

为了解决分库分表后,跨库查询和分页查询的难题,基于CQRS思想,采用es作为查询的存储中心。
ES基础名词解释
文档(document):索引和搜索时使用的主要数据载体,包含一个或多个存有数据的字段。
字段(field):文档的一部分,包含名称和值两部分。
词(term):一个搜索单元,表示文本中的一个词。
标记(token):表示在字段文本中出现的词,由这个词的文本、开始和结束偏移量以及类
型组成。
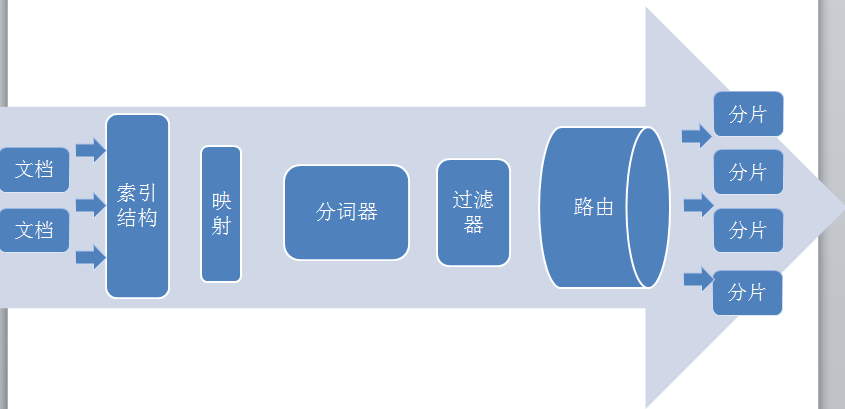
文档索引到es的分片中需要经历几个非常重要的加工环节,每个环节对索引和查询都有不用的影响。
此过程中的所有节点均可以使用自定义的方式来处理,不同定义配置,得到的结果不一样。当然我们只需了解官方建议,保证第一版本需求完成的实现方式。
1.索引结构。首先需要定义索引的结构,如树形结构,组合方式或者父子关系等匹配关系型数据库的结构。
2.映射。映射跟索引结构关联比较大,两者结合定义文档字段解析方式,如某个字段按字符串解析,某个字段按对象解析等
3.分词器。对输入的文档进行拆分,如一个长的文本 按词拆分。经过分词器后输出的是标记流。
4.过滤器。如小写过滤,同义词过滤等复杂转换匹配,保证文档按统一方式解释。
5.路由。把文档索引到不同分片上,负载 ,备份等需要。
针对关系型数据处理的要求,我们需要重点关注的是:
1.索引结构的建立,使用组合或者父子关系来索引文档,并且做一些适当冗余(如果需要)。
2.路由使用。由于父子关系索引的文档默认会分配到不同的分片上,影响查询效率。需要自定义路由的方式来索引和查询
3.其他各个加工环节影响性能的环节,可以在后续版本深入研究。
4.不同的索引方式对应的查询方式有差别。
5.注意用户使用时候怎么能傻瓜化
索引文档方式的特点的官方说明和对比图
| 数据结构 | 查询效率 | 数据修改 | 适用范围 |
|---|---|---|---|
| 规范化(按照数据库的表结构) | 查询慢,join多 | 支持 | 数据规范,结构清晰,数据量小,对查询速度要求不高 |
| 非规范化(数据冗余方式) | 比规范化快,通过冗余增加查询维度 | 支持,需要保持冗余格式 | 增加冗余字段,以最小的代价完成查询维度查询 |
| 嵌套方式 | 快,单一文档无join | 修改子项需要全部更新 | 子项多且不变,查询速度要求高 |
| 父子关系方式 | 父子分别查询快,支持has child、has parent等 | 可单独修改父项和子项 | 子项多,经常做增加修改变更 |
请关注:https://github.com/chenjy16
