

Web 爬虫下的 Python 数据分析:中情局全球概况图解
在本文章中,我将展示如何使用 Python 和 HTML 解析从网页中获取有价值的信息,之后会回答一些重要的数据分析问题。

在数据科学项目中,数据采集和清洗几乎总是最耗时、最麻烦的步骤。每个人都喜欢用 3D 交互式图表来构建一两个很酷的深度神经网络(或者 XGboost)模型,以此炫耀个人的技术。但这些模型是需要原始数据的,而且它们并不容易采集和清洗。
毕竟生活不像 Kaggle 一样是一个 zip 格式文件,等待您的解压和建模 :-)
但为什么我们要采集数据或者构建模型呢?最初的动机是回答商业、科学或者是社会上的问题。这是趋势么?事物间的关联性?实体的测量可以预测出这种现象的结果么?因为回答这个问题将会验证您作为这个该领域的科学家/实践者所提出的假设。您只是在使用数据(而不是像化学家使用试管或者物理学家使用磁铁)来验证您的假设,并且科学地证明/反驳它。这就是数据科学中的「科学」部分,名副其实……
相信我,提出一个需要一些数据科学技术应用来解决的高质量问题并不难。而且每一个这样的问题都会成为您的一个小项目,您可以将它开源在 Gihub 这样的平台来和您的朋友们分享。即使您不是专业的数据专家,也没有人可以阻止您通过编写很酷的代码来回答一个高质量的数据问题。这也表明您是对数据敏感并且可以用数据讲故事的人。
今天让我们来解决这样一个问题。。。
一个国家的 GDP(按购买力平价)与其互联网用户比例是否有任何关系?这种趋势对于低收入/中等收入/高收入国家而言是否类似?
现在您可以想到许多原始资料可以采集来作为回答此问题的数据。我发现中情局(是的 ‘AGENCY’)的一个网站保存了世界上所有国家的基本事实信息,是一个采集数据的好地方。
因此我们将使用以下 Python 模块来构建我们的数据库和可视化,
- Pandas, Numpy, matplotlib/seaborn
- Python urllib (发送 HTTP 请求)
- BeautifulSoup (用于 HTML 解析)
- Regular expression module (用于查找要搜索的精确匹配文本)
让我们讨论一下解决这个数据科学问题的程序结构。整个项目代码在我的 Github 仓库中都可以找到。如果您喜欢的话,请 fork 或者给个 star。
阅读 HTML 首页并传递给 BeautifulSoup
这儿是中情局全球概况首页
图:中情局全球概况首页
我们使用一个带有 SSL 错误忽略上下文的简单 urllib 请求来检索这个页面,然后将它传递给神奇的 BeautifulSoup,它将为我们解析 HTML 并生成一个漂亮的文本转储。对于那些不熟悉 BeautifulSoup 库的人,他们可以观以下视频或者在 Medium 上阅读这篇内容丰富的文章。
YouTube 视频地址:https://youtu.be/aIPqt-OdmS0
以下是读取的首页 HTML 的代码片段,
ctx = ssl.create_default_context()
ctx.check_hostname = False
ctx.verify_mode = ssl.CERT_NONE
# 从 URL 中读取 HTML 并将其传递给 BeautifulSoup
url = 'https://www.cia.gov/library/publications/the-world-factbook/'
print("Opening the file connection...")
uh= urllib.request.urlopen(url, context=ctx)
print("HTTP status",uh.getcode())
html =uh.read().decode()
print(f"Reading done. Total {len(html)} characters read.")
以下是我们如何将其传递给 BeautifulSoup 并使用 find_all 方法查找 HTML 中嵌入的所有国家名称和代码。基本上,这个想法是找到名为 ‘option’ 的 HTML 标签。标签中的文本是国家名,标签值的 5 号和 6 号表示的是 2 个字符的国家代码。
现在您可能会问,您如何知道只需要提取第五和第六字符?简单的答案是您必须亲自检查 soup 文本--即解析的 HTML 文本,并确定这些索引。没有通用的方法来检查这一点,因为每个 HTML 页面和底层结构都是独一无二的。
soup = BeautifulSoup(html, 'html.parser')
country_codes=[]
country_names=[]
for tag in soup.find_all('option'):
country_codes.append(tag.get('value')[5:7])
country_names.append(tag.text)
temp=country_codes.pop(0) # To remove the first entry 'World'
temp=country_names.pop(0) # To remove the first entry 'World'
爬取:将所有国家的文本数据逐个抓取到字典中
这一步就是他们所说的爬取或者抓取。要实现这一点,关键是要确定每个国家信息页面的 URL 是如何构造的。现在的一般情况是,这将很难获得。特殊情况下,快速检查显示了一个非常简单并且有规律的结构,以澳大利亚截图为例。
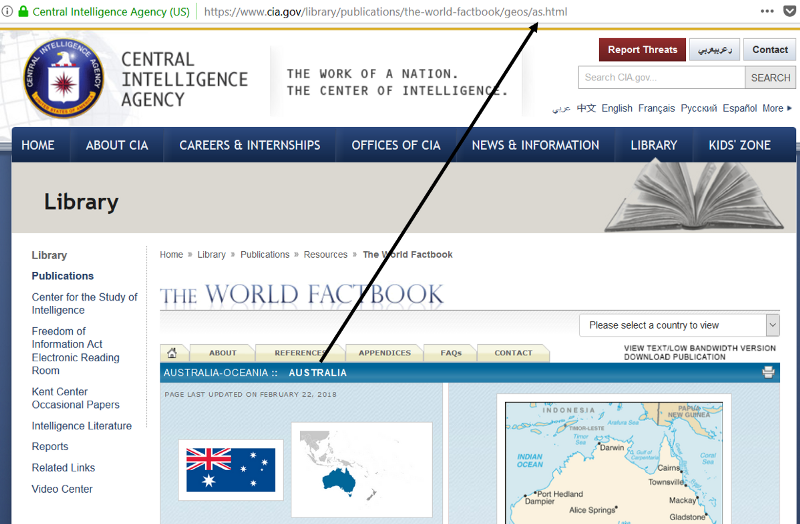
这意味着有一个固定的URL,您必须附加两个字符的国家代码,并获得该国家的页面网址。因此,我们只需遍历国家代码列表,使用 BeautifulSoup 提取所有文本并存储在本地词典中。这是代码片,
# 基础 URL
urlbase = 'https://www.cia.gov/library/publications/the-world-factbook/geos/'
# 空数据字典
text_data=dict()
# 遍历每个国家
for i in range(1,len(country_names)-1):
country_html=country_codes[i]+'.html'
url_to_get=urlbase+country_html
# 从 URL 中读取 HTML 并将其传递给 BeautifulSoup
html = urllib.request.urlopen(url_to_get, context=ctx).read()
soup = BeautifulSoup(html, 'html.parser')
txt=soup.get_text()
text_data[country_names[i]]=txt
print(f"Finished loading data for {country_names[i]}")
print ("\n**Finished downloading all text data!**")
如果您喜欢,可以存放在一个 Pickle dump 中
另外,我偏向于序列化并将数据存储在Python pickle 对象中。这样我下次打开 Jupyter 笔记本时,就可以直接读取数据而无需重复网络爬行步骤。
import pickle
pickle.dump(text_data,open("text_data_CIA_Factobook.p", "wb"))
# 取消选择,下次从本地存储区读取数据。
text_data = pickle.load(open("text_data_CIA_Factobook.p", "rb"))
使用正则表达式从文本转储中提取 GDP/人均数据
这是程序的核心文本分析部分,我们借助正则表达式模块来查找我们在庞大文本字符串中寻找的内容,并提取相关的数字数据。现在,正则表达式是 Python(或者几乎是所有的高级编程语言)中的一个丰富资源。它允许在大量文本中以特定模式搜索/匹配字符串。这里我们使用非常简单的正则表达式方法来匹配精确的单词,如“GDP — per capita (PPP):”然后读取几个字符,提取诸如 $ 和 () 等特定符号的位置,最后提取 GDP/人均数值。这是一个用数字说明的想法。
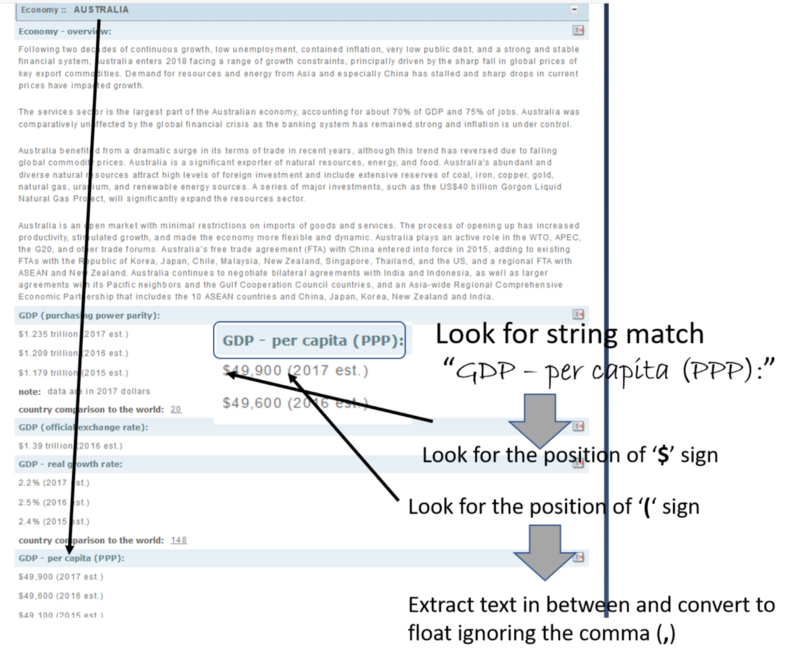
图:文本分析图示。
这个笔记本中还有其他一些常用的表达方式,例如,不管这个数字是以数十亿还是数万亿美元计算出来的,都可以正确地提取出 GDP 总量。
# 'b' 去捕捉 'billions', 't' 去捕捉 'trillions'
start = re.search('\$',string)
end = re.search('[b,t]',string)
if (start!=None and end!=None):
start=start.start()
end=end.start()
a=string[start+1:start+end-1]
a = convert_float(a)
if (string[end]=='t'):
# 如果 GDP 数值在 万亿中,则乘以 1000
a=1000*a
以下是代码片段的示例。注意放置在代码中的多个错误处理检查。这是必要的,因为 HTML 页面具有极不可预测性。并非所有国家都有 GDP 数据,并非所有页面的数据措辞都完全相同,并非所有数字看起来都一样,并非所有字符串放置方式都类似于 $ 和 ()。任何事都可能出错。
为所有的场景规划和编写代码几乎是不可能,但至少要有代码来处理可能出现的异常,这样您的程序才不会停止,并且可以继续优雅地进行下一页处理。
# 初始化保存数据的字典
GDP_PPP = {}
# 遍历每个国家
for i in range(1,len(country_names)-1):
country= country_names[i]
txt=text_data[country]
pos = txt.find('GDP - per capita (PPP):')
if pos!=-1: #If the wording/phrase is not present
pos= pos+len('GDP - per capita (PPP):')
string = txt[pos+1:pos+11]
start = re.search('\$',string)
end = re.search('\S',string)
if (start!=None and end!=None): #If search fails somehow
start=start.start()
end=end.start()
a=string[start+1:start+end-1]
#print(a)
a = convert_float(a)
if (a!=-1.0): #If the float conversion fails somehow
print(f"GDP/capita (PPP) of {country}: {a} dollars")
# 在字典中插入数据
GDP_PPP[country]=a
else:
print("**Could not find GDP/capita data!**")
else:
print("**Could not find GDP/capita data!**")
else:
print("**Could not find GDP/capita data!**")
print ("\nFinished finding all GDP/capita data")
不要忘记使用 pandas inner/left join 方法
需要记住的一点是,所有这些分本分析都将产生具有略微不同的国家集的数据。因为不同的国家可能无法获得不同类型的数据。人们可以使用一个 Pandas left join 来创建一个与所有可获得/可以提取的所有数据片段的所有公共国家相交的数据。
df_combined = df_demo.join(df_GDP, how='left')
df_combined.dropna(inplace=True)
啊,现在是很酷的东西,建模。。。但等等!还是先过滤吧!
在完成了所有的 HTML 解析、页面爬取和文本挖掘后,现在您已经可以享受这些好处了--渴望运行回归算法和很酷的可视化脚本!但是等等,在生成这些东西之前,通常您需要清洗您的数据(特别是针对这种社会经济问题)。基本上,您需要过滤掉异常值,例如非常小的国家(比如岛屿国家),它们可能对您要绘制的参数值造成极大的偏差,且不遵循您想要研究的主要基本动态。对这些过滤器来说,几行代码是很好的。可能有更多的 Pythonic 方法来实现他们,但我尽量保持它极其简单且易于遵循。例如,下面的代码创建过滤器,将 GDP 小于五百亿的小国拒之门外,低收入和高收入的界限分别为 5000 美元和 25000 美元(GDP/人均 GDP)。
# 创建过滤后的数据帧、x 和 y 数组
filter_gdp = df_combined['Total GDP (PPP)'] > 50
filter_low_income=df_combined['GDP (PPP)']>5000
filter_high_income=df_combined['GDP (PPP)']<25000
df_filtered = df_combined[filter_gdp][filter_low_income][filter_high_income]
最后是可视化
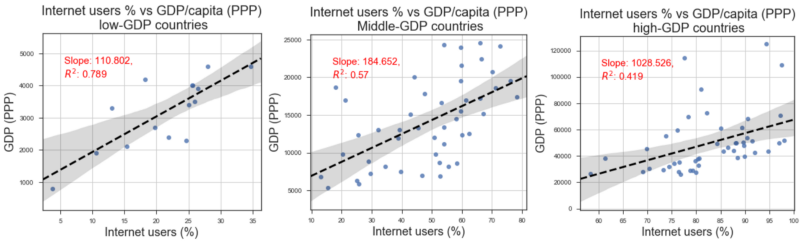
我们使用 seaborn regplot 函数创建线性回归拟合的散点图(互联网用户数量比上人均 GDP)和显示 95% 置信区间带。他们看起来就像下面一样。可以将结果解释为
一个国家的互联网用户数量与人均 GDP 之间存在着很强的正相关关系。此外,低收入/低 GDP 国家的相关强度明显高于高 GDP 发达国家。这可能意味着,与发达国家相比,互联网接入有助于低收入国家更快地增长,并更好地改善其公民的平均状况。
总结
本文通过一个 Python 笔记本演示来说明如何通过使用 BeautifulSoup 进行 HTML 解析来抓取用于下载原始信息的网页。在此基础上,阐述了如何利用正则表达式模块来搜索和提取用户所需要的重要信息。
最重要的是,它演示了在挖掘杂乱的HTML解析文本时,如何或为什么不可能有简单、通用的规则或程序结构。我们必须检查文本结构,并设置适当的错误处理检查,以便恰当地处理所有情况,以维护程序的流程(而不是崩溃),即使它无法提取所有这些场景的数据。
我希望读者能从提供的笔记本文件中获益,并根据自己的需求和想象力在此基础上构建。更多 Web 数据分析笔记 请查看我的仓库
如果您有任何问题和想法可以分享,请联系作者 tirthajyoti@gmail.com。当然您也可以查看作者的 GitHub 仓库中的 Python, R, 或者 MATLAB 和机器学习的资源。如果你像我一样热衷于机器学习/数据科学,请随时在 LinkedIn 上添加我或者在 Twitter 上关注我。
掘金翻译计划 是一个翻译优质互联网技术文章的社区,文章来源为 掘金 上的英文分享文章。内容覆盖 Android、iOS、前端、后端、区块链、产品、设计、人工智能等领域,想要查看更多优质译文请持续关注 掘金翻译计划、官方微博、知乎专栏。
