


mysql之高性能索引
当db的量达到一定数量级之后,每次进行全表扫描效率就会很低,因此一个常见的方案是建立一些必要的索引作为优化手段,那么问题就来了:
- 那么什么是索引呢?
- 索引的实现原理是怎样的?
- 我们通常说的聚集索引,非聚集索引的区别是什么?
- 如何创建和使用索引呢?
I. 索引介绍
MySQL官方对索引的定义为:索引是帮助MySQL高效获取数据的数据结构。简而言之,索引是数据结构
1. 几种树的结构
a. B+树
单来说就是一种为磁盘或者其他存储设备而设计的一种平衡二叉树,在B+tree中所有记录都按照key的大小存放在叶子结点上,各叶子结点直接用指针连接
b. 二叉树
二叉树的规则是父节点大于左孩子节点,小于右孩子节点
c. 平衡二叉树
首先是一个二叉树,但是要求任意一个节点的左右孩子节点的高度差不大于1
d. B树
首先是一个平衡二叉树,但是又要求每个叶子节点到根节点的距离相等
那么B树和B+树的区别是什么呢?
- B+树的叶子节点可以包含一个指针,指向另一个叶子节点
- B+树键值的拷贝存在非叶子节点;键值+记录存储在叶子节点
2. InnoDB引擎之B+树
mysql的InnnoDB引擎采用的B+树,只有叶子节点存储对应的数据列,有以下好处
- 叶子结点通常包含较多的记录,具有较高的扇出性(可理解为每个节点对应的下层节点较多),因此树的高度较低(3~4),而树的高度也决定了磁盘IO的次数,从而影响了数据库的性能。一般情况下,IO次数与树的高度是一致的
- 对于组合索引,B+tree索引是按照索引列名(从左到右的顺序)进行顺序排序的,因此可以将随机IO转换为顺序IO提升IO效率;并且可以支持order by \group等排序需求;适合范围查询
3. hash索引
hash索引,相比较于B树而言,不需要从根节点到叶子节点的遍历,可以一次定位到位置,查询效率更高,但缺点也很明显
- 仅能满足"=","IN"和"<=>"查询,不能使用范围查询
- 因为是通过hash值进行计算,所以只能精确查询,hash值是没什么规律的,不能保证顺序和原来一致,所以范围查询不行
- 无法进行排序
- 原因同上
- 不支持部分索引
- hash值的计算,是根据完整的几个索引列计算,如果少了其中一个乃至几个,这个hash值就没法计算了
- hash碰撞
4. 聚集索引与非聚集索引
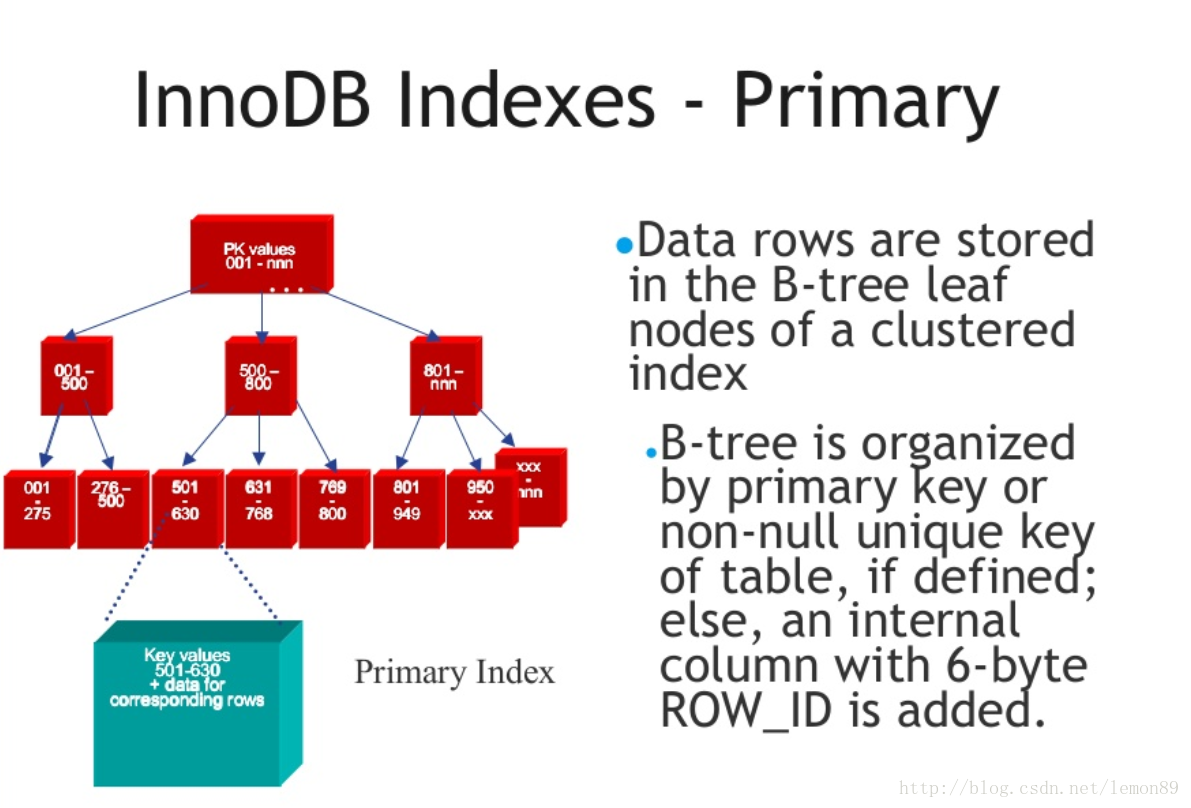
a. 聚集索引
InnoDB的数据文件本身就是索引文件,B+Tree的叶子节点上的data就是数据本身,key为主键,非叶子节点存放<key,address>,address就是下一层的地址
聚簇索引的结构图:
b. 非聚集索引
非聚簇索引,叶子节点上的data是主键(即聚簇索引的主键,所以聚簇索引的key,不能过长)。为什么存放的主键,而不是记录所在地址呢,理由相当简单,因为记录所在地址并不能保证一定不会变,但主键可以保证
非聚簇索引结构图:
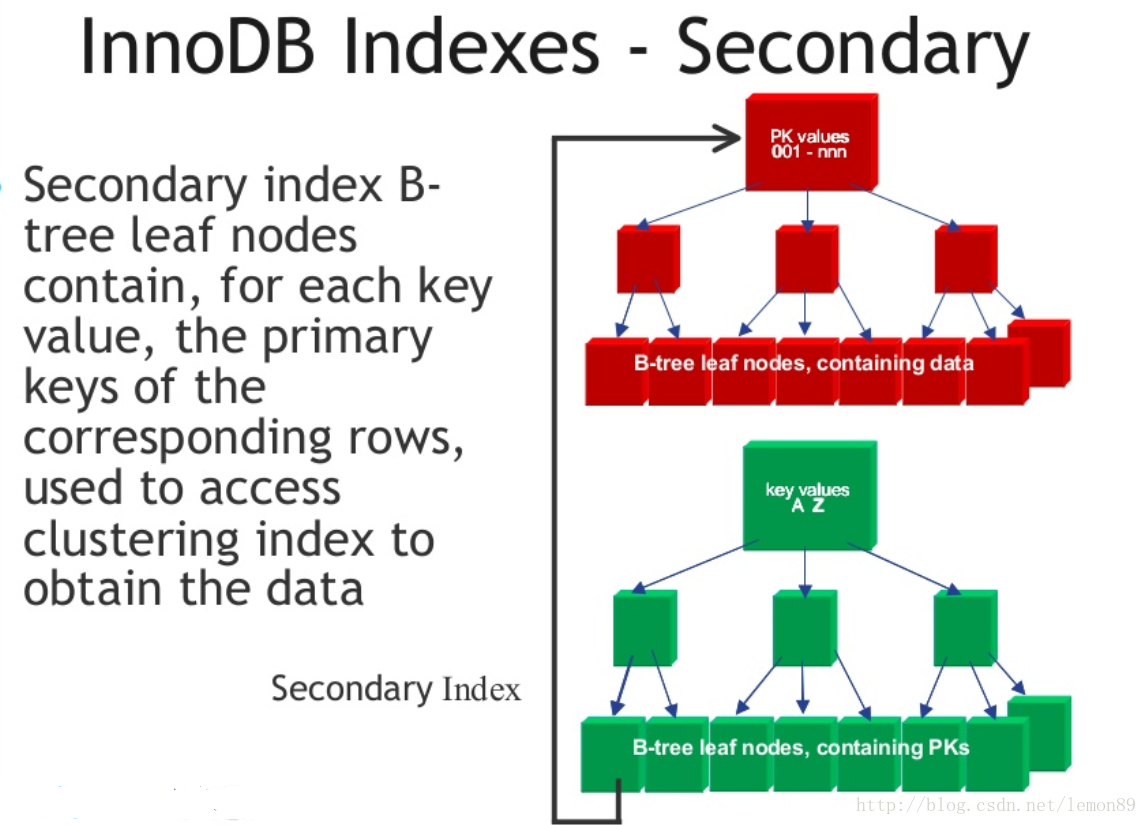
从非聚集索引的结构上,可以看出这种场景下的定位流程:
- 先通过非聚集索引,定位到对应的叶子节点,找到对应的主键
- 根据上面找到的主键,在聚集索引中,定位到对应的叶子节点(获取数据)
5. 索引的优点
- 避免全表扫描(当走不到索引时,就只能一个一个的去匹配;如果走索引,则可以根据B树来定位)
- 使用索引可以帮助服务器避免排序或者临时表 (叶子节点上的指针,可以有效的支持范围查询;此外叶子节点本身就是根据key进行排序的)
- 索引将随机IO变成顺序IO
6. 适用范围
索引并不是适用于任何情况。对于中型、大型表适用。对于小型表全表扫描更高效。而对于特大型表,考虑”分区”技术
II. 索引的使用原则
一般我们在创建表的时候,需要指定primary key, 这样就可以确定聚集索引了,那么如何添加非聚集索引呢?
1. 索引的几个语法
创建索引
-- 创建索引
create index `idx_img` on newuser(`img`);
-- 查看
show create table newuser\G;
输出
show create table newuser\G
*************************** 1. row ***************************
Table: newuser
Create Table: CREATE TABLE `newuser` (
`userId` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '用户id',
`username` varchar(30) DEFAULT '' COMMENT '用户登录名',
`nickname` varchar(30) NOT NULL DEFAULT '' COMMENT '用户昵称',
`password` varchar(50) DEFAULT '' COMMENT '用户登录密码 & 密文根式',
`address` text COMMENT '用户地址',
`email` varchar(50) NOT NULL DEFAULT '' COMMENT '用户邮箱',
`phone` bigint(20) NOT NULL DEFAULT '0' COMMENT '用户手机号',
`img` varchar(100) DEFAULT '' COMMENT '用户头像',
`extra` text,
`isDeleted` tinyint(1) unsigned NOT NULL DEFAULT '0',
`created` int(11) NOT NULL,
`updated` int(11) NOT NULL,
PRIMARY KEY (`userId`),
KEY `idx_username` (`username`),
KEY `idx_nickname` (`nickname`),
KEY `idx_email` (`email`),
KEY `idx_phone` (`phone`),
KEY `idx_img` (`img`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8
另一种常见的添加索引方式
alter table newuser add index `idx_extra_img`(`isDeleted`, `img`);
-- 查看索引
show index from newuser;
输出结果
+---------+------------+---------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+---------+------------+---------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| newuser | 0 | PRIMARY | 1 | userId | A | 3 | NULL | NULL | | BTREE | | |
| newuser | 1 | idx_username | 1 | username | A | 3 | NULL | NULL | YES | BTREE | | |
| newuser | 1 | idx_nickname | 1 | nickname | A | 3 | NULL | NULL | | BTREE | | |
| newuser | 1 | idx_email | 1 | email | A | 3 | NULL | NULL | | BTREE | | |
| newuser | 1 | idx_phone | 1 | phone | A | 3 | NULL | NULL | | BTREE | | |
| newuser | 1 | idx_img | 1 | img | A | 3 | NULL | NULL | YES | BTREE | | |
| newuser | 1 | idx_extra_img | 1 | isDeleted | A | 3 | NULL | NULL | | BTREE | | |
| newuser | 1 | idx_extra_img | 2 | img | A | 3 | NULL | NULL | YES | BTREE | | |
+---------+------------+---------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
删除索引
drop index `idx_extra_img` on newuser;
drop index `idx_img` on newuser;
-- 查看索引
show index from newuser;
输出
show index from newuser;
+---------+------------+--------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+---------+------------+--------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| newuser | 0 | PRIMARY | 1 | userId | A | 3 | NULL | NULL | | BTREE | | |
| newuser | 1 | idx_username | 1 | username | A | 3 | NULL | NULL | YES | BTREE | | |
| newuser | 1 | idx_nickname | 1 | nickname | A | 3 | NULL | NULL | | BTREE | | |
| newuser | 1 | idx_email | 1 | email | A | 3 | NULL | NULL | | BTREE | | |
| newuser | 1 | idx_phone | 1 | phone | A | 3 | NULL | NULL | | BTREE | | |
+---------+------------+--------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
强制走索引的一种方式
语法: select * from table force index(索引) where xxx
explain select * from newuser force index(PRIMARY) where userId not in (3, 2, 5);
-- +----+-------------+---------+-------+---------------+---------+---------+------+------+-------------+
-- | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
-- +----+-------------+---------+-------+---------------+---------+---------+------+------+-------------+
-- | 1 | SIMPLE | newuser | range | PRIMARY | PRIMARY | 8 | NULL | 4 | Using where |
-- +----+-------------+---------+-------+---------------+---------+---------+------+------+-------------+
explain select * from newuser where userId not in (3, 2, 5);
-- +----+-------------+---------+------+---------------+------+---------+------+------+-------------+
-- | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
-- +----+-------------+---------+------+---------------+------+---------+------+------+-------------+
-- | 1 | SIMPLE | newuser | ALL | PRIMARY | NULL | NULL | NULL | 3 | Using where |
-- +----+-------------+---------+------+---------------+------+---------+------+------+-------------+
2. 索引使用规则
当一个表内有多个索引时,如何判断自己的sql是否走到了索引,走的是哪个索引呢?
可以通过 explain 关键字来进行辅助判断,当然在实际写sql时,我们也有必要了解下索引匹配的规则,避免设置了一些冗余的索引,或者写出一些走不到索引的sql
测试的表结构如下
*************************** 1. row ***************************
Table: newuser
Create Table: CREATE TABLE `newuser` (
`userId` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '用户id',
`username` varchar(30) DEFAULT '' COMMENT '用户登录名',
`nickname` varchar(30) NOT NULL DEFAULT '' COMMENT '用户昵称',
`password` varchar(50) DEFAULT '' COMMENT '用户登录密码 & 密文根式',
`address` text COMMENT '用户地址',
`email` varchar(50) NOT NULL DEFAULT '' COMMENT '用户邮箱',
`phone` bigint(20) NOT NULL DEFAULT '0' COMMENT '用户手机号',
`img` varchar(100) DEFAULT '' COMMENT '用户头像',
`extra` text,
`isDeleted` tinyint(1) unsigned NOT NULL DEFAULT '0',
`created` int(11) NOT NULL,
`updated` int(11) NOT NULL,
PRIMARY KEY (`userId`),
KEY `idx_username` (`username`),
KEY `idx_nickname_email_phone` (`nickname`,`email`,`phone`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8
a. 最左前缀匹配原则
这个主要是针对多列非聚簇索引而言,比如有下面这个索引idx_nickname_email_phone(nickname, email, phone), nickname 定义在email的前面,那么下面这几个语句对应的情况是
-- 走索引
explain select * from newuser where nickname='小灰灰' and email='greywolf@xxx.com';
-- 1. 匹配nickname,可以走索引
explain select * from newuser where nickname='小灰灰';
-- 输出:
-- +----+-------------+---------+------+--------------------+--------------------+---------+-------+------+-----------------------+
-- | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
-- +----+-------------+---------+------+--------------------+--------------------+---------+-------+------+-----------------------+
-- | 1 | SIMPLE | newuser | ref | idx_nickname_email | idx_nickname_email | 92 | const | 1 | Using index condition |
-- +----+-------------+---------+------+--------------------+--------------------+---------+-------+------+-----------------------+
-- 2. 虽然匹配了email, 但是不满足最左匹配,不走索引
explain select * from newuser where email='greywolf@xxx.com';
-- 输出
-- +----+-------------+---------+------+---------------+------+---------+------+------+-------------+
-- | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
-- +----+-------------+---------+------+---------------+------+---------+------+------+-------------+
-- | 1 | SIMPLE | newuser | ALL | NULL | NULL | NULL | NULL | 3 | Using where |
-- +----+-------------+---------+------+---------------+------+---------+------+------+-------------+
b. 无法跳过某个列使用后续索引列
即对索引idx_nickname_email_phone(nickname, email, phone), 如果你的sql中,只有 nickname 和 phone, 那么phone走不到索引,因为不能跳过中间的email走索引
c. 范围查询后的列无法使用索引
如 >, <, between, like这种就是范围查询,下面的sql中,email 和phone都无法走到索引,因为nickname使用了范围查询
select * from newuser where nickname like '小灰%' and email='greywolf@xxx.com' and phone=15971112301 limit 10;
d. 列作为函数参数或表达式的一部分
-- 走不到索引
explain select * from newuser where userId+1=2 limit 1;
-- 输出
-- +----+-------------+---------+------+---------------+------+---------+------+------+-------------+
-- | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
-- +----+-------------+---------+------+---------------+------+---------+------+------+-------------+
-- | 1 | SIMPLE | newuser | ALL | NULL | NULL | NULL | NULL | 3 | Using where |
-- +----+-------------+---------+------+---------------+------+---------+------+------+-------------+
3. 索引缺点
- 虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件。
- 建立索引会占用磁盘空间的索引文件。一般情况这个问题不太严重,但如果你在一个大表上创建了多种组合索引,索引文件的会膨胀很快。
4. 注意事项
- 索引不会包含有NULL值的列
- 使用短索引
- 索引列排序
- MySQL查询只使用一个索引,因此如果where子句中已经使用了索引的话,那么order by中的列是不会使用索引的。因此数据库默认排序可以符合要求的情况下不要使用排序操作;尽量不要包含多个列的排序,如果需要最好给这些列创建复合索引
- like语句操作
- 一般情况下不鼓励使用like操作,如果非使用不可,如何使用也是一个问题。like “%aaa%” 不会使用索引而like “aaa%”可以使用索引
- 不要在列上进行运算
- select * from users where YEAR(adddate)<2007;
- 尽量不使用NOT IN和<>操作
5. sql使用策略
a. 使用一个sql代替多个sql
通常建议是使用一个sql来替代多个sql的查询
当然若sql执行效率很低,或者出现delete等导致锁表的操作时,也可以采用多个sql,避免阻塞其他sql
b. 分解关联查询
将关联join尽量放在应用中来做,尽量执行小而简单的的sql
- 分解后的sql简单,利于使用mysql缓存
- 执行分解后的sql,减少锁竞争
- 更好的扩展性和维护性(sql简单)
- 关联sql使用的是内嵌循环算法nestloop,而应用中可以使用hashmap等结构处理数据,效率更高
c. count
- count(*) 统计的是行数
- count(列名) 统计的是列不为null的数量
d. limit
- limit offset, size; 分页查询,会查询出 offset + size 条数据,获取最后的size条数据
如 limit 1000, 20 则会查询出满足条件的1020条数据,然后将最后的20个返回,所以尽量避免大翻页查询
e. union
需要将where、order by、limit 这些限制放入到每个子查询,才能重分提升效率。另外如非必须,尽量使用Union all,因为union会给每个子查询的临时表加入distinct,对每个临时表做唯一性检查,效率较差。
6. mysql使用查询
a. 查看索引
-- 单位为GB
SELECT CONCAT(ROUND(SUM(index_length)/(1024*1024*1024), 6), ' GB') AS 'Total Index Size'
FROM information_schema.TABLES WHERE table_schema LIKE 'databaseName';
b. 查看表空间
SELECT CONCAT(ROUND(SUM(data_length)/(1024*1024*1024), 6), ' GB') AS 'Total Data Size'
FROM information_schema.TABLES WHERE table_schema LIKE 'databaseName';
c. 查看数据库中所有表的信息
SELECT CONCAT(table_schema,'.',table_name) AS 'Table Name',
table_rows AS 'Number of Rows',
CONCAT(ROUND(data_length/(1024*1024*1024),6),' G') AS 'Data Size',
CONCAT(ROUND(index_length/(1024*1024*1024),6),' G') AS 'Index Size' ,
CONCAT(ROUND((data_length+index_length)/(1024*1024*1024),6),' G') AS'Total'
FROM information_schema.TABLES
WHERE table_schema LIKE 'databaseName';
IV. 其他
参考
个人博客: 一灰灰Blog
基于hexo + github pages搭建的个人博客,记录所有学习和工作中的博文,欢迎大家前去逛逛
声明
尽信书则不如,已上内容,纯属一家之言,因本人能力一般,见识有限,如发现bug或者有更好的建议,随时欢迎批评指正
- 微博地址: 小灰灰Blog
- QQ: 一灰灰/3302797840
扫描关注

