

这是日常学python的第15篇原创文章
前几篇文章我们学习了requests库和正则,还有个urllib库,我上篇文章也用了requests库来教大家去爬那些返回json格式的网页,挺好玩的。有读者让我来个正则的,所以我今天就来个正则+requests来进行爬取。
今天原来是想爬小说的,但想到我不怎么看小说,读者也是都喜欢学习的,对吧?嘻嘻!所以我来爬个与python相关的内容,恰好前几天我又看到别人推荐的一本python进阶书,这本书的作者是我们的python大神kennethreitz征集各路爱好python的人所写的,下面是地址:
中文版:pythonguidecn.readthedocs.io/zh/latest/
英文版:docs.python-guide.org/en/latest/
这本书适合于一切有python的学习者,不管你是初入python的小白,还是熟练使用python的老手,都适用。但是不看也没有影响你学习爬虫哈,这个只是说些python的奇淫技巧。
由于这本书在网上只有英语的电子版,可我英语渣渣,所以爬个中文版的网页然后把他弄成电子版。
若想直接获取该书电子版,可以在公众号「日常学python」后台回复『进阶』直接获取。
本篇文章用到的工具如下:
requests库
正则表达式
Sigil:将html网页转成epub电子书
epub转pdf:http://cn.epubee.com/epub转pdf.html
好了,下面详细分析:
1分析网站内容
可以看到首页中有整本书的内容链接,所以可以直接爬首页获取整本书的链接。
熟练地按下f12查看网页请求,非常容易找到这个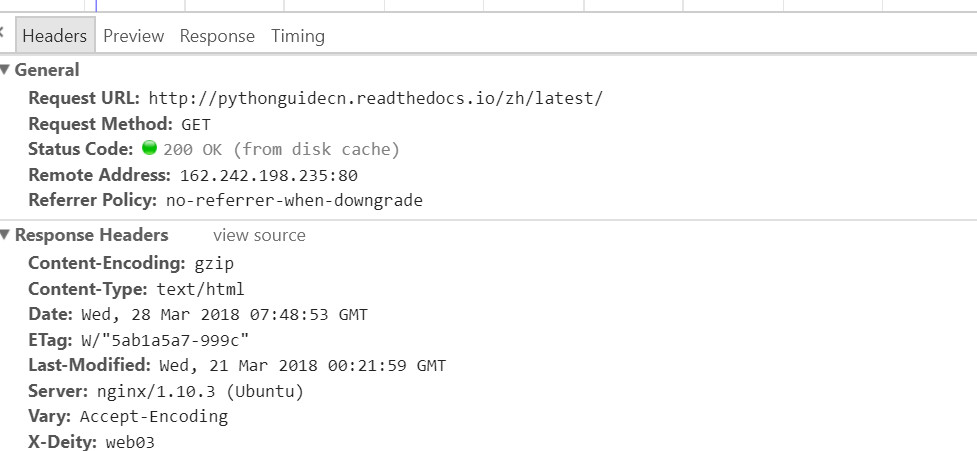
请求网站为:pythonguidecn.readthedocs.io/zh/latest/
请求方式为get,状态码为200,而且返回的是html元素,所以我们可以用正则来匹配所需要的内容。
那看看我们的匹配内容所在的地方
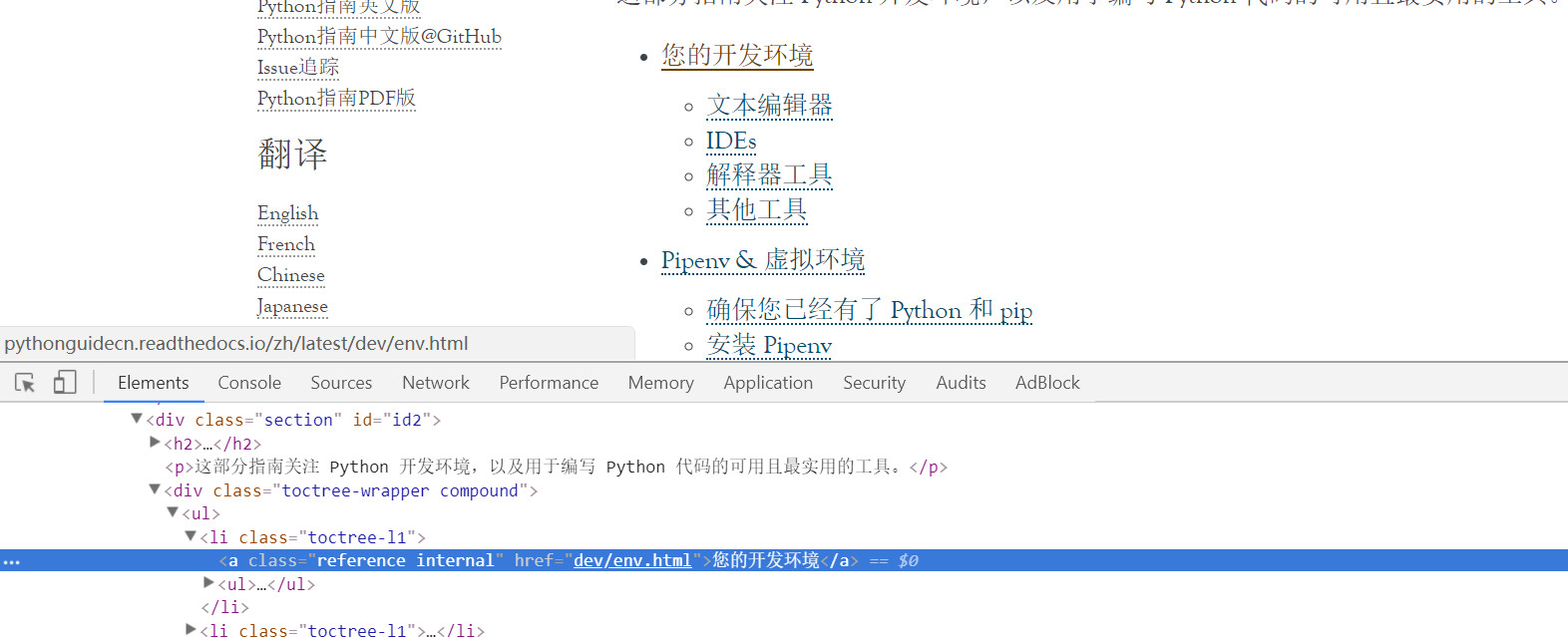
可以看到这个内容的地址和内容标题都在这个a标签上,所以正则很容易,如下:
toctree-l1.*?reference internal" href="([^"]*?)">(.*?)</a>
不知道你的正则学得怎样了,这里还是简单说下:
.:这个是概括字符集,为匹配除换行符以外的任意字符
*:这个是数量词,匹配的次数为0次以上
?:加了这个问号表示非贪婪,一般默认为贪婪
[^"]:这个表示不匹配双引号,挺好用的
实在不记得的可以看看我这篇文章,这里不详细说了,不记得就点开爬虫必学知识之正则表达式下篇看看
这里需要注意的是:在这里获取的网址列表里面有个内容的导航,如下:
所有我们在匹配完之后还需要再将这些带#号的网址给过滤掉。
接下来的就是获取每个网页的内容

可以看到内容都在这个div标签内,所以和上面一样,用正则就可以获取了。
ps: 其实这里用BeautifulSoup更好用,我会在后面文章中讲到哈!
匹配内容的正则为:
section".*?(<h1>.*?)<div class="sphinxsidebar
因为我的那个工具是把这些内容的html下载下来就可以了,所以接下来不需要清洗里面的html元素。
内容分析完毕,接下来的就容易了,就是用个循环把遍历所有文章,然后就利用正则把他爬下来就可以了。
2实操部分import re, requests
class Spider(object):
def __init__(self, headers, url):
self.headers = headers
self.url = url
def __get_hrefs(self):
'''获取书本的所有链接'''
response = requests.get(self.url, self.headers)
if response.status_code == 200:
response.encoding = 'utf-8'
hrefs = re.findall('toctree-l1.*?reference internal" href="([^"]*?)">(.*?)</a>', response.text, re.S)
return hrefs
else:
print('访问书本内容失败,状态码为', response.status_code)
def __get_page(self, url):
'''获取首页'''
response = requests.get(url, self.headers)
response.encoding = 'utf-8'
content = re.findall('section".*?(<h1>.*?)<div class="sphinxsidebar', response.text, re.S)
return content[0]
def __get_content(self, href):
'''获取每个页面的内容'''
if href:
href = self.url + href
response = requests.get(href, self.headers)
response.encoding = 'utf-8'
content = re.findall('section".*?(<h1>.*?)<div class="sphinxsidebar', response.text, re.S)
if content:
return content[0]
else:
print('正则获取失败')
else:
print('获取内容失败')
def run(self):
'''循环获取整本书内容'''
self.num = 0
hrefs = self.__get_hrefs()
content = self.__get_page(self.url)
with open(str(self.num)+'Python最佳实践指南.html', 'w', encoding='utf-8') as f:
f.write(content)
print('写入目录成功')
for href, title in hrefs:
if "#" in href:
continue
self.num += 1
content = self.__get_content(href)
with open(str(self.num)+title+'.html', 'w', encoding='utf-8') as f:
f.write(content)
print('下载第'+str(self.num)+'章成功')
print('下载完毕')
def main():
url = 'http://pythonguidecn.readthedocs.io/zh/latest/'
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36'}
spider = Spider(headers, url)
spider.run()
if __name__ == '__main__':
main()
点击运行,感觉美滋滋,可惜啊,代码总是爱玩弄你,赶紧报了个错:
File "E:/anaconda/python_project/newspaper/spider.py", line 52, in run
with open(str(self.num)+title+'.html', 'w', encoding='utf-8') as f:
FileNotFoundError: [Errno 2] No such file or directory: '38与C/C++库交互.html'
一眼看下去,还挺郁闷的,我没有打开文件的,都是在写文件,为什么报了这个错?仔细一看报错内容,这个名字有问题啊,你看
38与C/C++库交互.html
这个在window系统是以为你在 38与C 的 C++库交互.html 下的,怪不得会报错,所以,我在这里加了这个代码把/给替换掉
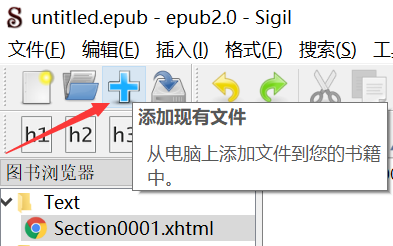
点击Sigil 的 + 号把刚才下载的内容导入
生成目录
添加书名作者
添加封面:点击左上角的 工具 -> 添加封面 即可
点击保存即可完成
转pdf:cn.epubee.com/epub转pdf.ht…
这个很容易就不说了。
结语
好了,文章内容就这么多,下个文章就是学习新内容了。期待ing。
上述文章如有错误欢迎在留言区指出,如果这篇文章对你有用,点个赞,转个发如何?
MORE延伸阅读
日常学python
代码不止bug,还有美和乐趣
