记化算法,对HTML文档进行解析。
标记化算法是将HTML文档输出为HTML标记,并使用状态来表示。每个状态收来自输入信息流的一个或多个字节,并根据这些字节更新下一个状态。
该算法相当复杂,于是我们基于一个简单的例子来理解其原理:
<html>
<body>
Hello world
</body>
</html> 初始状态是数据状态。在<html>中, 当解析遇到字符 < 时,状态更改为“标记打开状态”,接受一个a-z字符会创建“起始标记”。
这个状态一直会保持到接收 > 字符。在此期间接收的每个字符都会附加到新的标记名称上。
遇到 > 标记之后,会发送当前的标记,状态改为“数据状态”。<body> 标记也会是相同的处理。
目前 html与body 标记均已发出,现在我们回到了数据状态,当接收 Hello world 中的H字符时,将创建并发送字符标记,此后每一个字符都会发送一个字符标记。直到遇到</body>的 < 字符为止。
</body> 中 解析到< 时,状态回到了“标记打开状态”,接收的是/字符时,会创建 end tag token 并改为“标记名称状态”。这个状态将会继续保持,直到遇到 > 字符时结束。
</html> 也会进行同样的处理。
HTML的树构建算法:
在创建解析器的同时,也会创建 Document 对象。在构建树阶段,以 Document 为根节点DOM树会不断的修改,向其中添加各种元素。
利用标记生成器( 标记化算法 )发送的每个节点的DOM 树,会不断进行处理。规范( W3C标准 )中定义了每个标记所对应的DOM元素,这些元素会在接受到相应的标记时创建。
这些元素不仅会添加到DOM 树中,还会添加到开放元素的堆栈中。此堆栈用于纠正嵌套错误和处理未关闭的标记。
其算法也可以用状态机来描述,这些状态为“插入模式”,
例子:
<html>
<body>
Hello world
</body>
</html>此HTML构建树流程:
解析结束后的操作:
此阶段,浏览器会将文档标注为交互状态,并开始解析那些处于延迟模式的脚本(如: <script defer="defer" >),也就是那些应在文档解析完成后才执行的脚本。然后,文档状态将设置为“完成”,一个“加载”事件将随之触发。
浏览器的容错机制:
你在浏览 HTML 网页时从来不会看到“语法无效”的错误。这是因为浏览器会纠正任何无效内容,然后继续工作。
不同浏览器的错误处理机制是相当一致的,但这种机制却不是 HTML 当前规范的一部分。
需要注意,除非想作为反面教材出现容错代码段,否则还请编写格式正确的 HTML 代码。
浏览器渲染过程与原理浅析(二)我们会详细说一下神秘的CSS解析器与解析器的原理,细致的探讨样式与DOM 的关系。
