

前言
各位朋友大家好,小之今天又来给大家带来一些干货了。上篇文章机器学习股票价格预测初级实战是我在刚接触量化交易那会,因为苦于找不到数据源,所以找的一个第三方平台来获取股票数据。
后来对平台上使用的ipython notebook感兴趣了,我毕竟Python学习的时间不长,所以接触到这样特殊美好的编译环境,真的很欣喜。ipython中代码、文字、图表混合在一起,非常方便做文档演示,而且它可以即时编译,总之用起来很爽。
所以我就查阅了一些资料,了解到实际上我们自己也是可以使用ipython来作为本地编辑器的,这让我特别开心,加上这周五,也就是明天,我要在全公司面前做一个人工智能和量化交易方面的分享会,所以我就趁机把演示代码写在ipython notebook上,等明天的时候,先把代码跑好,然后边演示代码边演示图表,舒服,等会大家也会在文章中感受到ipython notebook的魅力。
这个PPT我会分享出来,并且还会用一篇文章,专门的说说我在这次分享会演讲中说了什么,想到了什么,希望可以和大家一起交流。
当然,PPT 的样式可能真的不太符合你的期望,我只是一个程序员,实在是不太擅长这些,所以白底黑字,感觉也是极好的。
URL分析
像上篇文章,我是用的股票中的指数数据来分析,不过呢,周五的分享会中,我需要用一个我们公司平时比较熟悉的一个品种(我们公司涉及的是贵金属现货),所以我就询问了我们的CTO,让他给我些路子拿到黄金的数据,后来CTO给了我个地址,华尔街见闻网站。然后点开我需要的品种的图表,用chrome的检查工具,轻易的就抓到了URL数据。网页上大概是这样的
这个数据的请求url是这样的
https://forexdata.wallstreetcn.com/kline?prod_code=XAUUSD&candle_period=8&data_count=1000&end_time=1413158399&fields=time_stamp%2Copen_px%2Cclose_px%2Chigh_px%2Clow_px
数据的格式很清晰,我们大概可以猜测到请求参数data_count代表的是请求的数据量,end_time是时间戳,这两个数据结合在一起就是从end_time开始往前data_count个交易日的数据。
后面带&号的就是我们需要获取的数据了,time_stamp是每笔数据的时间戳,close是收盘价,open是开盘价,high是最高价,low是最低价,这五个数据是我们需要绘制K线图的基本数据,就是所谓的蜡烛图了,K线有不太了解的伙伴可以自己查阅下,我在这里就不多细说了。
爬取数据
分析好url,我们就要正式的爬取数据了,我希望获取黄金(这里实际上是黄金/美金,代号是XAUUSD,是一种外汇)10年的数据,这里注意下,经过我的尝试,这个url中,data_count最多只能获取1000的数据,如果大于1000,也会默认返回1000条数据。那么自然,我们的请求参数end_time就得动态变化。
为了方便,我决定每次只爬取一年的数据,所以data_count固定死为365,而end_time通过format函数从参数中获取,代码如下
def get_data(end_time,count):
url = "https://forexdata.wallstreetcn.com/kline?prod_code=XAUUSD&candle_period=8&data_count=365&end_time="\
"{end_time}"\
"&fields=time_stamp%2Copen_px%2Cclose_px%2Chigh_px%2Clow_px".format(end_time=end_time)
response = requests.get(url) # 请求数据
data_list = json.loads(response.text) # json 解析
data = data_list.get("data").get("candle").get("XAUUSD")
# 转化为 DataFrame
df = pd.DataFrame(data,columns=['date','open','close','high','low'],index=list(range(count,count+365)))
return df
这里,我们使用requests第三方包来请求数据,拿到数据后先用json来解析数据,最后把数据转化为pandas的DataFrame结构。这个是常规操作了,大家应该都没什么问题。
获取数据的方法写好后,我们循环调用10次get_data函数,并且把DataFrame对象进行拼接,就完整的拿到我们黄金的10年数据了,注意每次循环间隔要有一定延时,免得被反爬虫机制封了iP啦。
init_time = 1237507200 # 2009年3月20日
window = 60*60*24*365 # 每次获取365天的数据
df = pd.DataFrame()
for i in range(10):
df = pd.concat([df,get_data(init_time + i * window,i*365)])
print("get data success ",i)
time.sleep(0.5)
好了,代码执行完之后,我们来看看df的数据,截一个ipython notebook的样式。
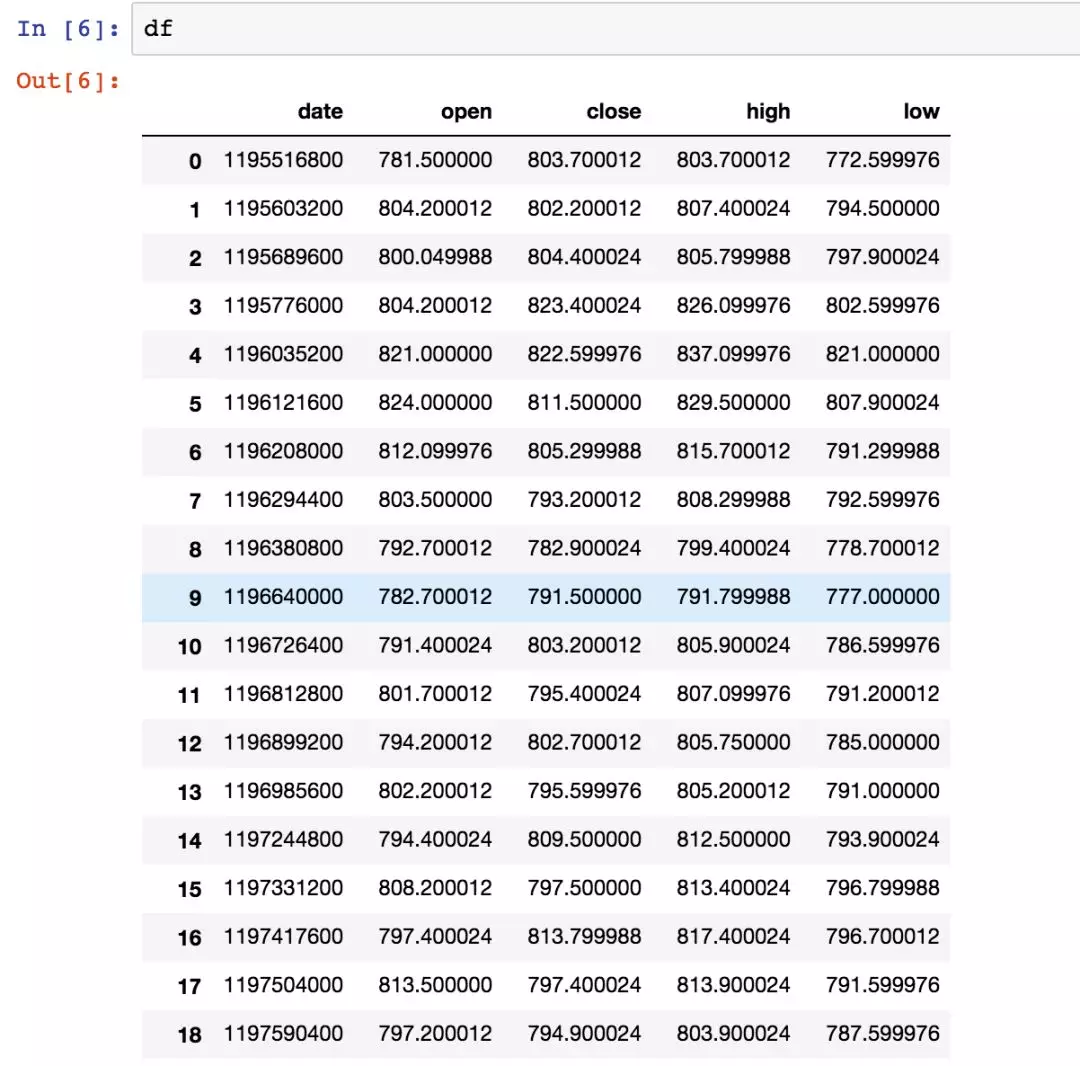
ipython这种体验我可以归纳为:及时行乐。
玩弄数据
好了,现在我们有了3650条DataFrame数据了,作为拥有数据分析三大神器的Python来说,下面就可以随意的玩弄数据了。(import matplotlib.pyplot as plt)
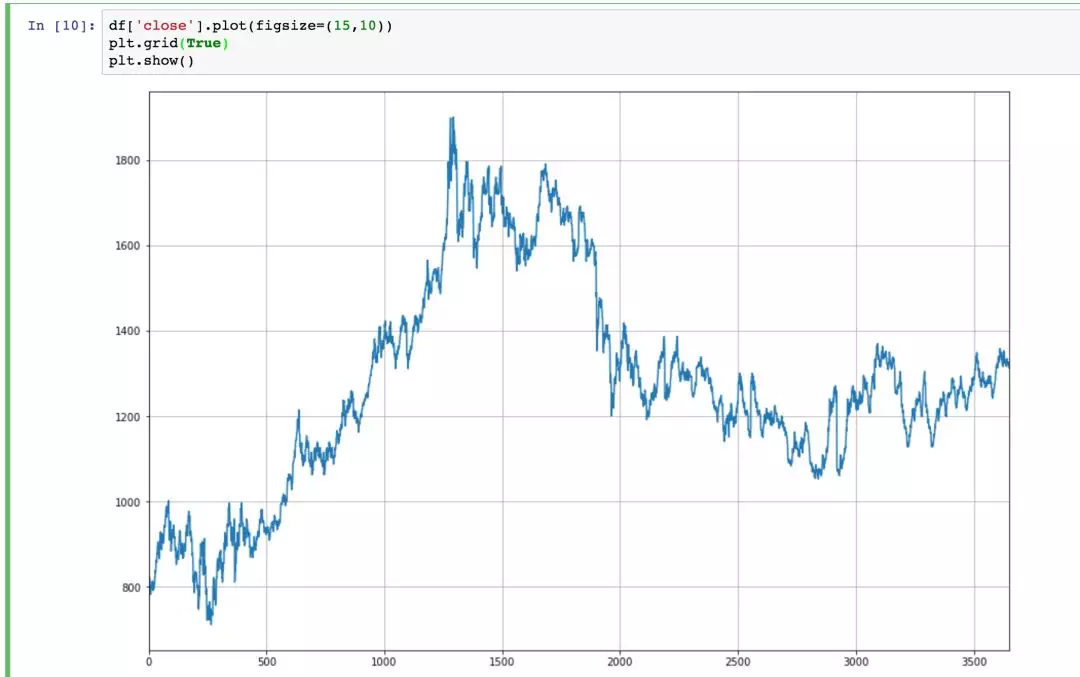
比如我们绘制下黄金的收盘价走势图,三行代码就可以咯
df['close'].plot(figsize=(15,10))
plt.grid(True)
plt.show()
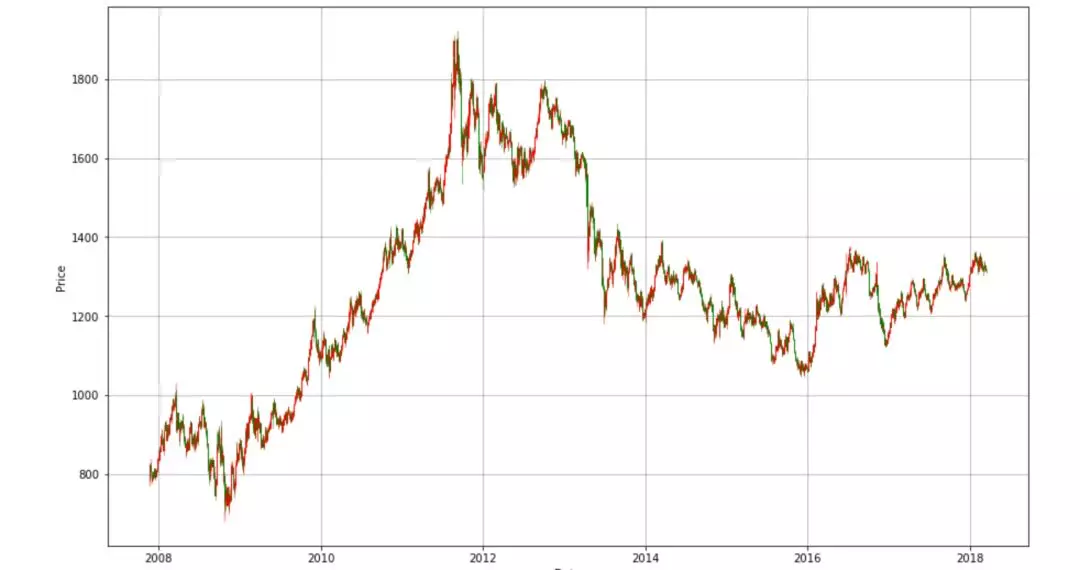
那我们有了绘制K线数据的5个基本数据,不绘制个K线显然说不过去。绘制K线的代码稍微复杂一些,主要就是处理横坐标的时间,需要有一个数据的转化,把时间戳转化为%Y-%m-%d,再把这种格式转化为pyplot支持的时间样式。
import matplotlib.finance as mpf
from matplotlib.pylab import date2num
import datetime
r = map(lambda x : time.strftime('%Y-%m-%d',time.localtime(x)),df['date'])
df['date'] = list(r)
def date_to_num(dates):
num_time = []
for date in dates:
date_time = datetime.datetime.strptime(date,'%Y-%m-%d')
num_date = date2num(date_time)
num_time.append(num_date)
return num_time
fig,ax = plt.subplots(figsize=(15,10))
mat_data = df.as_matrix()
num_time = date_to_num(mat_data[:,0])
mat_data[:,0] = num_time
fig.subplots_adjust(bottom=0.2)
ax.xaxis_date()
mpf.candlestick_ochl(ax,mat_data,width=0.6,colorup='r',colordown='g')
plt.grid(True)
plt.xlabel('Data')
plt.ylabel('Price')
plt.show()
我们还可以绘制这10年来每天的涨跌幅状态,从中能看出黄金走势的牛熊和震荡
rate_of_return = (df['close']-df['open'])/df['open']
rate_of_return.plot(kind='line',style='k--',figsize=(15,10))
plt.show()
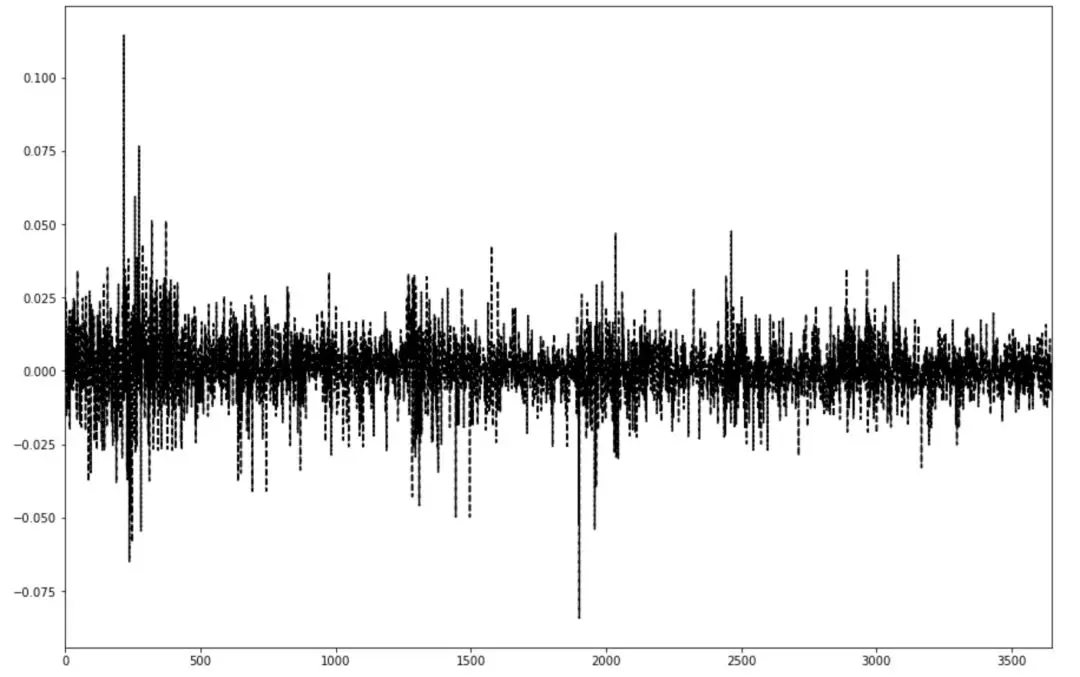
可以看出,黄金大部分时间都是在震荡,刚开始和中间有一些比较反常的情况,刚开始那个我推测是经济危机之后那段时间的调整,美元大跌那会吧。
哦对了,这里我要纠正下我上篇文章的一个错误,记得那个弯曲的柱状图吗,没错,就是它了
我当时以为是ipython的bug,后来发现并不是,而是代码中我加了这一行
with plt.xkcd():
xkcd是一部漫画的名称,然后这个函数代表就是用类似于这部漫画的style来画图,所以,这漫画是啥样的呢?

emm...看起来确实很手工。
结尾
好了,数据爬取篇就这样了,实际上和大部分爬取工作都差不多,只是行情有一定的特殊性。
下一篇我将针对这些数据玩弄一些机器学习代码,来和大家一起调调参。
推荐阅读
关注公众号获取更多干货文章-AI极客研修站

